融合双注意力与多标签的图像中文描述生成方法①
2021-08-02孙小强李婷玉刘志刚
田 枫,孙小强,刘 芳,李婷玉,张 蕾,刘志刚
1(东北石油大学 计算机与信息技术学院,大庆 163318)
2(中国石油天然气股份有限公司 冀东油田分公司 信息中心,唐山 063004)
图像是目前信息传播的主流媒介之一,随着成像设备的普及,图像数据量增长迅速.然而图像以像素的形式存储,这与用户对图像的解读之间存在巨大的差异,高效地对海量图像资源进行检索和管理极具挑战性.如何使计算机依照人类理解的形式对图像进行描述,已是目前图像理解领域的研究热点.
图像描述(Image Caption,IC)[1,2]是指计算机针对给定的图像,自动地以符合人类语法规则的句子将该图像的画面内容进行转换.句子不仅可以作为图像检索的元数据,从而提升对图像资源的检索和管理效率;而且相比词汇标签能更形象、直观地传达图像内容,因此图像描述任务吸引了众多研究者关注.现有的图像描述研究可分为3 类,分别是基于模板的图像描述生成方法[3]、基于检索的图像描述生成方法[4]以及基于翻译的图像描述生成方法[5–10],其中基于翻译的图像描述生成方法借助深度学习端到端的训练特性,通过在大规模图像句子对应数据集上进行学习,模型生成的描述句子更为新颖.现有的图像描述工作[3–10]以研究如何为图像生成英文的描述句子为主,显然此项研究不应该受限于语言,将图像描述研究扩展到母语使用人口最多的中文环境,具有更为重要的现实意义.
相比英文描述,中文词语含义更加丰富,中文句子结构也更为复杂,因此图像中文描述任务更具有难度;在模型构建方式上,现有的图像英文描述研究利用编码器-解码器框架[5–7]和融合注意力机制的编码器-解码器框架[8–10]来构建模型,而图像中文描述模型主要是基于编码器-解码器框架构建的.例如,2016年Li 等人[11]将文献[5]中的模型在中文的环境下重新训练,实现了首个图像中文描述模型CS-NIC;2019年张凯等人[12]通过利用机器翻译构建伪语料库,从而将常规编码器-解码器框架在中文的环境下重新训练.通过实验发现,虽然现有的图像中文描述模型可以对图像进行描述,但是描述句子的质量仍有待提升.通过对现有的图像中文描述研究进行分析,本文认为目前图像中文描述句子质量不高的原因可以归结为:1)现有研究利用编码器-解码器框架来构建模型,该框架仅在解码器的仅接收一次图像特征,由于解码器的“遗忘”特性,导致模型生成的描述句子整体质量不高;2)中文词语的含义较为丰富,现有研究在解码视觉特征时,并未考虑视觉特征中的误差因素;3)现有方法的优化目标主要是基于输入视觉特征和已经生成的词语,使预测的下一个词语是正确词语的概率最大化,这在一定程度上忽略了最终生成句子整体语义与图像内容的关联度.
针对上述问题,2016年Xu 等人[8]在编码器-解码器框架中引入注意力机制,使单词与图像视觉特征之间进行对齐,提升了模型对视觉特征的鉴别能力.注意力机制与人眼视觉特性相似,其原理是使模型在生成文字序列时,自主决定图像特征的权值,从而实现模型动态地关注图像中重要的区域.此外,也有研究利用从图像中提取多标签信息对模型生成的描述句子质量进行改善.例如,2019年蓝玮毓等人[13]利用概率编码的图像多标签重排模型生成的描述句子候选集,提升了模型生成的描述句子与图像内容的关联度.因此为提升中文描述句子质量,本文在现有研究的基础上提出融合双注意力与多标签的图像中文描述方法.本文方法通过融合图像多标签文本信息,增强解码器与图像内容的关联度;通过利用注意力机制,使模型能更好地利用视觉特征.通过实验对比分析,本文模型生成的图像描述句子更符合图像的内容,对图像的背景等细节信息也能够进行描述.
1 相关工作
现有的图像描述生成方法可分为3个类别.
