一种改进的皮层网络环境认知模型
2021-07-25阮晓钢
武 悦 阮晓钢 黄 静 柴 洁
环境认知是哺乳动物觅食和生存的基本技能,研究表明[1−3],哺乳动物普遍具有强大的环境认知能力.研究并复现哺乳动物的环境认知机制对于提高智能体导航能力、增进人们对生物环境认知机制的理解有着重要意义.有研究发现[4],前额皮层与高层次的环境认知有关,对前额皮层实施组织切除术后的大鼠不能完成Morris 水魔方环境认知任务.皮层网络实质上是不同神经元在大脑中的组织方式,其组成单元皮质柱是一种按照神经元功能排列的分层结构.皮层网络对于哺乳动物环境认知的重要作用在于建立感官输入与动作决策之间的联系,形成完整的环境认知能力.
为了使机器人表现出像哺乳动物那样强大的环境认知能力,很多学者对前额皮层网络进行了计算建模研究.皮层网络建模通常涉及奖励传播及路径规划两个问题.对于前者,目前广泛采用奖励扩散[5−9](Reward diffusion)的方法.该方法以固定的传播系数将奖励值传播给周围神经元,具有计算简单的优点.但是,由于离子通道的随机开闭或神经元的形态变化,神经元内部存在着噪声信号,干扰了神经元的规律放电[10].在考虑神经元噪声的情况下,基于奖励扩散方法的模型由于噪声在神经元传递过程中的累积效应,导航表现有所下降,且奖励信息随距离增加而发生衰减.对于路径规划问题,皮层网络模型的路径规划主要采用向量法[11]和位置细胞法[12−13].向量法通过对头朝向细胞的活动加权平均作为动作方向,位置细胞法以位置细胞中心为规划路径点.虽然这两种方法都能完成绕近路任务(例如托尔曼三通道迷宫[14]),但是规划出的路径均依赖于已探索区域,无法规划出全局上最短的路径.一些学者试图将两种方法结合起来以规避缺点[15−19],但其模型普遍存在易受神经元噪声影响的问题.
为了提高模型对于神经元噪声的鲁棒性,本文将波前传播(Wavefront propagation)方法引入模型.波前传播方法[20−22]利用整合放电(Integrateand-fire,IF)神经元避免奖励信息的衰减,由此增强模型抗神经元噪声的能力.其现象已在电生理学实验中被观测证实,是一种具有生物合理性(Bioplausibility)的计算方法[23].目前,已有学者将其应用于基于图的导航中[24−26],但关于该方法在皮层网络模型中的应用还鲜有报道.受此启发,本文将波前传播应用于模型的奖励传播回路,结合全局抑制神经元,提出一种改进的皮层网络模型以提高对神经元噪声的抗干扰性.另一方面,为了保证模型的路径规划效率,模型引入了位置细胞和时间细胞,利用时间细胞活动随时间增长的特性及其时间常数衰减机制选出全局最佳路径点,进而提高路径规划性能.
1 皮层网络环境认知与导航模型
生理学研究[27]表明,前额皮层中存在对奖励信息编码的神经元,提供与环境交互所需的动机信号.Preston 等证明了海马体与前额皮层间存在信息交互[28],前额皮层接收海马体感官信息的投射,其中包括对空间位置具有选择性的位置细胞[29]和对时间编码的时间细胞[30].此外,前额皮层中存在着同时传输奖励信息和运动信息的神经元[31].
基于前额皮层生理学结构及其环境认知功能的研究结论,本文对前额皮层网络进行计算建模.如图1 所示,皮层网络包含奖励传播回路和路径规划回路.奖励传播回路由奖励细胞和中间神经元构成,负责在皮层网络中传播奖励信息,中间神经元通过STDP 机制对奖励传播路径进行记忆;路径规划回路由中间神经元和位置偏好细胞构成,并接收来自海马体位置细胞和时间细胞的输入,其作用是利用奖励传播回路保存的环境信息进行路径规划,通过时间细胞对位置偏好细胞的增长性输入提高路径规划效率.
