基于BERT-FLAT-CRF 模型的中文时间表达式识别
2021-08-02朱乐俊王卫民
朱乐俊,王卫民
(江苏科技大学 计算机学院,江苏 镇江 212003)
0 引言
时间表达式在日常语句中十分常见,在语句理解中扮演着非常重要的角色。在自然语言中,时间是重要的语义载体,揭示事件从发生、发展到结束的过程[1]。有效识别时间表达式对于后续时间序列分析、事件抽取、智能对话理解均有重要作用。近年来人工智能的众多应用,包括智能客服、对话机器人等都离不开对时间信息的理解。比如在客服系统中包含时间信息的问句:“下个星期五畅游天翼活动还有吗”,又或者在对话机器人中发出指令“帮我订张星期三上午的火车票”,在此类情况中都需要准确理解时间信息。
文本中时间表达式识别难点主要在于边界难以划分,通常主要采取两种方式进行识别。第一种为基于规则的方法,利用时间表达式语法结构特点构造一系列规则进行匹配,可解释性强,但维护难度很大;第二种方式为基于机器学习的方法,一般采用条件随机场与隐马尔可夫模型以及最大熵模型,将时间表达式识别转变为序列标注问题。本文利用机器学习方法,在使用条件随机场的情况下加入词向量表达能力更加强大的预训练语言模型,并将时间词汇的特征编码代入深度学习模型中,使时间表达式识别效果大幅提升。
1 相关工作
时间表达式是自然语言处理中的基础任务,在信息抽取中具有重要地位,国内外学者对此开展了一系列研究。国外相关评测举办较早,最早可追溯到2004 年TERN(TE Recognition and Normalization Challenge)评测活动举办,后续又相继举办了ACE(Automatic Content Extraction Chal⁃lenge)评测活动,紧接着从2007 开始举办了一系列TempE⁃val 评测活动,产生了一大批性能良好的英文时间表达式识别方法。例如由德国海德堡大学Strotgen 等[2]开发的具有多语言特点的处理系统HeidelTime,该开源系统利用词性标注和手动设置的规则进行时间表达式识别与标准化;Chang 等[3]提出一种3 层时间模式语言。首先识别单个标记,然后将标记扩展为字符串,最后对字符串进行组合和过滤以获取时间表达式;Bethard[4]提出使用一系列词素语法特征与字母数字子类划分的时间类型,优化时间信息识别;Angeil 等[5]提出了一种通过概率上下文无关文法识别和解析时间表达式,定制了专注于时间信息的时间文法对时间表达式进行识别和标准化处理;Lee 等[6]根据组合范畴学语法定制时间语法,具有高效定制化的特性,可清晰表达时间信息,但系统构建与维护存在困难,也不具有较好的移植性;Zhong 等[7]不再使用固定的方法设计相应规则,而是通过使用一组与时间相联系的时间触发词触发时间表达式,并通过通用规则启发式扩展边界;在最新的英文时间表达式识别中,Ding 等[8]以词类型序列作为表达式模式,提出了基于模式的时间表达式识别方法。
相较于英文时间表达式识别工作,中文时间表达式识别因相关测评语料缺乏而起步相对较晚。贺瑞芳等[9]将依存分析与错误驱动的方式相结合,通过错误驱动的方式不断改造模型中时间表达式的错误标注,后续又提出了启发式错误驱动方法;邬桐等[10]在观察时间表达式结构特点后,提出“时间基元”概念,将其时间单位细化并运用于规则构造;刘莉等[11]将语义角色特征融合于机器学习模型CRF 中的识别时间表达式;吴琼等[12]提出了将条件随机场与时间词库相结合的方式进行时间识别,为解决时间表达式识别提供新思路;高源等[13]提出将时间词典细分为时间词词典和时间单位词典,优化词典特征与模型融合,最后结合了依存分析的方式识别时间短语;金博文[14]提出使用BiLSTM-CRF 模型识别时间表达式;宋国民等[15]通过构建时间信息正则表达式规则,利用表达式匹配的方式实现时间信息识别。
本文基于中文时间表达式现有研究,进一步提出基于BERT-FLAT-CRF 模型的中文时间表达式识别。该方法利用预训练语言模型BERT 作为字符嵌入的向量表示,有效解决信息长距离依赖问题,可获取潜在的上下文语义关系,为下游识别任务提供丰富的语义特征;利用FLAT 模型将时间词汇的特征编码代入深度学习模型,将字符特征与词汇特征融合,增强其边界信息,可有效提升对时间表达式边界的划分能力。
2 BERT-FLAT-CRF 模型构建
随着深度学习的快速发展,在自然语言处理领域内出现了预训练的语言模型,其强大的词向量表达能力在多个自然语言处理任务中达到了最优效果,因为其训练语料庞大,即使在小样本中也有非常不错的效果,因此将其引入到时间表达式识别中,并且在预训练模型中引入时间词汇特征,最后使用BERT 与FLAT 及条件随机场模型识别时间表达式。BERT-FLAT-CRF 整体网络结构如图1 所示。模型整体分为BERT 层、FLAT 层和CRF 层,BERT 层可有效获得上下文相关向量表示,FLAT 层融合时间词汇特征,CRF层能有效联合标签序列,使其输出正确的标签序列。