1)基于模板的图像描述生成方法.该类方法先利用计算机视觉技术识别出图像中视觉语义信息,然后填充到模板句子中.该类研究的代表性工作为Fang 等人[3]利用卷积神经网络(Convolutional Neural Network,CNN)[14,15]预测出一系列词语,再利用最大熵语言模型生成描述句子.该类方法往往能生成语法正确的描述句子,但是由于模板句子的数量有限,导致描述句子的多样性受限.
2)基于检索的图像描述生成方法.该类方法将相似图像描述句子作为输入图像的描述句子.该类研究的代表性工作为Ordonez 等人[4]从Flickr 网站收集大量图片,通过使用数据清洗技术使最终检索库中的每幅图像均对应一个描述句子,然后寻找与测试图像最相似图像,将该图像的描述句子作为测试图像的描述句子.该类方法往往能生成语义正确的描述句子,但是严重依赖于检索算法与数据集质量,当数据集中缺少与目标图像相似的图像,将导致匹配失败.
3)基于翻译的图像描述生成方法.该类方法受机器翻译的启发,将图像看作待翻译数据,描述句子视为翻译结果,利用编码器-解码器框架将图像内容进行翻译.该类研究的代表性工作为Vinyals 等人[5]利用CNN作为编码器,将图像编码为特定长度的语义向量,然后利用长短时记忆网络(Long Short Term Memory Neural Network,LSTM)[16]作为解码器,对语义向量进行解码,模型使用最大似然概率函数进行训练.汤鹏杰等人[7]在编码器-解码器框架中融合场景信息,使模型的性能得到提升.该类方法生成的描述句子要更为新颖,成为目前构建图像描述模型的主流方法.
Xu 等人[8]将注意力机制引入到图像描述研究中,先利用CNN 提取图像的卷积层特征,在生成每一个单词时,根据解码器LSTM的隐藏状态计算出各个特征区域对应的权重,通过权重乘上对应区域的特征对图像特征重新加权,然后由解码器对加权后的特征进行解码.该类方法通过使模型动态关注图像中的重要区域,提升模型的性能,吸引了众多研究者关注.随后,越来越多的研究者进一步地提出不同的注意力机制,比如全局-局部注意力机制[9]、自适应注意力机制[10]等.
仅有少数的工作研究了面向非英语语种的图像描述.李锡荣等人[11]借助人工翻译、机器翻译得到首个中文的数据集Flickr8k-cn,并对文献[5]中的模型重新训练,得到首个图像中文描述模型.张凯等人[12]通过利用机器翻译构建伪语料库,从而完成了端到端的中文描述生成.蓝玮毓等人[13]提出利用概率向量编码的图像标签信息,重排生成的图像描述文本集,提升了模型生成的描述句子与图像内容的关联度.这些工作都是利用编码器-解码器框架构建模型,解码器仅接收一次视觉特征,而且在解码过程中对视觉特征的利用方式简单,虽然注意力机制可以根据解码器的隐藏状态增强视觉特征的利用方式,但是融合注意力机制的编码器-解码器框架仅在图像英文描述生成中被证实是可行的,由于中文与英文之间的差异,注意力机制能否应用到图像中文描述研究中仍有待验证;此外,现有利用图像多标签改善描述句子质量的研究是使用概率向量编码的图像多标签进行的,且并没有利用图像多标签信息生成新的描述句子,对于一幅图像,其中的对象、场景、行为等信息往往是确定的,如何使用非概率编码的多标签文本辅助模型生成更高质量的描述句子仍需要实验进行验证;最后,本文根据图像中包含的目标类型和数量,对模型的描述能力进行分析.
2 融合双注意力与多标签的图像中文描述生成模型
1)优化目标
图像多标签不仅能反映图像内容,而且能作为描述句子中的词语,可为模型生成更高质量的中文描述文本提供帮助.因此对于输入图像Ii,令中文词表为D,本文为该图像预测一个中文标签集合{Li},标签Li与D中的单词对应.即本文利用Li辅助模型生成更高质量的中文描述句子S.模型的训练目标为式(1)所示:

其中,θ是模型需要学习的参数;N是训练集图像的数量;i是指数据集中第i幅图像,M是指第i幅图像对应的描述句子S的长度,S={s1,s2,…,sn}.因为CNN 提取的视觉特征相比图像Ii本身,能更好地反映其高层语义,因此令V(Ii)=Ii,V(Ii)表示图像对应的视觉特征,W(Ii)=Li,W(Ii)表示图像对应的多标签文本信息.利用链式求导法则,式(1)可转化式(2):

本文利用图像语义编码网络和双注意力解码网络对式(2)进行求解.图像语义编码网络用于提取视觉特征V(Ii)和多标签文本W(Ii);双注意力解码网络根据图像多标签文本W(Ii),更好地对视觉特征V(Ii)进行解码,从而生成更高质量的描述句子S.融合双注意力与多标签的图像中文描述生成模型框架如图1所示.
2)图像语义编码网络
如图1所示,图像语义编码网络由两部分组成,分别是视觉特征编码网络和多标签文本生成网络.对于输入图像Ii,视觉特征编码网络输出该图像的视觉特征V(Ii),多标签文本生成网络输出多标签文本W(Ii).为防止模型在训练阶段的损失相互干扰,图像多标签文本预测网络与图像视觉特征编码网络分离开进行训练.接下来本文分别介绍这两个子网络.

图1 模型框架图
① 视觉特征提取网络
本文以ResNet101 作为视觉特征提取网络.ResNet-101是ResNet[14]衍生出的一种网络,通过在大规模图像分类数据集ImageNet[15]上进行训练,ResNet101 在目标识别、目标检测等领域仍能有效刻画图像视觉信息.对于输入图像Ii,将其缩放到256×256个像素,利用视觉特征提取网络输出其视觉特征V(Ii).
② 多标签文本生成网络
本文微调AlexNet[15]网络结构,将微调后的网络作为本文的多标签文本生成网络.AlexNet是深度学习的一个代表性网络,不仅在图像分类等任务上表现优异,而且比ResNet 等网络的计算量少.但是AlexNet 网络本身并不适用于多标签分类,因此本文将AlexNet网络输出层的神经元结点的数量修改为中文词表D的长度,并将最后一层的激活函数改为适合多分类的Sigmoid 函数.训练过程中以BCEloss[17]作为模型的损失函数,其数学表达式如式(3)所示:

其中,N是图像数量,m是标签数量,其中O∈{0,1}n*o,表示样本的真实标签,T∈Rn*o,是模型对不同标签的预测概率输出.多标签文本生成网络的训练过程如图2所示.

图2 多标签文本生成网络训练过程
对图像描述数据集进行预处理,得到图像多标签数据集,将微调后的AlexNet 网络在图像多标签数据集上进行训练,将训练后模型的参数迁移到本文的多标签文本生成网络中.对于输入图像Ii,将其缩放到256×256个像素后,再利用多标签文本生成网络输出概率编码的图像多标签,最后通过设置阈值输出图像对应的多标签文本W(Ii).
由图1可知,一幅图像Ii,模型提取其视觉特征V(Ii)和多标签文本W(Ii)后,将其输入到双注意力的解码网络中,由双注意力解码网络对视觉特征进行解码生成描述词语.
3)双注意力解码网络
由于中文词语的含义较为丰富,因此合理地利用视觉特征对于图像描述生成尤为重要.本文模型在解码器中引入注意力机制,使解码器可以根据LSTM内部的隐藏状态ht,加权出与当前输出词语关联度高的视觉特征,进而对加权后的视觉特征进行解码生成描述词语.本文的双注意力解码网络工作流程解码流程如图3所示.