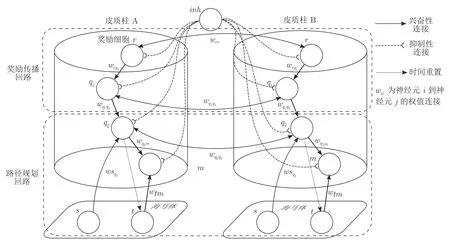
图1 皮层网络模型结构示意图Fig.1 Scheme of the cortical column network model
1.1 奖励传播回路
奖励传播回路包含奖励细胞r、中间神经元q1.奖励细胞对奖励信息进行编码,一旦机器人感知到奖励的存在(如到达逃生平台或放置有食物、水的位置),该细胞即产生脉冲放电.为了实现奖励信息在皮层网络中的传播,奖励细胞之间存在双向连接wrr.当奖励细胞被激活后,脉冲放电向其他奖励细胞传递,同时也向中间神经元q1传播.奖励回路采用基于IF 神经元的波前传播方法,波前(某时刻所有放电的神经元构成的膜电位场)从奖励位置出发传播到自身位置.在波前传播方法中,奖励细胞r和中间神经元q1的膜电位服从式(1):

其中V(t)∈[0,1]是神经元膜电位,τ是时间常数,N(t)是神经元噪声,Vinh(t)是来自全局抑制神经元的抑制性输入.I(t)是接收其他神经元的整合输入,服从式(2):
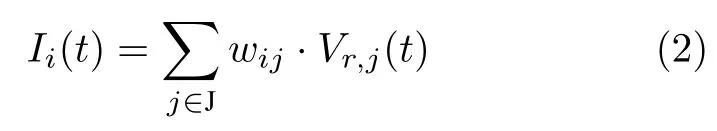
其中V∗,j为第j个皮质柱中类型为∗的神经元.若V(t)超过放电阈值Vthr,则神经元产生放电,膜电位提升至V(t)=1.放电后神经元进入一段时间的抑制状态,不接受其他神经元的输入,膜电位服从式(3):

其中tf是神经元放电的时刻,td是神经元进入抑制状态的持续时间.
中间神经元q1之间的权值wji根据STDP 学习律变化,权值改变服从式(4):
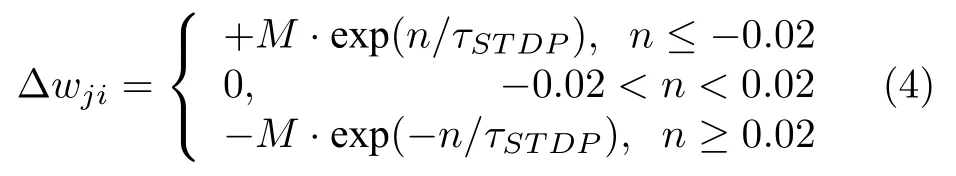
其中M是幅值,是突触后神经元与突触前神经元间的放电时间差.τSTDP控制放电时间差对权值变化的影响.
文献[32]证明了首个到达目标点的波前总是通过最短的路径,进而得出波前传播方法等价于Dijkstra 算法.因此,记录首个到达目标点的奖励信息波前传播路径即找到了通往奖励的最短路径.为了实现对波前传播路径的记忆,并利用其逆路径进行路径规划,权值共享给路径规划回路中的中间神经元q2用于路径规划.
由于每个神经元接收来自相邻神经元的输入,其中包含了噪声,该噪声在单一神经元上的积累可能导致其误放电,从而导致模型失效.为了解决这一问题,本模型在皮质柱外引入了全局抑制性神经元inh.抑制性输入需要满足一定的取值范围,输入过小无法达到消除神经元的误放电的目的,而输入过大则有可能破坏神经元的正常放电.考虑到神经元噪声的分布特性[10],本文将抑制性神经元inh的膜电位Vinh取值范围设置为服从式(5):
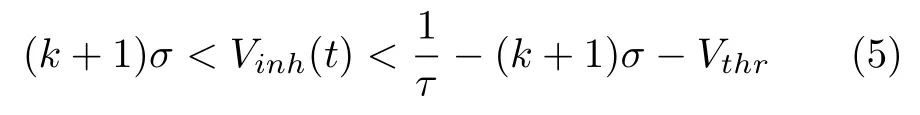
其中k为与当前皮质柱存在连接关系的皮质柱数量,σ为神经元噪声标准差.
