基于Bi-GRU的Webshell检测①
2021-08-02李帅刚王全民
李帅刚,王全民
(北京工业大学 信息学部,北京 100124)
随着我国互联网的突飞猛进,Web 应用在不同场景和业务中变得越来越重要,这也给不法分子提供了数不胜数的Web 漏洞靶场.作为一种常用的攻击工具,Webshell是以asp、php、jsp 等常见的网页文件形式存在的一种代码执行环境,也被叫做网页后门.攻击者通过层出不穷的Web 漏洞进入到后台管理系统后,通常会将php 或者jsp 后门文件与网站服务器Web 目录下正常的网页文件混在一起,然后就可以使用浏览器来访问Webshell,从而进行文件上传下载或者进一步的权限提升.根据国家互联网应急响应中心《2019年上半年我国互联网网络安全态势报告》,CNCERT 检测发现境内外约1.4 万个IP 地址对我国境内约2.6 万个网站植入后门,同比增长约1.2 倍,其中,约有1.3 万个(占全部 IP 地址总数的91.2%)境外IP 地址对境内约2.3 万个网站植入后门.同时,发生在我国云平台上的网络安全事件或威胁情况相比2018年进一步加剧,被植入后门链接数量占境内全部被植入后门链接数量的6 成以上[1].当前检测Webshell的方法如静态规则匹配、日志文件分析以及机器学习分类等,在抵抗灵活多变的逃逸技术时[2],未能有效保护服务器的安全.针对现状,急需一种能够有效检测Webshell的方法.
与正常网页文本的区别在于,Webshell 存在大量系统调用和文件操作函数如eval、system、cmd_shell、readdir 等,攻击者可通过上述特征函数远程操作服务器.因此,可以从文本分类的角度出发识别Webshell.随着深度学习的不断发展,多种算法模型在文本分类中表现优异.本文使用不同的算法模型进行实验对比,结果表明,Bi-GRU的检测效果最佳,能够有效解决当前检测Webshell 存在的问题.
1 相关研究
近年来,对Webshell 检测方法主要分为3 类,分别是基于流量的检测、基于日志的检测和基于文本的检测.
1.1 基于流量的检测
基于流量的检测是在网页文本与服务器通信过程中,通过分析http 请求与响应数据来识别Webshell.王应军[3]从Webshell 客户端工具和Webshell 执行原理的角度出发,对该过程中通信特征进行分析.Starov[4]提出不同类型Webshell 存在某些共性特征,将这些特征作为分类的依据.基于流量的检测,虽然能够达到一定的准确率,但是受限于人工观察样本和复杂的匹配规则.
1.2 基于日志的检测
基于日志的检测通过分析应用程序执行后生成的日志文件,找到异常的请求日志,从而识别出Webshell.石刘洋等[5]通过文本特征匹配,分析文件关联性进行检测,研究总结出Webshell 不常规行为生成的日志与正常日志存在巨大的出入.潘杰[6]采取文本分类SVM对日志进行检测,首先将日志进行聚类,然后对结果进行分析.但是,基于日志的检测方法存在滞后性,即攻击者攻击了系统之后,才会被发现.
1.3 基于文本的检测
基于文本的检测的优势在于发现及时、特征分析方便.孟正等[7]提出了一种基于SVM的检测方法,该方法的准确率为99%,存在的不足之处是恶意样本较少.张涵等[8]提出一种基于多层神经网络的方式来进行检测,将代码序列通过嵌入层转化为向量,然后使用神经网络进行检测.姜天[9]采取卷积神经网络模型检测Webshell,该方法整体效果不错,但评估方法中缺少漏报率等硬性评价指标.周龙等[10]提出了一种基于循环神经网络的方法来检测Webshell,使用TF-IDF 获取特征,以GRU为样本训练模型,不过其准确率还有待提高.
目前,在Webshell 检测的学术研究中常用的算法有SVM、MLP、CNN、RNN 等,这些算法模型有一定的识别Webshell 能力,但还存在准确率较低,误报率和漏报率较高等缺点.
2 本文方法
考虑到php、asp、jsp 等文本形式的Webshell 在语句逻辑上相差不大,且asp和jsp 在当前Web 开发中逐渐被淘汰,因此本文选择php 网页脚本作为研究对象.在特征选择方面,使用Word2Vec 算法[11]将词语转换为特征向量,该算法能够表征词语之间的关联度.在算法模型选择方面,循环神经网络[12]在训练序列数据时表现优异.本文最终选择能够传递正向和反向语句信息的Bi-GRU 作为分类算法,从前后两个方向挖掘语句信息,以提高检测效果.具体的研究过程如图1.