图3 双注意力的解码网络工作流程
双注意力解码网络首先利用视觉特征V(Ii)和解码器上一次输出词语更新LSTM内部的隐藏状态ht,LSTM内部更新公式如式(4)所示:

其中,Ew是词嵌入矩阵,Wt–1是LSTM的上一次的输出词语,ht–1是LSTM 上一次的隐藏状态,xt是LSTM当前的输入,σ是指Sigmoid 激活函数,f、i、o分别表示LSTM内部是否忘记此前信息、是否接受新的输入以及是否输出当前信息的“闸门”,W、U和b是LSTM结构中需要训练的模型参数,⊙表示对应向量与闸门取值的乘积,ct是LSTM 当前的记忆单元状态,ht是LSTM 当前的隐藏状态.
由图3可知,在LSTM内部的隐藏状态ht更新后,双注意力解码网络根据LSTM内部的隐藏状态ht利用通道注意力机制加权出与当前输出关联度较高的视觉特征V′(Ii).通道注意力机制从特征通道的角度分析与不同通道的视觉特征与当前输出词语的关联度,从而降低特征通道层的误差干扰,其内部的数学计算为式(5)所示:

其中,B是视觉特征的通道数,tanh和Softmax为激活函数,ba、bb、Wa、Wht、Wb是网络要学习的参数,V表示视觉特征的每一个通道平均池化后的通道特征,ht表示LSTM 在t时刻的隐藏状态,β的每个值表示每个通道特征的权重,⊙表示逐元素相乘,⊕表示逐元素相加.
如图3所示,双注意力解码网络加权出与当前输出词语关联度高的视觉特征V′(Ii)后,利用自适应注意力机制计算视觉特征V′(Ii)与当前输出词语的视觉关联度.自适应注意力机制利用视觉监督向量st对LSTM进行扩展,视觉监督向量st通过对已经生成的文本信息和当前输入的视觉特征进行建模,分析解码器输出的当前词语是否需要关注视觉特征.当模型生成非语义词语时,可以通过视觉监督向量st直接生成,而不需要再关注图像特征信息.自适应注意力解码网络内部的计算为:

其中,gt表示LSTM内部记忆单元ot中的候选状态,σ是指Sigmoid 激活函数,Ew是词嵌入矩阵,xt表示在t时刻LSTM 网络的输入单词.
最后双注意力机制解码网络将原有的上下文向量ct与视觉监督向量st进行加权生成一个新的上下文向量c′t.

其中,参数αt的取值范围为0 到1 之间.从式(7)中可以看出,当αt=1 时,新的上下文向量c′t为视觉监督向量st,此时双注意力解码网络只需利用已生成的文本信息可以预测下一个词语;反之,当αt=0 时,模型更关注视觉特征信息生成下一个单词.
为使双注意力解码网络更好地解码视觉特征,本文利用多标签文本W(Ii)初始化LSTM,增强LSTM内部的隐藏状态,初始化方式如式(8)所示:

其中,Wv,Ww是模型需要学习的参数,V(Ii)是视觉特征,W(Ii)是多标签文本.
4)中文描述生成
在MLP 层利用Softmax函数将c′t与词表D建立映射连接:

其中,yt是指在t时刻LSTM的输出,pt是MLP 对词表D中不同单词的预测概率,Softmax是激活函数,Wt是网络的学习参数.
3 实验
本节对本文方法的实验环境与具体参数设置进行介绍,并结合实验对本文模型进行分析.
1)实验环境
本文实验在深度学习服务器上运行,显卡其型号是NVIDIA 1070Ti,内存大小为8 GB.数据的预处理过程与模型的训练和测试过程均在Python3、PyTorch 0.4 上进行.
2)数据集
本文在Flickr8k-CN[11]、COCO-CN[18]两个图像中文描述数据集上进行实验.
Flickr8k-CN[11]是首个图像中文描述数据集,数据集中的图像大多来源于人类真实生活场景,且图像中的描述目标较为显著.该数据集中共有8000 张图像,
其中每幅图像对应5个描述文本,每个描述文本从不同的角度描述图像的内容,其中训练集6000 张图像,验证集1000 张图像,测试集1000 张图像.
COCO-CN[18]数据集中图像的场景更为多样化,图像中的干扰元素更多,每幅图像对应的描述文本由1个到5个不等,该数据集共有20341 张图像,其中训练集18341 张图像,验证集1000 张图像,测试集1000 张图像.数据集构成与示例如表1所示.

