一种适用于农村电影放映的订购推荐算法研究
2021-08-01王晓西
王晓西
(中央宣传部电影数字节目管理中心,北京 100866)
1 引言
农村电影放映服务是我国公共文化体系建设的重要组成部分,让更多农民群众能看到高质量、高水平的数字电影一直是公益电影工作者的追求。当前,农村电影市场年均供应影片超4000部、年均供应新片超600部。与其它电子商务系统类似,农村院线进行影片订购时面临着选片基数大的问题。因此,向各农村院线提供个性化影片订购推荐服务是非常有必要的。
研究者们在推荐算法的精准性、实时性方面进行了大量的努力,但推荐算法的实际运用还需要结合目标系统的运营特点进行针对性优化。农村电影放映有其独有特点,主要体现在几个方面:一是区域性,农村电影放映主要面向广大农村地区,不同地域的人民群众受环境、语言、民族、文化等影响对电影的喜好不尽相同;二是引导性,院线在订购影片过程中会受到包括“主题影片推荐活动”在内的影片订购指导,“好片”“热片”会出现扎堆订购的情况;三是计划性,院线订购放映除受到政策、季节、气候因素影响外,也受服务群体的影响,如给学校、景区等地放映的院线订购影片相对集中。正是由于农村电影放映工作的独特性,给各院线提供订购推荐服务需要结合这些特点开展。
2 传统基于用户的协同过滤推荐算法
2.1 推荐算法的选择
目前应用相对广泛的推荐技术包括基于内容过滤的推荐技术、基于协同过滤的推荐技术、基于深度学习的推荐技术等。基于用户的协同过滤推荐是基于协同过滤的推荐技术中的一种,其算法思想是通过发现近邻用户来完成推荐,比较适合于用户数量不多、历史行为丰富的使用场景。推荐算法都存在自身优缺点,在不同使用场景、不同数据源情况下推荐效果也存在差异,要结合在用系统的特点选择合适的推荐算法。
根据“电影数字节目交易平台”数据,2017年至2019年,全国农村院线年订购影片场次均超过千万场,年活跃订购院线稳定在270余条,年可订购影片均超过4000部,实际订购影片超过90%。2018年至2019年,两年合计在档影片5110部,两年都在档影片3667部,年均新签约影片超过600部,影片片种包括故事片、科教片、戏曲片、纪录片及美术片。通过以上数据并结合上节内容可以看出:
(1)农村院线数量相对较少且固定;
(2)每年可订购影片数量相对较多,影片有过档下线及新片上映等情况;
(3)院线年订购影片覆盖面较广,订购场次基数较大且区分度较高。
综上,在院线用户数量固定、有丰富的历史订购行为数据、整体数据规模稳定等特征的农村电影放映场景下,适宜采用基于用户的协同过滤推荐算法。