图1 研究过程
2.1 预处理
数据的预处理工作主要包括文件去重和编译获取opcode 指令[13].文件去重的目的是防止数据中出现大量相同的样本,主要是通过计算每个样本的MD5 值,进行比对,然后剔除相同的样本,以防止污染训练数据.完成文件去重之后,需要将php 源码转换为opcode 指令.opcode是php 源码编译之后生成的中间代码,它将php 脚本中可执行语句转换为Zend 支持的135 条指令.php 文件在服务器中的执行流程可分为两步:第1 步启动Zend 引擎,加载开启的扩展模块;第2 步Zend 引擎对php 文件进行一系列操作后得到opcode,然后执行opcode.只要源码中实现Webshell 相关功能,就会在opcode 指令中体现出来.在编译opcode的返回信息中,需要通过正则表达式获取opcode 指令字符串.以最常见的一句话木马webshell为例.

代码1.一句话木马Webshell
其原理是通过post 方式传入一个可执行的方法,然后eval 函数执行该方法,服务器将运行结果通过http 返回给用户,这样就如同拿到管理员权限一样,可以直接对服务器进行操作.通常一句话木马需要配合一些工具来使用.对一句话木马进行编译得到的opcode指令如序列1.

序列1.opcode 指令BEGIN_SILENCE FETCH_R FETCH_DIM_R INCLUDE_OR_EVAL END_SILENCE RETURN
2.2 特征提取
通过预处理后得到opcode 指令字符串,不能被算法模型识别.因此,需要提取样本的特征向量,以数字的形式输入到算法模型中.本文使用Word2Vec 获取文本特征向量.
Word2Vec 在自然语言处理中被大量的使用,它通过无监督的方式从语料库中学习词语之间的相似性,然后将每个词用一个向量来表示,从而用向量表征词的语义信息.最早的文本向量化技术如onehot 编码,通过建立一个语料库大小的一维向量,只是简单的将单词所在的位置设为1,其他位置设为0.通过上述方式得到的向量存在维度灾难、无法表征词语之间的语义信息等问题.而上述问题,在Word2Vec中可以被很好的解决.Word2Vec 模型结构有两种,一个是CBOW(Continuous Bag Of Words)模型,通过给定上下文来预测输入的值;另一个是Skip-Gram,通过给定输入的词,来预测上下文.后者的结构如图2所示,输入层用onehot 编码的向量,输出层通过一个Softmax 函数输出0-1 之间的值,表示当前词语与输入词之间的相似性,所有输出层的值和为1.在隐层中定义词语需要转换的维度,该层中的权重矩阵是网络学习的最终目标.本文选择Skip-Gram.

图2 Skip-Gram 结构[11]
2.3 深度学习算法
本文提出一种基于深度学习的Webshell 检测算法模型,该模型使用GRU 作为神经网络结构.GRU(Gated Recurrent Unit)[14]是LSTM (Long Short-Term Memory)的简化变体,其结构如图3所示.它将LSTM最初的3个门,输入门、输出门和遗忘门合并为重置门和更新门.这样,即可以解决RNN 在训练过程中的梯度消失和梯度爆炸的问题,同时又能使计算开销减小.GRU的输入输出结构与普通的RNN 一致,存在一个xt和上个节点传递下来的隐状态(hidden state)ht−1,该参数保留了前一序列状态的信息,同时也作为GRU的输入的值.通过当前节点的输入xt与上一节点的保留信息ht−1计算两个门控制状态.

图3 GRU 结构图[14]
图3中,zt为更新门(update gate),定义了前面记忆保存到当前时间步的多少,计算过程如式(1)所示,其中Wz表示权重,使用σ函数将结果控制在0~1 之间,结果值越大,保留之前的信息就越多.重置门(reset gate)决定了对之前序列信息的遗忘程度,公式如式(2)所示,整个步骤与更新门一致.h′t用来表示当前序列记忆内容,计算过程如式(3)所示,重置门起到遗忘多少保留信息的作用,使用tanh 作为激活函数.ht的作用是保留当前单元的信息并传递到下一个单元中,使用更新门来决定当前记忆内容和上一个序列中需要保留的信息,其计算公式如式(4)所示.


