时空特征与通道注意力融合的视觉手势识别技术
2021-08-05祖天奇
何 坚,刘 炎,祖天奇
(1.北京市物联网软件与系统工程技术研究中心,北京 100124;2.北京工业大学信息学部,北京 100124)
近年来,手势识别技术在体感游戏、手语识别、辅助驾驶及智能家电控制等领域应用广泛.由于手势在人机交互中的重要性,手势识别系统的研究一直是人们关注的焦点.根据文献[1]的调查,自然手势的表达大多是动态的,通过人体手部和上半肢协调运动来完成.因此,动态手势相比静态手势在手势表达中更为重要.
文献[2-3]中对近年来的一些动态手势识别方法进行了总结.例如,Adewuyi等[4]结合手指和手臂肌肉的肌电图数据对手部抓握和手指动作进行分类;Huang等[5]通过双通道方法融合人体手部加速度、角速度及肌肉电数据,再结合K邻近(K-nearest neighber,KNN)算法识别手势;田元等[6]使用Kinect体感设备获取人体的骨骼信息和深度图信息,结合骨骼关节点位置及手指特征对手势进行实时识别.
上面提到的一些工作为了达到更好的识别效果使用了不止一种模态信息,这种情况称为多模态方法[7].它们通常结合颜色信息(RGB格式)、深度图信息和骨骼关节点信息来检测识别手势.这种多源信息,如深度图和骨架关节,积极补充了颜色信息,有助于手势分类[8],然而除RGB以外信息的获取,通常需要特定的传感器,如微软的Kinect、华硕Xtion Pro或英特尔的Realsense3.这种对特定传感器的依赖导致对交互环境的限制,影响手势的自然表达.相反,基于RGB视频数据的动态手势识别技术具有使用方便、成本较低等优点,另外在许多公共空间也很容易找到监控摄像机,交互环境更多.这也是促使人们致力于发展仅使用RGB视频数据识别动态手势的原因之一.
之前的研究工作中,也有些工作仅将RGB视频数据作为手势识别的唯一信息来源,但只有少数工作者取得到了显著的结果,如文献[8-9].即便如此,这些研究中提到的好的识别效果也是在固定的几类手势动作上实现的,这些手势在表达时身体动作差异较大,通常也会简化手势识别的任务.
最近,深度学习的一些方法在计算机视觉领域的几个问题上分别取得了最优的结果[9-10],该类方法通常使用三维卷积网络(3D convolutional neural networks,3DCNN)[11]、双流融合网络[12-13]、卷积神经网络(convolutional neural network,CNN)和长短时记忆(long short term memory,LSTM)网络组合的方式[14]来识别动态手势.例如,Nunez等[15]通过CNN从连续手势帧中提取人体的骨骼数据和手部骨骼数据,再结合LSTM识别动态手势;Al-Hammadi等[16]直接使用3DCNN识别动态手势;Zhang等[17]将3DCNN和LSTM结合从视频帧中学习手势的时空特征图,再利用CNN从该特征图中学习更高层次的时空特征用于手势识别.
文献[13]中双流融合的方法在HMDB51[18]和UCF101[19]2个人体动作数据集上取得最佳识别效果.该方法通过2个卷积网络分别提取连续人体动作的空间特征和时序特征(光流),并探讨对比不同光流提取算法及双流融合方法对人体动作识别效果的影响,证明双向光流能较好表达人体运动信息.不过该方法应用于手势识别任务仍存在2个主要缺点:1)未对不同时序帧的初始权重系数进行考虑;2)空间通道直接对整幅视频帧卷积操作,对较小手部特征关注度不足.
最近的一些研究发现注意力机制能够帮助深度学习从众多信息中抽选出对当前任务目标更为关键的信息[20],其核心思想是基于原有数据找到数据间的关联性,进而突出某些重要特征.而有效通道注意力 (efficient channel attention,ECA)[21]机制相比同类型注意力机制降低了模型的复杂度并获得更高准确度.受双流融合网络和ECA注意力机制启发,本文对双流融合网络进行改进,结合有效通道注意力机制和单发多框检测器技术(single shot multibox detector,SSD)[22]建立了基于视觉的动态手势识别模型,并在Chalearn 2013公开手势数据集[23]上进行实验验证.
1 动态手势建模
手势交互环境中,动态手势的形态主要由人体姿态及手部轮廓构成,连续性手势的表达涉及对其变化规律的考虑.双流融合网络的方法分别从空间和时间上提取手势特征,对身体姿态差别较大的手势识别较好,但对身体姿态相同手部具体形状不同的手势识别欠佳,如图1所示(图1中(a)(b)2个手势在表达时身体动作差别较大;(c)(d)2个手势身体动作相同但手部轮廓不同).分析原因是因为双流融合网络在空间流中直接对整幅手势图像卷积操作,对较为明显的人体姿态特征能够有效提取,但对局部较小的手部轮廓特征关注不足.