2.2 基于用户的协同过滤推荐算法
传统基于用户的协同过滤推荐算法的应用思路是先计算查找与各院线有相似订购偏好的近邻院线,再从这些近邻院线的历史订购影片中找到目标院线最可能会订购的影片集合,最后按照对影片预测评分高低形成目标院线的影片推荐列表。在传统算法应用过程中影响最终推荐质量的环节包括近邻用户的计算查找和推荐列表的形成。
2.2.1 近邻用户的计算查找
有高相似性偏好的两个用户称为近邻用户,用户之间的相似性可以通过他们对相同物品 (影片)的评分(订购场次)来计算得到。在推荐算法中,用户对物品的评分可以用向量来表示,向量间的距离越近相似性越高。
度量用户间相似性方法有多种,比较常见的有:欧式相似性、余弦相似性及皮尔森相似性。其中,欧式相似性是通过多维向量空间中点间的绝对距离表示,余弦相似性是通过计算多维向量空间中用户间向量夹角的余弦值来体现,皮尔森相似性是在用户有共同评分的物品集 (订购相同影片集)的基础上衡量用户间相关程度,其值介于-1 与1之间。相似性度量是算法的核心,直接影响近邻用户计算查找的准确性。
2.2.2 推荐列表的形成
得到用户的近邻用户后,根据近邻用户对物品的实际评分预测用户对该物品的评分。参考一定数量的近邻用户,综合物品预测评分的高低产生推荐列表。假定N (u)为用户u的参考近邻用户集合,那么用户u对物品i的预测评分P计算公式如下:
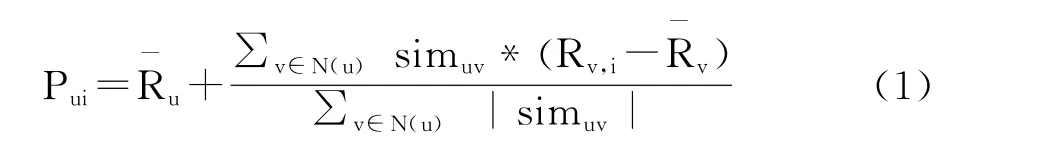
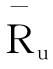
参考近邻用户越多,计算复杂度越高。通常做法是在整个用户集中,选择与用户相似性最高的前k个用户作为近邻集合,再根据公式 (1)计算预测评分,将分值较高的前N 个物品形成推荐列表推荐给用户。
3 算法改进
本文在传统基于用户的协同过滤推荐算法基础上,针对农村电影放映工作特点,提出了一种改进的协同过滤推荐算法。
3.1 评分预测模型修正
传统协同过滤算法中评分预测计算公式如式(1)所示,可以简化为:

公式中∑相似度*评分值给出了所有加权评分的总和,同时为了修正一个受到更多用户评分的物品对结果产生更大的影响,将评分总和除以所有对这个物品有评分的用户的相似度之和,进而得到最终针对某个物品的预测评分。
对于农村电影放映来说,由于存在院线订片引导性问题,各类推荐影片会被院线广泛订购,拥有较大评分基础。这些影片在做评分预测时不应该被削弱影响,而应拥有更多的贡献权重。为解决这一问题,本文提出基于农村电影放映场景下的影片评分预测模型为:
影片预测评分=∑(院线相似度*院线评分值)
3.2 近邻计算加权干预
协同过滤算法中近似邻居的查找是通过计算用户间相似性得到,不去考虑用户对物品的评分行为。在农村电影放映工作中院线计划性不同其订购需求也是不同的,有些院线订购影片相对集中、订购场次相对均衡,也有院线订购影片基数较大,订购较为分散。如图1,2018年至2019年间,在所示订购影片部数区间里的院线数量整体呈正态分布趋势,其中有超过50条院线订购影片超过500部,也有超过70条院线订购影片不足100部。

图1 院线订购影片部数分布
针对上述实际情况,本文引入加权参数lon表示两条院线之间最小共同订购影片的部数,院线相似性计算公式定义如下:

引入参数lon后,在计算院线相似性时将综合院线订购影片场次和院线订购影片部数两方面因素,可以减少订购影片部数少的院线对订购影片部数多的院线的干扰,提高近邻院线的判定标准。参数lon取值与院线订购影片部数len相关,lon计算公式定义如下:

式中,A,B表示院线订购影片部数区间,C 为常数,α为加权因子。
3.3 优化推荐影片排序
传统协同过滤推荐列表是根据对物品的预测评分高低排序形成,但在农村电影放映工作中需要考虑地域性观影习惯的问题。如A 省观众喜爱观看戏曲片,而B地院线几乎不会订购戏曲片,当A 省院线与B地院线经计算有较强相似性时,就可能会给B地院线推荐戏曲片,但显然这不是一个高质量的推荐。为此,本文提出在形成推荐影片清单后,引入影片片种加权参数t,重新对推荐清单计算排序,形成最终推荐列表。加权系数t计算公式定义如下:

式中,R表示院线订购影片片种场次比例,β为加权因子。
改进后推荐算法流程如图2示。
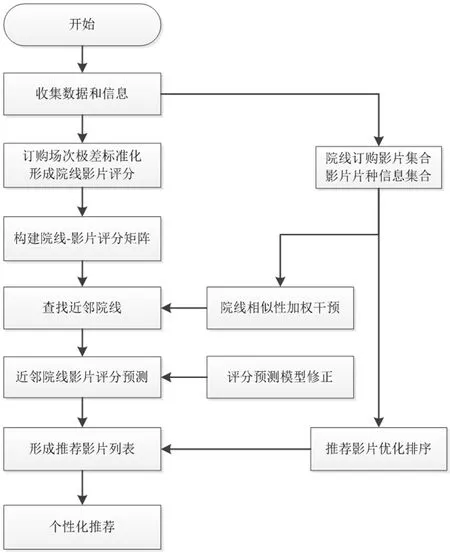
图2 改进算法流程图
4 实验设计与结果分析
4.1 实验数据集
本文采用“电影数字节目交易平台”2018 至2019两年真实交易订购数据集进行实验,此数据集包括272条院线、4650部电影、90526条交易记录。数据集统计信息如表1示,在设计算法时将数据集按80%:20%的比例划分训练集和测试集,训练集用来构造测试模型,测试集用来评价算法质量。在实现算法时将级差标准化后的订购场次值按0.1为刻度线性转化为电影评分,评分范围为1~10。本文所用数据集稀疏度为92.84%,属于高稀疏度矩阵。
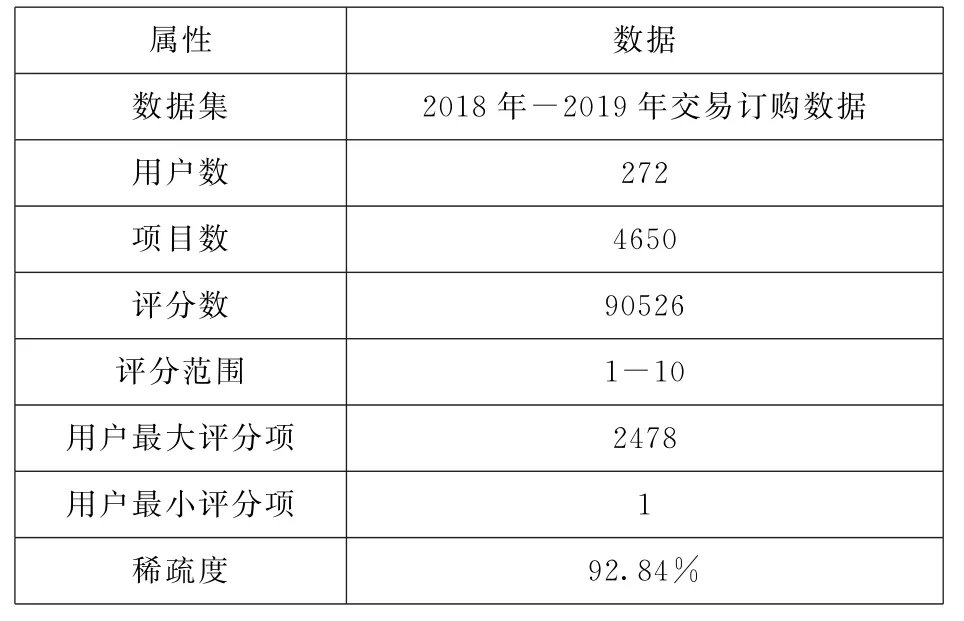
表1 实验数据集分析
4.2 算法评价指标
