基于分组遗传算法的集成多样性增强及其应用
2021-08-05陈双叶符寒光
陈双叶,赵 荣,符寒光
(1.北京工业大学信息学部,北京 100124;2.北京工业大学材料科学与工程学院,北京 100124)
在复杂的工业生产过程中,产品的质量参数往往需要抽取部分产品经过实验室检测得到,需要投入大量的人力、物力,而且具有很强的滞后性.通常这些滞后性较大的变量会采用软测量模型进行预测,但在实际应用中,由于生产环境的变化,会造成工艺参数的动态变化,这在机器学习领域称为概念漂移[1].概念漂移主要由数据的分布变化导致[2],目前共存在3类处理概念漂移的方法,包括滑动窗口技术[3]、漂移检测技术[4]和集成学习技术[5].滑动窗口技术仅仅保留最近的样本来帮助当前数据的学习;漂移检测技术通过检测概念的漂移来触发模型的更新;集成学习技术通过各个模型的组合可以方便地适应概念漂移后的新数据分布.
研究表明,集成学习具有较好的概念漂移处理能力[6].集成学习是一种通过组合多个基学习器以提高整体泛化性能的有效方法,该方法能很好地适应数据分布的变化.准确性和多样性是集成的2个重要特征[7],目前研究大多只关注集成学习器的准确性,而忽略了集成中基学习器间的多样性对集成泛化性能的影响.在过去的20多年中,多样性一直被认为是设计集成的主要推动力[8].研究者提出许多方法用于提高集成学习中基学习器间的多样性.Breiman[9]提出的Bagging算法通过对训练样本重采样生成基学习器训练子集的方式[10],得到差异较大的基学习器;Freund等[11]提出的Adaboost算法在训练基学习器的过程中,会逐步增加误分类样本的权重[12],从而调整训练集分布,使得基学习器预测能力能够相互补偿;Breiman[13]提出随机森林(random forest,RF)算法在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机特征选择[14],增加基学习器间的差异性;Chen等[8]提出基于合成邻域生成的集成学习(ensemble learning based on synthetic neighborhood generation,ESNG)算法,通过随机生成属性值改造数据集的方式来促进基学习器间的多样性.
本文提出一种基于分组遗传算法的多样性增强方法,该方法在以在线极限学习机(online sequential extreme learning machine,OS_ELM)为基学习器构建Bagging集成的基础上,在滑动窗口数据上,通过分组遗传算法对基学习器进行分组并对其参数执行杂交、突变和选择操作,从而提高集成中基学习器间的多样性.
1 算法描述
一个有效的集成应该尽可能多地包含准确且多样的基学习器,本文根据基学习器在滑动窗口数据的准确性和多样性对其进行分组,共分为4组:准确性高且多样性高(AD)、准确性高但多样性低(Ad)、准确性低但多样性高(aD)、准确性低且多样性低(ad).通过引进遗传算法,试图增加集成中准确且多样的基学习器数量,从而提高集成的泛化性能.该方法如图1所示,共分为4个阶段:离线建模、在线更新、进化操作和集成输出.