图1 不同手势举例Fig.1 Examples of different gestures
本文首先在双流融合网络中引入ECA注意力机制增强双流识别算法对手势关键帧的关注度;其次选取关注度最高的手势帧提取手部轮廓特征;最后将补充的手部轮廓特征与双流特征融合后分类识别手势.
表1中汇总了本文主要特征和有关映射函数的数学符号表示.

表1 主要符号和含义对应表Table 1 Main symbols and associated meanings
1.1 手势双流特征提取
相比静态手势,动态手势的识别还需要考虑连续帧之间的手势动作变换规律.光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来计算出相邻帧之间人体运动信息的一种方法[24].另外,利用光流作为时序上的运动信息可以去除不同背景对手势识别的影响.本部分参考双流融合网络的思想建立了动态手势双流卷积网络(gesture two-stream convolution network,GTSCN),该网络分别从空间和时间上提取手势表达中的人体姿态特征、运动特征,结构如图2所示.

图2 GTSCN网络结构Fig.2 GTSCN network structure
对于一个输入宽、高分别为w、h的手势视频,首先平均选取T帧手势图Xτ,X2τ,…,XTτ,将其堆叠作为双流中空间卷积网络的输入,用来提取动态手势中的人体姿态特征G.其中每选取的2帧手势图之间相隔τ帧.

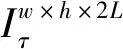
(1)
式中Pk表示从第τ帧(u,v)位置开始,沿着这个轨迹的第k个点,用来记录手势在每一帧像素上的移动轨迹,并且有如下递推解释:
(2)
1.2 注意力机制关键帧选取
以上建立的双流卷积网络模型分别从堆叠的手势帧和光流帧中提取手势特征.需要注意的是动态手势的表达是一个时序过程,注重手势表达过程中易于区分的关键性动作更能增强手势的识别效果.
本文引入ECA通道注意力对输入双流卷积网络中的手势帧和光流帧的特征图通道集合进行加权,用来提升手势关键帧的关注度.
ECA的工作原理在于:通过学习每个特征图通道在整个特征图通道集合中的权重比例系数,进而增强权重较高特征图通道的学习.通过将手势帧和光流帧按照时间顺序堆叠(每个手势帧和光流帧都可以看作一个特征图通道),再结合ECA即可求取每个手势帧和光流帧的加权权重,权重最高的即为动态手势表达过程中的关键帧.
另外,由于时序上堆叠的特征图通道之间具有一定的局部周期性[26](时间间隔较远视频帧之间的相关性更小),假设每个视频帧对应的特征图通道仅与其邻近k个特征图通道相关,依据ECA注意力机制的思想可结合每个特征图通道的邻近k个通道计算出该通道的局部加权权重
(3)
式中:C表示需要加权的特征图通道集合;ci表示C中的第i层特征图通道;σ表示Sigmoid激活函数;函数g(·)表示全局平均池化.设k与C之间的映射关系为φ(·),依据ECA本文使用以下非线性函数映射φ(·)
(4)
式中:|num|odd表示将num向上舍入为最近的奇数;γ、b为任意自然系数,本文设γ=2、b=1.至此,识别动态手势关键帧的注意力机制模块已建立.将输入GTSCN网络中的手势帧集合X和光流帧集合I分别代入到式(3)中的C,即可求对应通道的加权权重,进而增强手势关键帧的识别.
1.3 手部轮廓特征选取
通过式(3)可计算出GTSCN空间卷积网络中每一帧手势的加权权重,由于手势表达过程中的一些特定手部形态可以帮助区分不同手势,因此本文选取加权权重最高的手势帧用来提取手部轮廓特征O,增强运动姿态相似但手部轮廓不同手势的识别效果.
这里只选择加权权重最高的手势帧提取手部轮廓特征的考虑是:动态手势的表达是一个时序过程,手势表达过程中的初始阶段和结束阶段包含信息不多,如果对每一帧的手势都提取手部轮廓特征,作用性不强也增加计算复杂度.因此本文设计只提取关键帧的手部轮廓特征.