本实验中采用MAE (平均绝对误差)、准确率和召回率对算法质量进行评估。在农村电影放映工作场景下,更加注重预测准确率和召回率指标。
算法评价指标中,MAE 用于度量推荐算法的预测评分与真实值之间的差异,MAE 值越小,预测准确性越高,推荐质量越高;准确率用于度量推荐列表中是否都是用户喜欢的物品,即算法推荐成功的比率;召回率用于度量推荐列表中是否包含了用户喜欢的全部物品,召回率反映了待推荐物品被推荐的比率。
4.3 实验方案及结果分析
为验证本文所提改进算法的推荐效果,设计了两组实验,首先是对不同相似性度量方法进行实验,确定最佳的院线相似性度量方法;再在最佳的院线相似性度量方法基础上按本文第3节提出的各项加权参数调优对比,以期得出在农村电影放映场景应用下,本文提出的各项优化方案确有实效且改进后的协同过滤算法在推荐效果上能明显优于传统推荐算法。
4.3.1 实验一:确定最佳相似性度量方法
以皮尔森相似性、余弦相似性和欧式相似性三种相似性度量方法分别对数据集进行实验,计算其MAE及准确率、召回率。协同过滤算法中近邻数量k的值会影响算法性能,k 值取得过小参考项目不完整,影响推荐效果,k 值取得过大会增加系统计算复杂度,无关项目增多也会影响推荐结果。本文设定在推荐影片数量N=10的条件下,k的值从5增加到100,间隔增加为5,以此确定哪种相似性度量方法最优。实验结果如图3示。
从图3结果能看出,皮尔森相似性相对于余弦相似及欧式相似性在MAE、推荐准确率及召回率方面有最优表现,且当近邻院线数量k=5时,推荐效果最佳,准确率=12.3%,召回率=2.3%。如此,后续实验将在皮尔森相似性度量方法基础上进行。
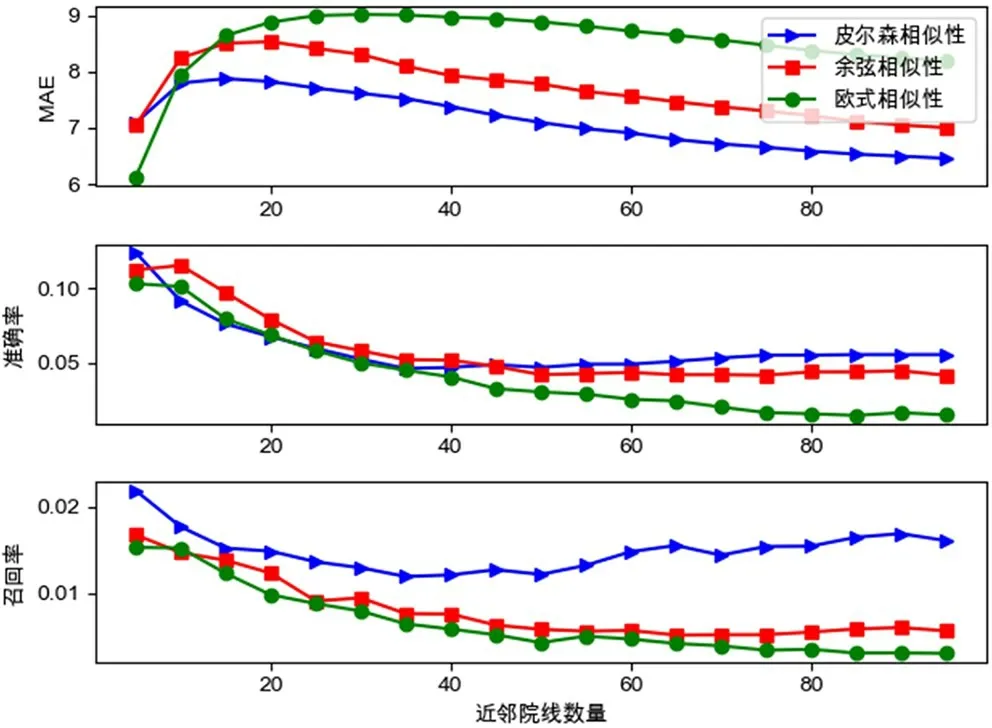
图3 不同相似性度量方法推荐效果对比
4.3.2 实验二:算法改进和参数调优
(1)评分预测模型修正
按3.1节描述,将传统协同过滤推荐中评分预测模型进行修正,放大热门影片的预测评分贡献。设定推荐影片数量N=10的条件下,k的值从5增加到50,间隔增加为5,对比评分预测模型修正前后的推荐效果,实验结果如图4示。

图4 评分预测模型修正前后推荐效果对比
实验结果表明,修正评分预测模型后推荐算法性能明显优于传统推荐算法。随着近邻院线数量k的增加,修正后推荐算法的推荐准确率和召回率整体呈现逐渐增高的趋势,并在k>35时,增加趋势变缓。如此,本文将近邻院线数量k设定为35,后面的所有实验都将在k=35的条件下进行。
(2)近邻计算加权干预