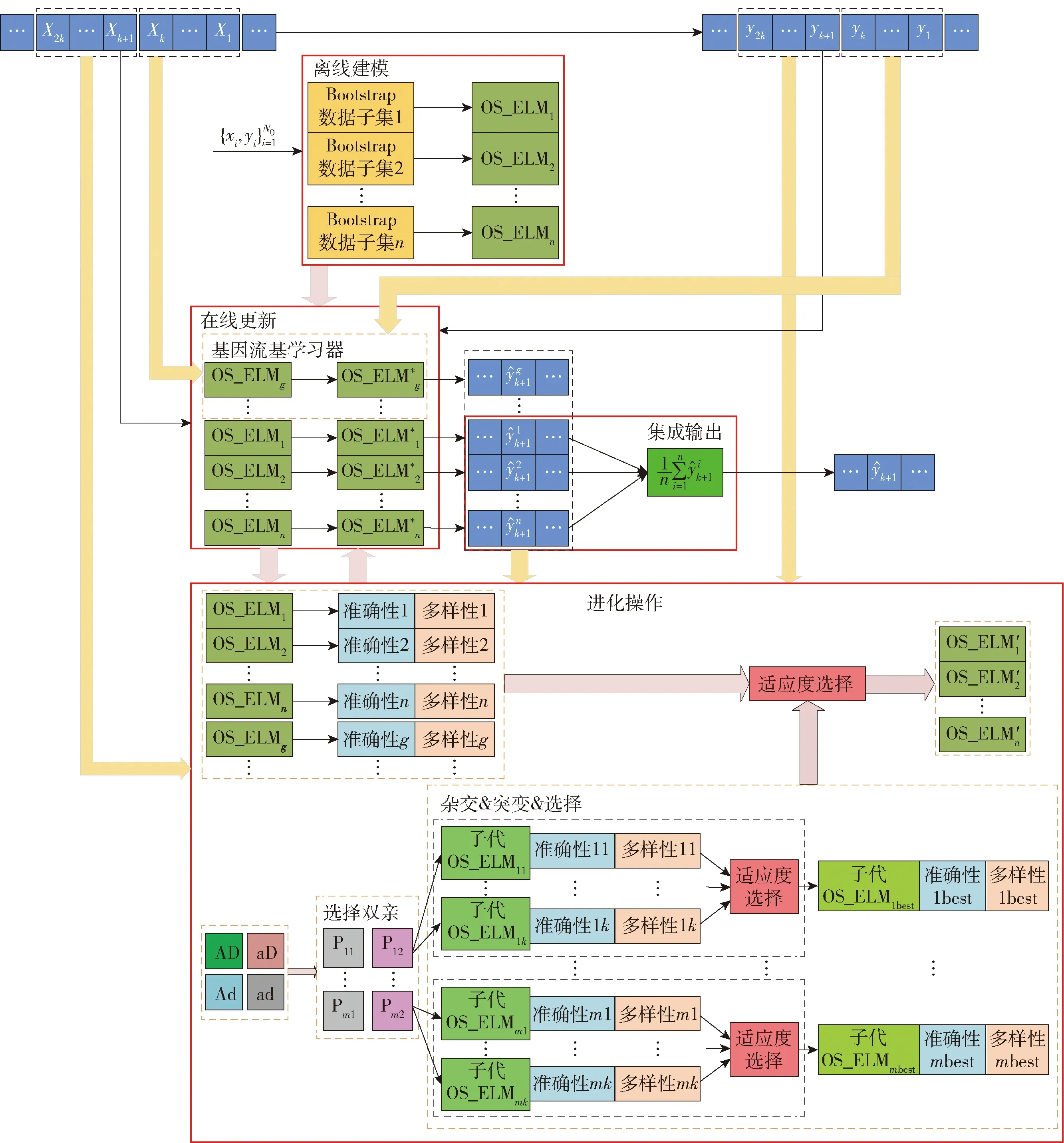
图1 基于分组遗传算法的集成在线极限学习机(GGAEOS_ELM)建模策略Fig.1 Proposed modeling strategy of ensemble OS_ELM based on grouping genetic algorithm(GGAEOS_ELM)
1.1 离线建模
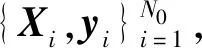
yi=φ(XiWd×L+b1×L)βL×1,i=1,…,N0
(1)
式中:φ(·)为激活函数;Wd×L和b1×L分别为输入权重矩阵和偏移量向量;L为隐含层神经元节点个数;βL×1为输出权重向量.Wd×L和b1×L由计算机产生的随机数组成.因此,确定OS_ELM模型只需计算出输出权重向量βL×1.设隐含层的输出为H0,则等式(1)可重写为
Y0=H0β0
(2)
式中
则输出权重向量可确定为
(3)
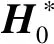
1.2 在线更新
在线场景中,离线建立的模型可能不能适应数据流的变化,导致模型的整体性能变差,通过模型的在线更新,即更新输出权重向量来应对概念漂移带来的影响.
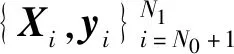
(4)
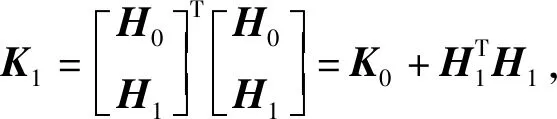
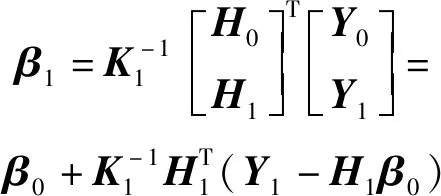
(5)
采用递归的思想,当第Nk+1个样本到达时,中间参数Kk+1和输出权重向量βk+1可表示为
(6)
(7)
1.3 进化操作
根据基学习器在滑动窗口数据中的准确性和多样性将基学习器分为4组,选择特定分组中的一对基学习器作为双亲,将基学习器的参数作为基因序列,通过进化操作产生准确且多样的子代基学习器用于集成.为了尽可能保留双亲中的优质基因,每对双亲每次进化会产生多个子代,选择适应度最高的子代用于集成.引入分组进化算法的目的如图2所示,即将ad中的基学习器向AD、Ad或aD中转移,将Ad或aD中的基学习器向AD中转移.
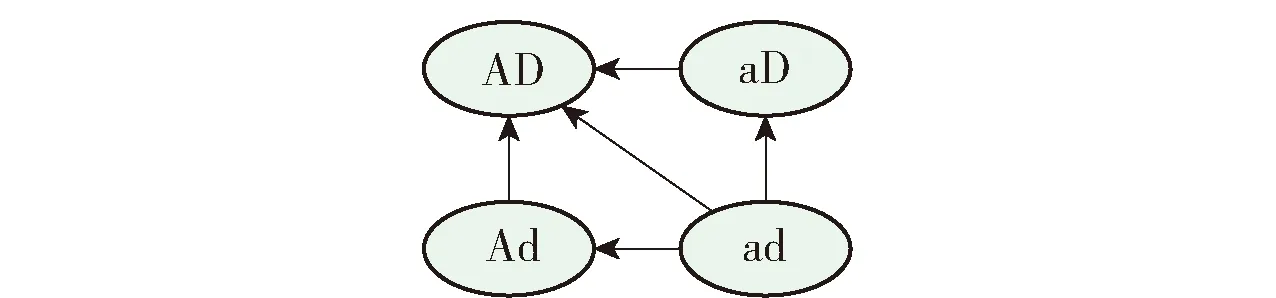
图2 引入分组进化算法的目的Fig.2 Purpose of introducing group genetic algorithm
AD中的基学习器只是在当前滑动窗口数据中性能较好,若数据发生概念漂移,可能也会表现出较差的性能;同样ad中的基学习器可能存在能够适应概念漂移的基因(参数),可以在概念漂移发生后快速适应新的数据.因此,根据表1中的条件选择双亲执行进化操作.

