基于深度学习的蚀变矿物识别
——以新疆白杨河铀矿床为例
2021-07-30易敏叶发旺张川邱骏挺
易敏,叶发旺,张川,邱骏挺
(核工业北京地质研究院 遥感信息与图像分析技术国家级重点实验室,北京 100029)
[关键字]高光谱遥感;蚀变矿物识别;深度学习;白杨河铀矿床
现代遥感不仅能提取蚀变和其他地质信息,还能发挥其独有的优势进行大范围有效的蚀变矿物填图,能为地质工作者对矿床成因增深理解[1-2],因此蚀变矿物识别是遥感地质中非常重要的一项工作。目前国内外对矿物光谱识别的方法以传统的光谱角匹配(SAM)、匹配滤波等方法为主[3-5],但他们对矿物光谱的细微差别不够敏感,同时受光谱信噪比、光谱重建等精度影响较大[6]。因此亟待研发一种能挖掘光谱潜在信息的算法,准确而又高效的识别蚀变矿物。
神经网络(Neural Network)是机器学习的一门分支,是受生物大脑启发建立的算法模型。目前在语音处理、图像分类、垃圾邮件处理、搜索引擎等领域均发挥了不可替代的作用。机器学习与传统算法最大不同之处在于,可以对已知数据进行学习得出模型参数。若能对蚀变矿物进行智能化识别,实现端到端的操作,必将大幅度减少人力成本,从而增加工作效率。为此,本文意图通过现有的数据,基于Tensorflow 框架,训练蚀变矿物识别模型,并对模型进行分析、评价,为蚀变矿物智能识别提供参考与借鉴。
1 网络架构
1.1 全连接网络
全连接神经网络是由输入层、输出层以及若干隐藏层组成。每一层包含多个节点,每个节点先进行线性运算,再通过激活函数进行非线性运算。模型训练是基于梯度下降原理,反复迭代循环,更新模型的参数,达到“学习”的效果,再根据学来的“知识”,对模型的性能进行测试与应用(图1)。
如图1 所示,共有4 个隐藏层与一个输入层、一个输出层。输入层输入的是蚀变矿物的光谱数据,隐藏层各层节点数分别为256、512、128 和128 个。网络激活函数、优化算法等信息如表1 所示。

表1 模型其他参数细节信息Table 1 Details of other parameters of the model
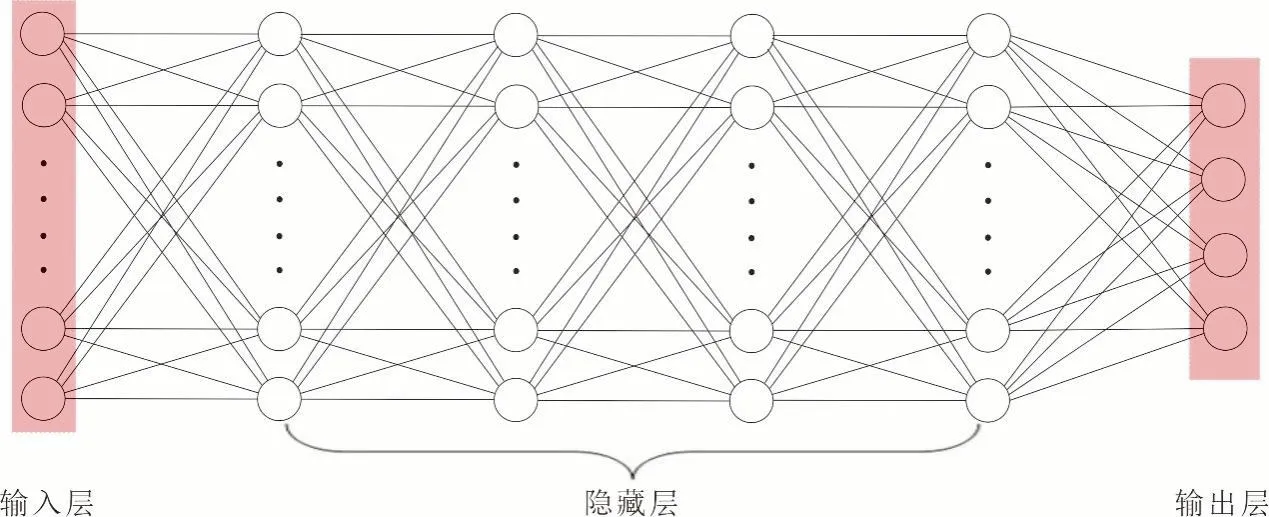
图1 全连接网络结构Fig.1 Fully connected network structure
1.2 残差神经网络
