基于迁移学习的小样本DGA恶意域名检测方法
2021-07-28顾兆军杨文瑾周景贤
顾兆军,杨文瑾,周景贤
1.中国民航大学 信息安全测评中心,天津300300
2.中国民航大学 计算机科学与技术学院,天津300300
3.中国民航大学 中欧航空工程师学院,天津300300
域名对僵尸网络、钓鱼网络、勒索软件等恶意网络活动的构建起着重要的作用。为了更好地隐蔽网络攻击,恶意域名通常会使用一些方法以躲避安全人员的封堵,域名生成算法(Domain Generation Algorithm,DGA)就是一种常用的手段[1]。通过特定算法和强随机性的种子,嵌入在恶意程序中的DGA可以生成大量域名,其中只有一部分域名会被用来注册。当某个恶意域名被甄别并加入黑名单拦截后,攻击者仍可使用DGA 生成的新的恶意域名进行通信和攻击,因此很难通过黑名单的方式有效实现对攻击的拦截。
早期DGA的检测方法主要包括逆向工程技术和蜜罐技术[2],但是这种方法往往耗费资源较大,检测周期较长。近年来,有关恶意域名检测方法的研究逐渐转向域名自身语言特征挖掘和流量分析的方向。Yadav等人对拥有同一IP 地址的域名进行KL 距离、编辑距离以及Jaccard系数的测量,证明该方法对Conficker类DGA域名有较好的检测效果[3]。Fu等人在Yadav等人所使用的三个系数的基础上增加了隐马尔科夫模型和概率上下无关文法的应用,优化了DGA检测模型[4]。Jose等人使用N-gram 等方法对域名特征进行提取,并建立随机森林分类模型,提高了域名检测系统的性能[5]。近年来仍不断有新型DGA域名出现[6],当出现新的DGA种类时,由于传统机器学习依赖于人工特征提取,分类器往往不能很好地适应新的DGA域名。为了减少人工提取特征工作,研究人员实现了深度学习在DGA 域名检测上的应用。Xu 等人提出基于N-gram 和卷积神经网络的NCBDC 域名分类模型,提升检测模型的鲁棒性[7]。陈立国等人提出了基于GRU的DGA域名检测算法,进一步提升了模型的收敛速度[8]。周康等人提出了基于自编码网络和LSTM的恶意域名检测方法,提高了模型的检测率和实时性[9]。由于深度学习方法需要大量数据支撑,当样本不足时,训练结果将很难提升,而迁移学习可以达到提升分类效果的作用。段萌等人提出基于迁移学习和卷积神经网络的小样本图像识别方法,提高了识别的准确率和模型的鲁棒性[10]。Hu等人基于局部迁移学习提出端到端的卫星图像分类方法CPADA,提高了缺乏足够数据的卫星图像的分类效果[11]。邱宁佳等人提出结合迁移学习的卷积神经网络算法,实现了在少量数据标注下对微博文本进行情感分类[12]。