值得注意的是,GTSCN网络中提取的人体姿态特征G和运动特征S具有像素级的对应关系.以刷牙和梳头2个动作为例,如果一只手在某个空间位置周期性地移动,那么时间卷积网络就能识别其运动轨迹,而空间卷积网络就可以识别其形态(牙齿或毛发),将其组合就可以辨别动作.因此本文首先在通道维度上堆叠特征G、S用来满足特征图层的像素级对应关系,然后使用三维卷积和三维池化对特征G、S进行融合,最后设计在全连接层拼接手部轮廓特征O,有
F=R(ψ(G⊕S))⊕O
(5)
式中:⊕表示变量拼接或通道堆叠;ψ(·)表示对变量进行三维卷积和三维池化;R(·)表示将变量转换为一维变量.最后F通过全连接层即可计算每类手势的预测概率pi,预测概率最大pmax即可作为最终的预测手势.
2 动态手势识别机
本文建立的动态手势识别机如图3所示,由通道注意力模块、手部轮廓特征提取网络、双流卷积网络、特征融合及分类模块构成,其中双流卷积网络中的空间卷积网络和时间卷积网络均均采用VGG16[27]构建,其他部分的构建方法将在本节逐一介绍.

图3 动态手势识别框架Fig.3 Dynamic gesture recognition frame
2.1 通道注意力模块
本文选用ECA来构建通道注意力模块,图4即为ECA结构的示意图.对于输入通道为C的手势帧和光流帧,首先使用全局平均池化操作(golbal average pooling,GAP)将每一层的特征图通道ci都映射为一个单一变量li.这里使用该操作的原因是:为保障求取各个视频帧对应特征图通道权重系数的合法性,应该结合整个通道的空间上下文信息,另外将整个特征图通道映射为单一变量也可以减少网络的训练参数,进而降低模型复杂度.全局平均池化操作的工作原理为:利用当前特征图通道中所有位置像素值的平均值用来表达整个特征图通道的信息.

图4 注意力机制模块图Fig.4 Attention module diagram
其次,需要结合每个特征图通道对应变量的邻近k个变量计算出当前特征图通道的加权权重vi(时序上堆叠的特征图通道具有一定的局部周期性,邻近的特征图通道之间相互影响,可只计算每个通道在其邻域内的加权权重).vi的计算表达式为
(6)

最后,使用Sigmoid激活函数将每个特征图通道的权重归一化到[0,1]范围内再结合输入数据即可得到加权后的特征图通道集合.⊗表示乘法操作.
其中,向量L和向量V之间的映射矩阵为

(7)
式中:第i行第k个非零元素wi,k即表示第i个特征图通道邻近的第k个特征图通道对其影响权重.
2.2 手势轮廓特征提取网络
输入空间卷积网络中的连续手势帧经过ECA模块可选出手势表达过程中的关键帧,然后再利用手势轮廓特征提取网络可从关键帧中提取手部轮廓特征,用来弥补双流融合网络对较小手部轮廓检测不足的问题.需要注意的是,多生物特征融合虽然可以提高识别系统的准确性,但也无疑提高了计算复杂度.
SSD作为一种多尺度、高精度的目标检测技术,能够快速识别图片中物体的位置及类别,因此本部分引用SSD技术从手势关键帧中提取手部轮廓特征,图5即为本文所用SSD网络架构.其中卷积层conv_8~conv_11分别从不同尺度的特征图中提取手部轮廓进行分类,旨在解决不同用户的不同手部大小对手部轮廓分类的影响.该方法的具体实现思路是:首先,在多个不同尺度特征图层的每个像素点周围预设几个候选框;然后,针对每个候选框都预测距离真正手部位置的偏移量及各类手部轮廓的置信度;最后,选择偏移量较小候选框中置信度最高的类别作为最终的手部轮廓类别.