对于全连接神经网络,理论上深层网络不会比浅层网络模型的效果差,但由于BP 算法会随着网络深度的增加出现梯度消失或梯度爆炸的问题,使得多数情况下深层网络的能力反而弱于浅层网络,因此在实际应用中网络结构不是越深越好。同时深层网络在训练过程中,也存在饱和问题,随着深度增加,模型的训练精度和测试精度会达到饱和并且迅速降低,即网络退化。在此基础上,何恺明等[7]提出了残差神经网络,通过跳层连接的方式,很好的解决梯度消失与网络退化问题。
残差网络结构中,输入数据为蚀变矿物光谱,输出为类别(图2)。网络激活函数、优化算法等信息见表1。以期望构建更深的网络来提高分类结果的精度与稳定性。
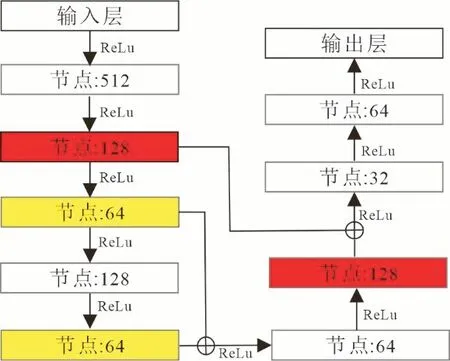
图2 残差网络结构Fig.2 Residual network structure
1.3 一维卷积神经网络
与全连接神经网络不同,卷积神经网络可以识别数据中的简单模式,使用这些简单模式在更高级层中生成复杂模式,再通过一定的规则对数据进行分类。光谱数据目视解译的核心在于识别特征波段与特征吸收峰,不同的吸收峰多数情况下对应着不同的化学键或者物质,因此希望利用卷积神经网络的特征提取来识别类似的模式,进而达到好的识别效果。无论是一维、二维还是三维,卷积神经网络都具有相同的特点和相同的处理方法,关键区别在于输入数据的维数以及特征检测器如何在数据上滑动。
卷积神经网络框架,输入为蚀变矿物的光谱曲线,通过卷积层与池化层的多次组合构建的卷积块来提取光谱曲线的特征。池化层能增加特征提取的视野,使卷积层不仅仅局限于设定的卷积窗口,扩大特征提取的范围。模型中卷积层均采用3×1 且步长为1 的卷积核。最后将提取的特征输入全连接神经网络中,对提取的特征进行学习与应用(图3,表2)。

表2 一维卷积神经网络模型参数Table 2 One-dimensional convolutional neural network model parameters
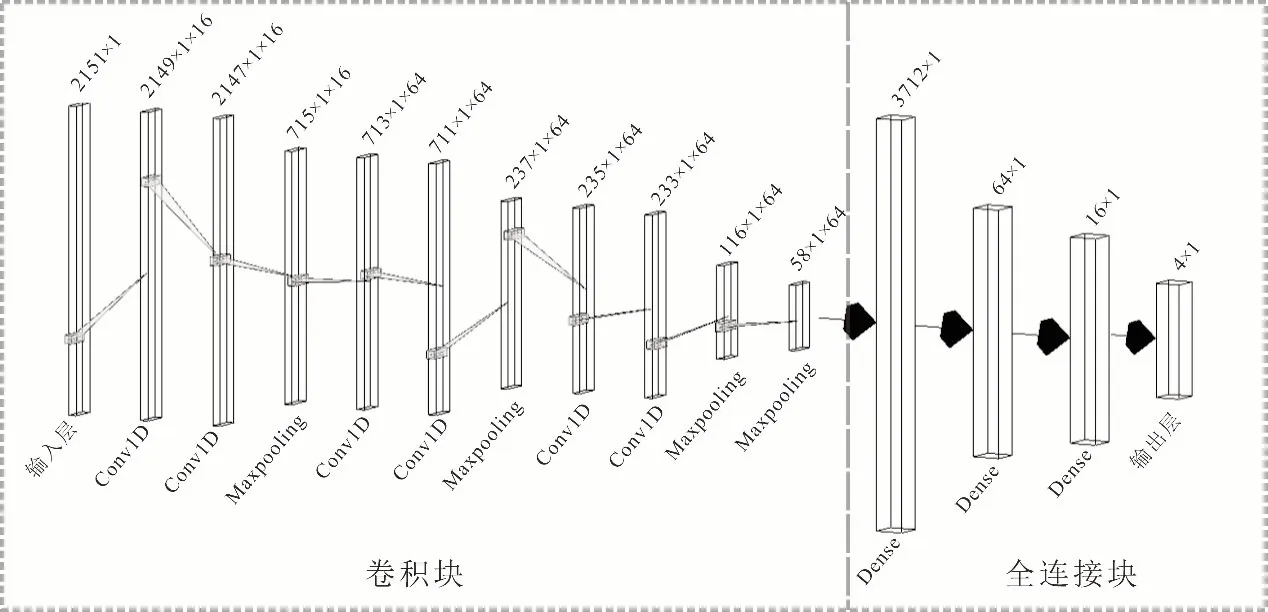
图3 一维卷积神经网络结构Fig.3 One-dimensional convolutional neural network structure
2 数据
