面向混合乐器音乐分析的稀疏特征提取方法
2021-07-28徐忠亮郭继峰
岳 琪,徐忠亮,郭继峰
东北林业大学 信息与计算机工程学院,哈尔滨150040
音乐信号是一类典型的音频时变数据,也是一种常见的混合源复杂数据,其组成元素(音符)相对固定,但是组合方式和强度多变,形成了其复杂的时变特征。在音乐的分析和处理过程中,演奏乐器是最关键的要素之一,特别是在室内乐、协奏曲以及交响乐的分析和研究中起到至关重要的作用;然而由于这些音乐体裁多乐器合奏的特性,以及不同乐器强度(音量)的相对变化,真实混合音乐音频经常无法得到用于机器学习的可靠标签,人工合成数据往往与真实数据存在较大差异,乐器识别也很难得到理想的结果。这在很大程度上影响了音乐音频的分析效果,同样的问题也存在于其他混合源数据分析过程中。解决这一问题的关键在于可解释的特征提取方法。传统的音乐音频分析识别方法经常建立在频域分析或物理特征的基础上,如傅里叶变换(FFT)、常数Q 变换(CQT)、梅尔频率倒谱(MFCC)、离散余弦变换(DCT)或小波变换(WT)等;这些特征提取方法能够在一定程度上反映音乐音频信号的频域变化,但音乐的混合乐器组成通常与主要的频域特征没有显著的关联(频域特征的变化主要受到和弦与音高的影响),需要利用多次谐波等特征才能实现乐器的识别;而在混合音乐的应用场景中,由于乐器之间的互相叠加和强度的变化,多次谐波等特征的精确性会受到更大的影响,这使得利用这些方法解析混合乐器组成变得更加困难。
稀疏分解作为一种相对成熟的信号压缩和成分解析的手段[1],一直以来受到学界的广泛关注,并已获得了长足的发展。稀疏分解算法的典型应用涵盖图像、音频等多类信号的压缩存储[2],超分辨率重建和融合[3-4],对统计独立噪声的消除[5],信号分析相关的事件或成分探测[6]以及稀疏表示分类[7-8]等。音乐信号本身由形态相对确定、但强度和组合方式多变的音符单元构成,对其进行稀疏分解的物理意义明确,因此结合稀疏分解方法可以对音乐信号的音乐体裁、调式等进行定量的分析研究,具有广阔的研究和应用前景,如董丽梦等利用稀疏表示分类器对音乐中和弦进行识别[9],Panagakis等将稀疏表示技术与时间调制结合、用于音乐体裁的分类[10],Han 等将稀疏特征用于乐器识别[11],Wu 等利用稀疏特征评价音乐演奏[12],都达成了较好的识别效果;此外,Plumbley 等还用稀疏编码实现了复调音乐的转录[13],Cogliati等也用快速卷积稀疏编码完成了普通和上下文相关钢琴音乐的转录[14-15],等等。以上这些工作涵盖音乐和弦、体裁、乐器分类以及其他调制分析方法,充分说明了稀疏分解在音乐信号解析领域的有效性。
与其他传统分析方法不同,稀疏分解可以被认为是一种基于时域波形、由训练数据驱动的方法,这为包括混合乐器分析和音乐分析可视化在内的音乐分析和处理提供了一种新的视角。已有很多工作证明音乐的稀疏特征与其体裁和情绪存在明显的关联关系[10,16]。本文提出一种基于样本重构向量稀疏性能的特征计算方法(Sparse Performance Index,SPI),探讨在混合乐器演奏的音乐音频中使用SPI 作为特征进行乐器识别和音乐时域分析的方法,针对量化困难的无标注混合音乐音频数据的分析与识别问题,建立多种乐器成分字典、基于这些字典提取SPI 稀疏特征对音乐样本进行实时的混合乐器分析和可视化,并通过实验验证该方案的可行性。
1 稀疏分解基本原理
使用字典D对样本yi进行稀疏分解,有以下通用表示如式(1):