现有大多数恶意域名检测方法通常基于充足的域名数据集进行特征提取和模型训练,当数据量不足时,分类效果将大大降低。为了减少人工特征提取成本,解决DGA 域名样本不足的问题,本文基于多核卷积神经网络对24类DGA域名检测方法进行研究,并提出了一个基于迁移学习的小样本DGA域名检测模型。该模型可以实现减少人工特征提取成本,并解决DGA 域名样本不足的问题。模型首先使用数据量充足的DGA种类进行预训练,并将预训练过程中所学到的域名知识迁移到小样本DGA域名检测模型中。为了避免迁移学习过程中出现过拟合,迁移知识只应用于多核卷积神经网络的初始化。模型实现了基于迁移学习的小样本DGA域名种类的检测方法,最终达到提升小样本DGA 分类模型的准确率的目的。
1 基于卷积神经网络和迁移学习的小样本DGA分类模型
1.1 整体框架
域名生成算法可以采用日期、热搜词等进行特定变换生成DGA 域名。虽然域名生成算法不同,但是域名生成的整体思路相似,因此神经网络对不同种类DGA域名所提取的特征有一定的通用性。许多研究在训练分类模型的过程中往往需要使用上千条数据,然而在获取域名数据时,发现存在数据量极少的DGA 域名种类。当某种DGA 数据量不足以支撑模型训练时,该模型使用迁移学习借鉴其他DGA 种类分类模型参数,有效提高分类效果,实现了仅使用10条小样本DGA数据完成分类模型的训练。
针对小样本DGA 域名分类问题,本研究采用迁移学习和卷积神经网络的方法将已有知识迁移到小样本数据集的分类过程中。小样本DGA域名分类模型整体框架思路如图1所示。
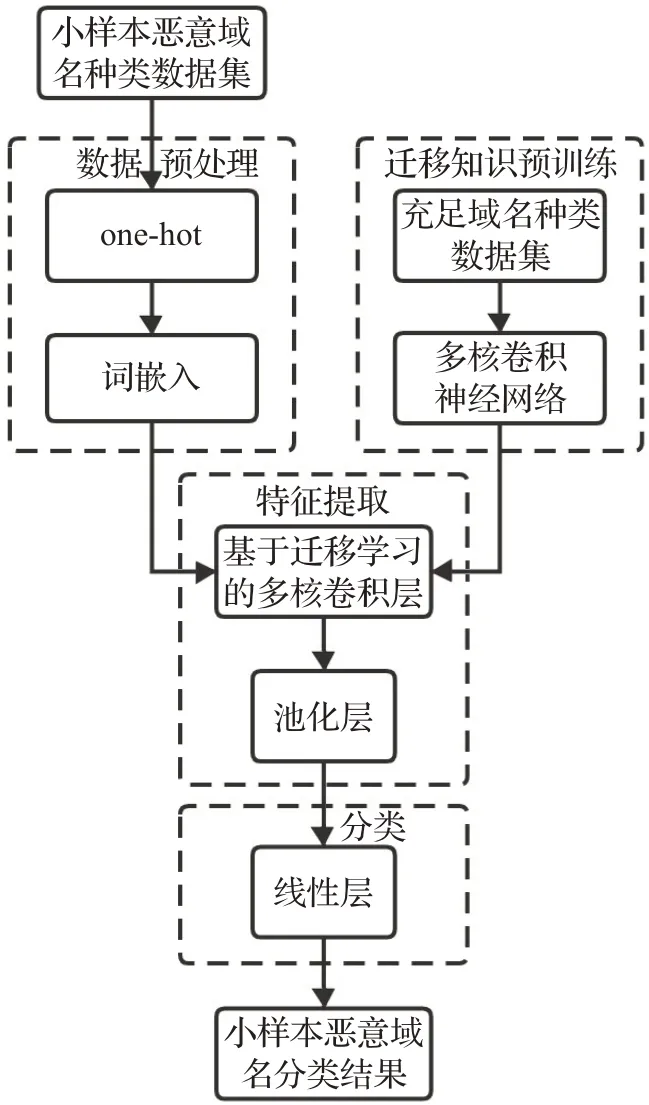
图1 小样本DGA域名分类框架
本研究首先对小样本域名数据集进行预处理,使用one-hot 编码方式将域名转化为模型可读的数据类型,并将域名字符进行嵌入映射到向量空间中。在训练分类模型之前,使用样本数据量充足的DGA 域名种类进行预训练,预训练过程中所获得的知识将用于迁移学习传入到小样本DGA 域名分类模型中。之后,将预处理得到的数据和预训练获得的知识传入多核卷积神经网络的卷积层进行特征提取,并使用池化层对特征进行筛选。最后将特征传入神经网络线性层进行分类,通过迭代使模型达到一个较好的分类效果并拿到最终的分类结果。
1.2 数据预处理
域名如“google.cn”等由两个及以上的部分组成,从右至左称为顶级域名和二级域名,以此推类还有三级域名等级别,不同域名级别以“.”进行划分。目前大部分学者针对DGA 域名的二级域名进行了研究[13-14]。根据顶级域名的不同,申请域名的限制条件和成本有所区别,某些DGA 种类常常选用一些较为容易申请的顶级域名如“.xyz”进行注册,同时,不同类别的DGA 所使用的顶级域名也不同。因此,本文将顶级域名加入考虑范围,使得特征的提取更加全面。