2.4 实验框架
本文实验框架如图4所示.样本通过嵌入层将每个opcode 指令转换为特征向量,接着输入到Bi-GRU中,将正向通过GRU输出的隐状态与反向通过GRU输出的隐状态拼接,从正向和反向获取样本中上下文信息.值得一提的是,本文选择将双向GRU的输出值作为全连接层的输入,该层输出一维向量,然后使用Softmax函数计算最终的概率,如式(5)所示.将模型输出值与0.5 进行比较,如果大于0.5,说明为正常样本,否则为Webshell[15–17].
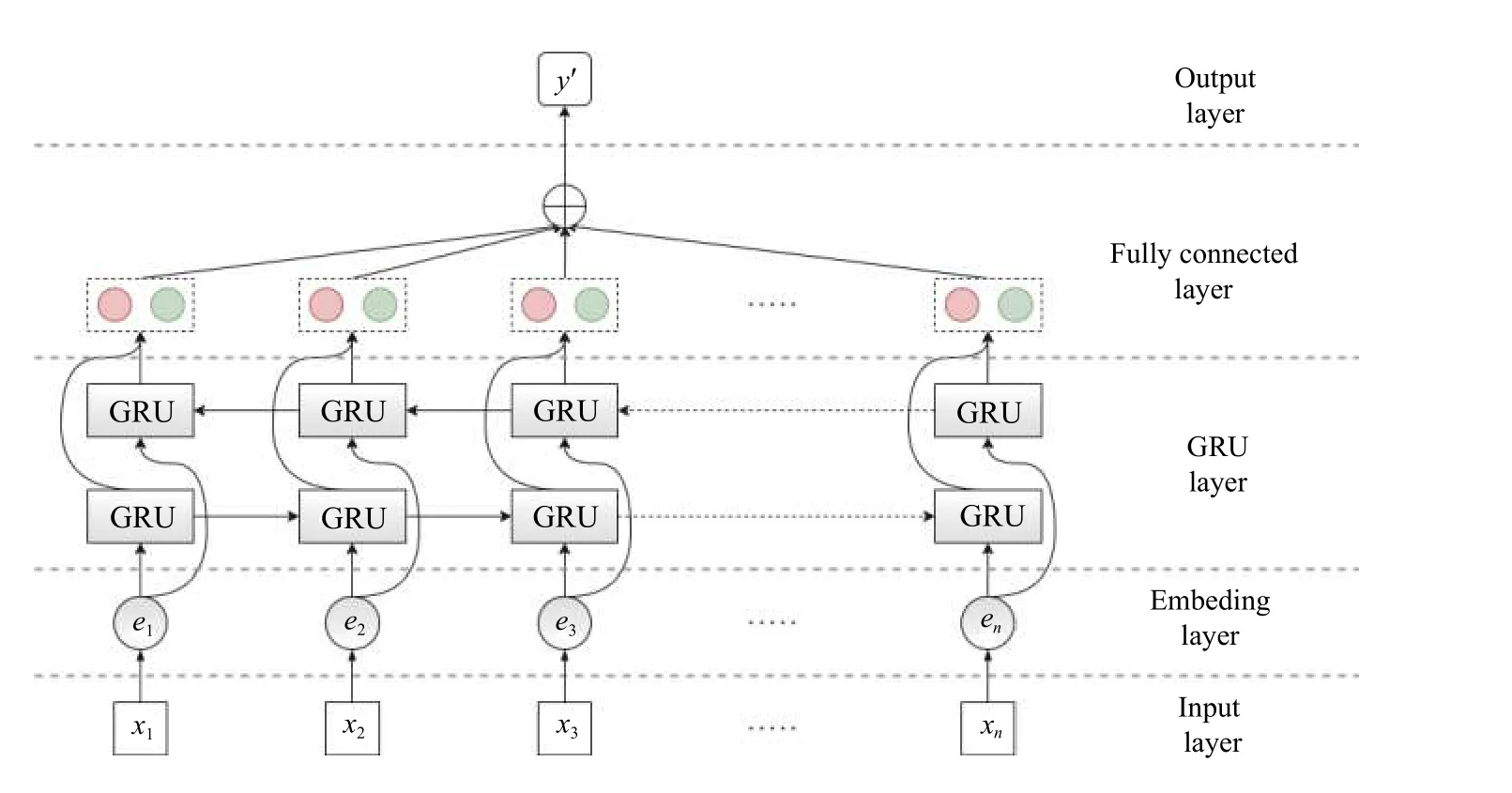
图4 实验框架

3 实验过程
3.1 实验数据来源
实验数据分为Webshell 样本和正常网页文本.其中Webshell 样本来源于Github 排名靠前的仓库如phpwebshells、webshellSample 等.正常样本来源于,当前用户量较大的php 框架如Thinkphp、WordPress 等.其中部分数据来源如表1所示.由于不同Webshell 所使用的php 版本存在不一致的情况,这造成部分样本编译opcode 失败,因此在编译opcode 指令过程中直接忽略报错的样本.为了方便进行后续分类,本文将正常样本的标签设置为1,而Webshell 样本设置0.