本文所用的光谱数据来自新疆雪米斯坦白杨河铀矿床的8 个钻孔(图4)。数据采集使用的仪器为:FieldSpec4可见光-短波红外地面光谱仪,共探测波谱范围为350~2 500 nm,光谱分辨率在350~1 050 nm范围内为3 nm,1 050~2 500 nm范围内为10 nm。数据采集利用内置光源,进行接触式测量,光谱测量点间距通常为30 cm,对于肉眼可见蚀变强烈位置则进行加密测量,间距为10 cm,各个测点记录两条曲线,共计6 700 个测点。
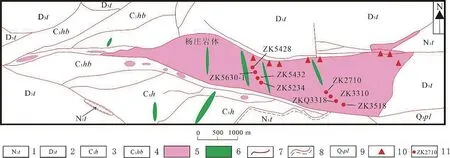
图4 白杨河铀矿床地质简图与钻孔分布图Fig.4 Geological map and borehole distribution of Baiyanghe area
经光谱分析可知,钻孔中较为发育的有4 类蚀变矿物,分别为伊利石、蒙脱石、绿泥石和碳酸盐[8-10]。经统计,伊利石有1 843 个样本数据、蒙脱石有800 个样本数据、绿泥石有310 个样本数据,碳酸盐有141 个样本数据(图5)。伊利石的特征吸收峰位于2 200 nm,在2 345 nm 处有个次级吸收峰;蒙脱石在2 200 nm 附近存在特征吸收峰;绿泥石在2 250~2 260 nm 有个特征吸收峰,在2 340~2 350 nm 位置存在次级吸收峰;碳酸盐在2 320~2 340 nm 存在吸收峰(图6,表3)。

表3 蚀变矿物的光谱特征Table 3 Spectral characteristics of alteration minerals
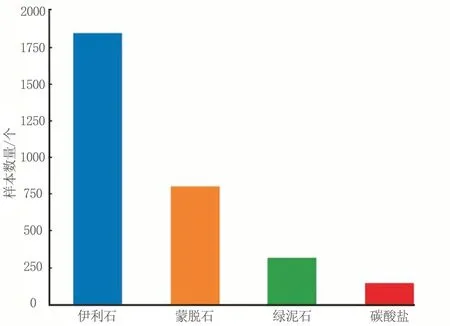
图5 样本数据数量分布直方图Fig.5 Histogram of the number of sample data
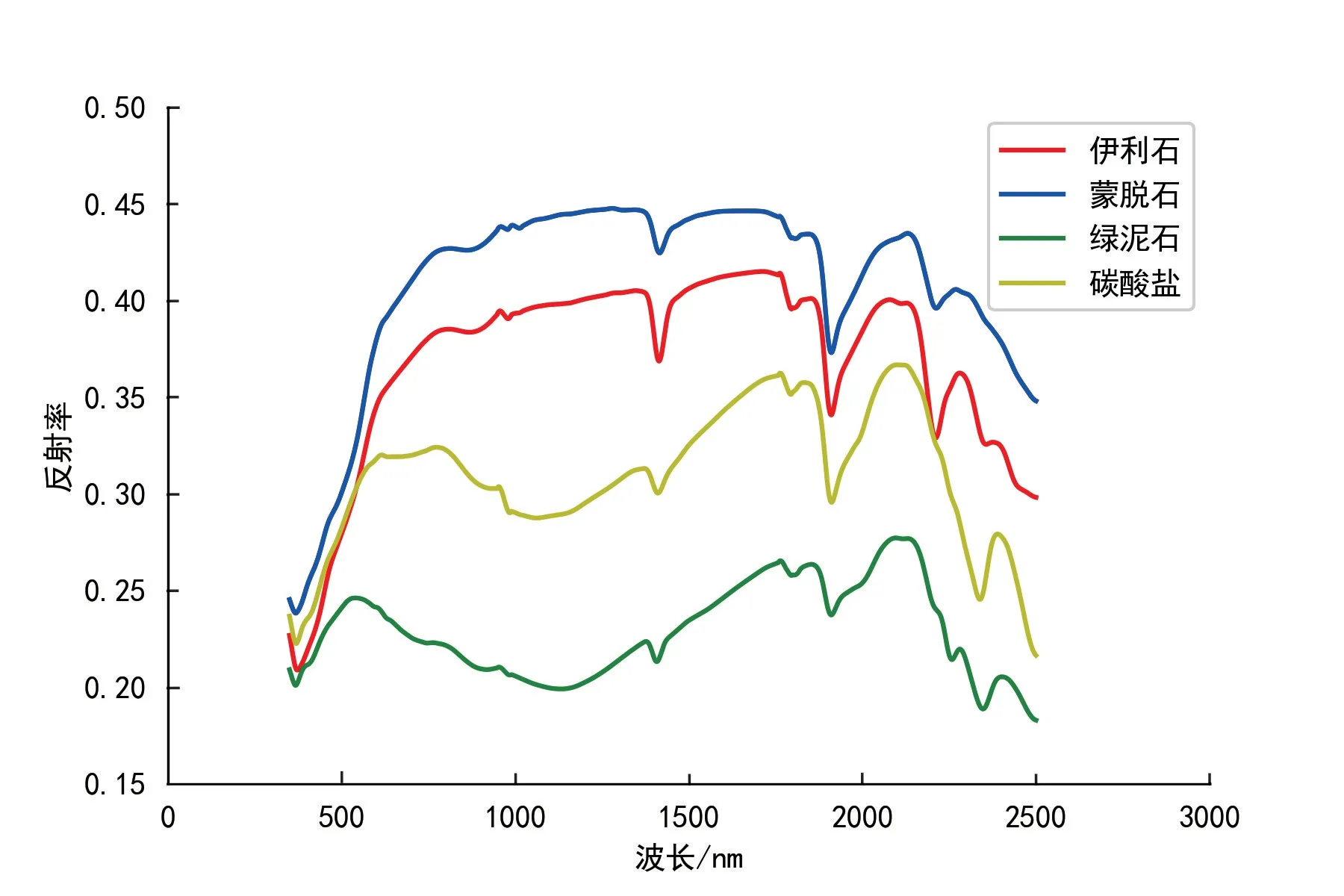
图6 蚀变矿物光谱曲线Fig.6 spectral curve of alteration minerals
为了更好地开展基于不同网络模型的蚀变矿物识别研究,对测得的光谱数据进行光谱去噪和数据增强处理。
2.1 光谱去噪
在测量过程中,由于操作不规范以及环境和仪器自身的影响,采集的矿物光谱信息或多或少包含噪声。在光谱分析中,常用的去噪方法有小波变换、傅里叶变换和光谱平滑滤波等。光谱去噪的实质是去除光谱曲线中的锯齿,使其平滑而又不失整体形态。本文利用常见的Savitzky-Golay平滑滤波方法对噪声进行处理。Savitzky-Golay平滑滤波是一种时域内基于局部多项式的最小二乘拟合方法,被广泛用以数据流平滑去噪。
