消费者行为大数据的物流服务市场调查
——以DF物流为例
2021-08-06江涌
江 涌
(黎明职业大学 商学院,福建 泉州 362000)
物流行业与广大消费者的生活休戚相关,物流企业为了提升业绩,其所提供的服务应迎合消费者的喜好与需求。因此真实了解消费者的消费偏好成为指引物流企业经营方针调整的一大风向标。选择合适的市场调查方式是物流企业获取消费者偏好信息的捷径。研究每一位消费者在物流消费过程中留下的行为痕迹是一种全覆盖、全方位、高精度的市场调查方式[1]。灵活运用各种统计量对消费者各种线上行为所产生的数据进行处理分析[2],就能透过大量的行为数据得出市场的真实现状,使企业更好地迎合市场需求,效果显著且成本低廉。
一、消费者行为产生的数据种类
(一)企业链接点击率
点击率即某一内容被点击的次数与该内容的链接被显示的次数之比。消费者如果关注本企业,对本企业所提供的服务感兴趣,就会点击企业在各网站的链接和查看企业的相关信息。从后台搜集的点击信息,可以了解关注企业信息的人数,从网站登录信息可以了解关注企业信息的人群结构,这些都是企业深入了解市场的有价值数据。
(二)月均消费次数
目前大多消费者都是通过个人电脑端或移动端呼叫物流服务。通过这些呼叫服务的网络信息可以清楚地了解每个消费者的消费频次,每次的消费金额,消费者的年龄分布、地点分布,从而为企业更好地做出经营决策提供可靠的依据[3]。
(三)搜索引擎中被搜索的次数
很多消费者会在搜索引擎上搜索物流服务提供商,再从搜索出的结果中选择有用的信息。物流服务提供商在行业中的地位如何?是否受消费者青睐?从其被消费者搜索的次数、频率就可以得出结论。
(四)企业公众号被关注以及所推送信息阅读人数
目前大部分物流服务企业都有企业公众号,从企业公众号的关注人数可以了解企业的知名度、受消费者关注的程度。从公众号推送信息被读取的情况,可以了解关注公众号的有效客户群体的信息,例如人数、性别、年龄、爱好等。
(五)输入法中的固定词组
现在各种输入法为了提高用户的输入效率,会记忆用户常用的词组。物流服务提供商是否成为客户的热门话题?是否广受关注?从输入法的常用词组中就可以得出结论[4]。
(六)服务结束后的评价
物流服务供应商在完成服务后,都会提供评价渠道,获取消费者对本次服务的反馈。目前,常用的评价方式有星级评价、分数评价、文字评价等,这些评价数据是了解消费者对企业服务产品满意程度的重要信息,企业可以此知晓所提供服务产品的受欢迎程度以及员工工作绩效。
二、消费者行为大数据统计量分析