图5 手部轮廓特征提取网络结构图Fig.5 Network structure diagram of hand contour feature extraction
2.3 特征融合分类模块
本文建立的特征融合及手势分类结构如图6所示,其中ψ(·)表示对变量进行三维卷积和三维池化操作,R(·)表示将变量转换为一维变量,⊕表示变量拼接或通道堆叠,FC表示全连接层.对于GTSCN双流网络中提取的人体姿态特征图G和手势运动特征图S,首先,在通道维度上进行堆叠并使用三维卷积和三维池化操作融合特征G、S形成动态手势的双流特征D;其次,将融合后的双流特征D转换成一维变量,并与手部轮廓特征O进行变量拼接;最后,使用全连接层进行分类得到最终的手势识别类型.

图6 特征融合分类模块示意图Fig.6 Feature fusion and classification module diagram
其中,全连接层的作用在于:通过多次线性变换求取融合后的手势特征F属于每一类手势类型的概率,概率最高的即为最终的手势类型.另外,本文的损失函数定义为交叉熵损失函数(全连接层的多分类任务常使用该损失函数),即
(8)
式中:M表示手势类型个数;pi表示手势属于第i个类型的概率.
3 实验结果分析
3.1 数据集简介
为验证本方法的泛化性,本文选择公开的Chalearn 2013意大利手语数据集进行实验.该数据集使用Kinect传感器以每秒20帧的速度记录了27个用户在不同背景下的手势词汇表达,其中共包含20个手势分类,每个手势的时长在50帧左右,并提供RGB、RGB-D、骨架、用户轮廓多种模态信息.另外该数据集共计13 858个样本,其中训练集7 754个、验证集3 362个、测试集2 742个.本文使用该数据的RGB模态数据与其他仅使用RGB信息的动态手势识别方法进行了对比.
3.2 网络训练
3.2.1 双流结构
本文设计GTSCN网络中的空间和时间卷积网络均采用VGG16特征提取网络构建,包含5个卷积层和3个全连接层,有关VGG16的具体参数设置可参考文献[27].
由于Chalearn 2013视频数据的分辨率为640×480,因此对于空间卷积网络,首先按照手势样本的开始帧和结束帧在中间平均选取T帧;然后从这T帧手势图中随机剪裁480×480的区域并缩放到224×224的分辨率大小;最后将堆叠的维度为224×224×T的手势帧输入到空间卷积网络.
对于时间卷积网络,首先按照式(1)计算出选取T帧手势图中每一帧手势的光流图集合,然后将堆叠的维度为224×224×2L×T的光流图输入到时间卷积网络.
3.2.2 手部轮廓特征提取网络
本文截取Chalearn 2013视频数据的手势帧标注左右手候选框及对应手部轮廓类型,进而训练手部轮廓特征提取网络.具体实现步骤如下:
步骤1在38×38的conv_4、19×19的conv_7、10×10的conv_8、5×5的conv_9、3×3的conv_10、1×1的conv_11六个不同尺度特征图层中预设多个手部标记候选框.其中,每一个候选框都需要预测以下2点信息:候选框中的手部轮廓类型p;左下角及右上角2个顶点坐标(xmin,ymin)、(xmax,ymax)距离真正手部位置的偏移量.
步骤2针对这6个特征图层中的每一个候选框,都使用5个卷积过滤器利用卷积操作的方式得到预测的4个坐标偏移量及手部轮廓类型置信度.
步骤3将各个候选框中预测的手部轮廓类型置信度从大到小排序,选取置信度最高的候选框作为其中一个手的真实框,并将其预测的手部轮廓类型和位置坐标作为该手部的预测结果.
步骤4计算剩余候选框与当前真实框的重叠度(intersection over union,IOU),并根据预设的重叠度阈值IOUt过滤掉一部分候选框(若上一步已确定左手的真实框,则可以过滤掉剩余所有左手的候选框,本文设置IOUt为0.5).然后从剩余候选框中选择预测置信度最高的作为另外一个手的真实框.重叠度的计算公式为
(9)
式中boxi表示第i个候选框的面积.
另外,由于Chalearn2013手势数据集中的左右手轮廓在视频图片中占比较小,因此本文按照式(10)对SSD默认候选框的归一化尺度做了调整,即
(10)
实验时标注的左右手候选框大小与视频画面的尺度比多数为0.05~0.30,因此本文设计手部轮廓候选框的归一化尺度见表2.