Fig.1 Structure of the BERT-FLAT-CRF model图1 BERT-FLAT-CRF 模型结构
2.1 Bert 层
Word2Vec[16]是深度学习技术在自然语言领域的一项成功应用。作为一种词嵌入方式,Word2Vec 将一个基于词典长度的one-hot 编码映射到低维语义空间,从而语义空间相似的词能够获得相近距离,以便用余弦相似度等方法直接度量。但该方法无法获得更多上下文信息,不具有词的多义性,例如“苹果”可以指水果,也可以指美国高科技公司。针对该问题,有研究者提出ELMO 模型[17],该模型利用双向LSTM 抽取结构,通过动态调整双向网络结构构造词向量,有效提取上下文表示,预训练得到具有上下文语义动态变化的词向量,并使多个自然语言处理任务达到最优水平。随后Radford 等[18]提出了GPT 模型,该模型改进了ELMO 使用的特征抽取器,LSTM 特征抽取器训练收敛较慢,且获取长距离信息的能力不强,因此GPT 使用Trans⁃form 特征抽取器,并将模型改造为单向,在生成任务中效果明显改进[19]。Devlin等[20]综合了以上模型优点,提出BERT模型,该模型使用双向Transform 结构,利用MaskLM与NSP 的方式对模型进行训练,在11 项任务中取得了最优结果,证明其词向量包含丰富的语义特征,因此本文引入该模型,其网络结构如图2 所示。
2.1.1 BERT 输入表示层
Bert 输入层主要由词嵌入、句子嵌入和位置嵌入三者向量直接相加得到输入的序列表示。其结构如图3 所示。
从图3 可以分别看到Token Embeddings 表示的单词向量。单词CLS 标志具有句子向量的表示,可作为下游分类任务使用,Segment Embedding 表示该词属于哪个句子,可区分句子,Position Embeddings 表示模型学习到的位置向量,在Transform 中位置向量为硬编码的加入,在BERT 模型中进行改造,可以在训练中学到位置表示。
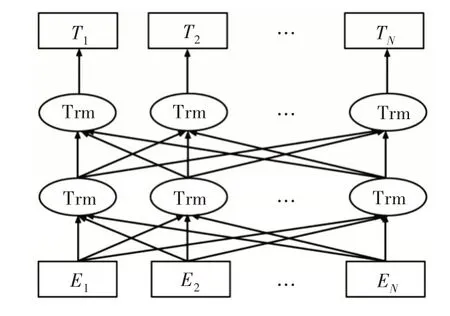
Fig.2 Bert model structure图2 Bert 模型结构

