结合邻域知识的文档级关键词抽取方法
2021-08-04李晨亮龙俊辉唐作立
李晨亮,龙俊辉,唐作立,周 涛
(1. 武汉大学空天信息安全与可信计算教育部重点实验室 武汉 430072;2. 武汉大学国家网络安全学院 武汉 430072)
关键词抽取技术是一种从文本中抽取主题和一些重要短语的技术,可以帮助阅读者快速了解文本中最有价值的信息[1]。一篇文档的关键词通常是几个单词或者短语,可以作为该文档主要内容的提要。近几十年来,自动抽取关键词的任务受到了广泛关注[2]。另外,由于关键词具有表达简洁、精准的特点,被广泛用于自然语言处理领域中的下游任务,比如文本摘要、情感分析以及文本聚类等[3]。
最传统的关键词抽取方法基于TF-IDF,它能识别出在当前文档中频繁出现,但在整个文档集合中不会频繁出现的单词,即该文档的重点单词。还有基于图的排序方法[4],它首先从文档构造一个词图,然后用基于随机游走的方法(如PageRank)确定关键词的重要性。通过构建词图,这些方法可以有效地识别最显著的关键词。近年来,基于端到端神经网络的关键词抽取方法受到越来越多的关注。文献[2]将关键词抽取视为一项序列标注任务,并提出了一种联合层RNN的模型。文献[5]首先提出了一种用于关键词抽取的编码器-解码器框架,并在框架中引入了注意力机制,使模型基于输入的文档来输出对应的关键词。文献[6]进一步提出了一个基于CNN的模型来完成这项任务。文献[7]提出了一种标题指导的seq2seq网络来加强隐式文档表示。另外,为了考虑生成的关键词之间的关系,文献[8]使用了自适应奖励的强化学习方法。文献[9]指出了关键词生成中第一个词的重要性。文献[10]利用了聚类的方法来过滤掉无意义的候选关键词。
基于端到端的神经网络方法还面临两个重要挑战:1) 建模有效的文档向量表示。文档向量表示能够直接决定解码器的输出结果,影响整个模型的效果;2) 生成全面并准确覆盖整个输入文档主题的关键词集合。为了解决以上问题,本文提出了结合邻域知识的文档级关键词抽取方法。在编码端给定一个文档,基于该文档与相似文档的相关信息以及文档内部单词之间的距离构建出文档的图结构,将相同的单词聚合到一起用同一个节点表示。在解码端设计了一种多样化指针网络,从原文档的词图中动态地选择相关的单词构成强概括性且不重复的关键词,极大优化了解码器端的性能。实验结果表明,相比传统非监督学习方法和经典的深度学习方法,结合邻域知识的文档级关键词抽取模型可以有效提升抽取结果的相关指标。
1 研究方法
本文模型由检索器、编码器及解码器组成。编码器采用了图卷积神经网络(graph convolutional networks, GCN)[11]进行编码,解码器以关键词为单位逐个生成关键词。编码器和解码器的结构示意图分别如图1和图2所示。

图1 编码器结构的示意图
1.1 检索器
输入指定文档,找到与该文档相似的邻域文档,邻域文档表示在局部空间中与指定文档靠近的文档。邻域文档可以给原文档提供额外的领域知识上下文信息。即给定文档x,利用相似文档检索技术检索出Top-K个邻域文档,原文档x被扩充为文档集合 χ={x,x1,···,xk},作为输入文档的增强上下文知识数据。相似文档检索技术的核心依赖于两个文档相似度的评估功能。本文使用余弦相似度方法来度量文档xi和文档xj的相似度,并引入TFIDF指标来度量文档中单词的重要性,最后计算出基于加权的文档词项向量的余弦相似度分数,其计算公式为:

1.2 编码器
1.2.1 图构建




1.2.2 图卷积神经网络
图卷积神经网络(GCN)是一个直接对图进行操作的多层神经网络,能够根据图内部节点中邻居节点的属性来归纳学习当前节点的嵌入向量表示。图卷积神经网络中一个卷积层能够捕获到每个节点的直接邻居信息,如果堆叠多层卷积网络就能够聚集到更大范围的邻域节点信息。因此一旦完成了文档图构建操作,便把整个图输入到一个多层图卷积神经网络中。每个卷积层通常包含两个阶段,第一个阶段聚合每个节点的所有邻居节点信息,在第二个阶段中,每个节点根据当前节点表示和聚合信息表示来更新自身的节点表示,两个阶段共同实现了一次完整的信息传输和聚合流程。给定节点矩阵表示Hl,l表示当前卷积层的下标,图中所有节点的聚合和更新过程用函数fl(Hl)表示,则有:


门控单元内部的函数gl具有和fl相似的网络结构。H0初始化为单词的嵌入表示,作为模型的初始输入。
1.2.3 文档聚合
针对编码器端最后一层HL中属于原文档的节点,模型采用多头自注意力机制[15]线性转换原文档中出现的单词表示,计算均值并拼接得到文档的向量表示c,则有:

实验中设置多头的数量为4,即T= 4。
1.3 解码器
解码器是该方法的重要组成部分,文档通过编码器得到文档的向量表示。基于文档表示,解码器将连续生成多个具有多样性且完整覆盖文档主题的多个关键词。本节将详细介绍用指针网络来实现解码器的方法,并说明引入的上下文修改机制以及覆盖机制的原理和作用。
1.3.1 指针网络
指针网络[16]是一种学习输出序列的条件概率的网络结构,能够解决可变大小输入字典的问题。因此输入文档表示,解码器就能从输入文档的字典范围中生成多个高质量关键词,满足关键词抽取任务的要求。和大多数seq2seq框架一样,解码器首先使用RNN框架来依次输出每一时刻t的网络隐藏状态,则有:

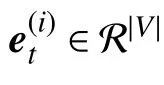
1.3.2 上下文修改机制


1.3.3 覆盖机制
在关键词抽取任务中,多个关键词通常对应原文中不同的位置,已经被模型选择过的单词应该尽量避免多次被模型选中。为了避免这个问题,模型引入了覆盖机制[17],灵活调节每个关键词的概率分布,确保原文中所有的重要区域都能够被模型重点关注并且被总结为关键词。
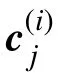


式中,新增的Wc是可学习参数。
1.4 训练

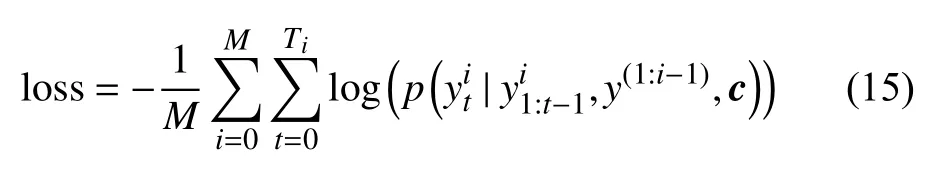
另外,训练和解码的过程中在关键词的末尾添加“EOS”符号来让模型停止生成多余的单词。
2 实验及结果分析
2.1 数据集
使用4个科学文献基准数据集来评估模型的效果,包括KP20k、Inspec、Krapivin以及SemEval。对KP20k数据集做了预处理,删除了其中重复的数据,最终保留了509 818个训练集样本,20 000个验证集样本以及20 000个测试集样本。并且有模型都是基于KP20k数据集进行训练。模型训练完成之后,在4个基准的测试集上测试了所有模型。数据集的统计结果如表1所示。

表1 数据集统计表
2.2 对比模型和评价指标
首先分别采用以下几个经典的关键词抽取算法作为本文模型的对比模型,其中包括4种无监督关键词抽取算法(Tf-Idf、TextRank、SingleRank[18]、ExpandRank[18])和其他基于监督的关键词抽取算法(Maui[19]、RNN[5]、CNN[6]、CopyRNN[5])。
为了评价每种模型的表现,采用F1分数作为评价指标。F1指标由召回率R、精确度P计算得到,计算方式如下:

最后,模型使用英文分词算法(porter stemmer)处理关键词,决定关键词之间是否匹配。
2.3 实验结果
表2总结了不同的关键词抽取算法在4个基准数据集上的表现情况,给出了前5位和前10位的F1结果,并且使用粗体显示最好的分数。

