融合机器学习与知识推理的可解释性框架①
2021-08-02李迪媛康达周
李迪媛,康达周
1(南京航空航天大学 计算机科学与技术学院/人工智能学院,南京 211106)
2(南京航空航天大学 高安全系统的软件开发与验证技术工信部重点实验室,南京 211106)
3(软件新技术与产业化协同创新中心,南京 210023)
机器学习[1]是计算机基于数据进行和改进预测或行为的一组方法[2],在效率、规模、可重复性等方面相较人类更加出色.因此,利用机器学习技术可以解决现实中很多领域的问题,如自动驾驶[3,4]、医疗诊断[5,6]、自然语言处理[7]等.
在很多重要领域,机器学习结果对最终决策具有重大影响.例如,使用机器学习技术实现的宫颈癌细胞图像自动识别系统,其识别结果能够辅助医师诊断宫颈癌,这不仅大幅度降低了人工成本,还提高了识别效率.然而,机器学习模型作为缺少可解释性的黑盒,人们不理解它为什么会做出某种特定的决策,其输出结果不能让人完全信任.比如说,医师很难信任缺少可解释性的宫颈癌细胞图像自动识别系统的结果.因此,赋予机器学习系统可解释性非常重要.
可解释性是人们能够理解决策的方法[8].在机器学习系统的上下文中,它是向人类解释或以可理解的术语呈现的能力[9].从本质上讲,可解释性是人类和决策模型之间的接口,它既是模型的准确代理,又是人类可以理解的[10].可解释性能够让人类明白系统做出决策的逻辑,还可以帮助人们更好地了解结果可能失败的原因.
机器学习可解释性分为本质可解释性和事后可解释性两类.本质可解释性意味着机器学习模型自身具有可解释性,一般在模型较为简单时实现,例如线性回归模型,它将目标预测为特征输入的加权和,所学到的线性关系使解释变得容易[11];决策树模型通过遍历决策树的节点(类别和属性)、根节点到叶子节点的路径(决策规则),提供对简单模型决策过程的模拟实现[12].事后可解释性是利用可解释性技术来解释复杂机器学习模型,例如基于个体条件图的可解释性模型,它为每个实例显示一条线,该线显示了特征更改时实例的预测如何改变[13];基于规则的可解释性模型通过从受训模型中提取解释规则的方式,提供对复杂模型尤其是黑盒模型的整体决策的逻辑的理解[14].该模型旨在以人类可理解的规则对模型做出特定决策的逻辑进行解释,但是当它的规则或决策出现错误时,可解释性将无法反映模型的真实决策情况.为了解决这个问题,可以思考一下人类是如何进行决策以及对决策结果进行解释的.
很多情况下,人类利用感知和推理共同完成决策[15].比如说,医师在判断一个宫颈细胞是否发生病变时,他首先能够根据自己的筛查经验,对细胞图像展现出来的细胞整体特征进行感知,得出一个大致的结论.然后,医师基于宫颈细胞病变相关的医学知识,对细胞的每个细胞形态学特征(例如细胞核大小、核质比高低等)进行观察,并结合这些特征和知识推理出另一个结论.医师会结合、对比两个结论,得出最终的诊断结果,并使用相关的医学知识来解释得出此诊断结果的原因.整个过程如图1所示.

图1 医师判断宫颈细胞是否病变
基于上述思路,本文提出了一种融合机器学习和知识推理两种途径的可解释性框架.它包含两个结果,一个是由机器学习模型感知整体特征得到的目标特征结果,另一个是通过结合多个子特征结果和规则进行知识推理得到的推理结果.框架结合两个结果,根据它们是否相同、分别是否可靠的不同情况,来做出相应不同的演进决策.这使得框架在训练和测试过程中不断提高结果的分类准确率,同时赋予真实决策结果以可解释性,在很大程度上解决了机器学习模型缺少可解释性的问题.本文为衡量推理结果是否可靠,提出了一种评估方法,它融合了多个机器学习结果和规则的参数.
本文使用面向液基细胞学检查图像的融合学习与推理的某类宫颈癌细胞识别这一案例,对融合机器学习和知识推理两种途径的可解释性框架进行了说明和验证.
1 融合机器学习与知识推理的可解释性框架
本文提出的融合机器学习与知识推理的可解释框架,包含知识推理模块、机器学习模块、知识推理融合机器学习模块,如表1所示.该框架的示意图如图2所示.

