Histogram-XGBoost的Tor匿名流量识别
2021-07-28王腾飞蔡满春芦天亮
王腾飞,蔡满春,岳 婷,芦天亮
中国人民公安大学 警务信息工程与网络安全学院,北京100076
Tor网络作为目前覆盖范围最大、活跃节点最多、服务类型最完善的匿名通信系统,在保护网络用户隐私的同时也成为了违法犯罪份子隐匿的空间。对Tor匿名流量的识别是实现网络监管与审查的基础,有着重要的研究意义和价值。
Tor 匿名流量本质上是一种经过加密混淆的流量,对其进行识别的本质是对加密混淆流量的分类,在该领域,传统的机器学习方法目前已经取得了一定的研究成果,但也存在着模型泛化能力差、健壮性不足、复杂度高等方面的缺陷。本文在分析总结已有加密流量分类技术、Tor匿名流量识别分类技术的基础上,结合Tor网络协议的特性,提出了一种基于Histogram[1]的Tor 匿名流量特征描述方法,在增加了时间维度相关特征的基础上,通过Histogram对相关特征进一步离散化处理,获得更加丰富的特征描述信息,提高特征的鲁棒性;针对Tor匿名流量连续、非线性的特点,将XGBoost 集成学习的思想应用到Tor匿名流量识别中,该方法可以很好地处理Tor匿名流量中包长、时间间隔、流持续时间等非线性的统计特征。围绕基于XGBoost的Tor匿名流量识别技术,本文的主要贡献如下:
(1)提出了一种Tor 匿名流量特征描述方法,针对Tor 匿名流量,在数据流粒度下对时间相关的流量特征进行描述,通过Histogram 对相关的特征进行离散化处理,提高特征在不同网络环境下的鲁棒性。
(2)基于XGboost,提出了一种新的Tor匿名流量识别方法,结合集成学习,将特征提取与模型训练过程结合起来,在较小的特征维度下实现对Tor匿名网络流量数据流粒度的识别。较小的特征维度可以使模型更加简单,该检测模型也不依赖于任何有关协议和拓扑的先验知识。
1 相关工作
对加密流量的识别技术伴随着流量加密混淆技术而出现。最初,Tor 目录服务器与OR 中继节点的IP 地址均是公开的,可以直接根据IP地址识别阻断Tor匿名通信流量,但随着Bridge、Meek 等混淆技术的出现,基于IP地址过滤的方法不再有效。目前针对混淆流量的识别技术根据实现原理可以分为两大类:基于DPI(深度包检测)的识别技术和基于机器学习的流量识别技术[2],国内外主要研究现状如下:
深度包检测技术已经应用于一些国家层面的网络审查[3],但检测技术主要是基于静态指纹特征。文献[4]针对FTE混淆流量提出了一种基于熵的识别方法,将混淆流量中第一个HTTP 报文中GET 字段的URI 信息熵与正常流量进行比较,能够获得较高的识别率,但是FTE 混淆插件可以通过自定义正则表达式将流量伪装成其他协议类型的流量,致使基于URI熵的识别方法适用性不高。文献[5]发现Tor 程序中密码套件与数字证书具有一致性,提出了一种基于TLS指纹的Tor流量在线识别方法,能够在Tor协议不更换密码套件与证书序列号的情况下,达到100%的识别率,但当Tor 程序改变了其密码套件或数字证书特征时,该方法需同步做出相应的修改。文献[6]分析总结出Meek插件7个稳定的流特征,提出了通过其中静态指纹特征对Meek 流量进行识别的两种方法,但该方法中较为关键的“轮询请求特征”易受到网络环境的影响,健壮性和矫正能力较差。