为了方便用户记忆,正常域名的字符通常会采用更符合发音习惯的组合方式,这与DGA 生成的域名有所不同。表1 中列出了几种常见DGA 的生成域名形式,可以看出某些在正常域名中出现概率极低的字符排列方式会出现在DGA域名中。

表1 三种常见DGA域名
为了将域名传入神经网络进行训练,首先采用onehot的编码方式对域名可用字符进行处理。然而采用此种编码方式得到的域名向量只能单纯地区分不同字符,不能表达字符排列方式的出现概率等信息。在自然语言处理的任务中,分布式表示因其对词之间距离的良好表达,以及出色的信息包含能力被广泛应用,因此在编码完成后采用分布式表示的方法,将域名嵌入到向量空间中。设域名数据集为D(d1,d2,…,dn),每一个dn的字符排列方式记为L(ln1,ln2,…,lnm),根据字符排列方式出现概率不同,可以通过一个转换矩阵T将域名转换为一个嵌入向量E:

其中,m为域名字符串长度,T为1×k维的转换矩阵,这样域名就映射到m×k维的向量空间中以表示域名字符间的关联程度。
1.3 多核卷积神经网络预训练
小样本DGA检测模型所使用的预训练卷积神经网络结构示意图如图2所示。

图2 预训练卷积神经网络结构
在卷积神经网络预训练过程中,使用样本数量充足的DGA种类数据集。首先将经过处理的域名0编码补齐为等长度字符串并传入嵌入层,之后将嵌入层的输出的向量与卷积核进行卷积,使用激活函数进行激活,卷积层所使用的计算公式如公式(2)所示:

其中,x为嵌入层传递输出,ki为卷积核,b为偏置,激活函数g使用ReLU函数。
n-gram 是自然语言处理中常用到的一种编码方式[15-16],目前已有部分研究使用这种方法提高DGA域名的分类精度[17-19]。若文本长度为l,n-gram 方法可以将文本分割成l+1-n个连续的n元组,从而保留文本的语序信息。然而随着n的不断增大,特征向量空间会不断增大,特征矩阵也会越来越稀疏。卷积神经网络中的卷积核可以起到与n-gram 方法类似的作用,通过设置卷积核的大小可以保留域名字符串的局部语序信息,而且不会带来特征稀疏的问题,从而省去了降维的过程,避免了在降维过程中信息的丢失。根据英文字符发音音节的经验,本文的卷积核大小第一维度设置为n={2,3,4}。
卷积层得到的结果将传入池化层,本文采用max pooling 的方法筛选掉不必要的冗余信息,之后将不同卷积核所对应的池化结果进行拼接。为了防止模型过拟合,提高模型的泛化能力,在传入线性层分类之前首先使用Dropout方法对神经元进行随机丢弃,Dropout值取0.5。