式中,D={d1,d2,…,dM},每个原子dj长度为L;yi=表示第i个样本及其重构系数向量;表示该分解结果的重构误差。包含l0范数的稀疏分解问题已被证明是一个NP 难问题,故在实际应用中通常使用l1范数代替l0范数,此时稀疏分解迭代求解模型可以表示为式(2)、(3):
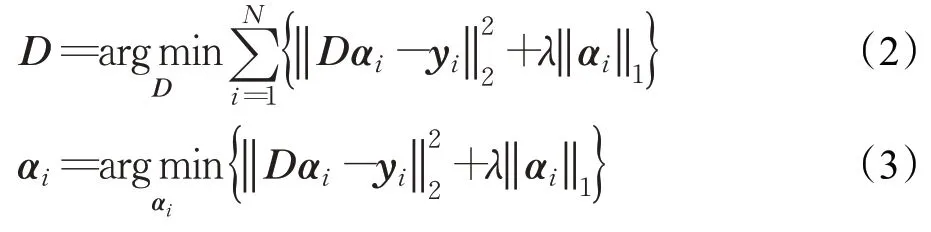
实际计算中通常把l1范数视为约束条件,以把该问题转化为凸优化问题进行求解,如常用的K-SVD 字典学习方法[17-18]和OMP 回归分析方法[19]及其变种都采取这一类方法解决稀疏分解的计算问题。在稀疏分解结果中,稀疏字典可以认为是对样本集内成分的近似拟合,稀疏系数向量则是对这些样本分布情况的表征,可以作为一些分类任务的特征使用;然而,系数向量的分布会在很大程度上受到字典的影响,其语义特性通常不很明确。为了解决普通方法对数据标签的依赖和特征可解释性问题,需要在稀疏系数向量基础上进一步进行特征加工和语义解释,以获得更有效的稀疏特征体系。
2 面向混合乐器成分解析的音乐稀疏分析方法
2.1 基于稀疏分解的混合数据分析理论
本文概述中已经提到,对训练数据的标签的依赖是现在混合数据分析和识别的一个主要限制条件。具体到混合音乐分析领域,深度神经网络(DNN)等方法训练过程中必须首先对训练用混合数据进行标记,这些标签一般由人工标注、工作量大,且通常只包括主要乐器种类标签,对于次要乐器的强度变化没有度量能力,对由几个强度相近成分组成的混合数据也无法保证标签的准确性。考虑一个数据样本y和两个不同的稀疏字典Da、Db,其中Da由与y同质的数据集训练得出,Db则由无关的数据集得出。假设Ci为y中存在的一个独立成分,daj、dbk分别为字典Da、Db中的任意原子,易知有式(4)所示结论:

由此,若样本y使用Da、Db建模所得系数向量分别为Va、Vb,易知E(max(Va))>E(max(Vb));以此类推,y中所有成分与字典Da中的相关度最大值都更高,单一系数期望值更大。由此可知,系数向量能量较集中、稀疏性能较好的稀疏字典与样本匹配性更高,即若能对系数向量能量分布进行精确的度量,则度量结果就被赋予了明确的语义信息——数据样本与特定成分字典的匹配程度。由此,可以在不依赖混合源数据标签的前提下,仅使用有标签的单一成分数据和无标签的混合源数据实现混合源数据识别,以及进一步的语义层面上的数据分析。
2.2 音乐SPI稀疏特征的计算方法
由于音乐信号本身是由确定的少量单音构成,且音乐信号集中的随机噪声强度相对较低,则该数据集必然具备稀疏性,适合使用稀疏分解算法进行分析。提出了一个基于稀疏分解,能够有效度量样本内成分复杂度的稀疏性能指标SPI(Sparse Performance Index),该指标被视为稀疏特征时的计算方式可以被定义如式(5):

式中,M为字典原子个数,αij、αik分别表示系数向量αi的第j、k个系数。当‖αi‖0=1,SPI(αi)=0,取得最小值,表示样本稀疏情况最好;当‖αi‖0=M且对所有j、k都有|αij|=|αik|时,SPI(αi)=1,取得最大值表示样本稀疏情况最差(系数完全均一化)。该特征指标通过计算重构系数两两差值之和,能够直接度量稀疏模型内部的系数能量分布情况,从而对音乐信号的变化产生即时响应,且对字典规模的变化不敏感,可以应用于多种类型的音乐分析。本文将以SPI稀疏特征为基础,介绍一种使用多种乐器的音乐成分字典,提取具有明确语义信息的多维稀疏特征向量的方法。该方法只需要使用相对容易获取的单乐器音频数据,不需要对混合音乐数据进行标注,对人工标注的需求量几乎为零,且容易拓展至其他混合成分数据分析识别领域,具有较高的潜在研究和应用价值。