按3.2节描述,引入参数lon对近邻院线计算加权干预,减少订购集中的院线对订购广泛的院线的干扰。公式(3)A、B的值与院线订购影片部数分布相关,如图1示,订购影片部数 [0,120]区间内的院线有89条,订购影片部数[120,350]区间内的院线有102条,订购影片部数[350+]区间内的院线有81条,三个区间院线数量大体相同,设定区间A、B的值分别为120、350。常数C 为订购影片超过350部的院线间相同订购阈值,设定最小可参考相似性邻居数量不低于80%,通过计算得到C值约为80。设定推荐影片数量N=10、近邻院线数量k=35的条件下,加权因子α的值从0.5增加到0.95,间隔增加为0.05,对比近邻计算加权前后的推荐效果,实验结果如图5示。

图5 近邻计算加权干预前后推荐效果对比
实验结果表明,随着近邻计算加权因子的变化,加权后算法的推荐准确率和召回率整体呈现先增再减的趋势,在加权因子α=0.75时效果最好,准确率达到36.5%,比未加权提高4.8%;召回率达到8.3%,比未加权提高4.7%。此时在区间 [120,350]内的院线采用其订购影片部数的25%作为相同订购阈值计算近邻院线。后续实验将在α=0.75的条件下进行。
(3)推荐列表优化排序
按3.3节描述,引入影片片种加权参数t平衡各地区群众观影习惯,优化推荐影片排序。设定推荐影片数量N=10、近邻院线数量k=35、加权因子α=0.75的条件下,加权因子β的值从0增加到0.4,间隔增加为0.05,对比参数t引入前后的推荐效果,实验结果如图6示。
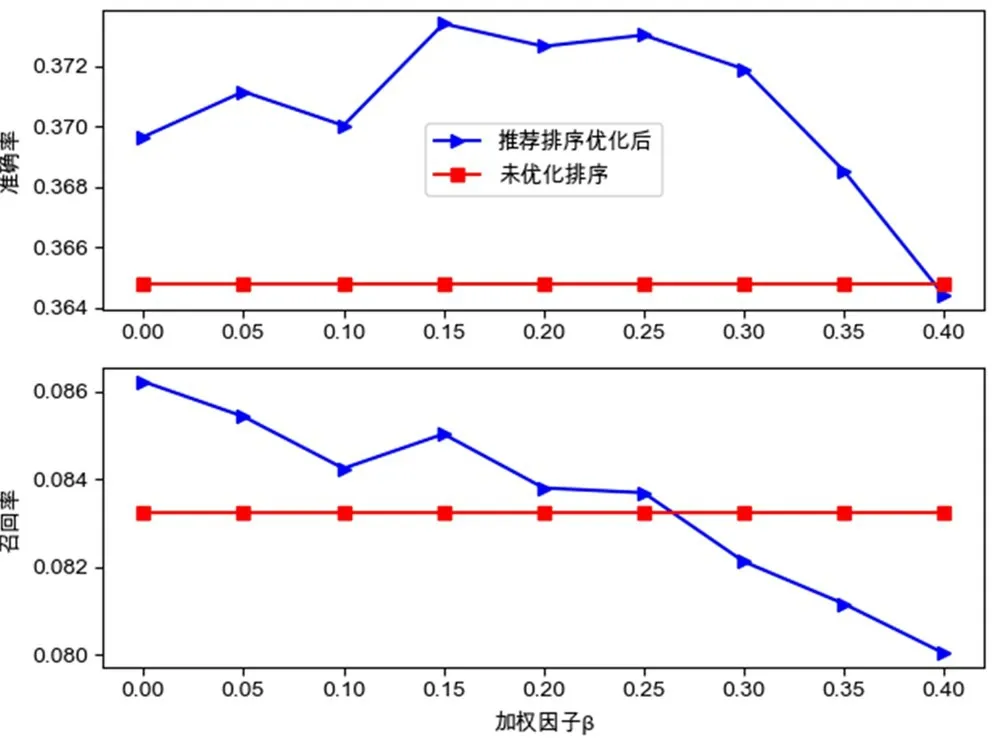
图6 推荐影片排序优化前后推荐效果对比
实验结果表明,随着影片片种加权因子的变化,推荐准确率先增再减,推荐召回率呈逐渐减少趋势。在加权因子β=0.15时准确率最高,达到37.3%,比未加权提高2.3%;召回率为8.5%,比未加权提高2.2%。
综合上述两组实验结果可知,在传统基于用户的协同过滤推荐基础上,通过修正评分预测模型、干预近邻计算、优化推荐影片排序后,推荐算法准确率能达到37.3%,较优化前提升2倍,算法召回率能达到8.5%,较优化前提升约2.7倍,算法改进有效。
5 结语
本文通过对农村电影院线在影片订购区域性、引导性、计划性上的深入分析,不断改进和优化传统推荐算法,提出了一种适用于农村电影放映场景下的影片订购推荐算法,实验结果表明算法改进效果达到预期。但本文方法是在离线环境下计算并完成推荐,在线推荐还需要考虑影片档期和计算时效性等问题,并且方法中对影片类型细分颗粒度还不够,这些问题将在下一步研究工作中予以优化。