本研究使用softmax函数和交叉熵对经过线性层得到的分类结果进行损失计算,这里应用的计算公式为:
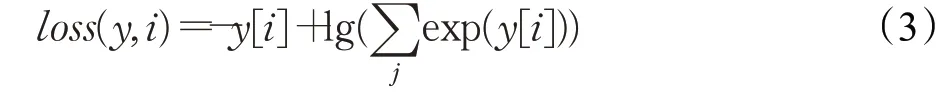
其中,y为线性层的分类结果,i为域名的种类。为了得到最小损失,使用可以为各个参数设置不同的自适应性学习率的Adam优化器更新卷积神经网络的权重。
1.4 小样本迁移卷积神经网络训练
数据样本的大小对神经网络模型的分类效果有极大的影响,对模型的上限有着决定性的作用。由于DGA是不断更新的,当特征发生改变的新型DGA域名样本数据量不足时,很难通过模型的优化实现对该类域名的高精度检测。迁移学习可以将模型在某领域已学习到的知识应用到另一相关领域当中,根据已有经验和极少的样本就可以完成对该领域的学习。
已有研究证明,卷积神经网络的浅层网络所提取的特征通常是较为简单的底层通用特征[20],因此将预训练所得到的嵌入层和卷积层参数作为知识迁移部分传递给小样本DGA 分类模型的特征提取模块。小样本DGA域名数据经过预处理传入迁移学习后的多核卷积神经网络并进行训练。为了避免参数固定导致训练效果降低或过拟合的现象出现,迁移的知识只应用于模型的初始化,在之后的训练过程中,迁移部分的模型参数仍参与训练更新。
小样本DGA分类模型使用的损失函数采用Sigmoid和BCELoss相结合的方法,计算公式如下所示:

其中,xn为预测第n个样本为正例的得分,zn为第n个样本为正例的预测概率,yn表示第n个样本的类别。优化器同样采用Adam以更新神经网络权重,在更新的过程中,为了使损失函数较为稳定的降低,学习率阶段性衰减,每次衰减为上一次迭代的0.5。
2 实验及结果分析
2.1 数据集与评价指标
2.1.1 域名数据集和测试环境
域名数据集来源于Alexa 网站和360Netlab 网站公开的数据,域名分为正常域名和DGA域名两部分。Alexa上提供了各个网站访问量排名,由于DGA 域名通常生存周期短,访问量通常不高,所以本文选取Alexa数据集中访问量较大的前10万条域名数据作为正常域名数据集。DGA 域名数据集来源于360Netlab的开源数据,该项目目前公布了44种不同类别的DGA域名共125多万条,包括常见的virut、tinba 等类型,以及suppobox 等基于字典的DGA 种类。由于部分域名种类数据数量过少,不足以支撑分类模型效果的验证,因此本文选用数据量较为充足的24类进行实验,360网站所提供的24类DGA 域名数据大小如表2 所示。小样本迁移卷积神经网络模型训练集仅使用10条DGA域名进行训练,迁移知识来自除小样本训练集以外的23个DGA域名类别。
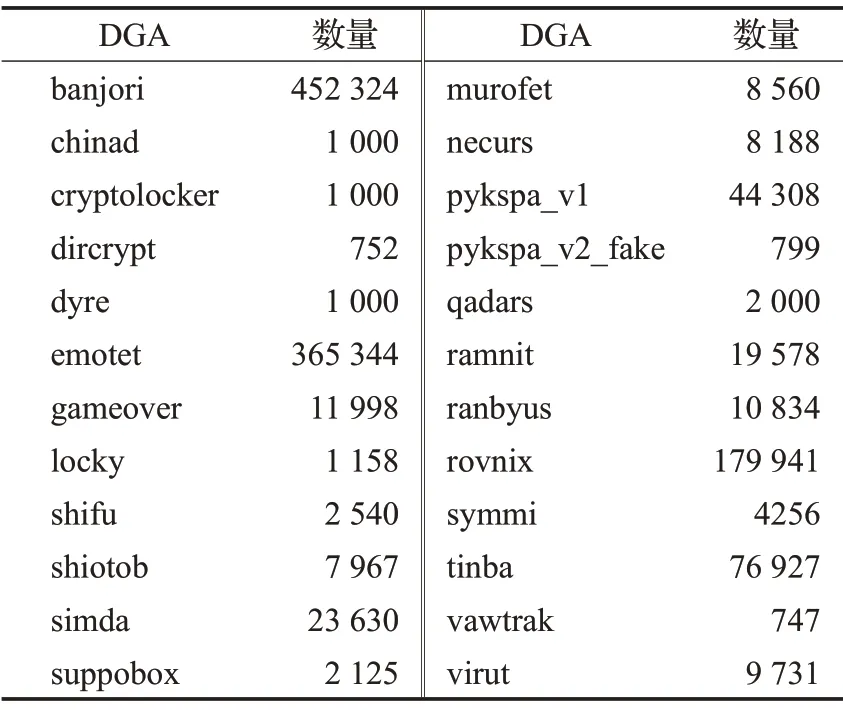