表1 数据集构成与示例
3)实验设置
由于中文句子缺乏自然分隔符,本文利用THULAC[19]中文分词工具对数据集中的描述句子进行分词.为避免罕见单词不利于描述文本生成,本文统计词频大于5的词语,并且增加“

表2 不同数据集合对应的词表D 大小
① 多标签文本生成网络参数设置
利用词表D对图像中文描述数据集中的出现频率大于5的名词、动词进行映射,得到图像中文多标签数据集.使用在ImageNet 数据集上预训练的AlexNet网络参数对多标签文本生成网络进行初始化.在网络的训练过程中,输入的图像分辨率设置为256×256个像素,学习率大小设置为0.001.为避免过拟合,训练过程中采用Dropout 对网络的隐藏输出采样.本文将多标签文本生成网络输出概率较大的作为该图像的多标签文本,通过在验证集上进行搜索,选取在验证集上取得最好效果为0.9.
② 融合双注意力与多标签模型的参数设置
将双注意力解码网络的LSTM的隐藏层维度设置为512,利用Adam 优化器优化模型的误差,批训练样本的大小设置为32.为了避免过拟合,采用Dropout 对网络的隐藏输出采样.在测试阶段采用了集束搜索策略,beam_size 大小为1.
③ 模型的评价指标设置
本文使用的评价指标为:BLEU[20]:机器翻译的评价指标,能够分析机器生成语句和参考语句间的N元文法准确率,根据N 元文法的选择该指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4 被广泛使用.METEOR[21]:利用单精度的加权调和平均数和单字召回率的方法改善BLEU 指标存在的问题.ROUGE[22]:通过比较召回率的相似度来度量指标.
4)实验结果与分析
① 实验1.数据集上模型效果对比
实验中选择CS-NIC[8]、软注意力机制(Soft-ATT)[11]、自适应注意力机制(Adaptive)[23]、通道注意力机制(SCA-CNN)[24]作为对比.其中CS-NIC是作为首个图像中文描述模型有重要的参考价值;软注意力机制、通道注意力机制与自适应注意力机制在图像英文描述研究中是有效的,为了验证注意力机制是否能应用于中文环境,本文将在中文的环境下对注意力模型重新训练.表3与表4是以上模型在Flickr8k-CN和COCO-CN 数据集上的表现.

