基于渐进对抗学习的弱监督目标定位
2021-07-28罗汉武李文震潘富城琚小明
罗汉武,李文震,潘富城,琚小明
1.国网内蒙古东部电力有限公司,呼和浩特010010
2.华东师范大学 软件工程学院,上海200062
目标定位是计算机视觉领域中的一个基本组成部分,它旨在确定图片中感兴趣目标的位置。伴随着深度学习的爆炸式发展,目标定位任务已经取得了突破式的的进展。诸如Faster RCNN[1]、YOLO[2]、SSD[3]、CornerNet[4]等一系列算法利用深度卷积神经网络结合滑动窗口和关键点的思想在定位精度和召回率上都取得了极大进步。然而,目前最先进的目标定位模型都需要大量精细的类别标签和位置信息(如边界框注释和分割掩码注释)在全监督的条件下才能训练。这些耗时耗力的精细标注在实际应用中往往很难获取,而且标注缺失严重,同时还存在数据量短缺的问题。这些问题无疑成为了深度学习大规模应用的阻碍。为了解决这些问题,弱监督目标定位技术已经引起越来越多的研究者关注。
弱监督目标定位一直保持着相当的挑战由于仅仅使用图像级的标注。它与全监督学习的巨大鸿沟源于缺少位置注释所造成的目标定位的随机性。如何利用弱注释的数据挖掘潜在的语义信息成为弱监督目标定位的重点所在。目前解决弱监督目标定位的最常见方法是将弱监督目标定位问题描述为多实例学习(Multiple Instances Learning,MIL)。MIL将每个训练数据看作是一个“包”,将检测目标看做“包”中的一个个实例,在训练检测器时迭代的挑选置信度最高的实例。在MIL中,大量的目标提案(Object proposal)的选取是通过一些传统的算法,例如selective search[5]、edge boxes[6]等完成的。但是当面对大规模数据时,这些算法选择会带来大量训练噪声,造成MIL 学习困难,测试结果不理想。另一方面,MIL天然的非凸性质造成这类方法对于模型初始化极其敏感,并且在训练中容易陷入局部最小值。为了解决这些问题,研究者们在更好的模型初始化方法[7]、优化策略[8]、经验化正则[9]等方面均取得了一些成果。但是,在如何量化次优解以及有效减少定位随机性等方面,现有方法仍然没有完全解决。
最近,类激活映射(Class Activation Mappings,CAM)[10]方法从另一个全新视角描述了弱监督目标定位任务。这种方法直接利用了卷积网络分类器学习到的具有辨别力的特征进行目标定位。它的关键思想是具有较高准确率的分类器应该观察到了相应目标后才会做出相应的分类决策。换句话说,具有辨别力的特征来自于相应的目标区域。然而,这种方法本质的缺陷是分类器总是倾向于关注少部分最具辨别力的特征以此决定分类的结果,这种缺陷直接导致了定位图总是仅仅覆盖目标最具有辨别力的一小部分,从而导致了定位错误。为了覆盖完整目标,对抗擦除技术(Adversarial Erase,AE)[11-15]已经被广泛应用解决CAM的缺陷。这些技术之间的相似之处在于,它们防止模型仅依赖于最有区别的部分进行分类,而是鼓励模型也学习较少有区别的部分,从而可以尽可能地定位更精确的目标边界。
本文将重点放在以CAM 为代表的新兴方法上,而不是MIL。多个研究已经表明,通过擦除最具辨别力的部分,对抗擦除技术可以有效捕捉完整的目标。然而,一些缺点也不能忽视,对抗擦除技术对计算资源消耗巨大且过度擦除容易忽略小目标。同时,无论是多实例学习还是对抗擦除学习,目前存在的方法总是直接利用大规模且有噪声的数据集合中训练对象检测器。由于数据集包含许多噪声,这直接导致获取正确的定位结果极具挑战性。无法忽视的是,目前的手工注释仍然存在很多主观的偏见,一个典型的例子就是一张图片的标签是鱼,然而场景中包含人。这些主观偏见同时也造成训练的不稳定性。