图2 融合机器学习与知识推理的可解释性框架示意图

表1 框架模块表
其中,决策目标是指一个系统预期达到的目的,目标特征是指决策目标的整体特征,目标特征具有多个子特征,它们是专家知识和数据之间的关联特征.例如,对于上文提到的诊断宫颈细胞是否病变的例子,决策目标是识别宫颈细胞图像是否展现出癌变细胞的特征,目标特征是宫颈细胞的整体特征,而子特征是细胞形态学特征(细胞核大小、核质比高低等).
1.1 知识推理模块
知识推理模块提供了用于推理决策的领域知识和业务规则,即决策目标相关的本体库O和规则库K.根据决策目标相关的领域知识,通过知识抽取、融合、加工的步骤,构建用于决策目标的本体库O,它表达了与决策目标有关的类和类之间的关系.本体库O支持网络本体语言(Ontology Web Language,OWL),其中目标特征类包含子特征类.将获取到的有关决策目标的专家知识转化为业务规则,组成规则库K,它支持语义网规则语言(Semantic Web Rule Language,SWRL).知识推理模块的示意图如图3所示.

图3 知识推理模块示意图
1.2 机器学习模块
机器学习模块提供了包含一个目标特征分类器C和多个子特征分类器C1~Cn的分类器组,其结果用于推理决策和结果演进.分类器组通过神经网络组结合数据集D、D1~Dn训练得到.神经网络组由一个目标特征分类神经网络N和n个子特征分类神经网络N1~Nn组成.数据集D用于训练N,D的数据标注以决策目标为分类标准;数据集D1~Dn分别用于训练N1~Nn,D1~Dn的数据标注分别以它们对应的子特征为分类标准.机器学习模块的示意图如图4所示.

图4 机器学习模块示意图
1.3 知识推理融合机器学习模块
(1)提取子特征
基于提取的子特征,知识推理模块中本体库O构建子特征类,机器学习模块构建子特征分类器.子特征是与决策目标有关的专家知识和数据之间的关联特征.其中,专家知识中高频提及的概念为知识特征,数据本身的特征为数据特征,将知识特征与数据特征进行关联和对应,所重合的特征为子特征.根据决策目标相关的知识特征和数据特征,框架提取出n个子特征f1~fn.那么,第1.1 节的本体库O的子特征类依据f1~fn构建;第1.2 节的数据集D1~Dn,其标注类别分别以f1~fn为分类标准,所构建的n个子特征分类器C1~Cn也分别以f1~fn为标准来分类待分类数据.
(2)支持机器学习结果的知识推理
一个待分类数据t经过分类器组,得到目标特征分类器C的分类结果Rc、子特征分类器C1~Cn的分类结果R1~Rn.将R1~Rn分别映射为本体库O中其对应的子特征类的实体数据,并基于本体库O和规则库K进行知识推理,得到推理结果Rr.结果Rc、Rr都为目标特征结果,即框架做出数据t为Rc、Rr的决策.后续将对两个目标特征结果Rc和Rr进行演进,实现结果的可解释性.
(3)机器学习结果结合推理结果演进
结合目标特征结果Rc(机器学习结果)和目标特征结果Rr(推理结果)进行演进,框架根据Rc和Rr是否相同、Rc和Rr分别是否可靠的不同情况,做出相应不同的决策.为衡量结果是否可靠,本文引进评估结果好坏的指标——可信度.分别计算目标特征结果Rc的可信度ARc和目标特征结果Rr的可信度ARr,然后结合两个结果进行演进,具体情况和每种情况对应的决策如表2所示.