2.3 稀疏特征向量的建立方法
参数选择是影响稀疏分解算法表现的最主要因素之一,包括分帧长度、字典规模和稀疏度约束(稀疏建模所使用的原子数)三项。对于较常见的44.1 kHz采样率的音乐信号,可以取中央C(261.63 Hz)为基准,保证每帧至少有一个完整波形,通常来说256采样点是一个合适的帧长。字典规模方面,需要覆盖绝大部分单音的波形及相位,同时兼顾字典的过完备性和计算效率,一般来说1 024 或2 048 维字典可以满足大部分独奏或室内乐音频分析的要求。稀疏度约束方面,考虑到一般音乐信号内的多次谐波和噪声情况,独奏和室内乐的最适稀疏度约束一般不超过10,交响曲则在35左右。
确定字典学习参数后,需要针对每一种基础乐器或乐器组合训练字典。所有字典需要使用同一参数训练,特别是稀疏度约束,以保证计算出的SPI值不会受到影响。针对不同的识别需求和数据情况,可以任意选取成分字典和SPI 特征的维数,以弦乐四重奏为例,可以分别训练小提琴、中提琴、大提琴和弦乐四重奏四类字典,每一帧样本分别使用这四类字典建模并计算SPI,也可以引入其中几种乐器合奏的数据训练更多字典、获取更多的SPI时序特征向量以提升识别准确率,也可以仅使用有可靠数据的少数乐器训练字典,这为该方法的应用赋予了较高的灵活性。
稀疏建模和字典学习算法方面,由于稀疏分解算法本身具有一定不确定性,所得的SPI时间序列需要平滑以便观察和分析,平滑窗长决定该分析算法的时间分辨率,窗长越长则算法稳定性越好,但时间分辨率会相应降低。在帧长256 采样点、帧间交叠50%的情况下,400~800 帧是一个合适的范围。由于平滑窗会覆盖一定的时间长度,所以分析结果相对真实的音乐信号变化会产生一个长度固定的时延;窗覆盖400 帧时,该时延约为1.16 s,不会对正常的实时分析产生显著影响。完成上述步骤后,即可得到与不同乐器成分字典一一对应的多个音乐稀疏分析时序特征向量,可以直观地展示乐曲本身的时序特性。
在得到了可靠的乐曲时序稀疏特征后,即可使用任何通用分类器,包括SVM、神经网络等对其进行乐器种类的识别或时域混合情况的分析,特征提取方法的整体流程框图如图1所示。

图1 特征提取方法流程图
3 实验与讨论
实验部分中,首先使用真实的混合乐器短乐段音频验证提出的SPI 稀疏特征识别混合乐器音乐中主要乐器成分的能力,而后在特定的音乐体裁下(弦乐四重奏)给出基于SPI的时域分析图谱并与乐段的信息作比对,验证SPI 稀疏特征反映乐曲乐段差异和乐器组成变化的能力。在实际的分析操作中,选取相对成熟的K-SVD字典学习方法和OMP回归分析方法进行稀疏分解的计算。
3.1 单一乐器的识别分类
在该部分中,使用IRMAS 音乐数据库[20]中的混合乐器音频数据集验证稀疏特征对单一乐器的识别效果。该数据库的训练数据往往以一种乐器为主导,但是同时混合着鼓声、伴奏声等其他乐器或声音信息,且包含各种不同的音乐风格,训练数据段长为3 s,采样率44.1 kHz,符合真实环境下对混合乐器音频识别的需求。
