基于国产高分数据的森林蓄积量反演研究
2021-08-05许晓东龙江平
肖 越,许晓东,龙江平,林 辉
(1.中南林业科技大学 林业遥感信息工程研究中心,长沙 410004;2.林业遥感大数据与生态安全湖南省重点实验室,长沙 410004;3.南方森林资源经营与监测国家林业与草原局重点实验室,长沙 410004)
传统的森林蓄积量估测主要以抽样调查为主,耗时费力,对森林生态环境有一定的破坏[1]。遥感技术的发展及其多时间分辨率和多空间分辨率的优点,改变了传统森林资源调查的方式,实现了对森林蓄积量连续性、大范围的动态监测[2-4]。目前,国内外学者运用遥感技术对森林蓄积量进行反演做了大量研究,按照数据源的不同主要分为三类:一是光学遥感数据(SPOT系列,LANDSAT系列,MODIS及国产高分卫星等)[5-7];二是机载激光雷达数据[8-9;三是合成孔径雷达数据(ALOS-PALSAR、Radarsat-2等)[10-12]。受制于机载激光雷达和合成孔径雷达的数据获取能力及覆盖不连续等问题,目前基于高空间分辨率的光学影像实现森林蓄积量的遥感反演更具有潜力和推广意义。
随着遥感技术和机器学习算法的飞速发展,森林蓄积量反演模型也从传统的单变量、多变量的线性模型演变为以KNN、随机森林、神经网络等为代表的机器学习模型[13-15]。在森林蓄积量的估测过程中,建立合适的函数模型决定了估计精度[16]。因此,机器学习算法应用于反演模型中的研究不仅对森林蓄积量估测有着重大意义,对于森林资源动态监测也有着重大影响。王海宾等[17]应用高分一号影像,构建偏最小二乘模型和KNN模型对北京市延庆区的森林蓄积量进行估测,结果表明基于KNN法建立的蓄积估测模型要好于偏最小二乘模型;张苏等[18]以国产高分一号为遥感数据源,采用多元线性回归和支持向量机回归方法开展亚热带针叶林蓄积量估算效果评价研究,结果表明支持向量机回归(SVR)模型估测蓄积量的精度要明显优于多元线性回归模型;刘唐等[19]基于LANDSAT-TM影像以及DEM数据,采用BP神经网络方法构建区分立地质量的森林蓄积量遥感估测模型,结果表明同等条件下,BP神经网络模型的预测精度及R2均优于多元线性回归模型。然而,不同模型对森林蓄积量估测的敏感程度和精度还存在不确定性。本文以内蒙古的旺业甸林场为研究区,利用国产高分二号影像,构建多元线性回归(MLR)、多层感知机(MLP)、K-近邻(KNN)、支持向量机(SVR)和随机森林(RF)等5种不同模型估测森林蓄积量,分析高分二号影像遥感因子和估测模型对森林蓄积量反演的敏感程度和响应过程。
1 研究区概况
旺业甸林场位于内蒙古赤峰市喀喇沁旗西南部,地处燕山山脉北麓七老图山支脉,是茅荆达坝次生林区的重要组成部分之一,地理坐标为北纬41°21′~41°39′,东经118°09′~118°30′。林场主要地形地貌为中山山地,地势西南高东北低,平均海拔800~1 890m。年均降水量300~500mm,主要集中在7—8月份,年蒸发量2 000mm,为明显的大陆季风性气候。土壤以典型棕壤为主。旺业甸林场的有林地面积2.33万hm2,其中人工林1.16万hm2,天然林1.17万hm2,活立木总蓄积量152.7万m3[20]。人工林树种以落叶松(Larixprincipis-rupprechtiiMayr)、油松(Pinustabulaeformis)、樟子松(Pinussylvestris)等为主,天然次生林树种以白桦(Betulaplatyphylla)等为主。
2 材料与方法
2.1 实验方案设计及地面数据获取
地面样地数据依据海拔、龄组、蓄积量、树种等因素采用系统布点。首先在旺业甸林场范围内平均划分为22个格网,在每个格网内选择1个对林分有充分代表性的样地作为中心样地,再在中心样地的附近寻找3个常规样地,共设计了88个样地。样地调查时间为2019年9月5日至2019年9月20日,样地大小设置为25m×25m。在每个样地中,利用高精度GNSS测定地面样地的角点和中心点位置。在样地内,采用每木检尺的方法测量胸径、树高、东西冠幅、南北冠幅及枝下高等参数。根据当地提供的树种二元材积表计算出样地内每株木的材积,统计得到每个样地的蓄积量。地面调查样地88块,其中油松样地45块,落叶松样地41块,樟子松样地2块。有2个样地的遥感图像被云层覆盖,故有效样地为86个。