表2 手部轮廓候选框的归一化尺度Table 2 Normalized scale of the hand contour candidate box
3.2.3 特征融合及分类模块
本文设计的特征融合及手势分类结构如图6所示.其中,三维卷积核的维度为3×3×3,步长为1;三维池化的维度为2×2×2,步长为2(最大池化).另外,本文在全连接层后面添加softmax激活函数预测手势类别.
3.3 实验结果分析
在显卡为NVIDIA Titan X、处理器为Intel Xeon ES的实验环境下,本文方法与之前在该数据集上的最佳手势识别结果进行了对比,如表3中所示.

表3 不同方法的实验结果对比Table 3 Results of different methods
文献[28]中设计的耦合隐式马尔可夫算法(coupled hidden Markov model,CHMM)仅使用RGB信息在该数据集上获得了之前的最佳手势识别效果,准确率为60.07%.该方法通过集成2个或多个隐式马尔可夫链(HMM)学习不同链隐藏节点的相互作用,进而增强单HMM的识别效果.本文一开始设计的GTSCN网络结构分别从空间卷积网络和时间卷积网络中获取手势的时空上下文信息,实验准确率为64.57%;结合ECA注意力机制后实验准确率为65.84%;再通过补充SSD提取的手部轮廓特征后获得了66.23%的识别效果.
由上述分析可知,通过结合通道注意力和手部轮廓特征,可有效提高双流融合网络的手势识别准确率.
本文也实验对比了不同特征融合策略对手势识别结果的影响,如表4所示.Max方法表示选取特征G、S在相同空间位置特征图通道的最大值作为双流融合特征,Sum方法表示选取特征G、S在相同空间位置特征图通道的和作为双流融合特征.实验结果表明利用三维卷积和三维池化能够更好地提高手势识别准确率,分析原因是与二维卷积、二维池化相比,三维卷积、三维池化能更好地从视频序列中学习人体手势的运动变化规律,其卷积和池化操作都是在时空上执行,而二维卷积和二维池化仅在空间上完成.

表4 不同特征融合策略对实验结果影响对比Table 4 Effect of different feature fusion strategies on experimental results
另外,在本文的实验环境中,SSD识别关键帧中的手部轮廓类型约耗时50 ms,相邻两帧之间的光流计算约耗时11 ms(光流在视频播放过程中采取实时计算),识别的总体延迟时间在200 ms以内,因此本文的手势识别方法可基本满足实时性要求.
4 结论
1)提出了一种基于RGB视频数据的动态手势识别模型.首先依据双流融合网络的思想构造了GTSCN网络,用来提取动态手势中的人体姿态特征、运动特征;其次设计在GTSCN网络中引入ECA注意力增强手势关键帧的学习,并结合SSD提取手部轮廓特征;最后通过全连接层分类识别手势.
2)通过在Chalearn 2013公开手语数据集上进行实验,证明结合ECA和SSD可以增强双流算法对相似手势的识别效果.
3)下一步研究计划是针对本文提出的模型开发设计一个手势识别系统,将实时拍摄到的手势视频转换为对应文本含义.