SPI特征的维数选取由识别分析任务需求的标签种类数量和可用的可靠单成分样本数据集数量共同决定,SPI 特征总的特征维数介于二者之间,必须选取分析目标所需标签对应的所有种类单成分样本数据,也可以选择其他类型数据集作为参考。受到公开数据集内容的限制,舍去了一些不常见乐器和缺乏单乐器训练数据的数据集(如电吉他和人声等),但在实际应用中单成分数据集相对容易采集,故不会影响本文方法的应用表现。最终选取的识别对象包括:大提琴、黑管、长笛、钢琴、萨克斯、小号和小提琴七种乐器,对每种乐器分别计算片段的平均SPI 值得到7 维特征向量,所有识别率都为五折交叉验证的平均结果。
为了直观展示特征提取方法的性能,首先选择SVM作为分类器,将SPI特征与使用广泛的传统MFCC特征,文献[21]使用的大规模(2 023 维)融合特征,matlab Timbre工具箱特征[22],以及SPI、MFCC的融合特征做出比较。不同乐器及整体加权平均识别准确率如表1。

表1 每种乐器与其他乐器的区分准确率 %
可以看到,不同乐器间的识别准确率有所差异,这是由乐器相似度和数据集的不同乐器标注质量差异所导致的,如该数据集中萨克斯片段以合奏为主,大提琴片段以协奏曲为主,故识别率相对较低,而小号乐段以独奏为主,且与其他乐器差异较大,故识别率相对较高。作为对比,单纯MFCC及其改进型对单一乐器音频单音的识别准确率约为95.32%和96.28%[23],由此可见提出的特征提取方法在复杂得多的IRMAS混合乐器短乐段数据集上已经达到了与之接近的效果。另外还使用了普通神经网络分类器对同样的数据集进行分类识别,结果如表2所示。

表2 不同特征的ANN七分类识别准确率
作为对比,在该数据集上使用2 023 维时频域融合特征的识别准确率约为68.3%,63维Timbre音色工具箱特征的7分类识别准确率约为67.2%。考虑到以上两种都为维数较高的融合特征,提出的SPI+MFCC的融合特征识别性能依然有明显的优势,验证了实验结果的可信度。
从两组实验结果中可以看到,SPI 特征在不同分类器上的识别能力都稍优于传统MFCC特征,而二者的融合特征则显著优于传统MFCC 特征的识别表现。这是因为SPI是一种包含语义信息的特征,而MFCC是一种对数据物理特性进行度量的特征,二者融合无疑可以达成更好的识别结果。同时,考虑到训练数据的复杂程度以及使用的特征维数非常少(7维),可以认为稀疏特征作为一种乐器区分特征是有效、可靠的,既可独立使用,也可以与其他特征共同使用以达成更好的识别效果。
3.2 混合音乐音频数据的无监督分析
在这一部分,为了有效地验证提出的方法对无标签混合乐器数据分析的效果,选取F.X.里赫特的F大调弦乐四重奏作为实验对象,样本数据由敖德萨四重奏乐团演奏。考虑到混合音乐数据几乎无法获取可靠的标签(特别是在乐器强度相近的合奏乐段),故不以识别率作为评价手段,而是直接展示SPI稀疏特征的时域变化图谱,通过对SPI特征图谱的分析,以直观的方式证明SPI稀疏特征反映混合音乐乐器组成变化的能力。该类别实验需要建立小提琴、中提琴三类稀疏成分字典,选取与其作曲年代和演奏方式相近,同时较具权威性的巴赫小提琴、大提琴无伴奏奏鸣曲和提勒曼的12 首中提琴无伴奏幻想曲作为训练样本集,演奏者分别为Nathan Milstein、Petr Přibyl和Maurice Gendron。
为了有效地进行对比,首先展示了上述三种独奏乐曲的SPI时域分析图谱。作为参考,也使用了无标注的弦乐四重奏数据训练字典,在图谱中绘制对应的曲线。SPI 曲线的平滑窗长400 帧,相当于1.16 s,每种乐器数据随机选择一首作为测试样本,其余作为训练样本建立256×2 048 的乐器成分字典,重构单帧样本最多使用10个不同的字典原子,绘制四种SPI 时域特征曲线、构成SPI 时域特征图谱。进行了大量实验,篇幅所限只展示其中部分结果,一些单乐器音频的时序分析实验结果如图2所示。