2.2 遥感数据
采用国产高分二号影像数据。高分二号卫星搭载了2台高分辨率1m全色、4m多光谱相机,包含4个波段,飞行海拔高度631km,轨道倾角97.9080°,重访周期5 d。本次研究的数据获取时间为2019年5月29日和2019年6月23日,共4景影像。
为了提取遥感因子,首先对高分二号影像数据进行辐射定标、大气校正、正射校正、几何校正、图像融合、图像裁剪等一系列预处理,为了与样地大小相匹配,将影像重采样至25m分辨率,处理结果如图1所示。
2.3 遥感因子提取
提取高分二号影像中4个单波段反射率因子、波段运算得到的12个植被指数因子(NDVI,DVI,EVI,ARVI等)及每个单波段的8种纹理因子即均值(Mean)、方差(Variance)、协同性(Homogeneity)、对比度(Contrast)、相异性(Dissimilarity)、信息熵(Entropy)、二阶矩(Second Moment)和相关性(Correlation),共计48个遥感因子。植被指数的计算公式如表1所示。利用Pearson相关系数法筛选出与森林蓄积量相关性较高的遥感因子参与建模。

表1 植被指数计算公式
2.4 森林蓄积量估测模型的构建
通过Pearson相关系数法筛选出来的高分二号遥感因子与实地调查的森林蓄积量联合建立多元线性回归模型(MLR)、多层感知机(MLP)、K-近邻(KNN)、支持向量机(SVR)、随机森林(RF)5种森林蓄积量估测模型。
传统的多元线性回归(MLR)主要包括2个或2个以上自变量,以自变量的最优组合为基础来实现模型对因变量的预估,可解释性强,但对于非线性数据或者数据特征间具有相关性的多项式回归难以建模;而机器学习模型能有效的解决这一问题,多层感知机(MLP)是由输入层、隐藏层和输出层构成,隐藏层可以包含一层或多层,每个隐藏层都可以通过激活函数对输出进行变换,多层感知机的层数和各隐藏层中隐藏单元个数以及激活函数的选择都是关键; K-近邻[21](KNN)是一种根据K个最近邻居的加权平均值来预测样本的方法,其关键点在于如何选择最佳的K值;支持向量机[22](SVR)是将输入空间通过非线性变换映射到一个高维空间,在高维空间中通过线性回归超平面从而解决低维空间中的非线性问题,其关键在于核函数的选择和惩罚参数的设定;随机森林(RF)是由决策树的思想衍生而来的,最早由Leo Breiman和Adele Cutler提出[23],其主要思想是利用有放回抽样的不同样本训练不同的决策树,最终得到所有决策树结果的平均值,其参数设置主要考虑决策树的个数。
2.5 精度评价
构建森林蓄积量反演模型采用分层随机抽样的方法,按森林蓄积量的分布情况将样地划分为3层,并从中随机选取2/3的样本(57)作为训练样本,1/3样本(29)作为验证样本。为了评价不同模型的估测能力,选择决定系数(R2),均方根误差(RMSE)和相对均方根误差(RRMSE)作为评价指标[24],其中,决定系数R2,均方根误差RMSE和相对均方根误差RRMSE的计算公式如下:
(1)
(2)
(3)
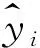
3 结果与分析
利用国产高分二号数据所提取的遥感因子,经Pearson相关系数法筛选后,结合5种不同模型估测森林蓄积量,得到基于GF-2数据的森林蓄积量最优反演模型,并绘制研究区内森林蓄积量空间分布图。
3.1 遥感因子的筛选
利用Pearson相关系数法筛选遥感因子,筛选出与森林蓄积量在0.01显著水平上显著相关的遥感因子8个,分别为Band1,Band2,Band3,ARVI,B1_Mean,B2_Mean,B3_Mean,B4_Mean,其相关系数如表2所示。

表2 变量和森林蓄积量的相关性