表1 选择执行进化操作的双亲Table 1 Choose parents to perform evolutionary operations
1.3.1 杂交操作
杂交操作是对2个基学习器的参数进行交换操作,本文是以OS_ELM构建的基学习器,其中输入权重矩阵Wd×L和偏移量向量b1×L由计算机产生的随机数组成,而输出权重向量βL×1通过计算得到,因此仅需对Wd×L和b1×L进行杂交操作.杂交操作如图3所示,图3中⊗表示杂交操作,图3(a)中cij表示Wd×L第i行中第j个交换参数的位置,图3(b)中cj表示b1×L中第j个交换参数的位置.每次双亲执行杂交操作将产生2个子代.
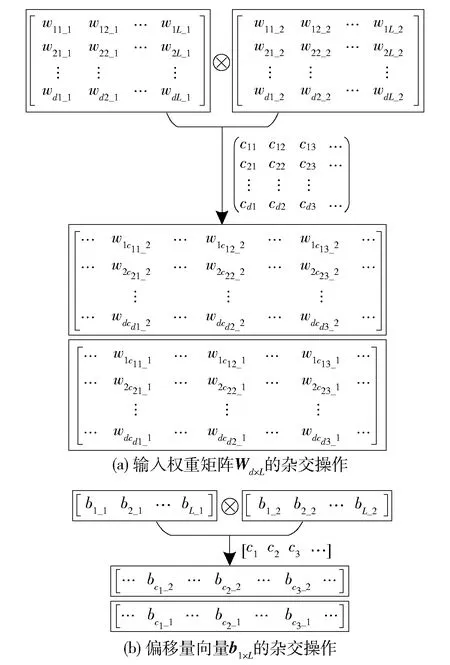
图3 基学习器的交叉操作Fig.3 Crossover operation of base learners
1.3.2 突变操作
突变操作是在杂交操作产生子代的基础上进行的,随机挑选一定比例的基因(参数)用随机值进行替换.突变操作如图4所示.图4(a)中mij表示Wd×L第i行中第j个突变参数的位置,图4(b)中mj表示b1×L中第j个突变参数的位置.
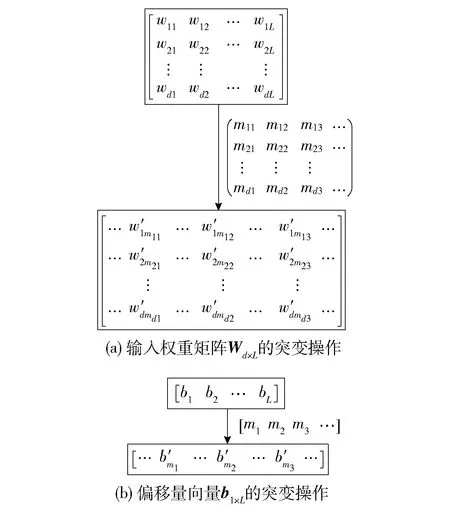
图4 基学习器的突变操作Fig.4 Mutation operation of base learner
对子代基学习器执行突变操作后,根据滑动窗口中的数据,计算出子代基学习器的输出权重向量βL×1,至此一个子代基学习器的构建完成.
1.3.3 选择操作
为了避免双亲优良基因(参数)的丢失,每对双亲会产生多个子代,并计算出每个子代基学习器的适应度值,挑选适应度值最大的子代基学习器用于集成选择操作.第i个子代基学习器的适应度计算公式为
Fi=wa×e-MSEi+wd×Di*
(8)
式中:MSEi为第i个子代基学习器在滑动窗口中的预测均方误差(mean squane error,MSE);Di*为第i个子代基学习器在滑动窗口中的多样性度量值;wa和wd分别为准确性和多样性对适应度的贡献量,且wa、wd满足wa+wd=1.
第i个子代基学习器在滑动窗口中的MSE计算公式为
(9)
式中:v为滑动窗口中样本的数量;fi(Xk)为第i个子代基学习器对样本Xk的预测值;yk表示样本Xk对应的真实值.
计算子代基学习器多样性度量值前,需先计算两两子代基学习器间的距离,第i个子代基学习器与第j个子代基学习器之间的距离计算公式为
(10)
则第i个子代基学习器的多样性度量值为
(11)
式中J为子代基学习器的个数.