表2 24类DGA域名数量
本文的测试环境为Windows10,Intel®CoreTMi7-8565U CPU,8 GB 内存。模型的实现基于Pytorch 深度学习框架,版本为1.3.1,开发环境为Anaconda4.8.2,Python版本为3.7.4,模型支持GPU加速。
2.1.2 评价指标
准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F值(F1)是常用的几种机器学习评价指标,准确率表示总样本中预测正确占比,精确率表示预测是正类中预测正确占比,召回率表示所有正类中预测正确占比,F值为精确率和召回率的调和平均值,因此,若是精确率和准确率都较好,F1 值也会较高。本研究将采用这四种方式对模型进行评估。这四个指标的计算公式如下列公式所示:
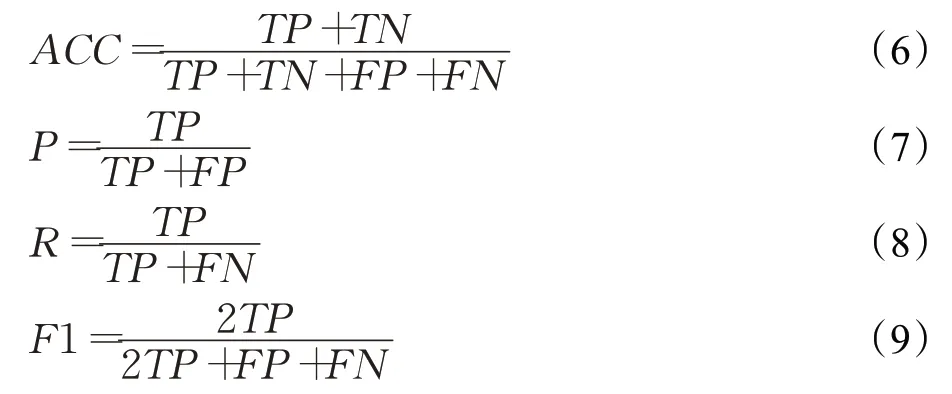
其中,TP为将正类预测为正类数,TN为将负类预测为负类数,FP为将负类预测为正类数,即误报数,FN为将正类预测为负类数,即漏报,这四个参数共同组成混淆矩阵。
2.2 数据处理
为了将域名数据转化成模型可读数据,首先使用one-hot 编码方式对原始域名进行编码,顶级域名将被保留。之后通过嵌入层将编码后的数据映射到向量空间中,根据公式(1),通过矩阵变换,编码数据转化为domain_len×Embedding_size的矩阵,其中第一维度为域名字符串长度,第二维度为嵌入维度,在本研究中取值为30。数据预处理的过程及最终结果如图3所示。

图3 数据预处理
2.3 实验结果对比分析
基于迁移学习和卷积神经网络的小样本DGA分类模型使用预训练的23 种域名分类器进行知识迁移,用于特征提取的卷积核大小为n×Embedding_size,其中第一维度n={2,3,4},卷积核个数为5。最终得到的分类效果如表3 所示。通过知识迁移,大部分DGA 种类都能被较好地分类,20 类DGA 域名分类准确率在92%以上,其中11 类准确率在97%以上,其余4 类准确率在80%到90%之间。

表3 迁移学习的小样本DGA分类结果 %
在24 类DGA 域名中,pykspa_v1、simda、suppobox和virut 类的迁移效果不够理想。simda 类和suppobox类域名的构成较为符合发音规则,如“nopolomojen.eu”,virut类大多数域名字符串长度都较短,二级域名长度通常只有6个字符,无法提取到充足的分类特征。
为了更直观地体现迁移学习在小样本DGA分类模型中起到的作用,本文使用样本充足的多核卷积神经网络DGA 分类模型和无知识迁移的小样本DGA 分类模型进行对比。图4至图7为三种模型得到的四项评价指标的对比结果。