表2 决策表
表2中,a为阈值,它由具体案例所属领域的专家或多次案例实验结果决定,案例对结果精度要求越严格则阈值越高.对于任何案例来说,结果精度要求再低也不能差于在正反类中随机选择一类的情况,精度要求再高也不可能好于类别全部预测正确的情况,因此a的取值区间在(0.5,1).通过对比ARc、ARr和a之间的大小关系,框架判断Rc和Rr是否可靠.在Rc和Rr相同且两个结果的可信度都较高的情况下,框架实现可解释性,即使用子特征分类器C1~Cn的分类结果R1~Rn、知识推理使用到的规则库K中的规则,来解释框架做出数据t为Rc(Rr)的决策的逻辑.在Rc和Rr相同且其中一个结果可信度较低的情况下,框架提升得到低可信度结果的分类器和规则库的信任:如果低可信度结果为Rr,则适当提高证据链中的参数值,证据链在下一节中描述;如果低可信度结果为Rc,则适当降低阈值a.在Rc和Rr不同且其中一个结果可信度较低的情况下,框架将优化和改进得到低可信度结果过程中使用到的分类器、规则库.
本文规定可信度ARc为目标特征分类器C观察Rc的概率值P与分类器C在验证集上的准确率Acc的几何平均值;ARr是融合了机器学习结果R1~Rn的参数值(例如结果概率值、灵敏度)和规则库K的参数值的综合评估值,具体计算方法在下一节描述.ARc考虑了Rc本身的可信程度和得到Rc的分类器C的性能,ARr考虑了推理Rr过程中使用到的数据R1~Rn本身的可信程度、得到R1~Rn的分类器C1~Cn的性能、规则库K的可靠度.因此,使用可信度衡量结果质量是较为充分的.
2 计算推理结果可信度
推理结果Rr是由支持机器学习结果的知识推理得到的.知识推理过程中规则使用的实体数据,都是由子特征分类器的结果映射而来,不一定正确.因此,Rr也可能是不正确的.那么,如何对融合了多个机器学习结果和规则的目标特征结果进行评估呢?本文提出了一个定义−结果证据链,它是有向无环图数据结构.结果证据链将记录得到Rr过程中一些重要的参数值.本文基于结果证据链的结构,自底向上地计算Rr的可信度ARr,以评估Rr是否可靠.
结果证据链是实现可解释性的另一关键部分,它使得在Rr失败时可能追溯到具体的原因.
2.1 结果证据链
定义1.结果证据链.结果证据链是一个有向无环图(Directed Acyclic Graph,DAG),记为三元组G=
结果证据链的节点,包括推理结果Rr、子特征分类器结果R1~Rn、R1~Rn的相关参数、基于的规则库K、K的相关参数,它们是V集合的组成元素.其中,子特征分类器结果Ri的相关参数,包括子特征分类器Ci观察Ri的概率值Pi、其在验证集上的灵敏度(sensitivity)Mi和特异度(specificity)Yi;规则库K的相关参数,是人为对K可靠性的评估值Kr,它的区间是[0,1].
本文使用知识图谱KG来表示结果证据链G.知识图谱通常用于表示和管理知识库[16],采用三元组描述事实[17].本文采用自顶向下的方法建立KG:
(1)将推理结果Rr与子特征分类器结果R1~Rn之间分别建立三元组
(2)将Rr与基于的规则库K之间建立三元组
(3)将子特征分类器结果Ri与它的相关参数之间分别建立三元组
(4)将规则库K与它的可靠性评估值Kr之间建立三元组
表示结果证据链G的知识图谱KG结构如图5所示.那么,G中存储了得到Rr过程中一些重要的参数值.

