光谱信息支持下城区林地信息提取方法
2021-08-05林双双钟九生段纪维代仁丽何志远
林双双,钟九生,何 鑫,江 丽,段纪维,代仁丽,何志远
(贵州师范大学 地理与环境科学学院,贵阳 550025)
林地现状信息实时、准确获取,对人类的生产经营具有重要的指导意义[1]。传统的高精度林地信息获取主要是通过人工目视解译勾绘得到,这种方式虽然较为准确,但非常耗费人力成本,导致其提取结果利用价值降低。现存的林地信息自动提取方法主要有基于像元的方法[2]、面向对象的方法[3]、基于新型红/黄边波谱信息的方法[4]和基于深度学习的方法[5-6]。随着研究的进展和计算机性能的改进,运用这些方法提取的林地信息在精确性和时效性上也有很大提升。但在现实地物纷繁复杂的情况下,这些方法仅用单一的模式来构建地物信息,始终难以达到人工目视解译的效果。因此,迫切需要快速、准确的技术方法来提高林地信息提取的实时性和准确性。
随着遥感技术的不断提高,遥感影像所能呈现的地物信息也更加详尽,这给地物信息的高效提取提供保障的同时,也带来了数据量大、信息冗余、地物纹理/光谱信息复杂等问题。面对这些问题,李青等[7]通过分析支持向量机的机理,提出了基于向量投影的支撑向量预选取方法,从样本去冗余的角度有效减少训练样本,提高了训练速度;刘巍等[8]借助地理学上的分区分层思想,用地貌单元作为约束条件,分层提取耕地信息,有效减少了提取的错误率;邹橙等[9]提出了新综合水体指数法(NCWI)来增强水体区域信息,随后结合其他方法确定最佳水体分割阈值,提高了水体提取精度。
本文尝试对区域特点进行分析,借助光谱信息对数据进行预处理,结合深度学习技术的优势,对林地信息进行提取。以我国西南山区城市为例,其城区林地分布有不平衡的特点:靠近城市中心,人地矛盾紧张,土地用途大多为商业或住宅用地,林地分布较少且相对破碎,距城市中心越远,林地分布也逐渐增多,在城市外围,林地呈集中连片分布;此外,城市信息与林地信息在遥感影像上的光谱特征差异较大,导致这两类地物在遥感影像上易于被分离。针对这一特点,可以借助光谱信息预先对研究区的非林地信息进行剔除,这一处理在减少数据处理量的同时,使选取的训练样本也更趋于平衡。
1 研究区概况