为了解决上文提及的一些缺陷,本文提出了渐进对抗学习解决弱监督目标定位问题。基于渐进对抗学习,训练数据首先依据学习协议将数据分为数个不同级别从而反映数据从简单到复杂的程度,例如简单背景到复杂背景,单个目标到多个目标等。然后基于多标签分类网络进行弱监督训练。为了提升网络的鲁棒性,提出相应的对抗损失函数适应弱监督目标定位。为了实现定位完整目标,利用金字塔对抗擦除机制逐层处理多个不同尺度的特征。从而在最后的定位图中定位完整的目标边界。相较于同类型的对抗擦除学习方法,本文的对抗擦除学习将弱监督定位从单目标拓展到了多目标定位,与同类型方法相比,其网络结构更加简洁,消耗资源也相对较小。与其他具有代表性的弱监督定位方法相比,实验结果充分表明了渐进对抗学习能够在弱监督学习下完成精确的目标定位,性能相较最先进的算法具有竞争力。
1 相关工作
1.1 对抗擦除学习
最近提出了数个弱监督学习方法利用了对抗擦除学习发现完整的语义目标,以此定位精确的目标边界。Singh 等人[12]提出HaS(Hide-and-Seek)策略用于将图片分割为多个网格块然后随机擦除某个块,从而迫使神经网络可以关注目标的不同部分,实现了弱监督目标定位。但是直接快速地随机选择策略导致的随机性无法有效擦除最具辨别力的特征。与此同时,Wei 等人[13]通过训练一个额外的分类网络实现了对抗擦除,通过将已经擦除部分辨别力特征的图片训练另一个分支网络,然后将多个分支的定位图融合从而定位完整的目标。这种方法的一个不可忽视的缺点就是必须花费更多的训练时间和计算资源来训练几个独立的网络以获得完整的目标区域。考虑到这些问题,Zhang等人[14]提出了一种新颖的对抗互补学习方法(Adversarial Complementary Learning,ACoL)以端到端的弱监督训练了一个精确的目标定位网络用于发现完整的语义目标。然而,这种方法仍然需要训练额外的分类器。为了实现更有效的对抗擦除学习,Choe等人[15]又提出了ADL(Attention-based Dropout Layer)层,一种轻量级但功能强大的方法,该方法利用自我注意机制来擦除对象的最有区别的部分。充分考虑上述方法的优缺点,尽管对抗擦除学习可以帮助网络不仅仅关注一部分语义目标,然而对抗擦除学习存在过度擦除丢失语义目标的现象,并且现有的对抗擦除方法往往只在一层特征图上实现擦除,由于一层特征图的信息有限,使用对抗擦除后往往很难挖掘完整的语义目标。受最近在特征金字塔研究[16-19]突破的启发,对抗擦除可以不仅仅在同一层进行,而采用多层特征图逐层擦除的方式,通过有序的在擦除后对于特征进行融合,既可以保证让网络不仅仅关注语义目标的一部分,也可以保证语义信息不会被过度擦除,因此可以挖掘更多的语义信息,实现更高精度的目标定位。因此本文提出金字塔对抗擦除机制,通过金字塔层次的对抗擦除方法,实现了擦除和融合两个互补操作,既保证可以挖掘完整的语义目标也可以保证语义信息不会被过度丢失,实现了端到端的目标定位网络,有效解决了上述方法的一些缺点。
1.2 渐进自步学习
受认知科学的启发,Bengio等人[20]首次提出了课程学习(Curriculum Learning,CL)的概念。在CL中,通过从简单到复杂逐渐将样本纳入训练中来学习模型。为了更好的解释性,Kumar 等人[21]将CL 原则表述为称为自步学习(SPL)的简明优化模型。最近,在计算机视觉领域已经提出了数个自步学习算法,包括视觉追踪[22]、图像搜索[23]、目标检测[24-25]等。这些方法充分说明了通过将复杂问题分解为更简单的问题可以在各种计算机视觉任务中获得更好性能。本文的后续实验也充分说明了自步学习对于弱监督的对象定位问题也是特别重要的。
2 基于自步对抗学习的弱监督目标定位
2.1 网络架构