Fig.3 Bert input vector representation图3 Bert 输入向量表示
2.1.2 BERT 预训练任务
BERT 预训练任务主要包含两个任务,一个是遮蔽语言模型(Masked Language Model),另一个是下一句预测(Next Sentence Prediction),两者分别从词级别和句子级别中进行向量表示。
遮蔽语言模型基于GPT 单向模型进行改进,使模型能够有效进行双向编码,但在模型预测过程中可通过双向编码看到待预测词,因此需遮蔽待预测词,随机遮蔽输入中的n 个词,然后利用双向LM 预测这些词,遮蔽的词汇数量需谨慎考虑,如数量太少,则每次目标函数包含的词太少,训练时需迭代多次;若遮蔽过多,将导致背景信息丢失过多,与预测场景不符。因此BERT 提出随机遮盖15%的词,利用模型预测遮盖的部分词汇中只有80% 的词会被masked token 取代,还有10%会随机用词汇替代,剩下10%保持不变,依旧使用原来位置的词。
下一句预测主要目的是为了学习两个句子之间的关系,BERT 策略是在模型中训练一个二分类模型,在分类任务中为模型设置50%的概率,从相应语料库中抽取上下文连续的两句话,利用剩下50%的概率从语料库中抽取上下文不相关的两句话,然后使模型预测这两句话是否上下文相关,通过该方式BERT 可学习到句子级别的向量表示。
2.2 FLAT 层
随着命名实体识别的快速发展,需要将词汇信息融入到深度学习模型。BERT 是基于字符的嵌入编码,无法有效融合词汇特征。在中文实体识别中,由于分词错误将扩大误差,因此一般基于字符的编码形式优于基于词汇编码的序列标注的建模方法。但同时如果不引入词汇信息,由于样本较小,基于序列标注的方法效果欠佳。引入词汇信息可大幅强化实体边界,有效捕捉较长的时间表达式边界。词汇信息引入方式主要有两种:一种为设计动态的抽取框架,可以兼容词汇信息输入;另一种与框架无关,只需在嵌入层融合词汇信息。
本文模型采用第一种方式,通过设计相应结构融入词汇信息。这种方式最早可追溯到Zhang 等[21]提出的一种融合词汇信息的Lattice LSTM 模型,通过词汇信息匹配输入的句子时,会获得一个网状式结构。Lattice 实际上是一个有向的无环图,通过词汇开始和结束字符有效界定格子位置。但由于Lattice LSTM 自身结构原因,存在部分信息损失、计算性能较低。
针对LatticeLSTM存在的问题,李孝男等[22]提出了FLAT(Flat-Lattice Transformer)模型,能够无损地引入词汇信息,通过使用位置编码的方式融合Lattice 结构,对于每一个字符和词汇都为其构建头位置编码与尾位置编码形式。该方式可使建模字符与所有匹配词汇信息有效交互,并设计了字符和词汇之间的3 种关系:交叉、包含、分离,然后将其表示为一个稠密的向量,利用head[i]和tail[i]表示字符和词汇头尾位置,从4 个不同的角度计算xi和xj的距离。
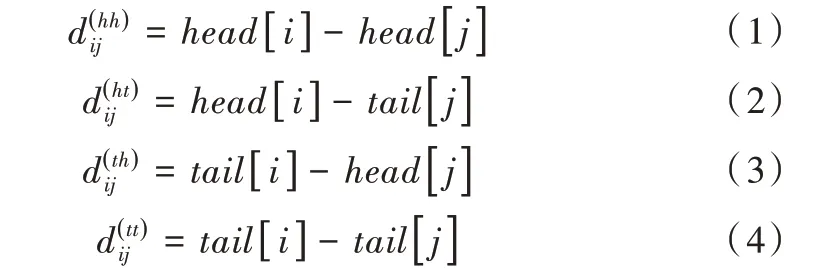
从式(1)—(4)得到4 个相对距离矩阵,其中表示xi开始位置与xj开始位置的距离,其余三者与此类似,然后将这4 个距离进行拼接再作一个非线性变换,得到xi与xj的位置编码向量Rij,如公式(5)所示。

其中Pd采用的是Transformer 中绝对位置编码。

因此字符与词汇之间可以充分且直接交互,使用Transformer-XL[23]中基于相对位置编码的self-attention 机制完成编码,最后取出字编码表示,将其输入CRF 层进行解码得到预测的序列标签。
2.3 CRF 层
针对该层网络结构引入序列标注模型中常用的条件随机场算法。利用BERT 与FLAT 模型寻找时间表达式边界问题,针对相邻标签之间的关系,可用条件随机场确定并进行约束,取得全局最优标记序列。
首先需将输入X=(x1,x2,…,xm)输入CRF 层,大小为n的全连接层得到词语标签分数矩阵sc ∈Rn*n,si j代表词语序列第i个字预测为标签j的分数,假设X的正确标签序列为Y=(y1,y2,…,ym),计算正确标签序列的分数S(X,Y)为:
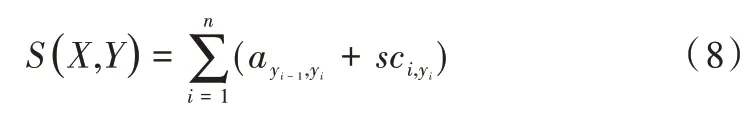
然后通过Softmax 函数归一化得到y序列标签的最大概率,如式(9)所示。