研究区涉及贵阳市的云岩区、观山湖区和白云区,本文选取12 800×12 800像素大小作为研究区。贵阳市位于贵州省中部的云贵高原东斜坡地带,地处北纬26°11′ ~26°55′,东经106°07′ ~107°17′,海拔约 1 100 m[10],位于长江与珠江分水岭地带,乌江支流南明河上游,属于亚热带湿润季风气候[11],年均气温15.3℃[12],年均降水量1 174.7mm[13],城市森林覆盖率达37.4%[14]。
2 研究方法
2.1 数据预处理
采用的实验数据为2020年11月13日由高分二号(GF-2)卫星获取的遥感影像数据,该数据由空间分辨率为1 m的全色和空间分辨率为4m的多光谱影像组成,其中多光谱影像含盖了红光、绿光、蓝光和近红外光4个波段。影像首先进行辐射定标、大气校正、正射校正等预处理,为获取更高分辨率的遥感数据,将全色和多光谱影像进行融合,最终得到空间分辨率为1m的多光谱影像,并计算其归一化植被指数(NDVI)。
2.2 提取流程
根据林地在城区的分布特点,设计如下流程:1)对研究区NDVI值进行观察,选取合适的林地阈值提取林地信息,形成林地初步成果;2)生成合适大小的全覆盖渔网图块,将图块与林地初步成果进行叠加,划分林地区域和非林地区域,同时将林地区域渔网图块对研究区影像进行分割,使林地提取模型可以分块处理林地信息,减轻机器压力;3)运用深度学习模型对样本进行训练,训练好的模型对上一步分割好的影像进行林地提取;4)将分块提取结果进行融合,得到林地空间分布图。具体流程如图1所示。
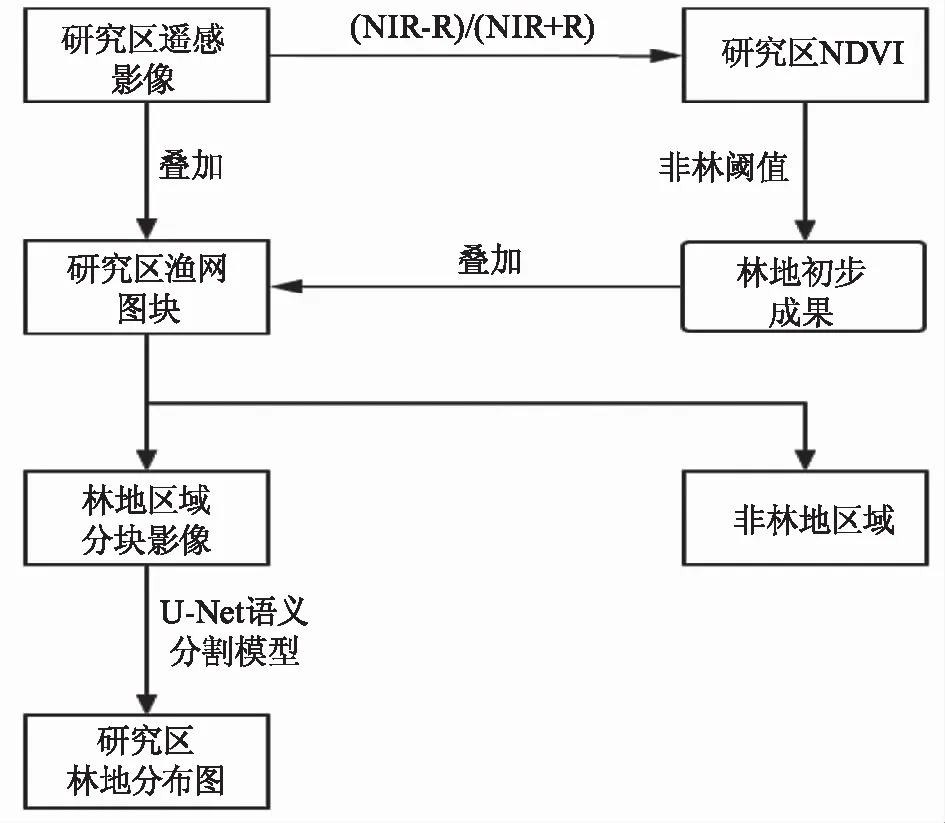
图1 光谱信息支持下的林地提取流程
2.3 NDVI阈值法提取林地信息
NDVI[15]是反映地表植被覆盖情况的数学指标,而林地作为植被的一种,在红波段有较强的吸收能力,在近红外波段具有较强的反射率,因此林地的NDVI值较大。其计算公式为:
NDVI=(NIR-R)/(NIR+R)
(1)
式中:NIR为近红外波段;R为红光波段。
在林地信息的提取中,可以选取合适NDVI阈值[16],将地物信息划分为林地与非林地区域,得到林地初步成果。此方法提取得到的林地信息,因“同物异谱”和“同谱异物”的原因,存在大量“椒盐现象”和较多不合理孔洞,需进一步处理。
2.4 林地与非林地区域划分及样本制作