基于机器学习的分类方法在加密流量识别中取得了广泛的应用,但基于机器学习的流量识别与分类过于依赖特征的设计与选择,特征的稳定性会极大地影响模型的效果。文献[7]在电路级和数据流级分别选取信元数、上行流量信元总数、下行信元与上行信元比等特征从电路级和数据流级两个维度上实现Tor流量的分类,但在开放环境中模型识别效率不佳。文献[8]通过提取源端口、目的端口、总报文数等35 种特征,将每一条流视为一个粒子并定义粒子间操作,用重力聚类算法解决Tor 流量分类问题,测试效果优于DBSCAN、K-means等聚类算法,但选取的特征的稳定性会受到混淆插件的干扰。文献[9]提出了一种基于两级过滤的Obfs4 流量检测方法,依次利用粗粒度的快速过滤和细粒度的准确识别来实现Obfs4流量的高精度实时识别,但该方法对流量数据集要求较高,在Tor流量稀疏的环境中,适用性较差。机器学习方法对特征的健壮性要求较高,随着Tor 混淆插件的更新,明文字段及部分统计字段的特征开始不再有效,模型识别率会大幅度降低。
深度学习方法能够避免传统机器学习提取流特征的过程,在Tor 匿名流量识别中也取得了一定的进展。文献[10]将原始分组序列作为输入,用CNN深度神经网络对Tor、网页、语音、视频等17 类流量进行分类,达到95%的精确率。但模型依赖的特征数多,训练开销较大。文献[11]提出了一种基于深度神经网络的方法来检测异常流量,该方法不依赖于具体的数据载荷,通过基于流的入侵检测模型实现异常流量的识别,但模型更新迭代时间长,实用性不强。虽然深度学习方法实验中取得了良好效果,但数据集需求量大、扩展性差,真实环境中效果有待验证。
已有的研究大都建立在网络环境稳定、数据集分布平衡的假设之上,且机器学习方法存在特征健壮性不强、易失效的问题;深度学习的方法尽管实现了特征的自动提取,但往往需要庞大的特征维度才能够保证模型的准确率,训练成本高且模型更迭效率低。从实践角度出发,网络环境的波动、Tor流量数据的稀疏都是不可忽略的现实因素,好的分类模型除了拥有可靠稳定的特征设计外,还应当能够在一定程度上适应网络环境的变化并且能够对较少样本数的类别拥有较好的识别率。因此,本文提出了一种鲁棒性强、特征维度小的Tor匿名流量识别模型,论文在数据集ISCXTor2016[12]上进行了相关验证实验。
2 基于Histogram-XGboost 的Tor 匿名流量识别方法
本文提出的Tor匿名流量识别模型的核心思想是在计算获取数据流粒度时间相关性特征的基础上,对特征进行离散化预处理,利用XGboost对预处理后的特征进行训练,从而完成对Tor匿名流量的识别。整体架构如图1所示,主要包括流量采集、特征获取、数据预处理以及识别分类四个模块,分别实现原始流量样本的收集、数据流粒度上时间相关性特征的计算与预处理、模型训练与分类三大功能。