1.2 路径规划回路
路径规划回路负责根据奖励传播回路保存的奖励信息进行路径规划.该回路具体设计思路如下:如前所述,为了追求最短导航路径,须使神经元信号沿所记忆的波前传播路线进行传播,令中间神经元q2接受中间神经元q1和位置细胞s的投射,利用奖励传播回路权值在路径规划回路中的副本将波前传播至目标点.但是,由于可能没有位置细胞对全局最短路径涉及的区域进行编码,该传播路径不一定是全局最短路径.为了解决这一问题,在模型中引入时间细胞和位置偏好细胞,实现分段路径规划.时间细胞充当计时器,并为位置偏好细胞提供增长性输入,使模型在子路径点的规划中经过多个位置细胞,其构成的直线路径能够穿越潜在的未探索区域,从而提高效率.
子目标点由位置偏好细胞确定,由于选取子目标点涉及不同位置偏好细胞的比较,而神经元放电的瞬时性决定其无法提供这一比较,因此在该回路中除中间神经元q2外均采用非放电神经元模型.中间神经元q2需为路径规划回路提供信息传播时序,仍然采用整合放电神经元模型.
中间神经元q2采用式(1)描述的整合放电神经元模型以实现波前传播,其作用是充当奖励传播回路和路径规划回路的连接,并为路径规划提供时序.当奖励传播回路完成奖励信息从目标点到自身位置的传播后,中间神经元q2被激活,进入路径规划阶段.为了使路径规划回路利用奖励传播回路计算的奖励信息,中间神经元q2共享中间神经元q1的权值,即.
海马体位置细胞s编码空间位置,对特定空间位置产生强烈反应.O' Keefe 通过电生理实验得出海马体位置细胞放电频率的最佳拟合为一高斯函数[29],因此本模型位置细胞膜电位Vs采用高斯函数描述,服从式(6):
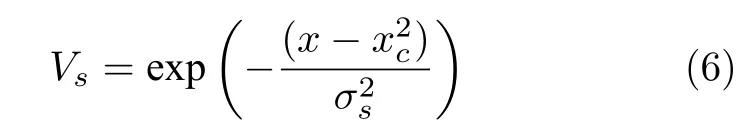
其中x是机器人位置,xc是位置细胞位置野中心,σs决定位置野的大小.位置细胞活动是判断是否新增皮质柱的依据,当所有位置细胞膜电位均小于阈值Vs,thr时,说明在当前位置没有相应的位置细胞对其编码,则新增一个皮质柱并与前一皮质柱建立连接.
位置偏好细胞m编码对皮质柱所在位置的偏好程度,决定路径规划中的子路径点.在路径规划的每一个子段中,机器人向值最大的位置偏好细胞直线移动.位置偏好细胞采用非放电神经元模型,接收来自中间神经元q2和海马体时间细胞t的输入,其膜电位服从式(7):

其中Vq2(t)为中间神经元q2的膜电位,Vt(t)为时间细胞的膜电位.
为了提高规划路径的效率及对动态环境的自适应性,在路径规划回路中引入时间细胞.时间细胞可以使模型在子路径点的规划中经过多个位置细胞,构成的直线路径可以穿越潜在的未探索区域,从而提高路径效率.在路径规划的每个子段中,时间细胞的活动随时间增长而增加,从而增加接受其投射的位置偏好细胞活动,其膜电位服从式(8):
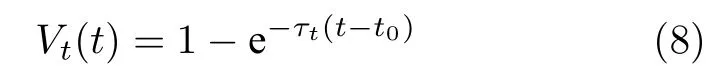
其中t0为路径规划中每个子段的初始时刻,即每个子段中神经元q2首次放电的时刻,τt为时间常数.