1.3.4 基因流
为了增加集成中基学习器间的多样性,提高集成学习快速应对概念漂移的能力,本文引入基因流的概念,即在执行进化操作后,利用当前滑动窗口中的数据训练产生一定数量的基学习器——基因流基学习器.基因流基学习器不参与下一滑动窗口数据的集成输出,只参与下一滑动窗口数据的在线更新和进化操作,通过进化操作可以将基因流基学习器中的优良基因(参数)流入子代基学习器中.
1.4 集成输出
在本次滑动窗口中,通过计算集成中基学习器和执行进化操作产生的子代基学习器的适应度值,挑选出适应度最高的n个基学习器用于最终的集成输出.集成输出的计算公式为
(12)
2 实验与分析
2.1 数据集说明
2.1.1 合成数据集
为了验证模型处理概念漂移的能力,在实验中测试了3组不同类型概念漂移的合成数据集.合成数据集采用改进的Fried数据集,该数据集由Friedman提出的函数生成,函数中包含10个连续值属性,属性值由区间为[0,1]的均匀分布随机生成.其中只有5个属性值与目标值有关,其真实目标值的函数计算公式为
y=10sin (πx1x2)+20(x3-0.5)2+10x4+
5x5+σ(0,1)
(13)
式中σ(0,1)为标准正态分布产生的随机数.合成数据集的改进过程如表2所示.
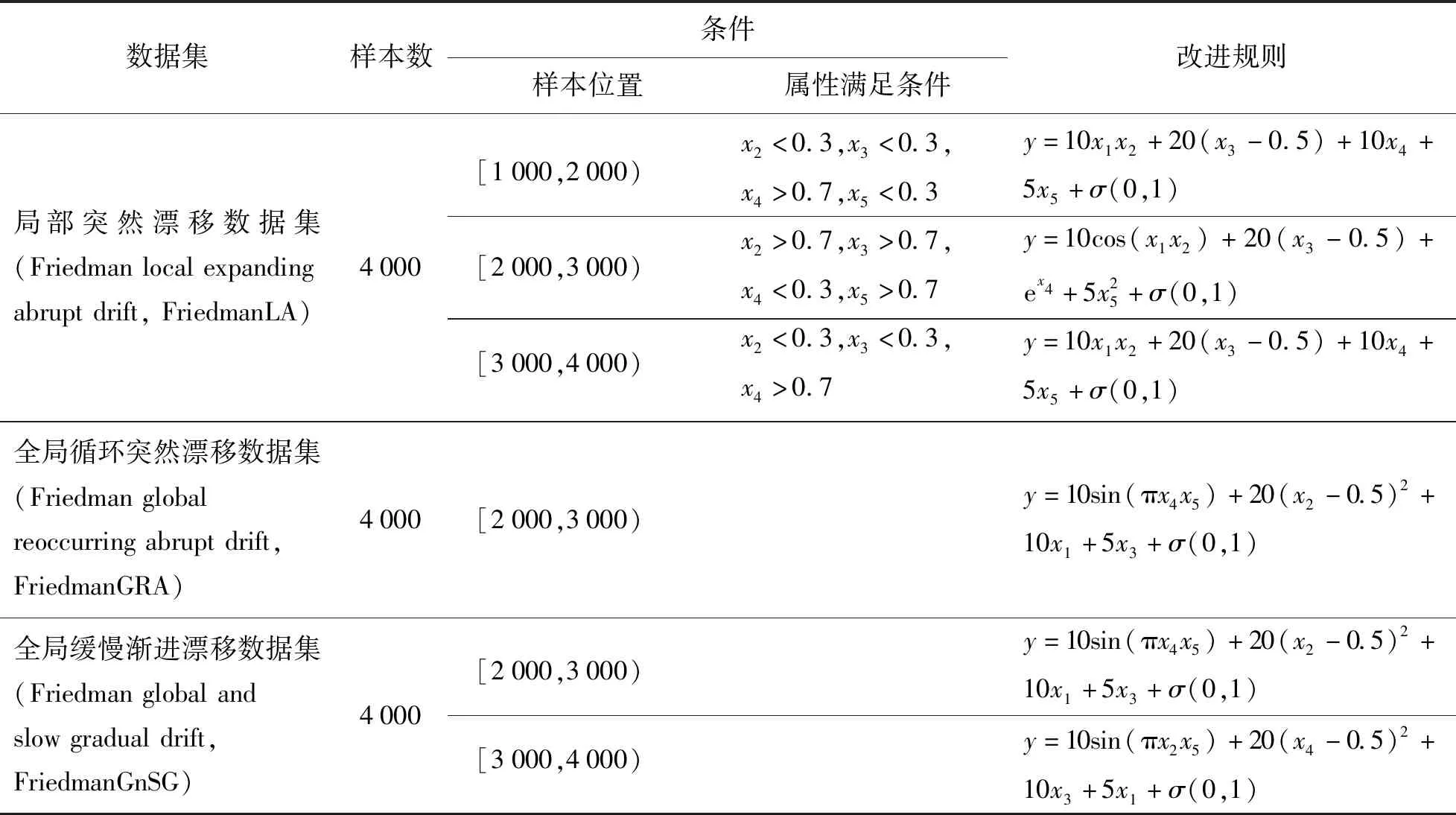
表2 合成数据集Table 2 Synthetic data sets
2.1.2 真实数据集
为了验证该方法在实际应用中能有效地减小模型的MSE,本实验选取了7组常用的真实数据集进行测试,结果表明在真实数据集上模型的性能表现较好,7组真实数据集的信息如表3所示.
