基于差分修正的SGDM算法①
2021-08-02袁炜,胡飞
袁 炜,胡 飞
(天津大学 数学学院,天津 300350)
当前,深度神经网络模型在视觉[1]、文本[2]和语音[3]等任务上都有着非常好的表现.但是随着神经网络层数的加深,模型的训练变得越来越困难.因此,研究人员开始关注优化方法.随机梯度下降法(SGD)是求解优化问题的一种简单有效的方法,SGD 被广泛应用于实际问题[4].该方法根据小批量(mini-batch)样本的可微损失函数的负梯度方向对模型参数进行更新,SGD具有训练速度快、精度高的优点.但由于其参数是每次按照一个小批量样本更新的,因此如果每个小批量样本的特性差异较大,更新方向可能会发生较大的变化,这导致了它不能快速收敛到最优解的问题.因此,SGD有很多变种,一般可以分为两类.第一类是学习率非自适应性方法,使用梯度的一阶矩估计——SGDM[5],结合每个小批量样本的梯度求滑动平均值来更新参数,极大地解决了SGD 算法收敛速度慢的问题,这个方法目前应用非常广泛,本文就针对这个方法进行改进.第二类是学习率自适应性方法,利用梯度的二阶矩估计实现学习率的自适应调整,包括AdaGrad[6],RMSProp[7],AdaDelta[8],Adam[9].其中Adam是深度学习中最常见的优化算法,虽然Adam 在训练集上的收敛速度相对较快,但在训练集上的收敛精度往往不如非自适应性优化方法SGDM,且泛化能力不如SGDM.AmsGrad[10]是对Adam的一个重要改进,但是最近的研究表明,它并没有改变自适应优化方法的缺点,实际效果也没有太大改善.RAdam[11]是Adam的一个新变体,可以自适应的纠正自适应学习率的变化.
目前很多研究都集中在第二类学习率自适应性方法上,却忽略了最基本的问题.无论自适应还是非自适应方法都用了指数滑动平均法,这些方法都试图用指数滑动平均得到近似样本总体的梯度,然而这种方法是有偏且具有滞后性的.针对这一问题我们提出了RSGDM算法,我们的方法计算梯度的差分,即计算当前迭代梯度与上一次迭代梯度的差,相当于梯度的变化量,我们在每次迭代时使用指数滑动平均估计当前梯度的变化量,然后用这一项与当前梯度的估计值进行加权求和,这样的做法可以降低偏差且缓解滞后性.
1 RSGDM 算法

算法1.RSGDM 算法:所有向量计算都是对应元素计算输入:学习率,指数衰减率,随机目标函数α β f(θ)随机初始化参数向量,初始化参数向量,初始化时间步长θt θ0m0=0,z0=0,∆g1=0 t=0 While 不收敛 do t←t+1计算t 时间步长上随机目标函数的梯度:gt←∇θ ft(θt−1)计算差分:∆gt=gt−gt−1更新梯度和差分的一阶矩估计:mt←β∗mt−1+(1−β)∗gt zt←β∗zt−1+(1−β)∗∆gt用差分的一阶矩估计修正对梯度的估计:nt←mt+β∗zt更新参数:θt←θt−1−α∗nt end Wimages/BZ_225_290_2831_291_2833.pnghile θt输出:结果参数
算法1 展示了RSGDM 算法的整体流程.设f(θ)为关于θ 可微的目标函数,我们希望最小化这个目标函数关于参数 θ的期望值,即最小化E[f(θ)].我们使用f1(θ),f2(θ),···,fT(θ)来表示时间步长1,2,···,T对应的随机目标函数.这个随机性来自于每个小批量的随机采样(minibatch)或者函数固有的噪声.梯度为gt=∇θft(θ),即在时间步长t时,目标函数ft关于参数θ的偏导向量.使用∆gt=gt−gt−1表示时间步长t和时间步长t−1对应的梯度差,即本文提到的差分.不同于SGDM 算法只对gt做指数滑动平均,RSGDM 算法对gt和∆gt都做指数滑动平均,并用后者的滑动平均值修正前者,下面列出SGDM算法和RSGDM 算法的更新公式.
1)SGDM 算法:

2)RSGDM 算法:
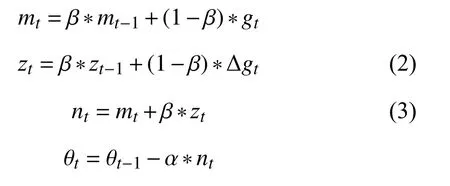
可以看出,RSGDM 算法比SGDM 算法多出式(2)和式(3),本文第2 节将证明SGDM中的式(1)mt对总体gt的估计是有偏的,我们就是使用式(2)和式(3)来进行偏差修正的.RSGDM 算法相比于SGDM 算法没有增加多余的超参,不会增加我们训练模型调参的负担.
2 偏差及滞后性分析
首先我们分析用指数滑动平均估计总体梯度的偏差,首先由SGDM 算法中的式(1)可以得到:

对式(4)两边取期望可得:

可以发现E(mt)≠E(gt),其中:

当迭代次数较多时,1 −βt可以忽略不计,最大的偏差就来自于式(6).如果gt是一个平稳序列,即E(gt)=C(C是常数)时,有ξ=0,此时mt是gt的一个无偏估计.但实际情况下,显然这是不可能的,所以mt是gt的有偏估计,且偏差主要来自于ξ.并且这个偏差会导致滞后性,比如梯度如果一直处在增大的状态,由于前面历史时刻梯度值较小也会导致估计值mt偏小一些,或者梯度如果一直增大,但从某个时刻开始减小,由于历史梯度的影响梯度的估计值mt可能还没有反应过来,这就是本文所说的滞后性带来的影响.针对这种情况我们提出了RSGDM 算法,使用梯度的差分(变化量)估计来修正梯度的估计值mt.直观上可以这样理解,如果梯度越来越大且差分的估计也是大于0的,那么这个修正项起到加速收敛的作用,如果梯度越来越大,在某一时刻要开始减小,那这个修正项就会起到修正梯度下降方向的作用.下面我们从公式上解释RSGDM 算法的优势:
首先由式(2),我们可以得到:

对RSGDM 算法中的式(3)两边取期望,我们可以得到:

nt是修正后的对gt的估计,我们可以对比式(5)和式(8),我们设不难发现 ς是RSGDM 算法的主要偏差来源,我们展开 ς,得到:

我们对比式(6)SGDM 算法的偏差项 ξ和式(9)RSGDM 算法的偏差项 ς,可以看出ξ受历史梯度g1,g2,···,gt−1影响,而ς受历史梯度g2,g3,···,gt−1影响.由于t很大且 β 小于0,βt−1∗[g1−E(gt)] 接近于0 可以忽略,那么可以得到ς=β∗ξ.可以看出RSGDM 算法偏差项ς少了历史梯度g1的影响,且由于 β 小于0,所以| ς|≤|ξ|.综上,我们可以得出RSGDM 算法对比SGDM 算法有更小的偏差,且受历史梯度影响要小(缓解了滞后性).
3 实验
本节我们通过实验证明我们的RSGDM 算法比SGDM 算法更有优势.我们选择图像分类任务来验证算法的优越性,实验使用了CIFAR-10和CIFAR-100数据集[12].CIFAR-10 数据集和CIFAR-100 数据集均由32×32 分辨率的RGB 图像组成,其中训练集均是50000 张图片,测试集10000 张图片.我们在CIFAR-10 数据集上进行10 种类别的分类,在CIFAR-100 数据集上进行100 种类别的分类.我们分别使用ResNet18模型和ResNet50[13]模型在CIFAR-10和CIFAR-100数据集上进行图像分类任务,每个任务使用SGDM 算法和我们的RSGDM 算法进行比较,评价的指标为分类的准确率.我们使用的深度学习框架是PyTorch,训练的硬件环境为单卡NVIDIA RTX 2080Ti GPU.实验中的批量大小(batch-size)设置为128,SGDM 算法和RSGDM 算法的两个超参数设置一样,其中动量 β=0.9,初始学习率 α=0.01,训练时我们使用了权重衰减的方法来防止过拟合,衰减参数设置为5e–4,学习率每50轮(epoch)减少一半.
表1和表2分别给出了ResNet18和ResNet50 使用不同的优化器在CIFAR-10和CIFAR-100 数据集上图像分类的准确率.我们可以看到在CIFAR-10 数据集上,SGDM和RSGDM 训练精度都达到了100%,测试精度我们的RSGDM 比SGDM 高了0.14%.在CIFAR-100 数据集上,SGDM和RSGDM 训练精度都是99.98%,在测试精度上RSGDM 比SGDM 高了0.57%.

表1 ResNet18 在CIFAR-10 上分类准确率(%)

表2 ResNet50 在CIFAR-100 上分类准确率(%)
图1–图4给出了ResNet18 在CIFAR-10 上使用SGDM 算法和RSGDM 算法的实验结果,包括训练准确率、训练损失、测试准确率、测试损失.由于我们实验设置每50个epoch 学习率减半,很明显可以看出4 张图在epoch50、100、150 均有一些波动.总体上看在训练准确率和训练损失上,两种方法无论收敛速度和收敛精度都大体相同,在收敛精度上训练后期我们的RSGDM 算法更具优势.

图1 ResNet18 在CIFAR-10 上的训练准确率

图2 ResNet18 在CIFAR-10 上的训练损失

图3 ResNet18 在CIFAR-10 上的测试准确率

图4 ResNet18 在CIFAR-10 上的测试损失
图5–图8给出了ResNet50 在CIFAR-100 上使用RSGDM 算法和SGDM 算法的实验结果.可以得出与CIFAR-10 类似的结果,在训练准确率和训练损失上二者的几乎相同,但是在收敛精度上,RSGDM 算法的表现在这个数据集上要领先SGDM 算法很多,可以看测试准确率那张图,从100个epoch 之后,我们的RSGDM 方法始终准确率高于SGDM,并且最终准确率比SGDM 高了0.57%.这进一步说明我们的方法是有效的.

图5 ResNet50 在CIFAR-100 上的训练准确率

图6 ResNet50 在CIFAR-100 上的训练损失

图7 ResNet50 在CIFAR-100 上的测试准确率

图8 ResNet50 在CIFAR-100 上的测试损失
4 结论
随着深度学习模型的不断复杂化,训练一个精度高的模型越来越不容易,一个好的优化器具有非常重要的作用.本文分析了传统方法SGDM 算法使用指数滑动平均估计总体梯度带来的偏差与滞后性,并理论上证明了这个偏差与滞后性存在.我们提出了基于差分修正的RSGDM 算法,该算法对梯度的差分进行估计并使用这个估计项修正指数滑动平均对梯度的估计,我们从理论上说明了算法的可行性,并且在CIFAR-10和CIFAR-100 两个数据集上进行图像分类任务的实验,实验结果也进一步说明了我们的RSGDM 算法的优势.值得一提的是,我们的RSGDM 算法没有引入更多的需要调试的参数,在不加重深度学习研究员调试超参负担的情况下,提升了收敛精度.本文开头介绍了当前这个领域的其他方法,包括现在最常用的学习率自适应性算法Adam 等,未来我们会使用现在的改进思路去提出新的学习率自适应性算法,提出更加准确高效的算法.