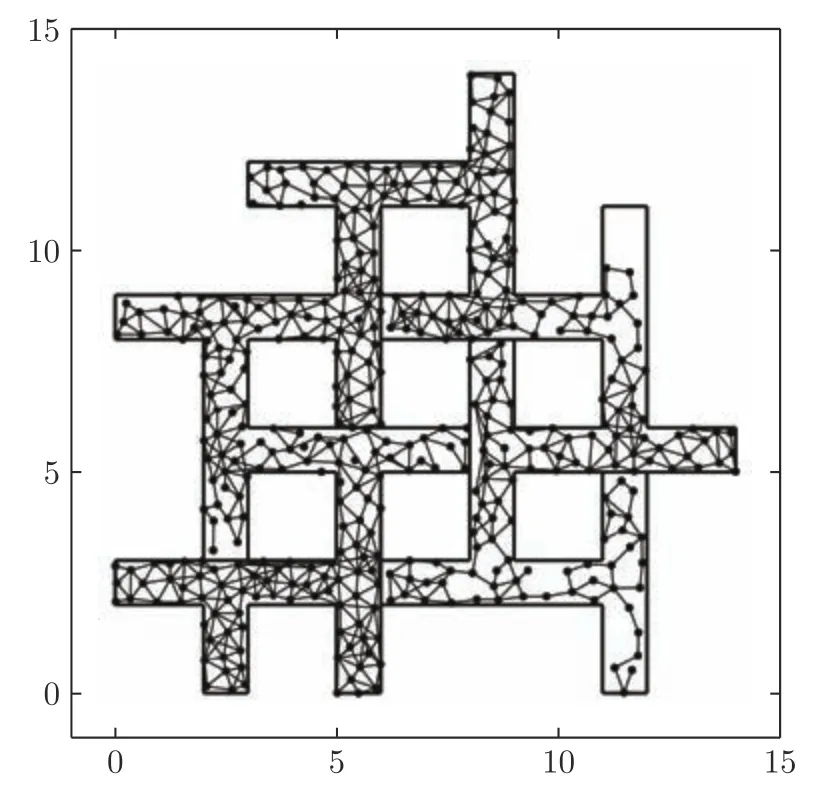
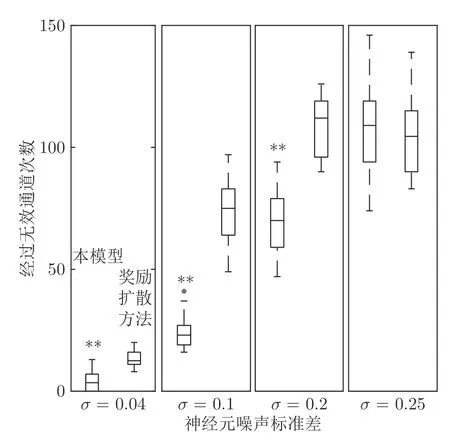
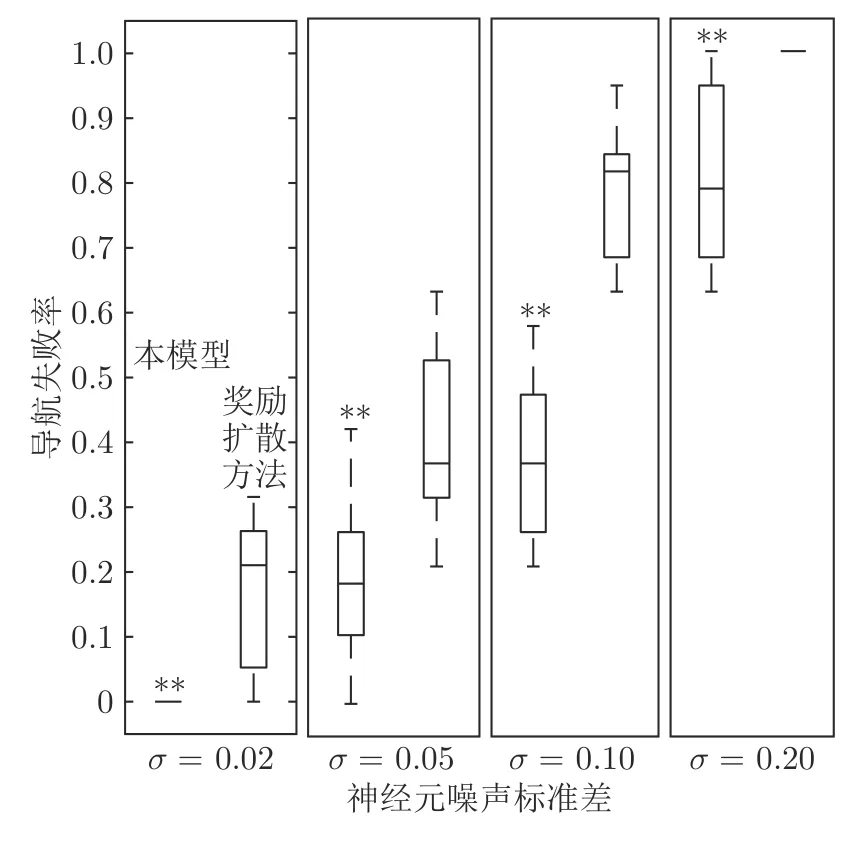
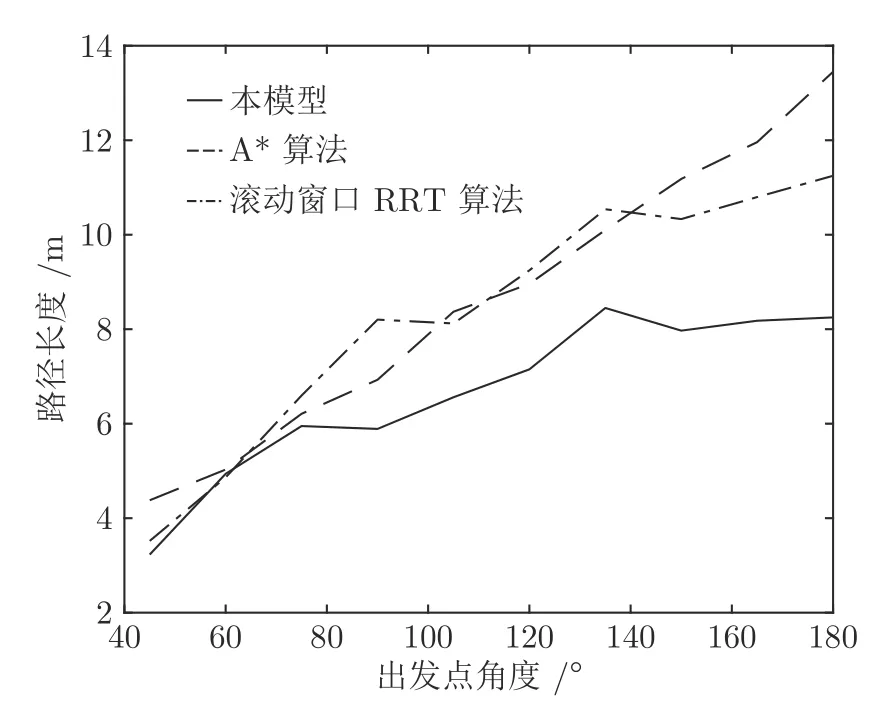
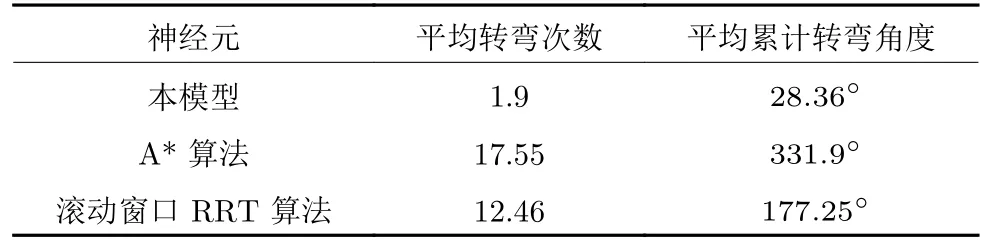
在时间细胞未饱和阶段Vt(t) 根据模型的设定,在机器人探索过的区域需要有相应的位置细胞对其进行编码.在对新环境的探索过程中,若所有位置细胞活动均不足,不能对该位置做出有效的空间感知,则新增一个编码当前位置的皮质柱,并建立与前一皮质柱的连接.因此,在经过一定时间或距离的运动后,将产生具有一定规模的皮层网络拓扑图.皮层网络拓扑图中的奖励细胞能够对奖励信息进行认知,形成由奖励到空间位置的映射,由此生成的认知地图可以用于执行寻找食物奖励或逃生等环境认知任务. 认知地图概念最早是由Tolman 等所提出[14].Tolman 等在三通道迷宫实验中发现,无论环境如何改变,大鼠均能够找到通往目标点的最短路径,由此提出大鼠记住的不是某些路径,而是在脑中生成了一幅认知地图.本模型所生成的皮层网络拓扑图与认知地图相对应,是认知地图在计算模型上的体现. 算法1.路径规划回路算法 本节通过两个心理学上的经典实验 (托尔曼14 单元T 型迷宫、Morris 水迷宫)对模型的环境认知能力、神经元噪声鲁棒性、动态环境的适应能力及路径规划效率进行测试. 本实验采用仿真机器人作为主体,具备距离传感器,能够探测正前方0.2 m 内是否存在障碍物,忽略体积将其视为一个质点.仿真机器人采用本文提出的皮层网络环境认知模型.对于整合放电神经元r、q1、q2,膜时间常数τ=0.8,放电阈值Vthr=0.3,放电后抑制阶段持续时间td=0.3 s.神经元的其他参数在表1 中列出.为了奖励信息在皮层网络中传播而不发生衰减,奖励细胞之间存在饱和双向连接wrr=1.中间神经元q2的激活条件是奖励信息传播至自身所在位置,仅在中间神经元q1和位置细胞s同时激活时放电,因此设置=0.1.将神经元参数值代入式(5),同时考虑到实际的神经元中抑制性输入通常为较低水平,本实验设置Vinh=0.1 为基准值.仿真时间间隔设置为Δt=0.02 s. 表1 模型参数值设定Table 1 Parameter setting of the model 2.2.1 实验背景 托尔曼[33]曾设计了14 单元T 型迷宫实验来观察大鼠在迷宫中的空间认知表现,并由此提出了认知地图的假设.如图2 所示,该迷宫有唯一一条通往奖励的路径和14 个无效通道.将大鼠放置在迷宫的起点,在另一端放置食物,测试大鼠直到获取食物时经过的无效通道的次数,该指标能够反映大鼠对环境的认知程度.