表3 不同模型在Flickr8k-CN 数据集上的表现

表4 不同模型在COCO-CN 数据集上的表现
图4是对表3的可视化.从图4中可知,相比目前的主流的图像中文描述模型CS-NIC,本文的模型通过融合双注意力机制与图像多标签文本,在BLEU-1、BLEU-2、BLEU-3 上均有提升,这证明本文提出的模型是有效的.具体地本文模型相比CS-NIC 模型,在BLEU-1 上的提升10.3%,在BLEU-2 上的提升12.1%,在BLEU-3 上的提升17.8%;此外,将注意力机制在中文的环境下重新训练后,相比CS-NIC 模型来说在不同的评价指标上,也均有一定的提升,这说明注意力机制可以应用到中文环境;另外,相比自适应注意力机制和通道注意力机制,本文模型在BLEU 评价指标上也有提升,这一点在表3和表4中均有所体现,这说明通过利用多标签文本初始化双注意力解码网络,可以生成更高质量的图像描述句子.
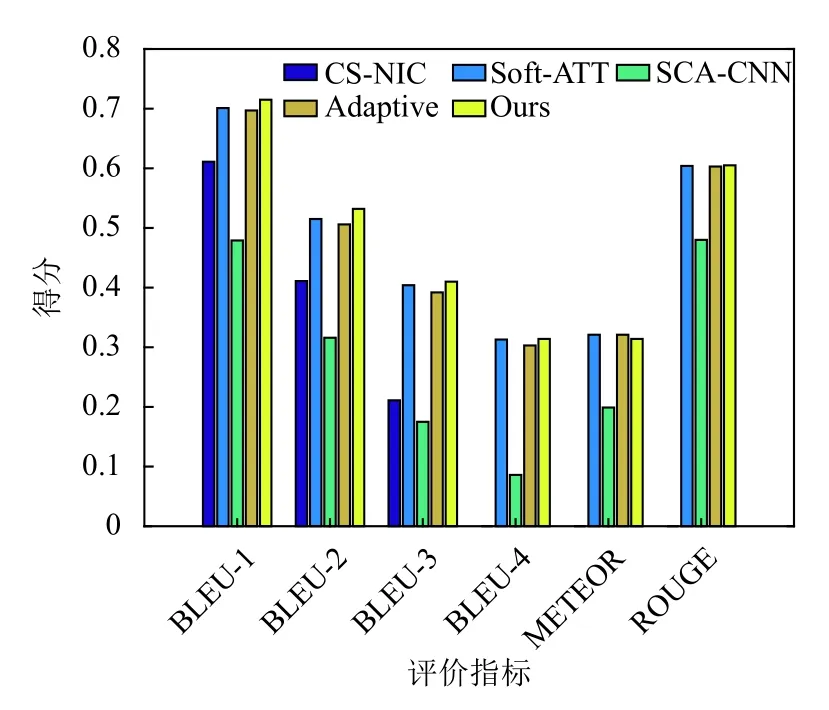
图4 Flickr8k-CN 数据集上不同模型在评价指标上的得分
② 实验2.Flickr8k-CN 数据集上消融实验
表5给出了本文模型不同组成部分对模型提升贡献度.通过表5可知,相比自适应注意力机制,本文通过融合通道注意力机制,在BLEU-1 上提升0.1%,在BLEU-2 上提升0.9%,在BLEU-3 上提升0.7%,BLEU-4上提升0.9%,这说明降低在视觉通道特征中误差因素的干扰,模型可以生成更高质量的描述句子;本文模型利用多标签文本初始化LSTM内部的隐藏状态,在BLEU-1 上提升0.4%,在BLEU-2 上提升0.4%,在BLEU上提升0.3%,在BLEU-4 上提升0.9%,这验证了通过利用多标签文本初始化LSTM内部的隐藏状态,可以提升图像中文描述模型的效果.

表5 不同模型在Flickr8k-CN 数据集上的消融实验
5)可视化实例分析
根据图像中描述对象的类型和数量进行分类,本文将数据集中的描述场景分为3 种类型,即单类单目标场景、单类多目标场景和多类多目标场景.表6是软注意力机制(Soft-ATT)、自适应注意力机制(Adaptive)、通道注意力机制(SCA-CNN)以及本文模型对不同场景的图像的描述效果.从表6可看出,本文提出的模型对图像中物体的识别和语义的理解还是比较准确的.

表6 不同场景下对比模型生成的图像中文描述文本
4 总结与展望
为提升图像中文描述句子质量,本文在验证注意力机制可用于图像中文描述生成的基础上,提出融合双注意力与图像多标签的图像中文描述生成方法.通过在图像中文描述数据集上进行评测,在多个图像描述评价指标上优于目前主流的图像中文描述生成模型.然而本文模型所使用的注意力机制是英文环境下的注意力机制迁移而来的,由于中文与英文语法的差异,因此结合中文语法规则设计出符合中文环境的注意力机制是该领域的目标.此外,在对不同场景的图像分析过程中,本文模型在单类单目标场景和多类多目标场景下,生成的描述句子更符合图像本身的内容,语义也更为饱满,但是对于多类单目标的场景,本文模型生成的图像中文描述句子容易只描述出图像中的部分区域,因此在未来的工作中会专注于提升模型对图像全局语义的理解能力.