图1 Tor匿名流量识别模型架构
2.1 流量采集
Tor 作为目前使用最广泛的匿名通信系统之一,使用多跳代理机制对用户通信隐私进行保护,客户端会基于加权随机的路由选择算法分别选择3个中继节点,根据洋葱路由的原理,只有在入口节点前识别出Tor匿名流量才能有效发现Tor 匿名网络用户[13]。因此,如图2所示,采集Tor匿名流量的位置一般为网关节点,在Tor用户与洋葱入口节点之间的网关处,通过网络嗅探获取流量信息。

图2 Tor匿名流量采集
2.2 特征获取
通过dump 等方式捕获的流量数据为pacp 类型文件,由多个数据分组构成,本文提出的分类模型使用的特征主要是数据流粒度上的时间相关性特征,特征获取的步骤如下。
2.2.1 数据流的生成
数据流是由一系列数据包构成的,这些数据包具有相同的{源IP,目标IP,源端口,目标端口和协议(TCP或UDP)}。在Tor 匿名流量中,所有的流均为TCP 协议流。数据流具有方向,由第一个数据报决定数据流的方向是向外或者向内。
2.2.2 特征的生成
已有的研究工作中,研究人员使用Netmate、pcap2flow、Tranalyzer[14]等工具进行流量分析处理,但这些工具多数是基于数据报字段进行计算,对强加密的Tor匿名流量并没有很好的效果,本文通过CICflowMeter[15]对pcap流量文件进行处理,来计算基于数据流的流量特征。
CICFlowMeter 是一种用Java 编写的网络流量流生成器,在选择计算、功能扩展以及控制流持续时间等方面提供了很好的灵活性。CICFlowMeter能够生成双向流,其中第一个数据包确定前向(源到目的地)和后向(目的地到源)方向,分别在正向和反向上计算如持续时间、数据包数量、字节数、数据包长度等83 种流量统计特征。特征选择方法在各种分类任务中起着关键作用,通过从数据集中显示的更多特征中选择较小的子集,它有助于提高机器学习算法的效率和准确性。
在针对Tor 匿名流量的识别中,文献[1]和文献[12]等研究表明,目前提出的大多数监管规避方法主要混淆了包的长度、包数量等方面的特征,而流的突发性以及其时间相关性特征在这个过程中无法被混淆。因此时间相关性特征可以较好地区分不同类别的流量,本文通过CfsSubsetEval 评估器[16]对CIC Flow 产生的83 种流量特征进行评估,最终选择了12个特征作为XGboost模型的输入。Cfs SubsetEval通过考虑每个特征的个体预测能力以及它们之间的冗余程度,来评估属性子集的价值,与子类相关性高但互相关性低的要素子集能获得更高的评分。表1 给出了对应的特征集合(|O|=12)和对应的特征重要性,它们具有Tor流量检测的最大信息增益和卡方统计量。

表1 时间相关性特征
如表1 所示,本文使用的时间特性中除流持续时间、单位时间的流字节数以外,还包含前向、后向的流间隔时间以及数据包的大小数量等相关统计量,相比于文献[17]提出的Tor 单元计算的方法,保持了流量原始的特征统计信息,具有更好的特征质量。
2.3 基于Histogram的数据特征预处理
为了提升特征鲁棒性,在训练前对特征进行类离散化处理。如图3所示,本文通过为每个特征生成一个全局分布,然后使用这些全局分布来填充每个实例的最终特征集,从而获得比简单统计更详细的特征信息。

图3 特征预处理的步骤
特征的预处理的主要步骤如下:
(1)计算每个时间特征的全局分布。将每个时间相关的特征进行排序形成有序数组,这个数组代表其各自功能的全局分布。对于每个特征的全局分布,将数据划分为b个区间,使每个区间拥有相同数量的元素。每个格子的最小值与最大值构成该格子的范围。
(2)对于每一个特征,创建其全局分布直方图,每个格子的区间由全局分布直方图的区间范围给出,在为每个实例生成最终特征集时,将使用直方图区间代替原有的数值型特征,落在每个格子的特征值的个数作为新的特征值,对新的特征进行标准化处理。
一般使用透射照明观察较为透明的标本,如吸虫幼虫发育各期、吸虫成虫、绦虫节片等染色玻片标本或尾蚴、毛蚴等活体标本。这时光从下往上透过样品,能够提供明亮有效的照明。而使用落射照明观察半透明或不透明的标本,如昆虫若虫、成虫等标本,这时光从上往下透过样品,通过任意调节照明的角度观察标本的立体结构。
更多的分布区间b能提供更加细粒度分类,但可能会降低特征的鲁棒性。使用更少的区间可以增强特征的鲁棒性,但会降低分类的精度。在ISCXTor2016数据集上,本文进行了参数b最佳取值的探索,最终在b=8时,取得了实验3.3.1节的最佳分类结果。
2.4 基于XGBoost的分类识别
Boosting 技术在解决少样本数据分类方面表现优异。XGBoost分类器是Boosting算法的一种扩展,由学习模型、参数调节和最优化目标函数组成。损失函数中加入了叶子节点权重和单决策树复杂度等正则项,可以防止决策树模型过于复杂,在训练速度上较其他算法有着较大的提升[18]。
对于XGBoost来说,设定合适的树的深度与目标函数非常重要,它们决定着模型的复杂程度。XGBoost的目标函数定义如公式(1)所示:

目标函数由两部分组成:损失函数L(θ)和正则化惩罚项Ω(θ)。其中,L(θ)是微分凸损失函数,用于测量预测yi与目标yi之间的差异。Ω(θ)是惩罚复杂模型的正则项。其中,T是树上的叶子数,γ是学习率,其值在0到1之间。γ乘以T等于生成树修剪,以防止过度拟合。
在公式(1)中由于存在以函数为参数的模型惩罚项,传统方法无法进行优化。因此,需要通过公式(2)来计算目标yi。