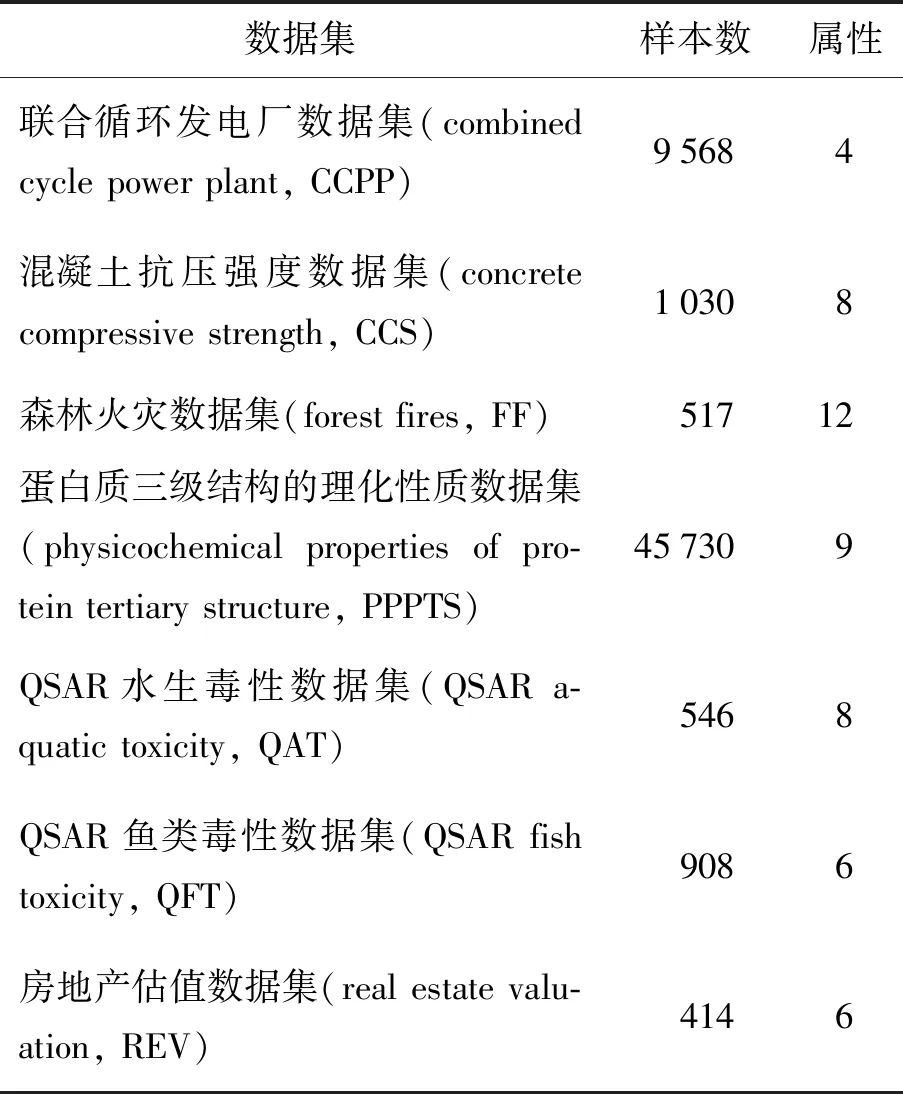
表3 真实数据集Table 3 Real-world data sets
2.2 实验设置
本实验是基于数据流在线更新基学习器,以滑动窗口执行分组进化操作,即在集成模型完成一个样本的预测,得到其真值后,更新各基学习器的参数,当预测的样本达到一定数量时,对基学习器进行分组进化操作.在进行杂交操作时,设置每对双亲产生的子代个数为20,每对参数的交叉概率Pc=0.5~1.0;在进行突变操作时,每条参数的突变概率Pm=0~0.05;在进行选择操作,计算各子代基学习器的适应度值时,令a=wa/wd.当a设置为0和1时,分别对应GGAEOS_ELM#1和GGAEOS_ELM#2.
本实验选取了RF、XGBoost、ESNG和EOS_ELM进行了对比实验,其中ESNG、EOS_ELM和GGAEOS_ELM均以OS_ELM作为基学习器,基学习器的数量设为20,隐含层节点个数设为25;RF和XGBoost以决策树作为基学习器,其数量也设为20.
本实验在合成数据集上均将前500个数据作为训练集,后3 500个数据作为测试集,在真实数据集上均采用数据集的20%作为训练集,80%作为测试集.对所有数据集的输入输出进行标准化使其范围为[0,1],标准化公式为
(14)
式中:s为初试数据矩阵;smax、smin分别为样本属性的最大值、最小值组成的向量.
2.3 实验结果
表4给出了不同算法在不同数据集上的运行结果,从实验结果可以看出,提出的GGAEOS_ELM的MSE明显低于其他算法的MSE.