为了详细说明消费者行为大数据统计量分析的应用方法,本文选择在网络消费活动中最能反映消费者市场信息的几个指标进行分析说明,包括企业链接点击率、在同类服务中被消费者选择的次数指标、物流服务五星好评率指标。这几个指标是消费者进行线上物流服务消费活动时必经的环节,因此数据最完整,所显示信息也更全面和准确。
(一)大数据统计量分析原理

图1 原假设的拒绝与接受区域
在对大量的数据进行分析处理前,只看未经处理的数据是得不出任何有用的结论的,但可以对结论进行假设,再用数据统计量去验证这些假设。具体的做法是,先设立两个对立的假设,一个是原假设,一个是备选假设;再设定两个区域,一个是接受区域,一个是拒绝区域。如果数据统计量落入接受区域,就接受原假设,拒绝备选假设;如果数据落入拒绝区域,就拒绝原假设,接受备选假设。原假设和备选假设的设立取决于企业想知道的结论。由于大部分历史数据都服从对称于均值的正态分布,因此可根据正态分布的图形来进行分析。如图1,正态分布曲线下方所覆盖的面积为概率[5],在假设检验中,该面积分为两部分,一部分为原假设的接受区域面积,一部分为原假设的拒绝区域面积。由统计学可知,曲线覆盖面积为对应情况的概率[6]85。概率统计学中不考虑小概率事件,因此,若统计量的值落入小概率的拒绝区域,就认为原假设不会发生,因此接受备选假设。图1说明了原假设的接受区域、拒绝区域、显著性水平之间的关系。
(二)企业链接点击率指标
在统计学中,可以把显著性变化视为质变。以点击率为例,点击率是企业比较关注的一个指标,是指企业链接被点击的次数与显示次数的百分比。企业链接点击率显著变化调查是一项纵向调查,能了解企业的营销策略相较于以往是否更加有效。消费者点击企业设置在各个网站的链接,这些点击数据进入网站后台,日积月累将会形成海量的数据,这些数据每天、每周、每月都会发生变化,这些变化是属于正常的数据波动,还是有发生质的变化,只看表面数据是无法得出结论的,需要通过统计量来验证。通常,企业希望通过其链接在网站上的点击率是否显著提高而判断近段时间的营销措施是否有效,在这种情况下,可以把原假设设置为“企业被关注程度没有显著变化”,把备选假设设置为“企业被关注程度显著提高”。以DF物流为例(为保护企业经营隐私,此处以DF物流为企业代称),DF物流在2020年第17周举办了促销活动,为了研究促销活动的成效,DF物流对点击率数据进行分析研究。表1是DF物流在某网站上的链接近段时间的点击率数据(由于篇幅有限,按周截取2020年第9周至第26周的18组数据)。DF物流每周二统计一次点击率,表1中的点击率为当天的数据。