优化目标是构建一个树结构,以最小化每次迭代中的目标函数。树结构从前一棵树的结论和残差(残差=实际值-预测值)中学习,从而拟合出当前的残差回归树。St(Ti)表示实例i在第t轮迭代中生成的树。
由于方程的目标函数(2)在求解平方损失函数的过程中是最优的,对于求解其他损失函数来说则变得非常复杂。因此,通过二阶泰勒展开得到公式(3),从而求解其他损失函数。其中最终目标函数取决于误差函数中每个数据点的一阶和二阶导数,这也加快了其优化速度。

模型在数据流粒度上设计了时间相关性特征以解决填充混淆带来的字段特征失效问题,通过基于Histogram的预处理方法进一步提高特征的鲁棒性以适应网络环境的变化,最后使用XGBoost 分类器来解决Tor 流量样本分布不均衡的问题,实现了较小维度特征的Tor匿名流量的快速识别。
3 实验评估
为了验证Histogram-XGBoost 模型的可行性、分类效果以及模型的稳定性,本文基于sklearn接口[20]实现了模型代码并进行了验证实验,实验环境参数如表2所示。

表2 实验环境相关参数
3.1 数据集
实验使用的数据集由Tor 匿名网络流量、正常流量两个部分组成,其中Tor 匿名流量包括来自ISCX Tor 2016的Tor匿名流量以及实验室环境下采集的Tor浏览器流量。
ISCX Tor 2016 是取自加拿大网络安全研究所网站的开源数据集,由TCPdump捕获,共22 GB,包括一个Tor 匿名流量文件以及一个正常流量文件,数据集构成如表3所示。
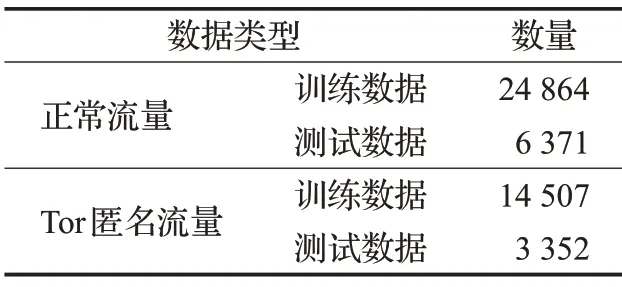
表3 ISCX Tor数据集情况
Tor浏览器流量则为实验室环境下通过Tor Browser Crawler[21]采集的访问不同应用类型网站产生的Tor匿名流量,流量采集分别在低速(下行20 Mbit/s/上行12 Mbit/s)、正常(下行50 Mbit/s/上行30 Mbit/s)、高速(下行80 Mbit/s/上行50 Mbit/s)三种网络链路状态下进行,同时也采集了3 种网络链路状态下的正常的网络流量。数据集构成如表4所示。
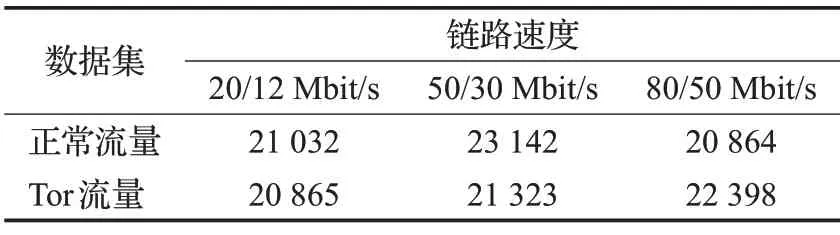
表4 Tor浏览器流量数据集情况
3.2 评估指标
实验结果的评价指标主要包括:分类的准确率(ACC),包括两种类型流量的准确率、召回率以及所有类别的整体的准确率。具体而言:
类的准确率ACCi=TPi/(TPi+FPi)
类的召回率Ti=TPi/(TPi+FNi)
整体准确率ACC=TP+TN/(TP+TN+FP+FN)
其中,TP是将正类预测为正类的数量,TN是将负类预测为负类的数量,FP是将负类预测为正类的数量,FN是将正类预测为负类的数量。
3.3 实验分析
本文共设置2组实验:(1)识别Tor匿名流量的二分类实验,主要用于验证本文提出的识别模型的有效性,并将实验结果同使用SVM、随机森林两种分类器产生的结果进行比较;(2)网络链路环境的影响实验,用于验证本文提出的特征预处理方法对不同网络环境的适用性。
3.3.1 基于XGboost的匿名流量识别
本节实验的主要目的是从背景流量中有效识别出Tor匿名流量。SVM在传统的分类任务中表现优异,文献[5-6,22]中均选择了SVM作为相应模型的分类器,因此本文将提出的识别模型与SVM、随机森林方法进行对比。此外,本文也对文献[9]中提出的基于深度学习识别加密流量的方法进行了复现,在同一数据集上对比了模型的分类效果。
实验结果如表5所示,其中类别0代表正常流量,类别1代表不同应用类型下的Tor匿名流量。