本文采用该实验测试模型的噪声鲁棒性以及对动态环境的自适应性. 图2 托尔曼14 单元T 型迷宫实验示意图Fig.2 Sketch of Tolman 14-unit T-maze experiment 2.2.2 实验设计与结果 托尔曼14 单元T 型迷宫实验验证了认知地图理论,本文在相同的环境下对模型的认知地图构建、神经元噪声鲁棒性和对动态环境的自适应性进行测试,实验分为准备阶段和测试阶段. 1)认知地图构建 在准备阶段中机器人从起点出发对迷宫进行探索,直至找到放置在目标点处的奖励.机器人在每次直线前进0.3 m 后进行60°以内的随机偏转,若遇到障碍物则继续改变朝向.经过探索,机器人建立起皮层网络(图3).图中,黑色圆点代表皮质柱,它们在探索过程中动态生成、连缀成网,形成皮层拓扑网络,以这种形式反映智能体对环境的认知,即构成认知地图. 图3 机器人探索迷宫后建立的皮层网络拓扑图 (m)Fig.3 Cortical column topological map after exploring the maze (m) 2)神经元噪声影响 神经元噪声是神经元内部产生的一种噪声电信号,干扰神经元的正常放电.文献[10]通过电生理学实验得出神经元噪声服从高斯分布,基于此结论在本实验中向皮层网络中所有神经元添加高斯分布噪声N~N(0,σ).在测试阶段中,将机器人放置于起始位置,模拟的目标点奖励使认知地图中对应的奖励细胞放电,激活皮层网络模型使机器人向目标点导航.受神经元噪声的影响,皮层网络内的神经元放电顺序可能被打乱,造成部分奖励信息的丢失.若大鼠停留在同一位置超过5 s,则认为模型陷入局部最优,此时仿真大鼠随机移动4 m 后重新进行路径规划,记录到达目标点过程中经过无效通道的次数.为了使实验结果具有统计学意义,总共做18组实验,在每组实验中设置不同的噪声标准差进行导航测试,并与采用奖励扩散方法的皮层网络模型进行对比,奖励值传播系数β=0.98,该系数为多次试验得出的能够产生最佳的导航结果的系数. 实验结果如图4 所示,从箱线图的上下边缘、上下四分位数以及中位数上看,当标准差在0.2 以内时,本模型经过无效通道次数显著少于奖励扩散方法.箱线图的箱体长度代表数据的波动程度,从图中可以看出,两种模型经过无效通道次数的波动程度均随神经元噪声增大而增加,但是在神经元噪声标准差不超过0.2 的范围内,本模型对应的箱体更短,表明失败次数的波动更少,进而说明了本模型的路径规划性能相对稳定(图中双星号代表在5 %的显著性水平下存在显著性差异). 图4 噪声标准差对导航结果的影响Fig.4 Influence of neuron noise standard variation on navigation results 当噪声标准差继续增大至0.25 时,两种方法的导航表现均接近盲目探索(盲目探索时经过无效通道的平均次数为122 次).