图5 结果证据链G 结构图
2.2 推理结果评估
计算ARr的方法使用了DS 证据理论的思想,它是一种不精确推理理论,被广泛应用于证据(数据)合成方面.DS 证据理论首先设辨识框架θ,它包含了所有假设;然后为每一个假设分配概率,分配函数称为Mass函数;最后基于Dempster 规则融合结果,即:

本文首先计算每个结果的灵敏度和特异度参数值.假设真阳性数量为TP,假阳性数量为FP,真阴性数量为TN,假阴性数量为FN,灵敏度M和特异度Y的计算公式如下:

即灵敏度为正确判断阳性的概率,而特异度为正确判断阴性的概率.然后,对ARr进行计算:
(1)定义Map 函数来表示每个Ri与Ri相关参数之间的映射关系,即Pi=m1(Ri)、Mi=m2(Ri)、Yi=m3(Ri);
(2)求归一化系数S:

其中,n为Ri的个数;
(3)融合子特征分类结果R1~Rn的参数,计算机器学习部分的可信度Ae:

其中,Wfi为Ri对应子特征fi的权重,视具体案例而定;
(4)融合机器学习部分的可信度Ae、规则库K的评估值Kr,计算可信度ARr:

后续将通过面向液基细胞学检查图像的融合学习与推理的某类宫颈癌细胞识别这一例子,对可解释框架进行具体地说明.
3 面向液基细胞学检查图像的融合学习与推理的某类宫颈癌细胞识别
宫颈癌是一个严重的健康问题,全世界每年有近50 万妇女患此病[19].宫颈癌筛查对于早期预防有着非常重要的作用,而宫颈鳞状上皮异常对于宫颈癌的诊断有重大意义[20].
3.1 子特征提取
根据宫颈鳞状上皮细胞图像和ASC-H 细胞形态学的专家知识,本文提取出了4个子特征f1~f4,如表3所示.

表3 ASC-H 细胞子特征表
本文选择对宫颈鳞状上皮异常中的非典型鳞状细胞-不除外高度鳞状上皮内病变(Atypical Squamous Cells:cannot exclude High-grade squamous intraepithelial lesion,ASC-H)细胞进行识别,以验证可解释框架的可行性.ASC-H 细胞识别框架在识别精度上有所提升,同时实现了识别结果的可解释性,在医师使用该识别框架时,能够根据框架给出的解释选择是否信任结果.值得一提的是,宫颈癌筛查的过程中应该避免假阴性,即避免本来病变的细胞被认为是没有病变的情况.因此,ASC-H 细胞识别框架将疑似ASC-H 也作为识别的一类,以避免漏掉病变细胞.
3.2 本体库和规则库构建
(1)本体库O
本文从有关ASC-H 细胞形态方面的医学知识中抽取出识别ASC-H 细胞的类和类之间的关系,并使用OWL 语言构建ASC-H 细胞识别本体库O,构建平台为Protégé.该本体的类信息如表4所示.
表4中Cell_size、N/C、Nucleus_size、Hyperchromatic为子特征类;ASC-H、Sus-ASC-H、Non-ASC-H为目标特征类.ASC-H 细胞识别本体的属性信息如表5所示.