为了验证参数a对集成基学习器准确性和多样性的影响,本实验选取a为0、0.2、0.4、0.6、0.8、1.0、1.2、1.4、1.6、1.8和2.0在合成数据集上进行实验.图5(a)(b)分别展示a对MSE和多样性的影响.
从图5中可以看出,适应度函数中适当增加准确性(即e-MSE)的比重,有利于增加集成中基学习器的准确性和多样性,但是随着准确性比重的增加,集成中基学习器的多样性会增加,而准确性会降低(即MSE增加).根据图5中的结果,a=0.4时较为合适.
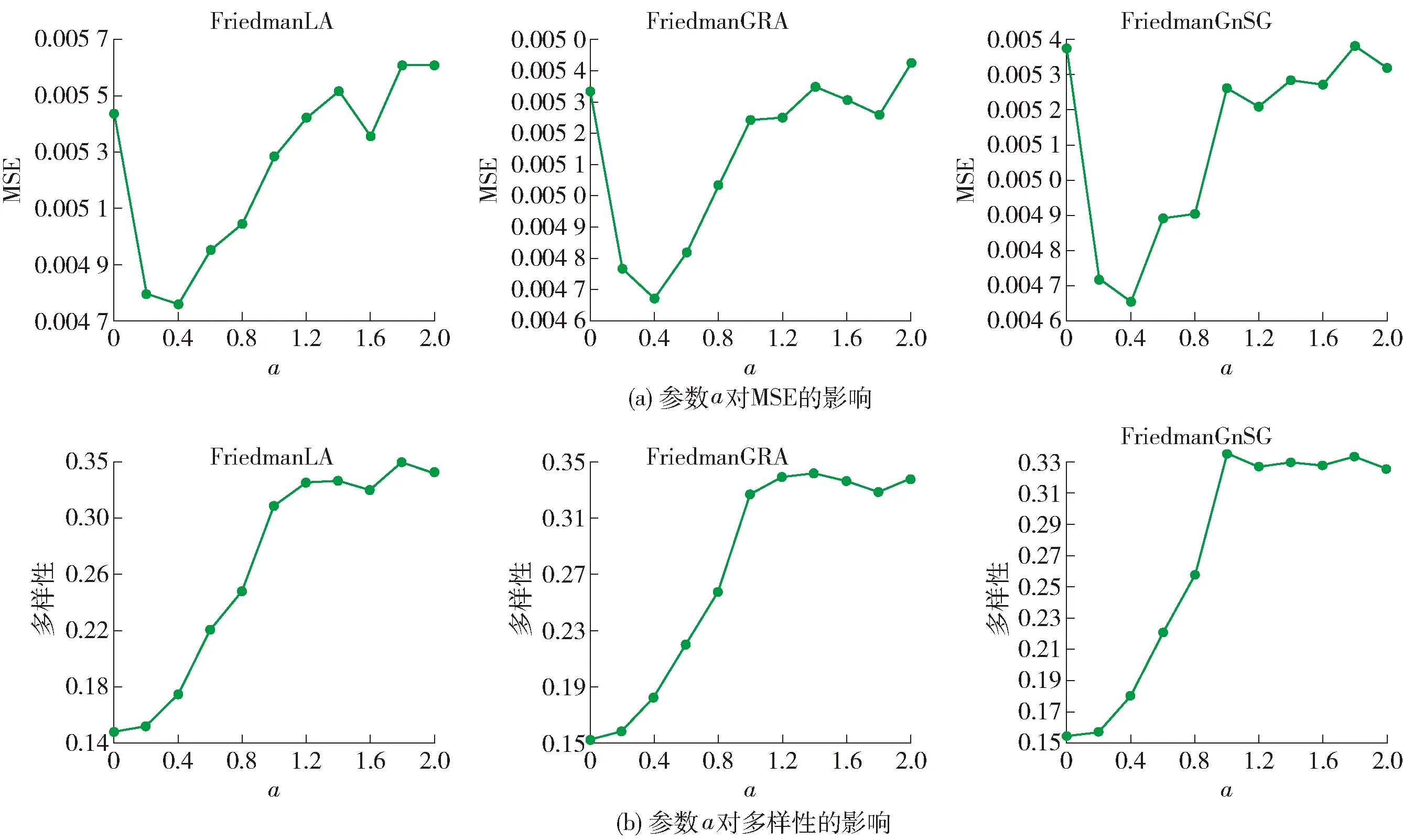
图5 参数a对MSE和多样性的影响Fig.5 Influence of parameter a on MSE and diversity
2.4 实验结果分析
本文提出的GGAEOS_ELM模型在性能上有较好的提升,是因为在进化过程中保留了双亲的优良基因(即参与进化操作的基学习器参数),同时引入基因流基学习器,有利于提升集成中基学习器间的多样性,当概念漂移发生时,能够快速适应当前的数据,从而提高集成的准确性,降低集成的MSE.表4中的结果表明,所提出的GGAEOS_ELM在对比实验中的MSE最低,预测精度有明显的提升.