然而在实际中,噪声标准差超过0.2 是一个小概率事件[10].实验结果表明,在合理的神经元噪声范围内,本模型的神经元噪声鲁棒性优于采用奖励扩散方法的皮层网络模型. 3)对动态环境的自适应性 当环境发生变化时,动物能很快适应这一变化,迅速做出调整,反映出动物在环境认知上的自适应性.本实验模拟这一过程,测试模型对动态环境的自适应能力.如图5 所示,测试包含3 次实验:第1 次,在托尔曼14 单元T 型迷宫中移除其中一处墙壁,标记为“1”(图5 (b));第2 次,恢复“1”处墙壁,标记为“2”,再移除迷宫中另外两处墙壁,分别标记为“3”、“4”(图5 (c));第3 次,在图5 (c)的基础上增加一处墙壁,标记为“5”(图5 (d)).3次实验对环境的改变逐渐增多,既包含对障碍的移除,也包含对障碍的增加. 令机器人利用准备阶段建立的认知地图在3 次实验中完成导航,结果如图5 所示.可以看出,机器人在3 次环境改变中都能自适应地调整巡航行为,重新找到通往目的地的较短路线,说明模型具有对动态环境的自适应性. 图5 机器人在环境发生变化前后采取的路线Fig.5 Path planned before and after environmental change 2.3.1 实验背景 1982 年Morris 等[34]在测试大鼠的空间记忆能力时设计了Morris 水迷宫实验.如图6 所示,Morris 水迷宫为一圆形水池,其中存在一个隐藏的逃生平台,被放置于水池中的大鼠需要找到并保持在逃生平台上以继续存活.实验结果表明,大鼠首次找到平台后,在后续的测试阶段从水池不同位置放入的大鼠均能够采取一条近似直线的路径逃往平台.然而,破坏海马体组织后大鼠无法成功地找到逃生平台,证明海马体具有空间记忆功能.此外,逃生时采取的路径也体现了海马体相关回路的路径寻优能力.本文采用该环境对模型的噪声鲁棒性和路径规划效率进行测试. 图6 Morris 水迷宫示意图Fig.6 Sketch of Morris water maze 2.3.2 实验设计与结果 本文实验仿照Morris 水迷宫实验设计如下:水迷宫为一直径10 m 的圆形水池,水池中有一边长为1 m 的正方形隐藏逃生平台;水池中的一组中心对称的障碍物用来测试模型的避障能力,中心对称结构能够防止逃生平台与障碍物线索的关联.实验分为准备阶段和测试阶段,首次逃生任务属于准备阶段,后续逃生任务均属于测试阶段. 1)认知地图构建 在准备阶段中机器人首次执行逃生任务,在逃生过程中对环境进行初次探索.机器人在每次直线前进0.3 m 后进行30°以内的随机偏转.大鼠在Morris 水迷宫实验中表现出沿边缘行进而避开中央区域的行为,本实验采用相似的设置,使机器人避开距中心3 m 内的区域.模型以皮层网络的拓扑结构来描述机器人逃生时经过的区域,是认知地图在计算模型层面的具体体现(图7). 