表2中,Band1,Band2,Band3分别为高分二号影像蓝色、绿色、红色波段的灰度值,ARVI为大气抗阻植被指数,B1_Mean,B2_Mean,B3_Mean,B4_Mean分别为蓝色、绿色、红色和近红外波段纹理滤波中的均值。高分二号影像中的绿色波段灰度值与森林蓄积量的相关性最高,其相关系数达到了0.453。
3.2 模型估测结果与精度评价
利用验证样本对5种森林蓄积量反演模型进行精度分析与评价,结果如表3所示。
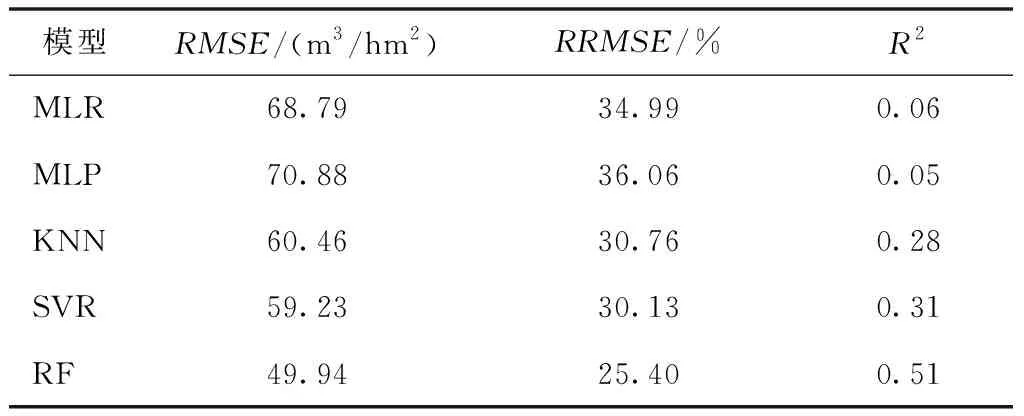
表3 估测模型精度评价
由表3分析可知,在5种森林蓄积量反演模型中,随机森林模型的拟合效果最好,估测精度最高,达到了74.60%;支持向量机模型的拟合效果次之,估测精度为69.87%;多层感知机模型和多元线性回归模型的拟合效果最差,估测精度分别为63.94%和65.01%。
通过绘制随机森林模型预测值与实测值散点图及残差图来进一步检验模型的拟合效果,结果如图2所示。
由图2可知,随机森林模型能够较准确地估测森林蓄积量,残差分布较为随机且无规律,模型拟合效果较好,较为稳定,预测精度最高,是最优的森林蓄积量反演模型。
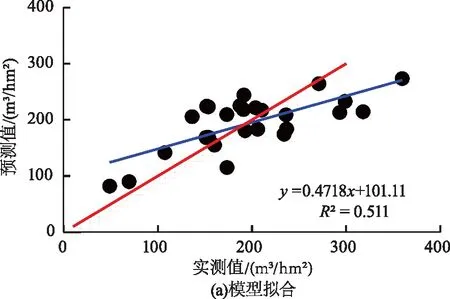
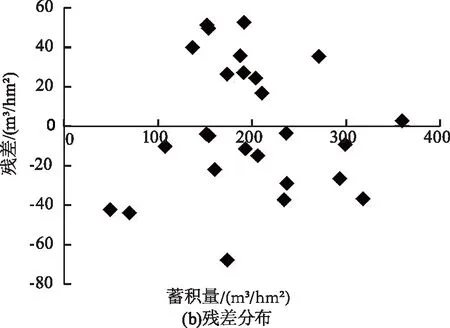
图2 随机森林模型拟合结果与残差分布图
3.3 森林蓄积量的空间分布
基于高分二号影像提取光谱因子、植被指数因子及纹理因子,经Pearson相关系数法筛选出8个因子作为自变量,利用构建的随机森林回归模型估算整个研究区的森林蓄积量并得到研究区内森林蓄积量的空间分布图,结果如图3所示。

图3 森林蓄积量反演图
从图3可以看出,森林蓄积量分布较高的地区主要集中在研究区的西部和东南部,其估值大多为200~300m3/hm2,而森林蓄积量分布较低的地区主要集中在研究区的西北部、中部和北部,其估值大多为0~100m3/hm2。这是因为西部及东南部地势较高,植被分布较为集中,人为活动较少,因此森林蓄积量较高;而西北部、中部及北部地势相对来说较为平坦,人为活动相对集中,因此蓄积量较低。研究区的森林蓄积量反演图符合实际调查结果,能够反映研究区内真实的森林蓄积量空间分布情况。
4 结论与讨论
4.1 结论
1) 高分二号影像用于森林蓄积量估测的最佳特征变量为Band1,Band2,Band3,ARVI,b1_Mean,b2_Mean,b3_Mean,b4_Mean。此外,利用高分二号影像提取出的基于二阶矩阵的纹理因子中均值(Mean)与森林蓄积量具有较高的相关性,说明高分二号影像的纹理因子能提高森林蓄积量的估测精度。
2) 随机森林相对于多元线性、多层感知机、K-近邻、支持向量机等方法具有更高的森林蓄积量估测精度。在5种森林蓄积量估测模型中,随机森林回归模型的估测效果最好(RMSE=49.94m3/hm2,RRMSE=25.40%,R2=0.51);支持向量机回归模型次之(RMSE=59.23m3/hm2,RRMSE=30.13%,R2=0.31);多层感知机模型和多元线性回归模型效果最差。
4.2 讨论
1) 使用光学遥感影像进行森林蓄积量的估测时,天气对于影像的质量具有很大的影响。本次实验地面样地的调查时间为2019年9月份,而9月份前后的高分二号影像受天气等因素的影响质量很差,因此所使用影像的获取时间为2019年5—6月份,中间间隔3个多月,这可能会对实验结果产生一定的影响。
2) 使用国产高分二号影像估测森林蓄积量时,在森林蓄积量为300m3/hm2左右会出现光饱和情况,产生低估现象。今后可考虑使用SAR数据与之相结合提高高蓄积量区域的估测精度。
3) 随机森林算法在反演森林蓄积量方面具有一定的潜力。随机森林在小样本的情况下对森林蓄积量表现出了较高的估测精度。随着算法的不断发展和完善,该算法在森林蓄积量估测甚至林业上将会取得更多的成果。
4) 本次研究区位于中温带区域,所选择的样本仅为研究区内的优势树种,所以实验结果对人工针叶林的蓄积量估测具有一定的参考意义,对其他地区及其他树种的蓄积量估测是否适用有待进一步研究。