表1 DF物流网上点击率数据
表1中,点击率的计算依据为DF物流的物流服务在网上被查询的次数占本周同类服务总查询次数的比率。其中2020年4月28日的点击率数据有所提升,这是否和企业在第17周加大了营销力度有关,还是仅仅为数据的正常波动,需要进行深入的分析。
1.设立原假设与备选假设
企业希望了解的是表1中第17周的营销活动是否有效,这就体现在第18周(4月28日)的点击率变化上。如果第18周的点击率提高仅仅是数据正常上下起伏,那就说明第17周的营销活动效果不好;而如果第18周点击率的提高属于显著性提高,即发生了质的变化,就说明第17周的营销活动有效。因此可把原假设设立为点击率没有发生显著变化;把备选假设设立为点击率发生了显著变化。
2.数据统计量分析
接下来研究第18周比第17周多出来的14个百分点是属于正常历史数据波动还是显著性变化。本例中的点击率为各期的具体数值,可用Z分布来研究。Z分布的统计量公式[6]125为:
(1)
通过历史数据可以计算出其标准差,标准差是衡量历史数据波动程度的一个重要指标。标准差的计算公式[6]61为:

(2)


(3)
3.研究统计量所处的区域

图2 点击率数据变化显著性水平分析
企业希望知道的是2020年4月28日点击率是否有显著提升。原假设为4月28日的点击率没有显著提升,备选假设为4月28日的点击率有显著提升。统计量的值越大,对原假设越不利,对备选假设越有利,因此原假设的拒绝区域应设置在正态分布图形的右边。同时,企业可根据自身经营情况、对显著性要求的高低、经营产品的特点、所研究问题的性质等情况对显著性水平进行设定。显著性水平的大小决定了拒绝区域面积的大小。DF物流根据自身经营的历史状况设定的点击率显著性水平为α=0.04,查标准正态分布表,得出相应的临界点为1.75。由于2.01>1.75,即统计量的值大于临界点的值,而拒绝区域在临界点的右边,说明统计量的值落入拒绝区域。因此拒绝原假设,接受备选假设。由此可以得出结论,4月28日比前一期增加的点击率,并不是普通的数据波动,而是发生了显著变化,说明营销措施有效。具体分析见图2。
(三)在同类服务中被消费者选择的次数指标