表4 ASC-H 细胞识别本体库的类信息表

表5 ASC-H 细胞识别本体库的属性信息表
在Protégé中为4个子特征类添加实例,实例为每个子特征的类别.为Cell_size 添加实体:中等细胞(c_l)、小细胞(c_s),为N/C 添加实体:核质比高(nc_l)、核质比低(nc_s),为Nucleus_size 添加实体:细胞核增大(nu_l)、细胞核正常(nu_s),为Hyperchromatic 添加实体:细胞核重度深染(h_l)、细胞核轻度深染(h_s).通过上述步骤,ASC-H 细胞识别本体创建完成.
(2)规则库K
规则库K包括4个规则,由ASC-H的细胞形态医学专家知识转化而来.
1)规则1.细胞组成部分的性质也是细胞的性质.SWRL 规则如rule1 所示:
rule1:is_part_of(?a,?b) ^ hasProperty(?a,?c) ->hasProperty(?b,?c)
对规则1的解析如下:is_part_of(?a,?b)表示a是b的组成部分;hasProperty(?a,?c)表示a 具有c 性质;hasProperty(?b,?c)表示b 具有c 性质.
2)规则2.细胞形态中,小细胞、核质比高、细胞核增大、细胞核轻度深染全部符合,则认为细胞是ASC-H.SWRL 规则如rule2 所示:
rule2:Squamous_epithelial_cell(?t) ^ hasProperty(?t,c_s) ^ hasProperty(?t,nc_l) ^ hasProperty(?t,nu_l) ^hasProperty(?t,h_s) ->ASC-H(?t)
对规则2的解析如下:Squamous_epithelial_cell(?t)表示t是Squamous_epithelial_cell 类的一个实例;hasProperty(?t,c_s) 表示t 具有小细胞的性质;hasProperty(?t,nc_l) 表示t 具有核质比高的性质;hasProperty(?t,nu_l)表示t 具有细胞核增大的性质;hasProperty(?t,h_s)表示t 具有轻度深染的性质;ASCH(?t)表示t为ASC-H 细胞.文章后面的SWRL 规则都与规则2 类似,因此不再做详细解析.
3)规则3.细胞形态中,核质比高、细胞核增大有任意一项符合,则认为细胞是疑似ASC-H.SWRL 规则如rule3a、3b 所示:
rule3a:Squamous_epithelial_cell(?t) ^ hasProperty(?t,nc_l) ->Sus-ASC-H(?t)
rule3b:Squamous_epithelial_cell(?t) ^ hasProperty(?t,nu_l) ->Sus-ASC-H(?t)
4)规则4.细胞形态中,小细胞、核质比高、细胞核增大、细胞核轻度深染全部不符合,则认为细胞不是ASC-H.SWRL 规则如rule4 所示:
rule4:Squamous_epithelial_cell(?t) ^ donot-hasPro perty(?t,c_s) ^ donot-hasProperty(?t,nc_l) ^ donot-has Property(?t,nu_l) ^ donot-hasProperty(?t,h_s) ->Non-ASC-H(?t)
3.3 数据集和分类器组构建
(1)数据集
数据集D和D1~D4都由数个大小为128×128的宫颈鳞状上皮细胞图像组成.D的标注类别为细胞类型,D1~D4的标注类别依据子特征f1~f4,如表6所示.

表6 数据集标注类别表
(2)分类器组
目标特征分类神经网络N的架构是任意用于分类的神经网络模型,本文选取了自己搭建的卷积神经网络(Convolutional Neural Networks,CNN)、变分自编码器(Variational Auto-Encoder,VAE)、CNN 经典模型——VGG19 这3 种模型分别实现3 种目标特征分类器.例如,在使用VAE 作为N的架构时,其损失函数为VAE 理论上的损失函数:

其中,j是隐变量的维度,μ、σ2是隐变量的变分概率分布的均值和方差.使用数据集D对N进行训练:当经过30000 步训练或 L达到目标值时,停止训练并保存当前模型.该模型为目标特征分类器C,它将按照ASC-H细胞形态的整体特征的标准来分类细胞.
子特征分类神经网络N1~N4的架构是任意用于分类的神经网络模型,本文均选用CNN 实现4个子特征分类器.子特征分类神经网络N1~N4均使用交叉熵作为损失函数:

其中,k是分类的类别数量,yi为指示变量(0 或1),如果该类别和样本i的类别相同就是1,否则是0.使用数据集D1~D4对N1~N4进行训练:当经过10000 步训练或 L达到目标值时,停止训练并保存当前模型.这4个模型为子特征分类器C1~C4,它们分别按照细胞大小、核质比高低、细胞核大小、细胞核染色程度的标准来分类细胞.
那么,分类器组由1个目标特征分类器C和4个子特征分类器C1~C4组成.
3.4 支持机器学习结果的知识推理
假设将一个待识别细胞图像t输入到ASC-H 细胞识别框架,它经过分类器组后,目标特征分类器C得到目标特征结果Rc;子特征分类器C1~C4得到4个子特征结果R1~R4,将R1~R4映射为ASC-H 细胞识别本体库O中对应的子特征类(Cell_size、N/C、Nucleus_size、Hyperchromatic)的实体数据,并基于本体库O和规则库K进行知识推理,得到推理结果Rr.后续将对两个结果Rc和Rr进行演进,实现结果的可解释性.
3.5 机器学习结果结合推理结果演进
(1)计算可信度
计算目标特征结果Rc的可信度ARc,它为分类器C观察Rc的概率值P与C 在验证集上的准确率Acc的几何平均值.
计算目标特征结果Rr的可信度ARr,首先要根据2.1 节的方法构建目标特征结果Rr的结果证据链G.然后,根据2.2 节的计算方法,基于结果证据链G的结构,自底向上地计算目标特征结果Rr的可信度ARr.对于本ASC-H 细胞识别案例,核质比高低、细胞核大小这两个子特征在提取的细胞特征中相对更为重要.因此,本文设置f1~f4的子特征权重值分别为:Wf1=0.2,Wf2=0.4,Wf3=0.3,Wf4=0.1.
(2)分析处理结果
根据Rc、Rr、ARc、ARr的情况,框架如1.5 节所述的方法做出不同的演进决策.多次实验表明,将ASC-H细胞识别案例的阈值a取值为0.8 最合适.
4 验证ASC-H 细胞识别框架
验证集由400个大小为128×128的宫颈鳞状上皮细胞图像组成.本文实现了3.3 节中3 种目标特征分类器.为方便计算每种分类器的评估值,将正类设为Non-ASC-H,负类设为Sus-ASC-H和ASC-H的总合.在经过不同大小的数据集训练后,每种分类器在验证集上的准确率、F1 值如表7所示.