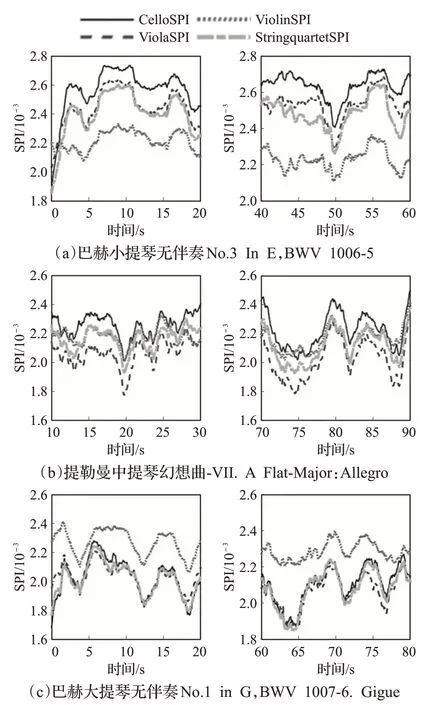
图2 单乐器音频SPI图谱实验结果
其他所有实验趋势均与所示结果基本一致。可以看到,在所有单乐器数据的SPI图谱中,几条SPI曲线的相对位置在所有乐段都保持稳定,在小提琴和中提琴实验中,对应乐器的曲线几乎始终比其他乐器曲线更低,而在大提琴实验中,大提琴曲线只是稍低于中提琴及四重奏分析曲线。这是因为大提琴音色相对浑厚,因此其复杂度也会相对较高,这一点也可由其他乐器实验中大提琴对应曲线的高位置得到验证。三种乐器独奏时的SPI 特征分布都具有明显特点:小提琴独奏时小提琴曲线处于最低位置,其他曲线分布较分散;中提琴独奏时中提琴曲线处于最低位置,所有曲线分布都比较集中;大提琴独奏时大提琴曲线位置较低,而小提琴曲线处于最高位置。由此,不同乐器的SPI特征分布目视即可见典型差异,从而可以进行直观的识别和分析,从而使特征体系具备了极高的可解释性,这一点是其他特征体系不具备的。
接下来,展示弦乐四重奏的实验结果。乐段选取自F.X.里赫特F大调弦乐四重奏Op.26:II.Presto,部分乐段分析结果如图3所示。

图3 弦乐四重奏SPI图谱实验结果
在四重奏实验中,几类乐器的SPI曲线出现了依段落的交替起伏;由于大部分时间是多种乐器合奏,故很多时段SPI曲线差异不如独奏乐段明显,但每个乐器曲线处于最低位置、与该乐器独奏时曲线分布特征相似的时段在时间轴上与演奏过程中对应乐器声音占主导地位的时段完全吻合,如5~20 s的大提琴主导乐段,35~48 s的小提琴乐段,和210~215 s 的中提琴主导乐段等。除了一些乐器独奏段落外,整个乐曲中四重奏曲线在绝大部分时间处于最低的位置,反映了该曲目的体裁。
以上的实验结果可以表明SPI 特征指标体系的诸多有意义的特性。首先,它可以在仅使用单一成分数据和无标签数据作为训练数据的基础上,直接对无标注的混合成分音乐数据进行有效的分析,从图谱的分布形态(或比较SPI 值的大小)就可以得到准确度很高的识别结果。其次,它对相对较弱、不占主要地位的成分的强度变化也有较强的表征能力,对于分析和研究这些次要成分有重要的意义和价值。最后,SPI 图谱的共性变化与音乐本身的时域情感、内容存在着明显的关联,而这些现象也是下一步重要的研究对象之一。
4 结束语
本文介绍了一种基于多乐器字典稀疏分解的音乐信号时域分析方法,通过建立多种不同乐器的成分字典,以及使用SPI 指标对其进行时域复杂度度量、提取稀疏特征,可以有效区分混合乐器的组合情况,同时也能够直观地反映音乐本身的情感和内容变化,对音乐的定量分析具有明确的意义和价值。需要强调的是,该方法的应用并不仅限于音乐领域,所有能够获取明确的成分数据集的声音信号,乃至于其他各类数据信号都可以使用该方法进行数据成分字典的训练和基于稀疏复杂度评价的成分时序变化分析,这使得本文所述方法在诸如野外生物的声音捕捉和识别、机械故障杂音的捕捉和预警、生物电信号异常波动的捕捉等多个方面具备直观和潜在的研究和应用前景。在后续工作中,可以对协奏曲、交响曲及包含人声的演唱等更复杂的音乐形式进行分析和探索,同时对不同乐器的固有复杂度特性进行研究,并在其他可能的应用领域拓展该方法的应用方式和适用范围,以服务于更广泛的音乐和其他各类时变信号的分析需要。