算法的核心思想是对一定长度窗口内的数据点进行k 阶多项式拟合,得到拟合后的结果进行插值。S-G 滤波窗口进行的是加权平均运算,加权系数是根据互动窗口内点的高阶多项式的最小二乘拟合得出,在进行平滑滤波时,拟合信号中的低频成分,过滤高频成分。同时也存在一定的问题,如果噪声在高频段,那么滤波的结果就是去除了噪声,反之,若噪声在低频段,那么滤波的结果就是留下了噪声。S-G 滤波在去除噪声的同时可以确保信号的形状、宽度不变。
2.2 数据增强
在光谱分析中,光谱特征位置搜索最常见的方法是选择其特征吸收波段,通常会进行包络线去除来增强吸收峰谷的视觉效果。包络线是根据光谱曲线连接而成的折线段。包络线去除的核心,是通过实际光谱曲线上各个点与包络线对应波长的值进行比值,计算得到的结果保持了光谱的波长数且范围仍然在0~1 之间。以样本数据中某单个光谱数据进行包络线去除(图7,图8)。可以看出,经过包络线去除后,光谱曲线的吸收特征明显增强。
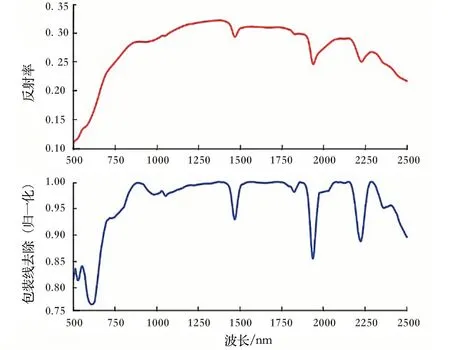
图7 包络线去除光谱曲线对比Fig.7 Comparison of envelope removal spectrum curves

图8 经包络线去除后各类样本的平均曲线(数值有偏移)Fig.8 The average curve of the sample after the envelope is removed(the value is offset)
3 实验结果
基于Tensorflow 框架,搭建全连接网络、残差网络与卷积神经网络3 种模型,用新疆白杨河铀矿床8 个钻孔3 094 个样本数据对模型进行分析与评价。随机挑选80%的数据作为模型的训练样本,20%作为测试样本。同时输入的数据分为两组,一组是未增强的原始数据作为输入,另一组是包络线去除后增强数据作为输入。结果发现,3 种模型的测试精度均随着模型的训练精度升高而上升,但训练到一定程度后,测试精度整体趋于稳定且上下波动(图9)。
全连接网络共训练250 次,从图9 a、9 b 可以看出,训练精度与测试精度的精度起伏差可以达到10%~25%,难以挑选出最佳训练次数,利用未增强数据能相对减少精度的大范围起伏,表明包络线去除不能增加全连接网络的鲁棒性。