表7 每种分类器的评估值表
通过框架中支持机器学习结果的知识推理方法,得到验证集里每个样本的推理结果,并使用文中提出的方法,将每个样本的目标特征分类器结果结合其推理结果进行演进.每种目标特征分类器在结合了支持机器学习结果的知识推理方法进行演进后,准确率和F1 值均有所提升,如表8所示.每种分类器在不同数据集大小下演进前后的准确率比较如图6、图7、图8所示.

图6 数据集大小为1000 时演进前后准确率对比图

图7 数据集大小为2000 时演进前后准确率对比图

图8 数据集大小为3000 时演进前后准确率对比图

表8 每种分类器实现演进后的评估值表
实验表明,文中提出的机器学习结果结合推理结果演进方法总会提升目标特征分类器的性能,并且在分类器自身精度较低时,提升的效果更加明显.当分类器在训练过程中使用的数据量和自身精度都达到了比较饱和的程度时,演进方法对于提升分类器性能方面的作用会较小.通过结合推理结果,演进方法总能将目标特征分类器的一部分错误结果剔除,并且在不断地使用框架对细胞分类时,演进过程也在进行迭代,目标特征分类器将被持续优化.
本文使用3个具体的实例来验证ASC-H 细胞识别框架.该框架在应用于医学领域时,VAE为最合适的目标特征分类器,因为它在分类细胞的同时将细胞样本映射为空间分布,便于医师在近似分布的细胞图像群中划分细胞类型.因此,选择数据集大小为3000的VAE 分类器,它在验证集上的准确率Acc=0.7925.
实例a.将一个待识别细胞图像输入到ASC-H 细胞识别框架,细胞图像如图9(a)所示.它经过分类器组后,分类器C得到目标特征结果Rc为Non-ASC-H;分类器C1~C4得到的4个子特征结果R1~R4分别为中等细胞、核质比低、细胞核正常、细胞核重度深染,结合R1~R4、ASC-H 细胞识别本体库O、规则库K的rule4规则进行知识推理,得到推理结果Rr为Non-ASC-H.
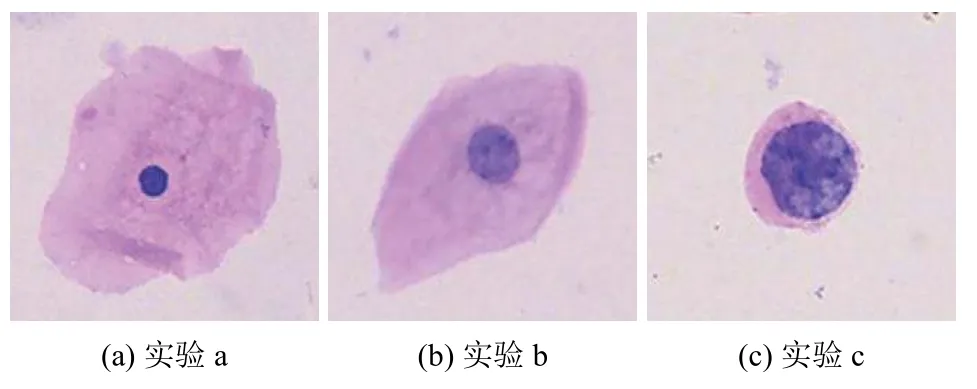
图9 待分类细胞图像
Rc的可信度ARc=0.84.Rr的结果证据链G的节点值如表9所示.