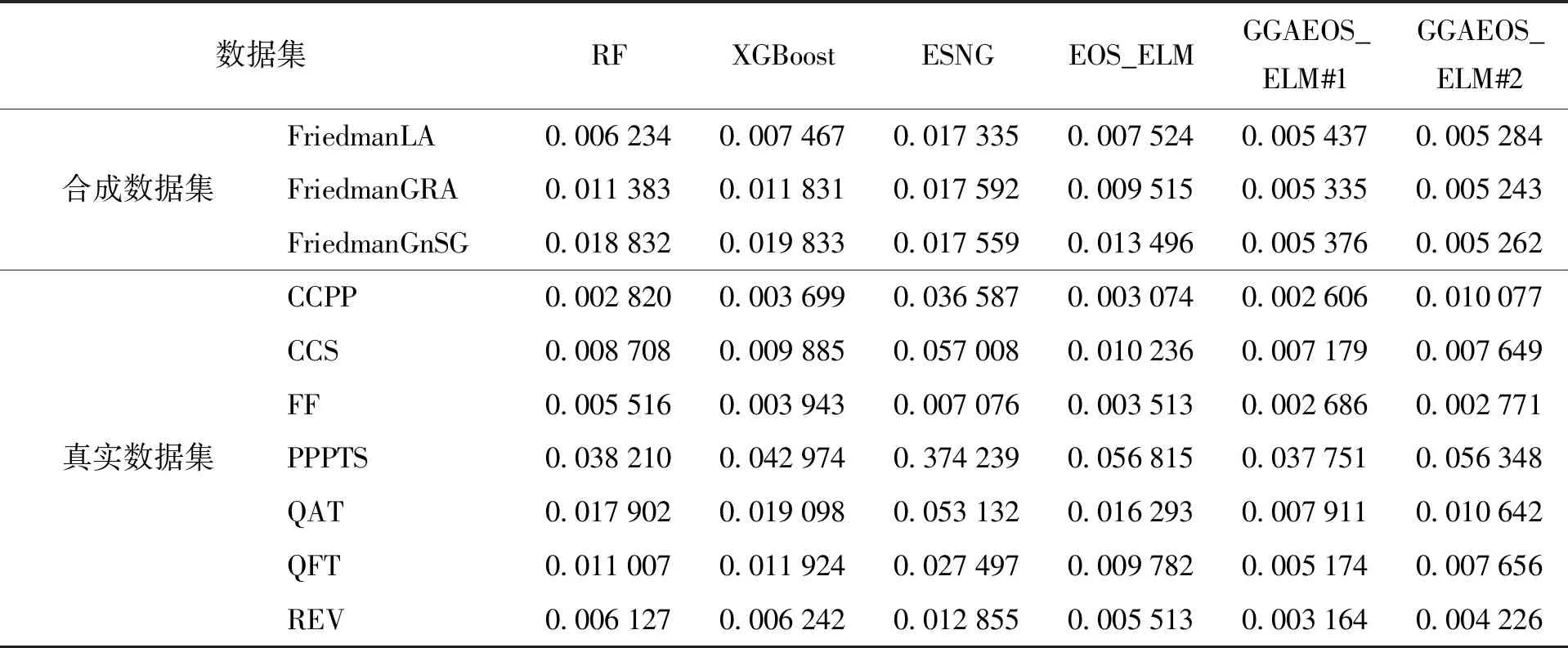
表4 不同算法的MSE运行结果对比Table 4 Comparison of MSE running results of different algorithms
RF是在基学习器(决策树)训练过程中引入随机属性选择,在选择属性的过程中并没有考虑属性与目标值间的关联度,可能将关联度较大的属性丢弃,这将不利于基学习器的学习.XGBoost和RF一样对特征集合进行抽样,增加样本多样性,降低过拟合[15].ESNG是通过随机生成属性值改造数据集的方式,来促进基学习器间的多样性,但随机生成的属性值,具有很强的不确定性,改造后的数据集可能会严重偏离当前或将要出现的概念,因此ESNG在实验数据集上的性能表现较差.EOS_ELM仅在训练时通过改变基学习器训练数据集的方式来增加基学习器间的多样性,但只能在训练数据集上确保基学习器间的多样性,在在线更新的过程中,由于OS_ELM参数的更新,基学习器间的多样性逐渐减小,随着时间的推移将表现出相似的性能,当概念漂移发生后,基于OS_ELM构建的集成学习EOS_ELM不能对新的概念快速反应.
RF、XGBoost、ESNG和EOS_ELM都是基于数据集操作来提升集成中基学习器间的多样性,虽然在性能上能有较好的表现,但是对数据集的操作往往具有不确定性,可能得到不能适应当前或将要出现数据的基学习器,影响集成的预测性能.本文提出的GGAEOS_ELM是通过优化基学习器参数的方式来提升集成中基学习器间的多样性,选择适应度值最高的基学习器进行集成输出.GGAEOS_ELM算法由于没有对数据集进行改造,因此能较好地适应当前的概念,当数据发生概念漂移时,多样的基学习器又能迅速地适应漂移后的概念,有效地提升集成的预测性能.