基于渐进对抗学习的弱监督目标定位网络的架构如图1所示,考虑到传统的图像分类问题总是假设每张图片仅仅包含一个目标,这种假设导致使用图像分类网络仅在图像级标签训练弱监督目标定位网络存在天然的不适应性。为了缓解这种不适应性,本文将弱监督目标定位问题描述为多标签分类问题。同时,考虑到现有的多标签分类网络总是将每个标签的分布视为独立的,这种策略对于多目标分类是不适用的,因为很多目标之间存在内在的上下文关系,例如骑自行车的人,人的空间位置是在自行车之上,这种上下文关系往往成为弱监督定位多目标很重要的因素,因此需要通过一些方式引入多目标的这种上下文关联应用于目标定位。本文提出对抗标签损失解决上述问题。对抗标签损失本质上从正反两个方面来进行建模,及网络不仅要预测图片包含什么,还要预测图片不包含什么,通过包含与不包含关系的建模,可以巧妙地打破传统多标签分类网络将各个标签建模为单独分布的缺陷,更好地适应多目标弱监督定位问题。
具体来说,假设数据集有K类目标以及N张训练集图片。本文将训练集形式化定义为:ℓ={(I(1),L(1)),(I(2),L(2)),…,(I(N),L(N))},这里I表示图片数据,L表示相应的标签。L=[l1,l2,…,lK]T形式化为K维向量。每个l用1或者0表示是否相应的目标是否在图片中出现。本文提出的对抗多标签损失如下。
如图1所示,在最后的分类阶段,首先添加了一个正常的全连接层(FC layer),对应的标签为L=[l1,l2,…,lK]T,然后,添加了一个相反的对抗分支(Adversarial FC layer),对应一个对抗标签,定义如式(1):
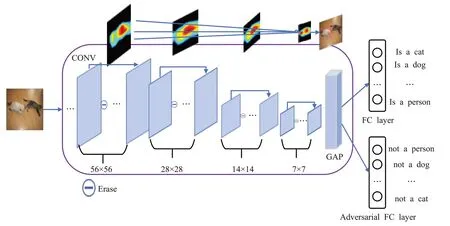
图1 基于渐进对抗学习的弱监督定位框架
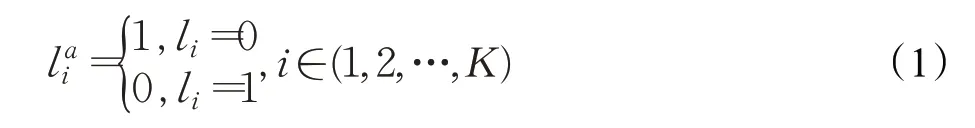
这里每个L显示是否图片包括相应的目标。同样的是,每个La表示是否图片不包含相应的目标。为了计算最后的损失,对于输入的图片I,前向计算获取最后的两个K维向量输出P(I)以及Pa(I),两个输出均通过sigmoid 函数实现了概率化处理。P(I)为FC layer的输出,表示每个目标出现的概率,Pa(I)为Adversarial FC layer的输出,表示每个目标不会出现的概率。对于某一张输入图片,对于第i类的损失可以定义为式(2):

总损失通过对所有训练样例以及所有类别进行求和平均得到,如式(3)所示:
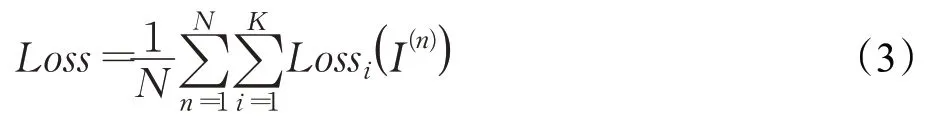
与可挑选的其他损失函数,例如二元逻辑回归损失和多分类交叉熵损失等相比,本文提出的对抗多标签分类损失通过引入对抗分支,其可以充分考虑到不同目标的上下文关系,因此本文的多标签分类网络可以更好地适应多目标定位任务,在实际训练中可以避免大量的训练噪声使训练更稳定。
2.2 金字塔对抗擦除机制
为了解决定位图总是仅仅覆盖目标的一部分,无法定位完整目标以及对抗擦除学习总是消耗太多计算资源的问题。受He等人提出的ResNet[26]以及FPN[16]启发,深度卷积神经网络通过多个网络层计算了多层次的特征维度。从低维度到高纬度的语义信息天然构成了金字塔形状。从感受野的角度,随着神经网络越来越深,其感受野也会越来越大,最后一层的感受野可以感受最具有辨别力的特征,这对于单纯的图形分类是有利的,然而迁移到目标定位问题,就会产生无法定位完整目标的问题。多个研究已经表明,通过特征融合可以有效提升多个不同计算机视觉任务。为了解决弱监督目标定位问题,本文提出金字塔对抗擦除机制,通过在不同尺度的网络层进行对抗擦除并融合相应语义信息,从而鼓励最后一层的特征图可以感受不同感受野的语义信息,最后可以定位完整目标。