表9 实例a中Rr 结果证据链G的节点值表
如第2.1 节所述,规则库K的参数Kr是人为对K的评估值.在本实例中,Kr=0.75.根据第2.2 节的计算方法,计算Rr的可信度ARr:
1)使用式(1)求归一化系数S=2.43;
2)使用式(2)求机器学习部分的可信度Ae=0.77;
3)使用式(3)得到Rr的可信度ARr=0.76.
Rc和Rr相同,Rc的可信度ARc高于0.8,Rr的可信度ARr低于0.8.如1.5 节所述,框架做出细胞为Non-ASC-H的决策,并更加信任得到Rr过程中的分类器C1~C4和规则库K,因此人工适当地提高结果证据链G中较低的参数值,例如Y1、Y4和Kr.
实例b.将一个待识别细胞图像输入到ASC-H 细胞识别框架,细胞图像如图9(b)所示.框架得到Rc为Sus-ASC-H;Rr为Non-ASC-H.
Rc的可信度ARc=0.87.除Pi外,Rr的结果证据链G的节点值因实例a 人工修改Y1、Y4和Kr而产生变化,如表10所示.

表10 实例b中Rr 结果证据链G的节点值表
在本实例中,Kr=0.80.根据相同计算方法,得到S=2.45、Ae=0.76、ARr=0.78.
Rc和Rr不同,ARc高于0.8,ARr低于0.8.因此,框架做出细胞为Sus-ASC-H的决策,并优化得到Rr的分类器和规则库的规则.根据结果证据链G记录的参数值,可以发现基于的规则库的可靠性评估值Kr不高,即规则库可能存在错误;分类器C1的特异度较低,即C1正确判断中等细胞的概率偏低.根据Rr失败的原因,对规则库K的规则进行检查,如有错误进行修正;对C1进行优化,以提高框架的分类精度.
实例c.将一个待识别细胞图像输入到ASC-H 细胞识别框架,细胞图像如图9(c)所示.框架得到Rc为ASC-H;Rr为ASC-H.
Rc的可信度ARc=0.85.除Pi外,Rr的结果证据链G的节点值因实例b 对规则库K和分类器C1优化而产生变化,如表11所示.

表11 实例c中Rr 结果证据链G的节点值表
在本实例中,Kr=0.85.根据相同计算方法,得到S=2.54、Ae=0.77、ARr=0.81.
Rc和Rr相同,且两个结果的可信度都高于0.8,框架认为Rc和Rr都较为可靠.因此,框架做出细胞为ASC-H的决策,并使用子特征结果小细胞、核质比高、细胞核增大、轻度深染,以及规则库K的rule2 规则,对细胞图像t为ASC-H 这一决策进行解释说明.因此,医师可以理解框架将此细胞识别为ASC-H的逻辑,并根据解释来决定是否相信该识别结果.
可以看出,实例b 通过结果证据链G找到了Rr失败的原因,基于这些原因对相应的部分进行优化后,实例c中框架的分类精度有所提升.在两个结果都相同且较为可靠时,框架赋予结果可解释性,很大程度上解决了规则无法反映模型的真实决策情况的问题.
5 结论与展望
本文提出了一种融合机器学习和知识推理的可解释框架,该框架在提升分类精度的同时,实现了机器学习结果的可解释性.通过面向液基细胞学检查图像的融合学习与推理的某类宫颈癌细胞识别方法对框架进行验证,说明该方法可靠可行.所提出的可解释框架对实现机器学习模型的可解释性具有一定参考意义.