在设置适应度函数参数时,不同参数的设定对集成中基学习器间的多样性和集成预测的准确性有一定的影响.如图5所示,在适应度函数中适当增加基学习器的准确性,有助于提升集成中基学习器间的多样性和集成预测的准确性.当适应度函数中少量增加基学习器准确性的比重时,集成中基学习器间仍然保留有较大的多样性,且准确性也有一定程度的增加.若没有发生概念漂移,则集成的准确性将有一定的提升;若发生概念漂移,由于集成中基学习器间仍保留有较大的多样性,因此也能快速适应概念漂移后的数据.在图5中对应a取值0~0.4的数据段.
当适应度函数中基学习准确性的比重增加较大时,虽然集成中基学习器的准确性提升较大,但基学习器间的多样性受到影响,集成中基学习器的预测性能趋向一致,若发生概念漂移,则集成中的基学习器不能快速适应,导致集成的准确性较低,MSE增大.在图5中对应a取值0.4~2.0的数据段.
2.5 铝合金薄板带材力学性能在线预测
本节将文中提出的GGAEOS_ELM应用于某铝厂5XXX型铝合金薄板带材力学性能的在线预测.铝合金薄板带材生产过程较为复杂,根据生产经验和现场实际数据,共得到11个化学成分和64个工艺参数组成输入特征向量,铝合金薄板带材的力学性能作为输出变量,包括抗拉强度、屈服强度和断后伸长率.通过对原始数据进行数据清洗得到364组可用的铝合金薄板带材生产数据集.
在进行铝合金薄板带材力学性能在线预测前,先使用式(14)对数据进行归一化处理.由于数据的特征维度为75,存在一定程度的冗余,为了降低特征维度,本文利用主成分分析法(principal component analysis,PCA)选取前10个主成分来代表原始数据,进而将75维输入数据降为10维,前10个主成分贡献率与累计贡献率如表5所示.

表5 前10个主成分贡献率与累积贡献率Table 5 Top 10 principal component contribution rate and cumulative contribution rate %
在预测结束后使用式(15)对预测值进行重新标定,根据标定后的值计算各模型的MSE和均方根误差(root mean square error,RMSE).
y*=(smax-smin)+smin
(15)
各模型在铝合金薄板带材力学性能在线预测的结果对比如表6所示.
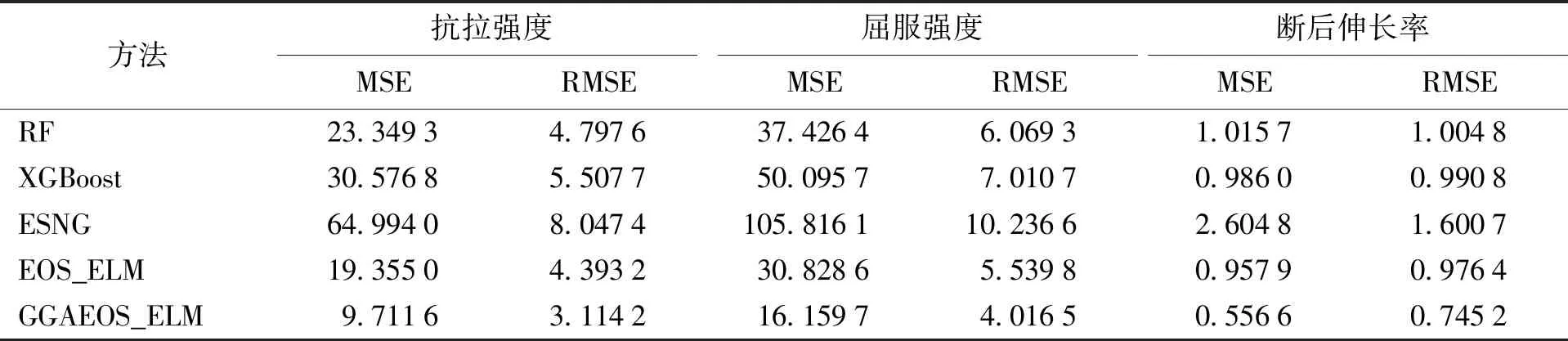
表6 铝合金薄板带材力学性能在线预测结果Table 6 Online prediction results of mechanical properties of aluminum alloy sheet and strip
由表6可知,本文所提出的GGAEOS_ELM在铝合金薄板带材的3个力学性能在线预测时表现最好,这说明GGAEOS_ELM的合理性与有效性.
3 结论
1)本文提出一种基于分组遗传算法的多样性增强方法,该方法在以OS_ELM为基学习器构建Bagging集成的基础上,针对滑动窗口数据,通过分组遗传算法对基学习器进行分组并对其参数执行杂交、突变和选择操作,同时,引入基因流的概念,增加基学习器进化强度,增强集成中基学习器间的多样性,提高集成模型的泛化性能.
2)设计对比实验,实验结果表明GGAEOS_ELM具有更好的预测性能,对具有概念漂移的数据集效果更好.
3)最后在铝合金薄板带材力学性能在线预测实验上,通过对复杂工业工艺过程参数的主成分提取,降低数据的输入维度.实验结果表明,GGAEOS_ELM在铝合金薄板带材力学性能的在线预测上也能有较好的性能表现.