针对城区林地分布不平衡这一特点,对研究区生成 10 000个覆盖全区的128×128像素大小的渔网图块,并将这些图块与上文得到的林地初步成果进行叠加,剔除掉 3 933个非林地区域图块,这一步操作在减少数据处理量的同时,使得接下来抽取的样本也更趋于均衡,保证了样本的典型性、分布均匀性及充足性。
用林地区域渔网图块对研究区影像进行分割处理,形成 6 067个待预测影像,并从这 6 067个渔网图块中,随机抽取200个训练样本和60个测试集用于模型训练,样本的勾绘是在林地初步成果图斑的基础上进行孔洞融合、噪声去除和边界调整等少量改动,有效减轻了样本制作的工作量。
2.5 U-Net语义分割模型提取林地信息
U-Net模型[17]最初是为医学图像分割设计的,随后因其简洁的结构以及显著的效果在许多领域都得到了应用。该模型使用卷积层替换掉全连接层,使得图片的输入与输出拥有一致大小。模型包含1个下采样特征提取过程和1个上采样特征联合过程,致使输出能够保留上下文空间特征,实现图像像素级别端到端的预测,能有效减少信息损失。
U-Net因其特有的网络结构,适用于大尺度的分割任务,本文在大量剔除了非林地信息的干扰后,林地信息的分布在128×128像素大小尺度上,属于大尺度分布的地类,因此选用U-Net网络模型对林地与非林地信息进行分割。
3 结果与分析
3.1 林地空间分布
使用上述方法,最终得到研究区林地空间分布图(图2)。
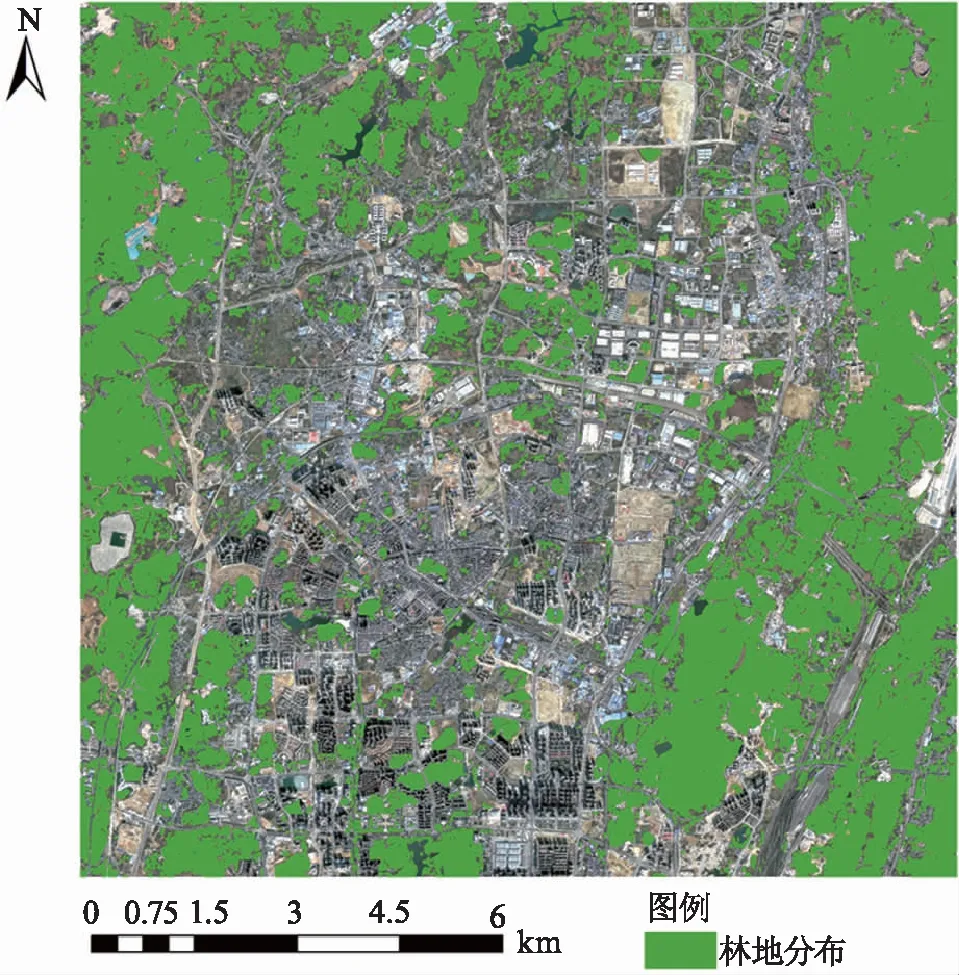
图2 研究区林地分布图
为探究本文方法改进效果,参考第三次全国国土调查林地分类标准,对研究区的林地信息进行人工标注,以此作为林地真实值,后截取3个512×512像素大小的区域进行对比分析,如图3所示。

图3 林地提取结果对比分析图
由林地提取结果对比分析图可知,本文方法提取的林地结果与真实林地标注较为接近,有少量精度的损失主要是在林粮间作或植被成熟度较高的耕地区域;相较而言,仅对整个研究区采用单一的深度学习模型的方法,因其没有对所需信息进行预处理,导致处理区域较大,随机抽取的样本平衡程度低,因此在一些光谱信息与林地较为相似的非林地区域提取效果不如本文方法;再将本文方法与NDVI阈值法提取的林地结果进行对比,NDVI阈值法由于“同物异谱”和“同谱异物”的原因,提取的结果较为破碎,且存在很多“椒盐噪声”现象,本文方法有效避免了此类问题。