在同类服务中被消费者选择的次数能很好地说明企业的竞争力水平。该项指标是横向对比指标,能说明调查企业与同行业其他企业在消费者心中的接受程度是否有显著差异。消费者在需要物流服务前会通过网络平台、通讯平台对物流企业进行了解,再最终选择物流服务供应商。企业应对各个平台的消费者行为数据进行分析。仍以DF物流的市场调查为例,DF物流将自身的数据与同行企业XD物流(为保护企业经营隐私,此处以XD物流为企业代称)进行对比,DF物流具有本企业的各期数据(因篇幅有限,只列举其中32周的数据,实际工作中为了提高分析精度可导入所有数据),而只搜集到部分XD物流的相关数据。只看表面数据无法判断两家企业在消费者接受程度方面是否有显著差异,虽然平均值不同,但无法知晓这种差异是属于正常的企业间数据差异还是企业经营水平的显著性差异。在此种情况下,选择T统计量进行分析,可以不受两家企业信息量是否一致情况的限制。表2和表3是DF物流与XD物流两家企业在2019年被消费者选择次数情况。

表2 DF物流被消费者选择次数

表2(续)
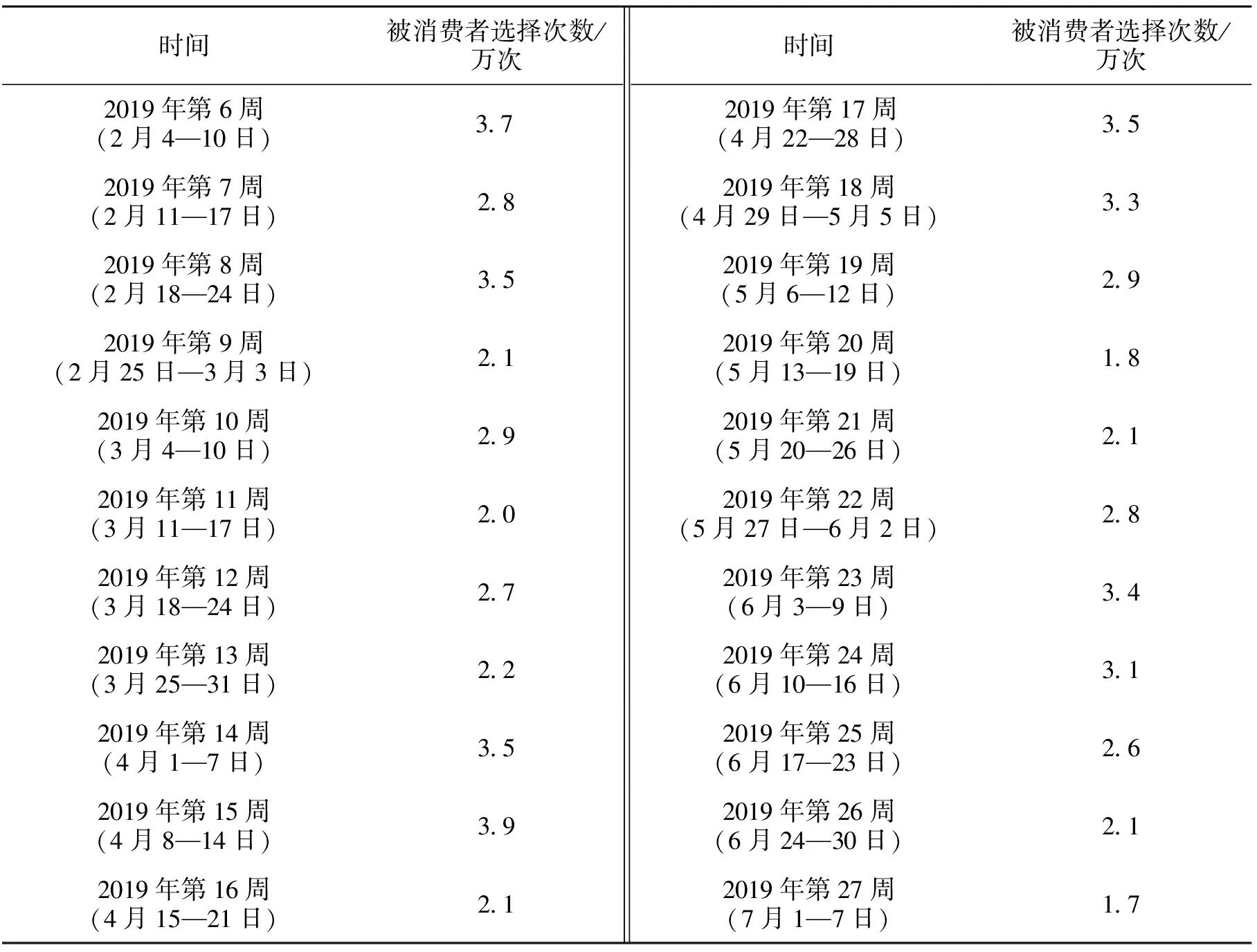
表3 XD物流被消费者选择次数
1.设立原假设与备选假设
DF物流希望通过此次调查,研究与XD物流在消费者接受程度方面是否属于同一竞争层次。因此,原假设可设立为:两家企业被消费者选择的次数没有显著差异(在消费者心中的接受程度一样);备选假设可设立为:两家企业被消费者选择的次数有显著差异(发生了质变)。
2.数据统计量分析
由于此次是将两家企业的数据进行对比,采用T分布进行分析比较合适。T分布统计量的计算公式[6]166为:
(4)


S1(表2数据的标准差)=5.3;
S2(表3数据的标准差)=6.53。
将以上数值代入T分布公式(4),可得:
(5)
3.研究统计量所处的区域
无论DF物流的消费者接受程度显著优于XD物流,还是XD物流的消费者接受程度显著优于DF物流,都属于两者之间有显著差异的情况。因此,当统计量落入右边极值(DF物流的消费者接受程度显著优于XD物流)或左边极值(XD物流的消费者接受程度显著优于DF物流)都对备选假设有利,因此拒绝区域应放在图形的两边。DF物流在消费者接受程度方面的显著性水平为0.05,自由度为(n1+n2-2)=52时,查T分布表单侧0.025的临界值为±2.31,即-2.31~2.31为接受区域。-2.31<0.29<2.31,T值落入接受区域,因此接受原假设,即可以认为两家企业在消费者接受程度方面没有显著差异。具体分析见图3。

图3 两家物流企业被消费者选择次数显著性对比
根据此结论,可以判断DF物流与XD物流在消费者接受度方面处于同一水平,因此可以XD物流为参照展开价格、服务方面的竞争。