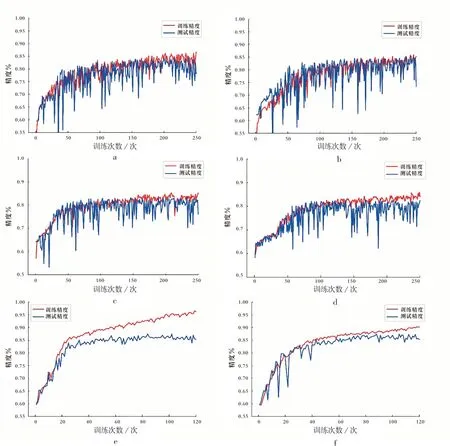
图9 各类模型的训练精度和测试精度Fig.9 Diagram of training accuracy and test accuracy of models
残差网络共训练250 次,从图9 c、9 d 可以看出,训练精度与测试精度有较大的起伏,但浮动差值较全连接网络小,但也难以得出最佳训练次数范围,模型鲁棒性不佳,去包络线数据不能增加网络的鲁棒性。
卷积神经网络由于收敛速度快,因此训练次数较前者网络少,共120 次。从图9 e、9 f 的模型训练精度与测试精度曲线能看出,随着训练次数的增加,测试精度达到饱和而趋于稳定,而训练精度曲线与测试精度曲线分离,模型进入过拟合阶段。未增强数据训练的模型较增强数据训练的模型测试精度更早达到饱和,所需训练时间少,而数据增强模型对抵抗过拟合能力强。相比而言,精度浮动较全连接网络与残差网络更小,且精度比二者高,鲁棒性最好。
根据各个模型的测试精度与测试精度曲线,选取相对最佳训练次数训练出6 个蚀变矿物识别模型的模型参数与精度及模型分类结果混淆矩阵(表4,图10)。

表4 各模型分类结果对比Tab.4 Comparison of classification results of dilerent models
由图10 a、10 b 可知,训练出的全连接网络对蒙脱石与绿泥石的识别能力强,而对伊利石和碳酸盐识别能力差,其中二者对蒙脱石的识别准确度为94%,识别精度最低都为碳酸盐。存在严重的伊利石误分为蒙脱石与碳酸盐误分为绿泥石现象,而包络线去除能稍微改善碳酸盐与绿泥石误分情况。
由图10 c、10 d 可知,不同输入数据训练出的残差网络间差异大,以未包络线去除的数据作为输入的残差网络只对伊利石有较好的识别效果,碳酸盐误分为绿泥石的比率大于正确分类比率;以增强数据训练的模型对蒙脱石与绿泥石具有很好的识别结果,却存在严重的伊利石误分为蒙脱石以及碳酸盐误分为绿泥石现象。
由图10 e、10 f 可知,不同输入数据训练出的一维卷积网络差异不大,均对伊利石与绿泥石识别效果好,但也存在误分现象,主要是蒙脱石误分为伊利石与碳酸盐误分为绿泥石;包络线去除对一维卷积模型精度有一定的改善。

图10 各类模型分类的混淆矩阵Fig.10 Confusion matrix of various model classifications
4 讨论
