实现网络视频流多分类的迁移学习算法
2021-07-28董育宁
王 彦,董育宁,葛 军
1.南京邮电大学 通信与信息工程学院,南京210003
2.南京邮电大学 现代邮政学院,南京210003
根据思科视觉网络指数(2020)[1]的最新预测,从2017 年到2022 年,全球互联网视频流量将翻两番,到2022 年将占所有互联网流量的82%以上。不同类型的视频应用程序对服务质量(Quality of Service,QoS)的要求也不同。视频业务的识别和分类是实现相关网络行为以进一步提高视频服务端到端QoS 的前提。互联网服务提供商(Internet Service Provider,ISP)为了合理地将相应的网络资源分配给不同的视频应用程序,需要对视频服务进行精细的分类,而不仅仅是将视频业务视为一个单独的类别。
近年来,机器学习(Machine Learning,ML)方法已经成功地用于识别网络视频流量。但是传统的ML 不能解决以下两个问题:首先,由于网络视频服务技术的不断更新,许多以前收集的视频流数据集很容易过时,再重新收集和标记新的实例需要花费大量人力成本。其次,每次更新数据集时,都需要重新训练新模型,该过程非常复杂且耗时。因此,本文提出一种迁移学习(Transfer Learning,TL)框架来解决上述问题。该方法可以在仅拥有比较少的新收集的有标签数据和大量过时的训练数据集的情况下来实现视频流多分类。
在基于ML的分类方法中,特征选择(Feature Selection,FS)是重要的一步。它通常被视为数据预处理操作,可以减少后续分类算法的计算时间,改善预测性能。
本文的主要创新点如下:
(1)借鉴MultiSURF[2]与遗传算法(Genetic Algorithm,GA)[3],提出一种混合式的FS算法——MSGA。该算法结合了过滤式与包裹式FS 方法的优点,在实现特征尺寸快速降维的同时还可以降低特征子集的冗余度,能帮助后续分类器提高分类准确率。
(2)借鉴SAMME 算法[4],将TrAdaBoost 算法[5]从只可识别两类扩展到可识别多类,从而提出了MultiTrAda-Boost算法,实现对视频流数据的精细分类;该算法可以较好地利用过去的数据,从中筛选出有用的样本迁移至分类目标域,在节省大量收集和标记新数据的成本的同时也提高了分类的准确率。
1 相关工作
1.1 特征选择方法
Ferriyan 和Thamrin 等[6]提出了一种用于入侵检测系统的基于遗传算法的的优化FS 方法,该方法采用单点交叉的方式来选择GA的参数,并结合随机森林算法在分类率和训练时间方面取得了较好的结果。刘成锴等[7]提出了一种将过滤式算法TF-IDF(Term Frequency-Inverse Document Frequency)与封装式GA相结合的文本FS算法,该方法有效降低了高维的文本特征,并具有良好的分类效果。姚树春等[8]针对高维小样本数据FS冗余度高和过拟合的问题,提出一种基于混合GA与互信息分析的高维小样本FS 算法,该算法有效地增强了GA的稳定性和鲁棒性,并且实现了较好的FS效果。
1.2 网络视频流分类方法
Canovas等[9]根据模式对多媒体流量进行分类,这些模式允许使用视频流和网络特征作为输入参数来区分流量类型。吴争等[10]针对不同类别网络流分布不平衡的问题,设计了一种能够实现低存储、低时延、高准确率的网络视频流细分类算法,并在真实数据集中取得了较高的识别率。杨凌云等[11]使用较小的数据来代替长视频流进行分类,减少了数据处理时间的同时也提高了分类精度。
1.3 迁移学习分类方法
Zhang 等[12]提出了一种新的TL 框架JGSA,该框架可减少两个域之间在统计和几何上的偏移,从而更好地实现跨域迁移,提高识别准确率。Han等[13]提出了一种两阶段分类技术,该技术结合了TL 和Web 数据扩充方法,有效地减少了对训练集样本数量的要求并避免了过拟合问题。刘三民等[14]结合TL 方法,利用大量的历史标注样本来辅助当前新概念的模型学习,解决了代表新概念标注样本数量不足的问题。
2 本文方法
2.1 基础理论
2.1.1 MultiSURF模型
MultiSURF 是一种过滤式FS 方法,它根据每个属性和类别的相关性为每个属性分配不同的权重。特征权重向量W[A] 的更新如下所示:

其中,diff是一个距离函数,用于计算样本S1和样本S2之间的属性A的值的区别(其中S1=Ri和S2=最近的命中(H)或最近的未命中(M)),b是训练样本的总数,h和m分别为最近的命中次数和最近的未命中的个数。然后,该算法会依据各个特征的权重值大小进行排序,进而选择特征子集。
2.1.2 TrAdaBoost算法
TrAdaBoost 是一个TL 算法,可通过提升基础学习器从而将有用的知识从一个分布域迁移到另一个分布域。该算法的输出如下:

其中,γt为εt/(1-εt),εt是基础学习器的分类错误率,N为最大迭代次数。从中可以看出它只可以处理两分类(0或者1)问题。
2.1.3 SAMME算法
SAMME 是一种自然地将AdaBoost[15]算法扩展到可实现多分类而不是将其转化成进行多次二分类情况的算法。它通过优化一个多类指数损失函数,来获得样本c属于类k的概率,即:

2.1.4 JGSA算法
JGSA(Joint Geometrical and Statistical Alignment)是一个可以同时减少源和目标域之间的分布和几何差异的迁移学习框架,具体来说,通过学习两个耦合投影(A代表源域,B代表目标域)来获得各自域的新表示。映射完成之后,可以达到(1)目标域数据的方差最大化;(2)保留源域数据的判别信息;(3)源域和目标域之间的分布散度最小化;(4)源域和目标域的子空间散度最小化。该算法的整体目标函数为:

其中,St、Sw、Sb分别是目标域散度矩阵、类内散布矩阵和类间散度矩阵,λ、β、μ是重要的权衡参数。最终,该算法通过不断优化目标函数来减小域位移。
2.2 混合式特征选择算法
本节提出一种新的基于MultiSURF 和GA 的混合FS方法MSGA,如图1所示。

图1 MSGA算法流程图
使用MSGA算法选择特征子集的计算过程如下:
步骤1 首先MultiSURF算法依据公式(1)计算出每个属性的权重值,并将其按从大到小的顺序进行排序,去掉部分与类别关联较弱的属性,最后按照顺序选择前a个属性。
步骤2 基于上一步选出的a个属性随机初始化原始种群。
步骤3 计算每个个体的适应度函数值,本实验中的适应度值为CART算法的分类准确率。
步骤4 算法遵循基本的GA 操作,对个体进行选择、变异、交叉。
步骤5 将新生成的所有解加到种群中,形成新的种群。
步骤6 如果适应度值不再变化,或者算法达到最大迭代次数,则此时的输出的结果为最佳个体,否则重复步骤3至5,直到满足终止条件。
在进行分类实验之前,使用MSGA特征选择算法从原始的25个特征[10]中筛选出8个特征,具体如表1所示。

表1 分类实验数据集的8个特征
2.3 分类算法框架
本文提出的MultiTrAdaBoost算法继承了TrAdaBoost的迁移思想,并结合SAMME 来实现多类识别。算法1给出了MultiTrAdaBoost 的详细计算步骤。首先,分别初始化两个有标签训练集Ta和Tb的权重向量W1(n是旧数据集Ta的大小,m是新数据集Tb的大小)。β用于更新Ta中样本的权重,被设置为,即它的大小由n和迭代次数N决定。然后算法进入迭代过程,在每次迭代开始时首先归一化pt,它是所有训练集T(Ta∪Tb)样本的权重分布。本实验中选择CART算法作为基础学习器,所有用于训练基础学习器的样本都遵循pt的分布,然后学习器将得到一个假设函数ht:X→Y,并将其保存起来,以便最终可以通过加性模型进行组合以形成一个强分类器。之后计算数据集Tb上的错误率εt并根据它更新βt。如果Ta中的样本分类错误,其权重将乘以,以减少其对下一轮迭代中的学习器的影响。如果Tb中的样本分类错误,其权重将乘以增加权重值,这将使下一个分类器更加关注此样本。经过几次迭代后,通过不断从Ta中选择辅助数据来帮助分类,基础学习器的错误率将逐渐变小。最后,所有保存的基础学习器将与各自的权重ln(1 /βt)集成在一起,以生成最终的强分类器。在本算法中,最终输出的假设函数是:

其中,N是迭代的次数,ht是基础学习器的假设函数,βt=γt/(K-1) 。I是一个指示函数,它代表如果ht(x)=k则它的值为1,否则为0。
算法1 MultiTrAdaBoost
输入:两个有标签训练集Ta和Tb,无标签测试集S,类别数目K,基础学习器和最大迭代次数N。


3 实验结果及分析
3.1 数据集
实验中共使用两个数据集,一个是包含780个样本的老数据集,于2013 年在南京邮电大学(Nanjing University of Posts and Telecommunications,NJUPT)收集。另一个新数据集包含438个样本,是2019年在伦敦玛丽皇后大学(Queen Mary University of London,QMUL)收集的。这两个数据集的每个样本都具有相同的25个特征和各自的类别标签。数据集总共包含6种类别,即在线标清视频(SD,480p),在线高清视频(HD,720p),在线超清视频(CD,1 080p),交互式视频通信(IVC),P2P视频(P2P)和网络实时视频(ILV)。
由于NJUPT 数据集为六年前收集的,所以在某种程度上已经过时了。因此,可以将其视为过时的数据集Ta。QMUL数据集分为两部分:带标签的新数据集(Tb)和无标签的测试集(S),这两部分服从相同的分布。为了进行更加详细的比较,本文从QMUL 数据集中分别提取了20%、40%和60%的数据作为Tb,其余为测试集S。
3.2 实验设置
将MSGA 与MultiSURF 和基于GA 的包裹式两种FS算法进行对比,后端分类算法都是MultiTrAdaBoost。
为了验证MultiTrAdaBoost 算法的性能,本文选择了(1)Cart_a,它利用旧数据集Ta作为训练集;(2)Cart_ab,它将老数据集Ta和新数据集Tb组合起来形成训练集,这两种方法均使用CART 算法训练分类器;(3)JGSA[13]TL 算法进行性能比较。在MultiTrAdaBoost 中,CART算法被用作基础学习器。
使用总体准确率、查准率、查全率和F1-measure 来测试算法性能,分别定义如下:

3.3 实验结果
分别使用MultiSURF、基于GA 的包裹式和MSGA三种FS 算法选出了8、10 和8 个特征,最后的分类总体准确率如表2所示。

表2 三种FS算法在测试集上的总体准确率
可以看出,使用MSGA的分类结果要高于其他两种方法,这说明MSGA所选择的特征对于分类来说更加有效。MultiSURF 算法选择的特征子集大小与MSGA 相同,但子集内容不一样,由于其是过滤式FS 方法,所以无法避免特征子集冗余问题,分类精度均低于0.9。相较于MSGA,基于GA 的FS 方法选择了更多的特征,但是分类精度仍然普遍低于MSGA,这意味着包裹式FS方法并不能很好地去除无关特征。
表3 显示了本文提出的TL 算法与两种传统ML 方法分类的总体准确率。可以发现,本文算法的整体准确率明显高于其他两种基于传统ML的方法。
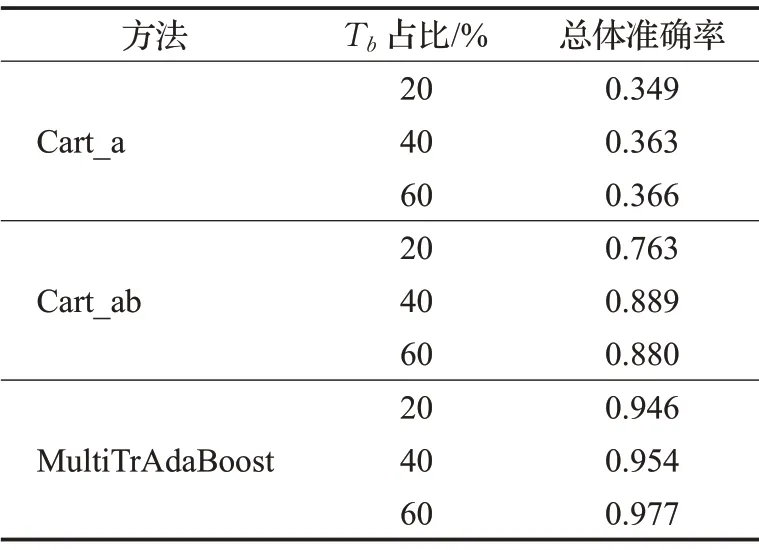
表3 三种分类方法的总体准确率
Cart_a的总体准确率均低于37%,这表明了新数据集和老数据集之间的分布是不相同的,通过训练老数据集得到的模型无法识别新的数据集。在Cart_ab 算法中,即使引入新数据集Tb作为训练集,由于有大量和新数据集分布不同的过时实例Ta的干扰,该算法不能很好地训练模型,分类准确率均低于89%。而本文算法可以克服新老数据集分布不同的问题,通过从老数据集中筛选出有用的样本来帮助分类进而提高分类准确率,其总体准确率达到了94%以上,并且还可以减少大量老数据集的浪费。
表4给出了JGSA与本文方法对六种不同类型的网络视频流分类的结果,可以看出,本文方法明显优于JGSA方法。JGSA不能很好地区分SD、HD和ILV三类,这是由于原始数据中这三个类别特征分布比较相似,当通过JGSA 算法映射到更低维度的子空间之后,三个类别的新老数据的子空间无法很好地区别开,仍存在较大的域位移。另外,在总体准确率方面,本文方法的分类精确度高于94%,而JGSA方法的总体正确率仅为67%。因为本文方法是通过迭代训练弱分类器来从源域中直接筛选出与目标域相似的数据,相较于JGSA,更为简单有效。
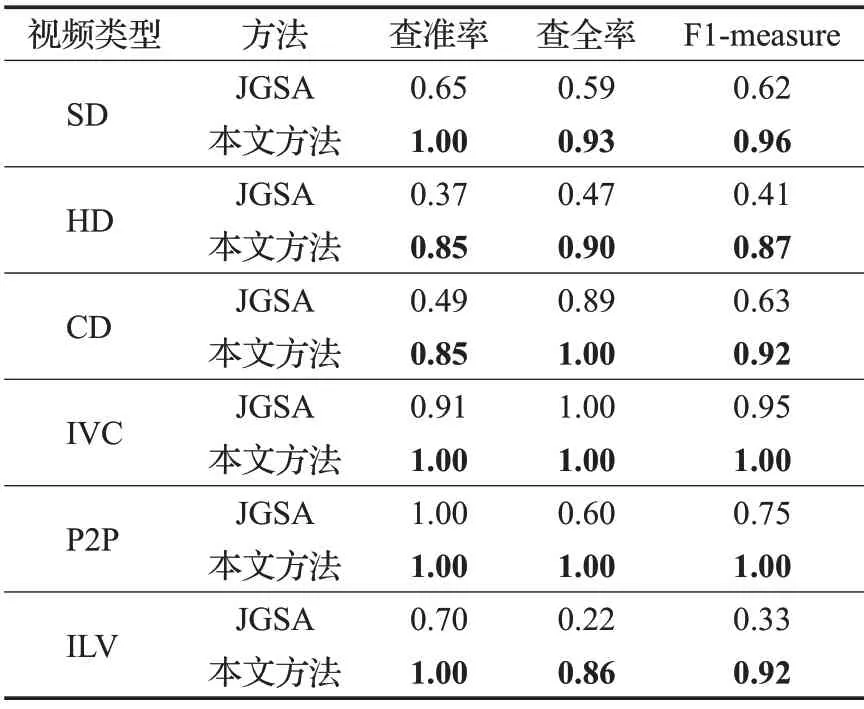
表4 JGSA和本文方法对6种网络视频流分类结果对比
4 结束语
本文提出了一种基于TL的新型网络视频流量分类算法MultiTrAdaBoost,该算法将TrAdaBoost与SAMME算法结合起来,可以实现多类别的分类。实验结果表明,在训练集和测试集处于不同分布的情况下,本文方法可以在整体准确率上获得更好的性能。另外,为了提高分类准确率,本文还提出了一种混合式的FS 方法MSGA,可以在选择特征子集的过程中快速降维并减小子集的冗余度。尽管如此,仍有一些需要进一步探索的问题,而下一步的工作是研究如何在具有不同特征空间或不同类标签的领域之间迁移知识。