(四)物流服务五星好评率指标
为了快速得到客户接受物流服务之后的反馈,物流企业都会在服务评价中以星级评价的方式了解客户的反馈情况。很多物流企业也以客户的星级评价来判断企业经营决策的准确性。DF物流在2019年第28周(7月8—14日)对员工进行岗位技能培训。为评估此次培训的效果,可对培训前后的五星好评率数据进行数理分析,详见表4。
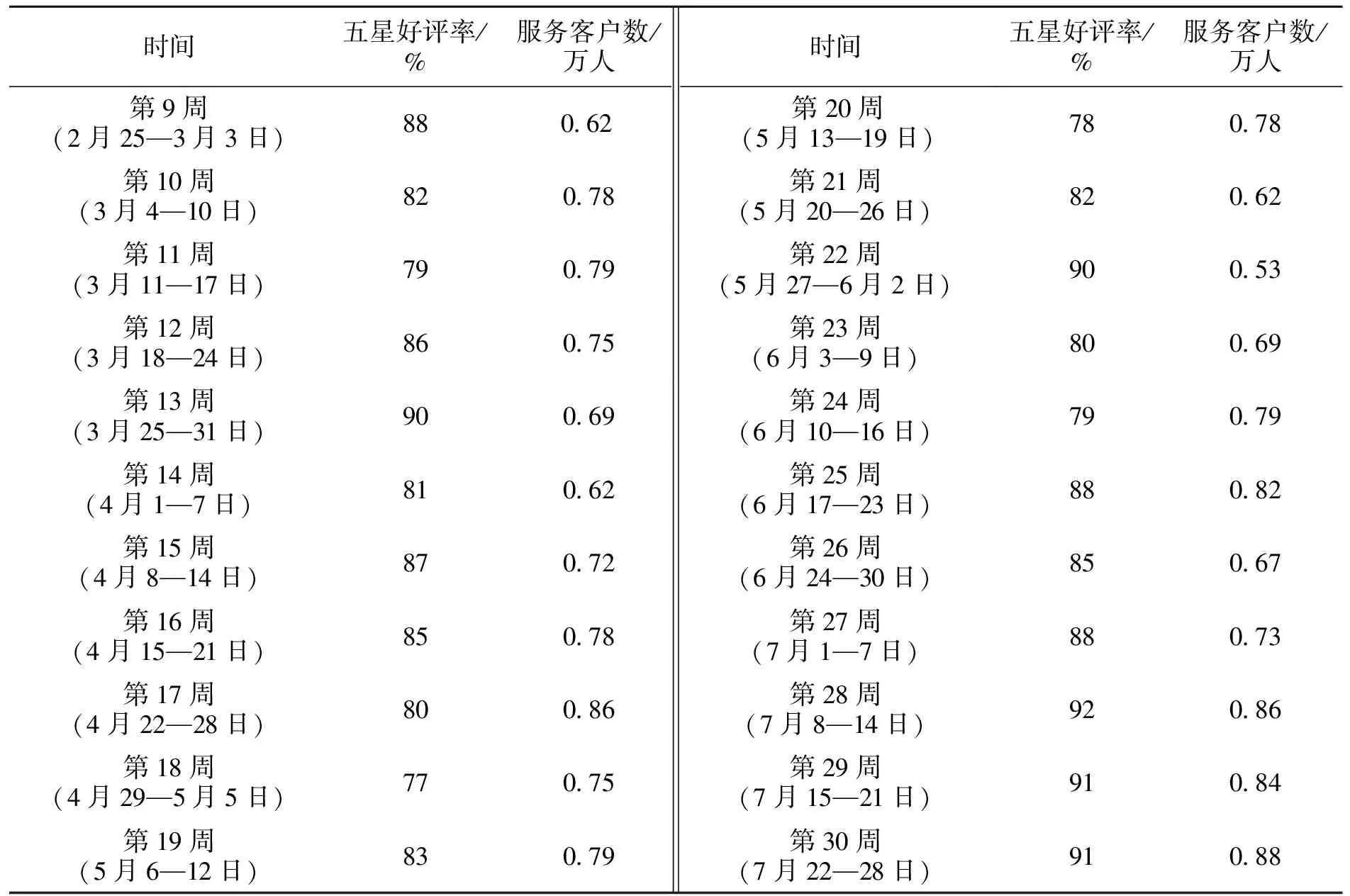
表4 DF物流2019年五星好评率部分数据
1.设立原假设与备选假设
从表4中的数据可以看出,DF物流每周的五星好评率都有波动,如果不对数据进行数理分析,就无法判断第28周经过培训后的五星好评率的增加是正常的数据起伏还是有显著提高。针对此问题,可将原假设设立为:第28周的五星好评率没有显著提高;将备选假设设定为:第28周的五星好评率有显著提高。
2.数据统计量分析
具体分析时,可将第28周的数据与前期所有数据的五星好评率数据进行一一对比,分析第28周数据变化的显著性。篇幅有限,本次分析只选取第28周与第27周的数据对比分析为例,实际工作中可借助分析软件实现所有历史数据的对比分析,提高分析精度。
由于五星好评率指标是消费者群体比例的一个指标,此种情况用P检验会更加适合。P检验的统计公式[6]128为:
(6)
式(6)中,P1和P2为两次被比较的数据,n1和n2为两次被比较数据的单位个体数。
把表4的数据代入式(6)中,得出:
(7)
3.研究统计量所处的区域
本次调查,DF物流希望了解的是第28周的培训是否有效。如果有效,第28周的五星好评率会显著高于前几周未培训时的五星好评率。统计量的值越大(在横轴上的位置越靠右),越不利于原假设(第28周的五星好评率没有显著提高)。因此,原假设的拒绝区域应设置在右边。DF物流在五星好评率方面能够接受的显著性水平为0.05。此次P统计量的自由度为(n1+n2-2)=(8.6+7.3-2)≈14。因为拒绝区域在右边,所以查T分布临界值表时应查找“单侧0.05,自由度14”的P值,查得临界值为1.761。
将计算得出的P值为0.017,与查表所得的临界值对比:由于0.017<1.761,统计量的值落在接受原假设的区域,因此接受原假设,即可以认为第28周的五星好评率没有显著提高,具体情况见图4。从这方面来看,第28周的培训效果并不理想。当然,有可能培训效果的显现有一定的滞后性,如果企业希望继续研究培训效果的滞后性,可以继续分析培训后的数据(如第29周、30周的数据)研究培训效果的滞后时间。篇幅所限,这里不再验证。