其中,Z代表X所有可能的标签序列。最后取得最大化正确标签序列的似然概率。

根据公式(10)求得的损失计算梯度,不断优化,将损失降到最小,使其预测正确标签的概率尽可能大以调整参数、优化目标。在模型训练后,使用维特比算法求出概率最大的一条标签序列作为最终预测标签,即可得到标签序列识别时间表达式。
3 实验及评估标准
3.1 实验语料
本文使用2010 年SemEval-2010 评测TempEval-2 任务中的中文语料数据集。在TempEval-2 的任务语料中共有44 篇训练文档和15 篇测试文档,作为与其他实验方法的对比语料。
同时由于TempEval-2 语料较少,本文从中文百度百科中随机爬取文档并利用斯坦福分词器对文档进行词性标注工作,获得所有具有时间词标注的句子,并人工修正标注相应标签,共获得3 352 条带有时间表达式的句子,时间表达式数量为3 646 个,以此验证本文模型在深度学习模型中同样具有非常好的效果。本文数据集按照8∶2 的方式划分为训练集和测试集。将2 681 条句子划分为训练集,
671 条句子为测试集。
3.2 标注体系
在用序列标注的方法进行命名实体识别时,最常用的两种标签体系分别为BIO 和BIOES,本文采用较为简洁的BIO 标签方式,在时间类别方面依旧采用SemEval2010(Se⁃mantic Evaluations)task 13 中的方法,将时间表达式类别分为Duration、Set、Time、Date,时间类型说明如表1 所示。BIO标注模式中的B 表示实体开始,I 表示实体中间与结尾,O表示非实体部分,时间表达式类型可划为4 种类别,因此需将标签的体系分为9 种,分别为B-T,I-T 表示时间,B-D,ID 表示日期,B-S,I-S 表示重复时间,B-U,I-U 表示持续时间,O 为非时间表达式部分。本文时间表达式识别使用的数据标注示例如表2 所示。

Table 1 Type description of time表1 时间类型说明

Table 2 Time expression annotation examples表2 时间表达式标注示例
3.3 评估标准
采用正确率P、召回率R 以及F 值作为本文实验评测标准。

3.4 实验环境
本文实验操作系统为Ubuntu,实验详情如表3 所示。

Table 3 Experimental environment表3 实验环境
3.5 实验参数
在Bert 模型中本文选择中文预训练BERT-Base 中文版本进行实验,模型共有12 层,隐含层有768 维度,12 个注意力头,有110M 参数,最大序列长度选择128,batch-size选择16,学习率为5e-5,为防止过拟合采用dropout 为0.5。
3.6 实验结果与分析
在TempEval-2 语料下,本文与文献[10]基于语义角色标注的识别、文献[11]基于“时间基元”的时间表达式识别以及文献[13]基于词典特征优化和依存关系的中文时间表达式识别进行比较,这些方法多为规则和传统机器学习方式,本文通过引入深度学习预训练语言模型、融合时间词汇特征,有效提升模型识别精度。比较结果如表4 所示。

Table 4 Comparison with the traditional time expression recognition method表4 与传统时间表达式识别方法比较
如表5 所示,在深度学习模型中本文方法同样具有较好的效果。
基于IDCNN-CRF、BiGRU-CRF、BiLSTM-CRF、LSTMCNN-CRF 等模型的实际效果相差不大,因为没有引入自然语言处理中的预训练语言模型,其词向量表达能力有限,且捕捉长距离依赖的能力不强,基于Bert-CRF 的模型虽然引入了Bert 模型,较好地解决了长距离依赖与词向量表达局限性,但因为基于字符嵌入,并没有融合时间词汇特征,而本文基于BERT-FLAT-CRF 的模型融合了时间词汇特征,进一步提高了对时间表达式的识别能力。

Table 5 Comparison with deep learning model recognition methods表5 与深度学习模型识别方法比较
4 结语
本文针对时间表达式在传统机器学习方法中需构造大量规则且标注数据集较少、识别困难的问题,提出了一种基于BERT-FLAT-CRF 深度学习网络架构的识别方法。在TempEval-2 数据集中,本文方法可获得更高的正确率93.12%和召回率92.25%,在基于自建数据集的实验中与其它深度学习模型进行比较,证明本文模型在加入时间词汇特征后表现最佳,为中文时间表达式识别问题提供了新的解决方案。下一步将继续挖掘中文时间表达式特点,探索在标签上采用成分标签方案的可行性,使时间表达式结构特点得到充分利用。