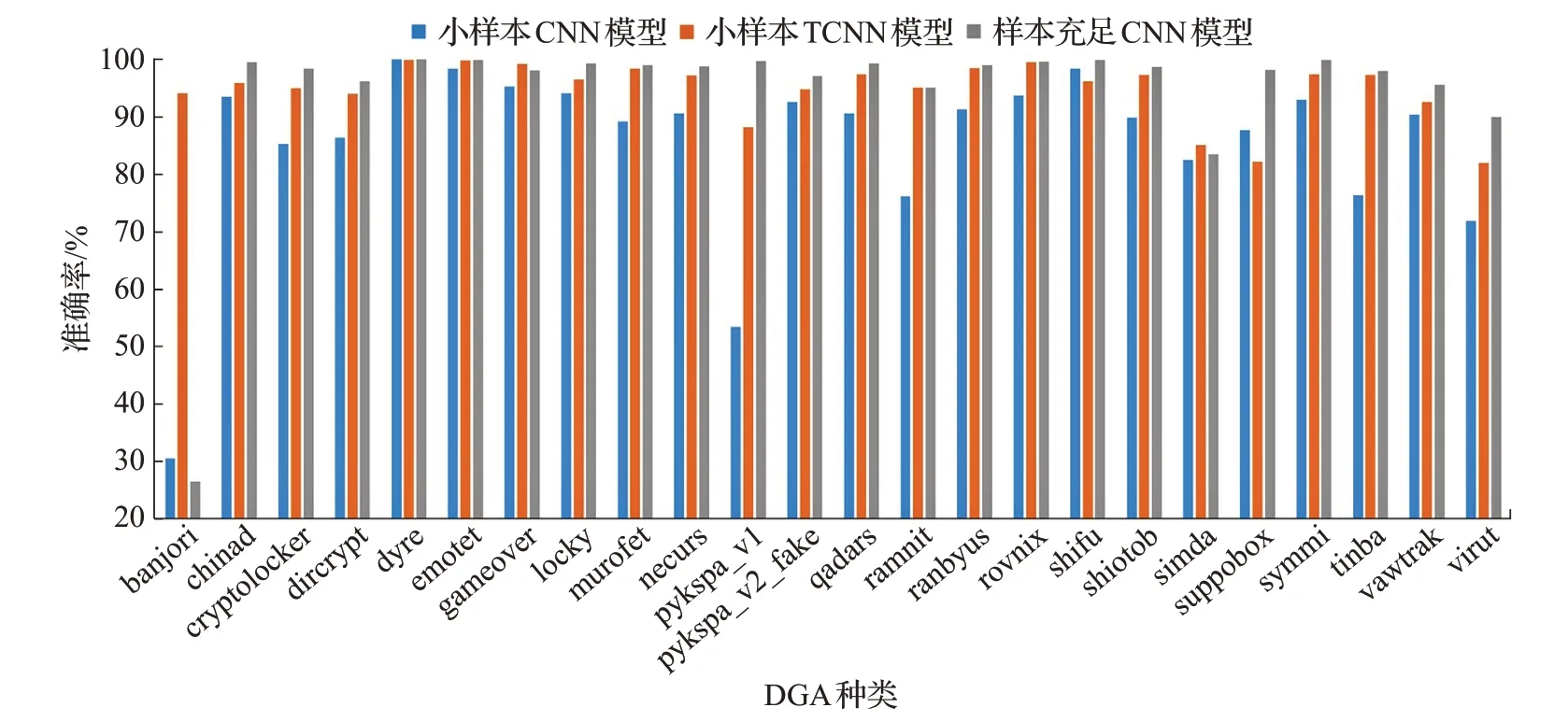
图4 三种模型分类准确率对比

图5 三种模型分类精确率对比
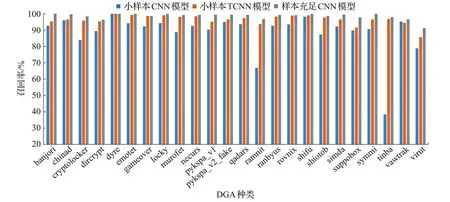
图6 三种模型分类召回率对比
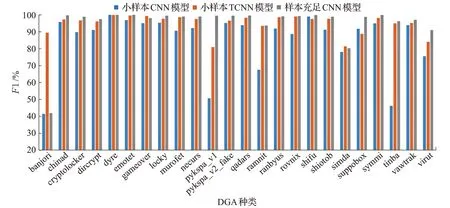
图7 三种模型分类F 值对比
当数据样本充足时,单层多核卷积神经网络可以满足大多数种类的DGA 域名检测且识别结果较好,其中21 类DGA 域名的分类准确率达到95%以上,14 类的准确率、精确率、召回率和F值均在98%以上。而无知识迁移的小样本DGA 域名分类效果明显较差,大部分种类的四项评价标准均有明显下降,仅有少部分DGA 域名仍能达到训练数据充足时的检测效果,11类域名准确率达到92%以上。
对比两个小样本DGA 分类模型,通过对充足样本训练的神经网络进行迁移,23 类DGA 域名的四项评价标准较未迁移之前均有较为明显的提升。将经过迁移学习的小样本分类模型和充足样本所训练的分类模型进行对比,20 类小样本DGA 分类模型四项评价标准与样本充足时所训练的模型差值不超过-4%,3类小样本DGA域名分类模型的准确率、精确率和F1 值优于样本充足时的训练结果。pykspa_v1、suppobox 和virut 类DGA域名的迁移模型训练结果与样本充足训练结果相比差距仍较大,但pykspa_v1和virut类小样本分类结果较无知识迁移的分类结果已有明显提升,suppobox类域名迁移后的效果比未迁移的结果略差。
此外,在训练过程中,训练数据量不足的模型需要花费更长的时间迭代更多次数才能得到模型较优参数。而经过知识迁移的模型收敛速度较快,所花费时间大约为无知识迁移模型的25%。
3 结语
本文提出了基于迁移学习的卷积神经网络小样本DGA 域名分类模型,并对24 种DGA 域名进行了测试。首先在数据预处理部分保留了顶级域名的特征,并将域名映射在向量空间中完成字符嵌入。预训练部分使用其他多种类DGA 域名对多核卷积神经网络进行训练。之后将预训练得到的知识迁移到小样本DGA分类模型中,并使用处理后的数据进行训练。实验结果表明,大部分经过知识迁移的DGA域名分类结果较无迁移模型有明显提升,四项评价标准接近数据充足时训练的模型,20类域名准确率在92%以上,11类准确率达到97%。由于迁移后的模型对小部分的域名种类效果不够理想,在接下来的工作中,将在进行知识迁移之前分析各类域名的领域分布差异,并对自动检测新型小样本域名的无监督方法进行研究以进一步减少人工标注成本。