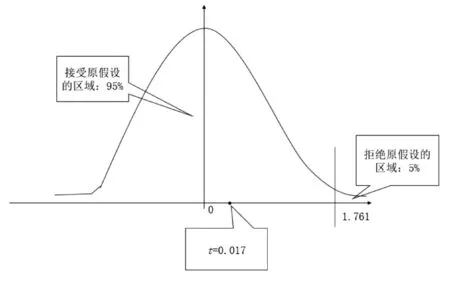
图4 五星好评率分析
三、结论和对策
通过对DF物流服务反馈数据的统计分析,可以判断DF物流在2019—2020年市场认可状况以及一些工作的实施效果,为今后企业的发展提供借鉴,同时针对数据分析所反映的情况采取相应措施,具体见表5。

表5 2019—2020年DF物流市场认可情况及工作实施效果
DF物流针对消费者行为反馈数据的分析结果,可相应采取以下对策。
1.前期采取的营销措施效果显著,接下来的工作中可以继续采取前期的营销措施并适当加大力度,同时继续调查营销财务数据与消费者的反馈数据;研究营销措施所产生效果的实时变化情况,及时根据消费者的反馈情况调整营销工作,使营销工作跟上市场变化,同时提高营销费用的投入产出效率。
2.通过调查得出DF物流与XD物流同处一个竞争层次的结论,这对企业接下来找准定位、制定竞争策略很有帮助。由于同处于一个竞争层次,因此在产品、服务、价格、市场占有率等方面都有可比性,企业在研发服务种类、制定产品价格、市场细分等方面都应参考XD物流的相应举措,精准制定企业的产品策略、渠道策略,以提升企业竞争力。
3.从五星好评率的反馈调查得出的结论是:企业的培训效果并不显著。这说明前期采取的培训方式或培训内容不适合本企业的情况,或者员工对培训内容的接受程度、执行程度不理想。接下来,企业应着手对前期培训的方式和内容进行研究,对员工接受培训后的工作行为进行调查,查找出问题并进行整改。
根据消费者行为反馈大数据所分析出来的结果采取对应的解决措施,如此制定出来的决策更加准确、更加符合客观实际情况,可帮助企业健康、快速成长[7]。因此,消费者反馈行为的大数据分析是企业经营决策的依据,应该纳入到企业日常工作中。
四、结束语
除本文所列举的企业链接点击率、在同类服务中选择的次数、物流服务五星好评率外,企业还可以对其他消费者行为信息进行大数据分析[8],例如搜索引擎中被搜索的次数、企业名称在输入法词组中出现的比率、企业公众号推送信息被点击阅读的次数等。在分析过程中,首先根据自身需要设置原假设与备选假设;其次根据数据类型灵活选择合适的统计模型并计算统计量;最后把统计量与统计模型的临界值对比,判断统计量所处的区域,从两个假设中选出正确的一个作为结论。这种调查方法信息来源可靠,结论准确,调查成本低,是适合大多数企业进行市场调查的方法。