3.2 精度评价与分析
在对局部信息进行分析的基础上,为了定量对比本文方法较其他方法的优势,选取总体分类精度(OA),Kappa系数和交并比(IoU)3个得到广泛认可的指标作为提取精度衡量,计算公式如表1所示。

表1 精度评估计算公式
被用来与本文方法进行比较试验的方法包括基于U-Net方法和基于NDVI阈值方法,计算结果如表2所示。
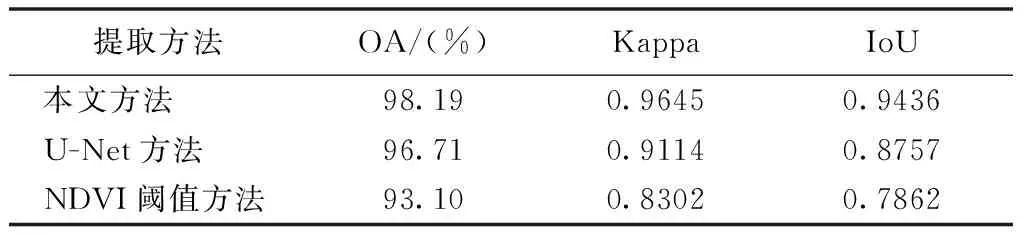
表2 3种方法的定量评价指标对比
综上计算结果可知,本文方法对林地信息的提取精度优于其他2种方法,其中总体精度比U-Net方法和NDVI阈值方法分别高1.48%和5.09%;Kappa系数比U-Net方法和NDVI阈值方法分别高5.31%和13.25%;IoU比U-Net方法和NDVI阈值方法分别高6.79%和15.74%,这些精度指标的提升,说明本文方法具有较为明显的优势。
4 讨论与结论
自然界在某种范围和等级之中,没有完全相似的现象,也没有绝对差异的现象[18],进而地表特征具有多样性和复杂性,所映射的遥感影像也呈现这样的特性,如果不考虑地表本身的特点、意图,使用单一模型对地物信息进行提取,往往很难得到较高精度的结果。本文在对城区林地进行提取之前,考虑到了城区存在大量与林地差异较大的地物,如果能在数据处理之前将这些非目标信息排除,可以大大减轻模型训练的处理难度,使得提取过程在时间和精度上有更好的表现。本文也存在一些可以进一步探究的地方,主要为以下几个方面:
1) 本文借助光谱信息的帮助,对地物信息进行预处理,虽然在精度上相较以往方法有所提高,但是还会存在一些精度的损失,这些损失主要集中在林粮间作和植被成熟度较高的耕地区域,此类地物在波谱信息和纹理上与林地均有较高的相似性,因此误差难以完全避免,后续工作中有望采取其他方法进一步提高提取精度。
2) U-Net模型可以通过少量样本得到较好效果,本文抽取总研究区面积2%的数据量作为样本,实际上还存在较多样本冗余,未来工作中可以尝试在保证精度的同时减少训练样本的采集量,也可以针对不同样本特征,尝试不同的损失函数进行试验。
3) 本文仅使用了一种深度学习模型,后续工作可以对区域特征进一步分析研究,选取合适的多种模型组合进行地物提取,使模型有更好的区域针对性。