图7 Morris 水迷宫路逃生实验中的移动轨迹(左)和建立的皮层网络拓扑图(右)(m)Fig.7 Moving trace on the preparing stage (left)and the established cortical column network (right)(m) 2)神经元噪声影响 为测试模型对神经元噪声的鲁棒性,根据文献[9]指出的神经元噪声服从高斯分布的结论,在实验中向皮层网络中所有神经元添加高斯分布噪声N~N(0,σ).在测试阶段中,将机器人放置于水池内不同起始位置,模拟的逃生本能将对应逃生平台位置的奖励细胞激活,使机器人向逃生平台导航.若大鼠停留在同一位置超过10 秒,则认为模型陷入了局部最优,该次导航失败.为排除偶然因素的干扰,共进行18 组相同的测试,在每组中设置不同的噪声标准差进行导航测试,并与采用奖励扩散方法的皮层网络模型进行对比. 实验结果如图8 所示,由于波前传播的整合放电特性以及全局抑制神经元的抑制作用,本模型在神经元噪声标准差较小时(σ=0.02)导航未受影响,其导航失败率为0,而奖励扩散方法的失败率中位数达到了20 %.当噪声标准差增大至0.05 和0.1 时,本模型的导航失败率的最大最小值、上下四分位数以及中位数始终低于奖励扩散方法,当噪声标准差较大时(σ=0.2),本模型导航失败率中位数达到0.77,而奖励扩散方法完全失败.该结果表明,本论文模型的神经元噪声鲁棒性显著优于采用奖励扩散方法的皮层网络模型(p=0.05). 图8 不同噪声对导航的影响Fig.8 Influence of neuron noise on navigation results 3)路径规划效率 在测试阶段,将机器人放置于水池内不同起始位置执行逃生任务,神经元噪声设置为N~N(0,0.01).在其中几次逃生中(图9),机器人能够穿越未探索过的区域(与图7 所建立的认知地图相比),说明本模型的路径规划是基于全局而完成的. 图9 从不同位置出发的逃生路线 (m)Fig.9 Escape trace from different starting points (m) 为了说明本模型的路径规划效果,本实验选择了A*算法[35]和滚动窗口快速扩展随机树算法(Rapid-exploring random tree,RRT)[36]进行了对比.两者均为路径规划中经常使用的流行算法.为使A* 算法与RRT 算法在本实验中表现出最佳效果,本文通过多次实验设计算法细节及参数如下:A* 算法中节点评估函数为f(x)=g(x)+h(x),其中g(x)为已选取节点的累计路程,h(x)为当前位置到目标点的欧氏距离;滚动窗口RRT 算法中窗口半径r=1.5 m,随机树生长步长ρ=0.3 m,窗口范围内随机树节点数量K=25.步长与本论文中皮质柱平均间隔相近,以保证在相近的条件下进行路径规划的比较. 