表2 不同模型在4种基准数据集上的关键词抽取性能
首先将本文的模型与传统的关键词抽取算法进行比较,结果显示本文的模型在所有测试集上都取得了明显的提升效果。另外,本文模型相较于常见的基于端到端的深度学习方法也有了更进一步提升,说明本文模型引入了文档邻域知识,图卷积方法以及多种多样性机制确实学习到了有效的文档向量表示,并使生成的关键词尽可能多地覆盖了文档主题。本文的模型相较于各对比模型都有着良好的关键词抽取效果,证明了该模型的有效性。
2.4 消融实验
为了验证上下文修改机制和覆盖机制对关键词抽取任务的性能影响,在Inspec数据集和Krapivin数据集上对模型进行消融实验。其中,“-ConModify”表示不使用上下文修改机制,即模型在解码的时候不参考之前生成的关键词内容来修改文档向量表示。“-CovMech”表示不使用覆盖机制即每当解码器生成关键词单词的时候,不再记录所有单词one-hot编码总和。“-Neither”表示两者都不使用。从表3中能看到如果模型单纯添加了覆盖机制的情况下即“-ConModify”,相比于“-Neither”方法能够在Krapivin数据集上得到更好的效果,然而在Inspec数据集上的效果却降低了。如模型仅仅增加了上下文修改机制即“-CovMech”,结果表明上下文修改机制在两种数据集上都能给模型带来更好的关键词抽取效果。相较于“-Neither”方法,当同时加入上下文修改机制和覆盖机制,模型的关键词抽取效果得到了提升,说明当前两种机制存在很强的互补关系,并且进一步增强了模型的鲁棒性。

表3 消融实验
2.5 参数分析
编码器端使用了图方法来对所有文档进行建模和编码。为了深入研究模型的效果,分析不同GCN层数对模型效果的影响。实验结果如表4所示,结果显示当编码端只有一层GCN的时候,图中的节点无法从邻居节点得到足够的有效信息。在设置2层GCN的情况下,模型在Inspect数据集上取得了较好的效果。直到在实验中设置了6层GCN的情况下,模型在Inspec和SemEval数据集上同时达到了出色的效果。
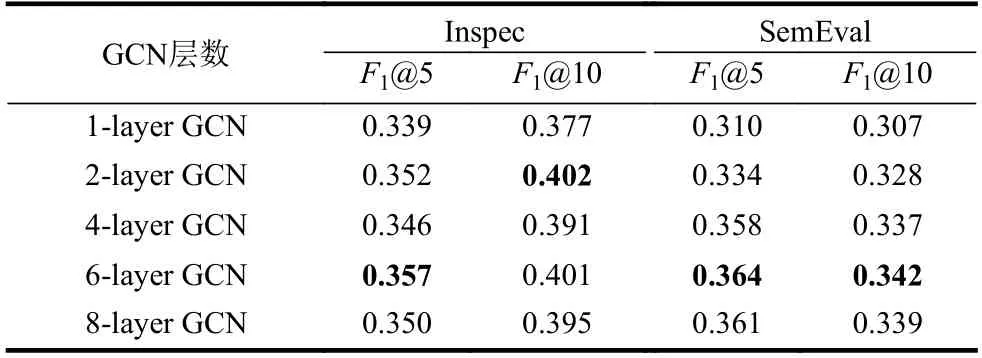
表4 GCN层数对模型效果的影响
实验结果表明随着GCN层数的增加,模型效果会逐渐提升。然而过多的GCN层数会导致整个图中的节点出现同质化的负面效果,导致模型性能下降。另外,通常情况下2层GCN会得到较好的拟合效果,然而卷积网络门控单元和残差学习框架来缓解GCN的过拟合过程,并最终取得了更好的关键词抽取效果。
3 结 束 语
针对关键词抽取任务,本文提出了一种结合邻域知识的文档级关键词抽取方法。为了更好地建模输入文档的向量表示和生成覆盖文档所有主题的关键词集合,计算文档之间的相似度并选择部分最近邻文档作为原文档的邻域知识。然后根据每个文档中单词之间的长短程关系构建词图,合并输入文档和邻域文档的词图,利用图卷积网络完成编码过程。最后采用指针网络完成解码过程。模型引入上下文修改机制和覆盖机制,共同避免模型生成重复的关键词。在多种数据集上进行关键词抽取任务的对比实验,结果证明结合邻域知识的文档级关键词抽取模型能够有效提升关键词抽取任务的效果。