对3 种网络模型训练与测试的结果分析表明,不同神经网络模型训练出的性能差异很大,不同类型数据输入对模型训练也存在显著差异。在训练模型过程中,全连接网络与残差网络的训练精度与测试精度上下浮动大,不利于寻找最佳模型训练次数,若仅根据训练与测试精度最高点寻找最佳模型会使模型缺乏一定的鲁棒性。对模型进行多次训练与测试,计算各个精度指标的平均值来增加模型间的可比性。
由图9 可见,全连接网络的测试与训练精度上下浮动大,这是由于迭代次数增加,权重不断更新,更新后的权重不能稳定提升识别精度,导致精度浮动大。在全连接网络的基础上,以跳层连接方式增加网络深度的残差网络也同样存在这个问题,这也表明网络层数增加不能稳定提升模型识别精度。而以模式识别为主的一维卷积神经网络,收敛快且相对稳定,在一定程度上缓和了全连接和残差网络这方面的劣势。
由图10 可见,全连接网络和残差网络识别结果中,均存在严重的错分类现象。错分类别有相似的特性,即以蒙脱石与伊利石、绿泥石与碳酸盐为主,而一维卷积网络的错分情况相对有所改善。根据图6、图8 可以发现,蒙脱石与伊利石的光谱相似度高,碳酸盐与绿泥石的光谱相似度高。一维卷积网络模型的识别结果发现,光谱相似度高的两组类别中,样本数量多的类别分类效果好。同时发现包络线去除虽然能增加光谱吸收峰谷的特征,但并不能稳定的提高矿物的识别精度。
基于神经网络算法对矿物蚀变识别能有不错的效果,但在研究中又存在一些问题,例如样本数量的均衡问题与网络本身的局限性问题。对这些问题的改进或许能进一步增加模型的识别精度,也可以从光谱数据处理方面入手来强化网络的特征提取能力进而提升识别精度。
5 结论
本研究实验表明,以Tensorflow 深度学习框架为基础,利用全连接网络、残差网络和一维卷积神经网络对新疆白杨河铀矿床钻孔岩心数据进行训练,通过对比研究,得出以下结论:
1)全连接网络、残差网络和一维卷积神经网络对蚀变矿物识别都具有好的可行性。但整体而言,一维卷积神经网络模型鲁棒性更强,同时还能实现端到端识别,减少人为操作与工作量。
2)包络线去除虽然能在视觉上增强光谱的吸收峰谷特征,但不能很稳定的增加模型的鲁棒性,同时包络线去除在一定程度上会影响模型的识别精度。
3)3 类模型识别精度低的均为光谱相似性高但训练样本较少的蚀变类别,或许可以通过增加样本数量以及平衡各类样本数量来进一步提高模型的精度,用具有更多“知识”的模型来更准确识别样本类型。