在路径规划效果指标的选取上,本文参考了文献[37],采用转弯次数、角度以及路径长度作为对比指标.转弯次数及角度的增加通常对机器人的运动速度带来限制,造成频繁的减速、停止和加速,降低导航效率.因此,较少的转弯次数、转弯角度以及较短的导航路径通常意味着更好的路径规划效果. 图10 对不同方法所规划的路径长度进行了对比.从该图可以看出,除出发点角度(出发点与水池中心的连线与x轴正半轴夹角的绝对值)为60° 时本模型规划的路径长度无明显优势外,其余出发点角度下本模型规划的路径长度都明显短于另两种算法. 图10 不同规划方法所规划路径长度Fig.10 Length of planned path by different planning method 表2 列出了本实验中从所有角度出发的平均转弯次数和平均累计转弯角度.由实验结果可以看出,本模型的平均转弯次数及平均累计转弯角度远低于A* 算法和滚动窗口RRT 算法,说明规划的路径更加平滑,有效地提高了路径规划及导航的效率. 表2 不同方法规划路径的转弯次数及转弯角度对比Table 2 Comparison of turning counts and angle of path planned by different path planning methods 哺乳动物的皮层网络整合感官信息并输出动作决策,该信息处理中枢对环境认知的重要性引起了许多对皮层网络的计算建模研究.针对目前的皮层网络模型受神经元噪声影响较大的问题,本文利用整合放电模型的非线性特性对神经元进行建模,将波前传播方法引入奖励传播回路,同时结合全局抑制神经元,使模型具有更强的抗噪声干扰性.同时,为了防止路径规划效率的下降,在路径规划回路中引入位置偏好细胞和来自海马体的时间细胞,通过时间细胞及其时间常数衰减机制选出全局最佳路径点.模型结构、各神经元功能设计及波前传播方法都基于目前的神经生理学研究结论,具有一定的生物合理性. 为了验证模型的有效性,本文复现了心理学上两个经典的环境认知实验:托尔曼14 单元T 型迷宫实验和Morris 水迷宫实验,并与其他皮层网络模型和路径规划方法进行了对比.实验数据表明,本文所提出的模型与其他皮层网络模型相比具有更强的神经元噪声鲁棒性,较之A* 算法和滚动窗口RRT算法具有更好的路径规划效果.同时,模型也表现出较强的对动态环境的自适应能力. 另一方面,目前模型中时间细胞的时间常数衰减机制较为简单,需要进一步优化以提高最佳路径点的选取能力及搜寻速度.为了使模型具有更佳的环境适应能力,时间常数随环境的变化机制需要进一步探讨.如何构建时间常数衰减机制涉及的回路,使其符合生理学研究发现,也是下一步研究的重点.1.3 认知地图(Cognitive Map)的构建

2 实验设计与实验结果
2.1 仿真实验参数

2.2 托尔曼14 单元T 型迷宫实验


2.3 Morris 水迷宫实验



3 结论