表1 数据来源
对原始样本进行编译后,最终得到5830 样本,其中正常脚本个数为4664,Webshell 脚本个数为1166,两者比例约为4:1.
3.2 实验参数
系统结构如图4所示,每个样本中opcode 指令的个数为400,超出的部分直接划掉,不足的样本用0 填补.通过Word2Vec 训练后,opcode 指令转换为特征向量,维度为128,将其输入到Bi-GRU中进行训练.在GRU 层中,正向和反向中GRU 单元的个数都为128,选择dropout为0.2 防止过拟合的产生.输出层中的激活函数为Softmax.
实验采用Adam 优化算法,学习率为0.01,损失函数使用交叉熵.其中训练集和验证集的比列为8:2,共计训练5个epoch.
3.3 评估标准
本实验是一个二分类问题,选择准确率、假正率和假负率作为模型评估的标准.Webshell 样本可看作负样本,正常样本为正样本.根据表2定义混淆矩阵.

表2 混淆矩阵
准确率(Accuracy,Acc),表示预测结果正确的比率,计算过程如式(6)所示.

假正率(False Positive Rate,FPR),表示Webshell被预测为正常样本的比率,可作为漏报率,计算过程如式(7)所示.

假负率(False Negative Rate,FNR),表示正常样本被预测为Webshell的比率,可作为误报率,计算过程如式(8)所示.

3.4 实验与分析
为了验证Bi-GRU的有效性,本文共使用了7 种算法进行对比分析.在SVM和MLP的训练过程中,特征向量皆为原始样本的opcode 指令.卷积神经网络算法使用TextCNN[18]的模型结构,将单个文本转换为二维向量,建立卷积层,从图片角度对文本进行分类.在循环神经网络的算法模型中,分别比较了LSTM、Bi-LSTM和GRU 模型的分类效果.最终实验数据如表3所示.

表3 实验数据
从表3中可以看出,Bi-GRU 算法明显优于其他算法.Bi-GRU 在文本分类中的准确率最高,达到了98%,高于GRU 约1.2%,是因为Bi-GRU 获取的是文本中双向记忆信息,结构更复杂.同时,LSTM和Bi-LSTM在识别Webshell的准确率上表现差劲,分别为93%和89%,其他3 类算法中CNN的准确率表现较好,但准确率低于Bi-GRU 约1.1%,说明CNN 并不适用于Webshell的检测.在7 种算法模型中,Bi-GRU的漏报率最低,为3.5%左右,但是误报率稍逊于SVM和CNN,但在真实的检测环境下,更应该关注其漏报的情况.
图5是所有分类算法训练结果计算出的ROC 曲线,其中Bi-GRU、GRU、CNN 更加靠近左上角,说明分类效果远超其他4 类算法.Bi-GRU 将样本的中的每个opcode 当做序列,前面时间步的信息会被保留下来,作为本时间步喂养的数据.在模型训练的过程中,学习Webshell 上下文中特殊的函数组合与语句逻辑,将学习到的内容作为识别Webshell和正常样本的依据.同时,从正反两个方向中发现语句的关联信息,对Webshell的识别也起到了很大的帮助.

图5 ROC 曲线
4 总结
本文提出了一种基于Bi-GRU的Webshell 检测方法,以php的opcode 作为原始数据,设定样本中opcode指令的个数为400,使用Word2Vec 获取特征向量,采用七种不同的算法模型进行对比试验,得出Bi-GRU的模型在检测Webshell的准确率、漏报率上明显优于其他算法模型,但是在误报率上还存在不足.
在接下来的研究中,考虑使用词袋模型对样本中的opcode 指令进行切分组合,结合TF-IDF 获取词频特征,尝试其他文本分类模型如图卷积神经网络,解决误报率高的问题,进一步提高模型检测Webshell的效果.