本文的网络结构基于ResNet50,不同于以前提出的对抗擦除方法,本文逐步擦除{56×56,28×28,14×14,7×7}四个不同尺度的特征图。考虑到Resnet 架构中,多个层会产生相同大小的特征图,本文将这些层称为AE step。如图2 所示,金字塔对抗擦除机制作用于AE step{1,2,3,4}。对于每一个AE step,令表示AE step i的第一层,表示AE step i的最后一层。将的每个值归一化到[0,1]的输出定义为。那么在中,最具辨别力的部分可以定义为特征图一系列像素点的值大于给定阈值δ的部分。通过将其像素值置为0,从而擦除中最具辨别力的部分。单纯地擦除无法鼓励网络发现目标的不同部分,因此,本文使用跳远连接(skip connection)对擦除前和擦除后的相同大小的层进行特征融合,令表示融合过的层,计算如式(4)所示。对和逐元素求最大值。

图2 金字塔对抗擦除机制
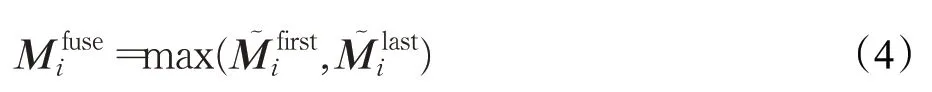
在测试图片阶段,可以获取最后一层的融合定位图,将其调整和原始图片一样的大小。为了产生相应的预测回归框用于定位,通过固定的阈值分割前景和背景。然后寻找覆盖前景像素中最大连接区域的边界框,这可以生成对应的回归框。
2.3 自步学习协议
为了避免大规模数据级内在的大量噪声影响训练结果,本文提出了一个自步学习协议对训练集的图片进行了由简单到复杂的排序。训练数据集包括ILSVRC 2012[27]and Pascal VOC 2007[28],为了从难到易挑选训练样本。本文设计的排序协议通过衡量每张图片视觉搜索的难度进行排序。
准确地说,本文采用了多种图像属性综合排序一张图片的视觉搜索难度。例如杂乱背景、规模和位置、类别类型、遮挡和其他类型的噪音。不失一般性。本文与文献[29]采用了一致的评估标准。包括注释的目标数、目标占整张图片的比例、不同目标类的数量、目标的截断、被遮挡目标的数量、已经被标注为检测困难的目标数量。这些标准通过Kendall’s τ[30]相关系数进行了数字化。Kendall’s τ 是基于两个变量之间不一致对的数量和一致对的数量之间的差异除以对总数而得出的序数数据的相关性度量。作为一种有效的措施,实际上可以对图像难度进行良好的度量。更多的细节可以参阅文献[29]。
值得注意的是,由于ILSVRC 2012 多用于图像分类任务,因此仅仅包含一个目标,因此ILSVRC 2012与包含多目标的Pascall VOC 2007 使用自步学习协议进行单独排序。首先训练单目标的ILSVRC 2012,然后接着训练多目标的Pascal VOC 2007,这种自步学习过程对于提升训练稳定性是极为重要的。
3 实验和结果分析
3.1 实验设置
本文实验的训练和测试数据集是ILSVRC 2012和Pascal VOC2007 数据集,其中ILSVRC 2012 仅选取了与Pascal VOC数据集对应的20类目标。实验评估指标根据数据集不同而有所不同。对于ILSVRC 2012测试集,本文采取Top1 误差、Top5 误差,具体表现为相应的预测第一类的和前五类的分类和定位误差。对于Pascal VOC 2007数据集,本文采用了弱监督目标定位的通用评估指标CorLoc(Correct Localization,正确定位率)。其中CorLoc计算了测试图片中预测回归框与真实值大于等于0.5 IoU(Intersection over Union,交并比)的比例。最后,本文也可视化了部分Pascal VOC2007测试集的定位表现。
3.2 对比实验分析
本文选取了多个先进的弱监督目标定位算法与本文的自步对抗学习算法进行了对比。在ILSVRC 2012数据集测试中,选取了c-MWP[31]、ACoL[14]、ADL[15]三种算法进行对比。在多目标的Pascal VOC2007数据集测试中,选取了LCL[32]、WSDDN[33]、TS2C[34]、C-WSL[35]进行了对比。为了逐步地比较不同组件对自步对抗学习的影响,本文使用了缩略词表示自步对抗的每一步:
(l)PAE(Pyramid Adversarial Erase):使用金字塔对抗机制。
(2)AMCL(Adversarial Multi-label Classification Loss):使用多标签对抗损失。