表5 流量识别实验结果
表5 与图4 的结果表明,本文提出的基于XGboost的模型可以很好地从背景流量中识别出Tor匿名流量,平均精度高达98.75%,与对照模型相比,本文提出模型的召回率更高,在网络监管任务中,更高的召回率意味着更低的漏报率。

图4 流量识别实验结果对比
3.3.2 不同网络链路环境的适应性
本文的方案中所使用的特征多数为数据流粒度下的时间相关性特征,为了提高特征的健壮性,减少网络延时、拥堵等对模型精确度的影响[23],在特征预处理阶段,使用了基于Histrogm的特征预处理方法来提高特征的鲁棒性,本节实验的主要目的是通过探索不同网络链路环境下模型的识别效果,来验证本文提出的特征预处理方案的有效性。
本节实验中,分别使用标准化预处理和本文提出的Histrogm特征预处理方法进行预处理,随后将本文提出的XGboost 模型在正常链路状态收集的数据集下进行训练,最后在三种数据集的测试集中进行测试。实验结果如表6所示。
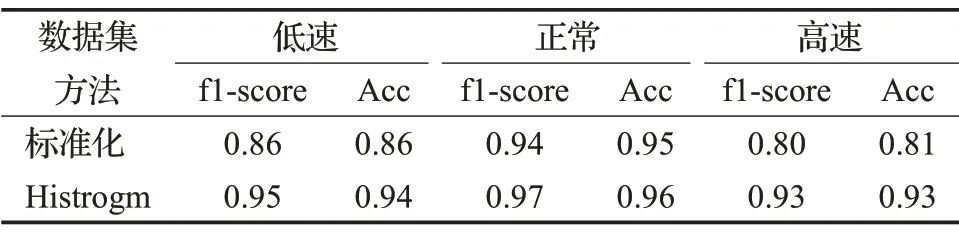
表6 不同链路状态下对比实验
表6 与图5 的结果表明,时间相关性特征确实会受到网络链路状态的影响。较快的链路速度相比较慢的链速度对模型识别准确的影响程度更大,本文提出的特征预处理方法相比于只是用标准化处理的方法能够有效减少网络链路波动对模型准确性的影响。

图5 链路适应性实验结果对比
4 结束语
本文提出了一种Tor 匿名网络流量分类识别模型。通过对时间相关性特征进行基于Histrogm 的离散化预处理,提高特征的健壮性。在ISCXTor2016数据集上进行验证实验,将实验结果与SVM、随机森林等在加密流量识别中表现较好的分类模型进行比较,结果表明本文模型在准确性与召回率上表现较好。因为本文使用的特征多数为时间相关性特征,将Histogram-XGBoost 模型在不同网络链路状态下收集的Tor匿名流量上进行识别对比。实验结果表明,经过预处理后的时间相关性特征具有较好的健壮性,本文提出的模型受网络环境影响较小。
在实验中发现,流超时时间的选择在一定程度上影响着数据收集的质量以及后续分类识别的准确率,下一步计划通过在不同的流超时时间下收集数据进行实验对比,探究能够提高识别效率的流超时时间,最终目标是在真实网络环境中实现匿名网络流量的快速检测。