(3)SPL(Self-Paced Learning):使用自步学习协议。
表1显示了自步对抗学习与上述三种算法在ILSVRC 2012数据集上的弱监督定位结果,用Top1误差、Top5误差表示,其数值越小表示结果越好。
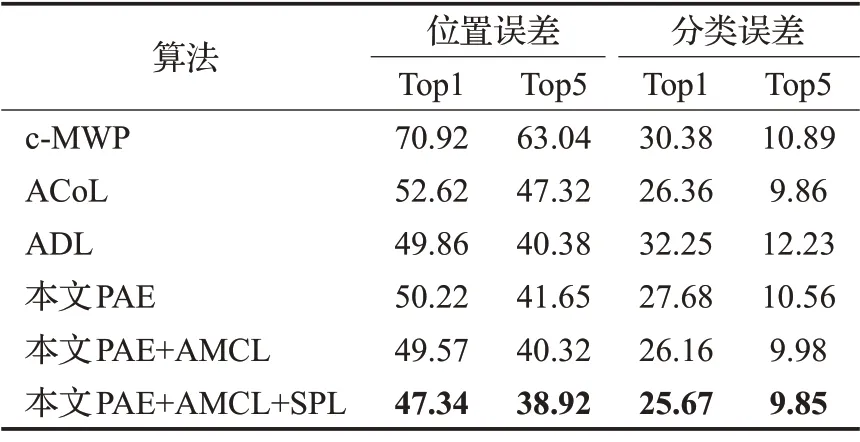
表1 ILSVRC 2012对比实验 %
正如表1 所示,随着不同组件的应用,自步对抗学习的Top1、Top5 的位置误差和分类误差逐步减少。其中自步学习对于整体的提升有很大贡献,因为自步学习保证了模型在强噪声条件下可以平缓地学习挖掘语义目标,与其他三种算法对比,在最优配置下,在Top1 位置误差上,比ADL 低2.5 个百分点,比ACoL 低5.3 个百分点,比c_MWP低23.6个百分点,体现了自步对抗学习在强噪声和弱监督下可以实现更有效的目标定位,这得益于自步学习从简单到复杂的学习,保证了模型学习参数是的稳定性。在Top5 位置误差上,自步对抗学习仍然优于其他算法,体现了算法在预测多个类别的稳定性。同时,与其他算法在位置误差和分类误差的权衡不同,渐进对抗学习在稳步提升定位精度的同时也减少了分类的误差。
渐进对抗学习在弱监督单目标定位上实现了相当的稳定性和精度。为了验证算法在多目标定位的效果,本文在VOC 2007 数据集上进行的对比实验如表2 所示,主要指标为CorLoc,检测多张不同图片的多个目标。本文实现了平均61.3%的CorLoc。特别在“bird”“person”两类上实现了最先进的提升。本文的结果优于LCL、WSDDN、TS2C 三种算法,仅次于C-WSL 算法。但是值得注意的是C-WSL 还使用了其他监督信息用于训练。C-WSL算法利用每类对象的数目作为监督从一组对象建议中识别正确的高得分对象框,而本文仅仅使用了图像级别的监督信息。
如表1 和表2 所示,实验也评估了渐进对抗学习不同组件的作用,从结果上来看,单纯地使用PAE 的结果是比较差的,尤其在VOC2007 数据集上,仅仅达到了42.1%,远低于其他对比的算法。这与训练中的大量噪声导致学习的模糊性是分不开的。强噪声情况下,由于缺乏位置信息,尽管使用PAE 可以尽可能挖掘语义目标,但是由于存在多个语义目标,在网络训练时,语义目标挖掘仍然存在较大的随机性,因为AMCL可以挖掘不同语义目标的关系,同时也能提升学习单一语义目标的效果。因此随着AMCL的使用,两个数据集上的评估结果都取得了比较明显的提升。在VOC2007,CorLOC增加了7个百分点(42.1%到49.9%),SPL已经在其他视觉任务上是一种有效的学习策略,使用SPL 后,CorLoc 实现了巨大的提升。

表2 Pascal VOC 2007对比实验(CorLoc) %
图3用可视化的方式显示了本文算法的定位效果,绿色边框显示了算法的定位框,红色框显示了真实定位框。可以看出渐进对抗学习可以定位精确的目标边界,与真实边框重合度较高。然而在数个类上的表现却很难得到提升。例如“bottle”和“plant”两个类的定位精度保持较低的水平。一个主要原因是这些类的大部分被遮挡和重叠,这导致目标定位上的不完整或语义挖掘的不连续,这些导致定位不准确或者只定位到部分,毫无疑问,这些问题导致了更多的进一步改进的空间。

图3 弱监督目标定位效果图
4 结束语
为了解决仅在图像级标签完成目标定位的问题,提出了一种基于渐进对抗学习的弱监督目标定位算法。算法引入自步学习缓解大规模数据的噪声影响,同时提出多标签对抗损失帮助多标签分类网络更好地适应弱监督多目标定位任务,最后为了更好地定位完整目标,提出金字塔对抗擦除机制以定位更准确的目标边界。实验结果表明该算法能有效提高在弱监督目标定位任务上的性能。然而,算法在密集目标的表现仍然较差,下一步将继续研究设计改善密集目标和遮挡目标的弱监督目标定位,通过使用自定锚框,增加细化网络提升密集目标的定位效果。
