基于PCA-RF直流炉中间点温度预测控制
2021-07-23梁伟平鲍鹏凯
梁伟平,鲍鹏凯
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引言
为了加快洁净燃煤发电新技术的研发和推广应用,提高煤电发电效率及节能环保水平,在未来的很多年,煤炭在中国能源结构中的主导地位不会发生根本的改变。由于未来全球能源需求预计仍将大幅增加,国际能源署煤炭产业咨询委员会强调指出,煤炭将继续作为21世纪的全球能源解决方案[1]。为了响应节约资源的号召,大机组、大容量、大电网的电力系统已经开始逐渐取代了过去的小机组、小容量的电力生产潮流,而直流锅炉作为现代电力生产的主要设备,承载着节约资源和保护环境的作用,而分离器出口温度作为反应直流锅炉中给水流量和水煤比的一个重要的工况指标,它直接关系着机组的安全运行,研究它对电力生产过程的重要性不言而喻。
直流锅炉中间点温度一般是汽水分离器出口的饱和温度。目前,国内的许多学者针对它开展了一系列的研究。罗志浩[2]等人在典型直流炉中间点温度控制特点的研究中,指出直流锅炉的中间点温度过热度对机组过热汽温、水冷壁和过热器金属温度都十分敏感,中间点温度过热度控制的品质直接关系机组的稳定安全运行。方彦君[3]等在基于主蒸汽温度控制系统,建立了锅炉水冷壁部分的物理模型,根据守恒定律,测试了其在不同运行工况下的中间点温度机理模型的性能。袁淑娟[4]等以超临界直流锅炉为研究对象,分析了给水量和燃料量与锅炉中间点温度的关系,建立了中间点温度非线性离散模型,并进行控制系统设计,证明了该控制系统在适应变工况运行的同时,能够实现中间点温度稳定的控制目的,能实时响应负荷变化。钟治琨[5]从锅炉的分布参数和多变量密切耦合的特性角度为出发点,建立了自我组织的模糊神经网络的方法来模拟中间点温度控制系统,并且在水煤比发生变化的情况下很好地反映了中间点的温度动态。
上述文献虽有对中间点温度的研究,但是他们只注重从机理方面研究中间点温度与各种锅炉工况之间的联系,并没有实际地去研究如何去预测中间点温度的值。本文采集了某电厂DCS历史数据,建立了基于PCA降维技术的随机森林模型,并通过仿真实验验证了模型的有效性。
1 预测模型介绍
1.1 PCA降维技术的原理
所谓的数据降维是对原始的高维特征数据进行映射,有选择地得到一些重要的特征,实现数据从高维到低维的转化。常见的降维方法有:独立成分分析(ICA)[6]、奇异值分解(SVD)[7]、因子分析法[8]、等距特征映射(ISOMAP)[9]。
本文采用的PCA(主成分分析)是一种线性组合的算法,用少数新变量去代替原来变量,使得到降维后的新特征尽可能多地去包含原来特征的信息,去除原来特征中重复的一部分信息。
假设数据样本集中的样本数有m个,其中单个样本的维度是n维。
其实现步骤如下:


2)计算样本的协方差矩阵:

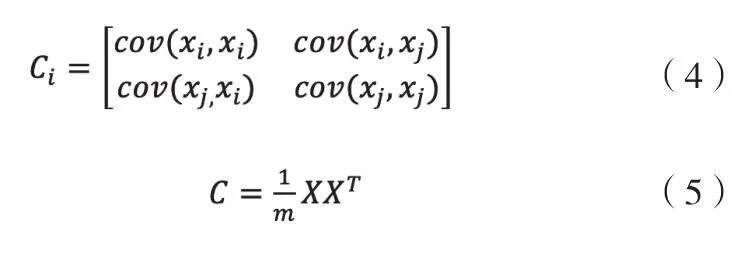
3)求协方差矩阵C的特征值和相对应的特征向量
根据式(6)求协方差矩阵的特征值和特征向量:

让计算好的λ从大到小进行排列,将得到的特征向量按λ的顺序进行排列。
4)通过3)得到特征向量组成的矩阵,利用其对原始数据进行降维操作,得到降维后的新数据集:

5)通过4)得到的新的数据集,然后一一计算其所包含某个特征的信息贡献率和累计信息贡献率。
信息贡献率计算公式如下:

前k个特征的累计方差贡献率如下:

根据公式(9)计算得到的累计方差贡献率总和,当其贡献值达到90%以上时,就选择它所包含的部分特征代替原来的几个特征进行分析。
1.2 随机森林RF模型的构建
随机森林算法最早是由美国统计学家Leo Breiman[10]在2001年提出的,他将Bagging集成学习理论[11]与随机子空间方法[12]相结合,提出一种机器学习算法。RF是以决策树为基本分类器的一个集成学习模型。集成学习是将单个分类器聚集起来,通过对每个基本分类器的分类结果进行组合,来决定待分类样本的归属类别[13]。其模型示意图如图1所示。
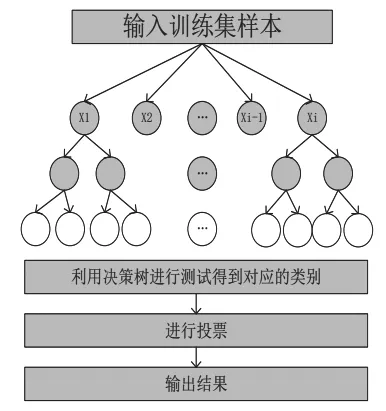
图1 随机森林模型示意图Fig.1 Schematic diagram of random forest model
随机森林模型构建步骤如下:
不防设样本的特征个数为n,其中m为n的子特征(0<m ≤ n)。
1)利用随机森林中重采样方法(Bootstrap),从原始数据集中进行有放回的采样,生成一个样本数为T的训练集 :b1,b2,b3,......,bT。
2)利用第1步得到训练集,生成与其对应的决策树:T1,T2,......Tn,在其生成的对应的决策树的非叶子节点上选择特征前,从n个特征中随机抽取m个特征作为分裂的起始点,并且以这m中最好的生长方向为分裂的最佳方向。
3)在第2步完成以后,让得到的决策树都自由地生长,生长结束以后传入样本的测试集X,利用生长好的决策树一一进行测试,得到相应的类别。
4)将第3步得到的决策树采用投票的方法,把其中输出最多的作为其类别。
1.3 PCA-随机森林架构(见图2)

图2 PCA-随机森林架构Fig.2 PCA Random forest architecture
2 对实验数据进行处理
本实验采用的数据来源于华北地区某电场,数据采集是通过DCS系统导出来的实测数据,测量的数据种类包括:燃料量、给水流量、三级过热器出口烟气温度1、三级过热蒸汽烟气温度2、主蒸汽压力、主蒸汽温度、中间点温度。其中,这些采集到的数据都是带双引号的文本格式,不能直接根据需要对其进行处理,得到正常的计算机可以识别的格式。
由于采集的数据量纲不一样,量纲的不同会导致计算结果的不同,尺度大的特征在计算中往往起决定作用,而尺度小的特征在计算中往往会被忽略。因此,为了消除特征尺度的差异,所以需要对其数据做归一化处理。其归一化公式如式(10)所示:
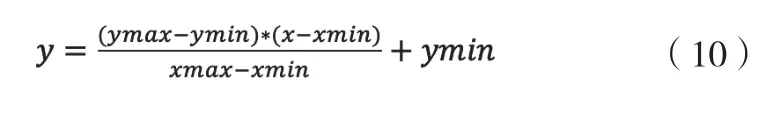
对采集的数据处理完成后,如果直接选用8个影响因素建立预测模型,容易导致模型训练时出现过拟合。因此,需要通过PCA算法删除样本中冗余的部分,采用PCA进行分析,将其分析得到的贡献率利用排序工具让其从大到小进行排序,如图3所示。
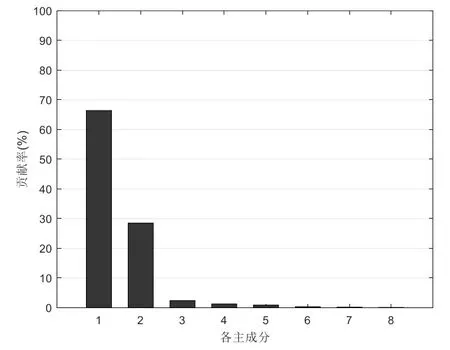
图3 各主成分的贡献率Fig.3 Contribution rate of principal components
从图3和表1可以看出,前3个特征的累积方差贡献率达到了95%,可以用前2个特征来代替原始数据集,用BP神经网络和随机森林对降维后的数据进行训练和预测。

表1 各主成分贡献率的值Table 1 Values of contribution rate of principal components
3 预测结果与分析
通过PCA降维技术选用燃料量、给水流量两个特征和选用数据集的前1900个数据组成原始数据集,对RF(随机森林)和BP神经网络进行训练和预测。其中,BP神经网络的训练模型参数设定见表2。

表2 BP神经网络的参数设定Table 2 Parameter setting of BP neural network
从图4、图5和表3可知,在一定的误差范围内,即417<range<419.5时,在100个样本中,PCA-BP的预测个数为51个,PCA-RF的个数为78个,通过公式:
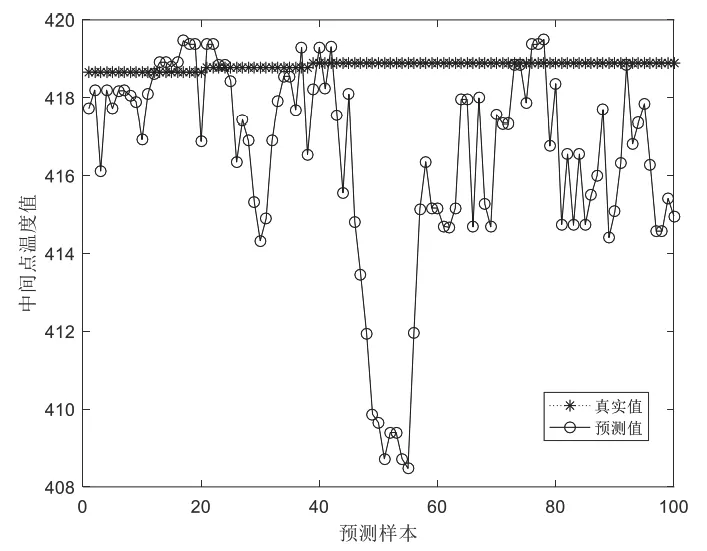
图4 BP神经网络的预测结果Fig.4 Prediction results of BP neural network
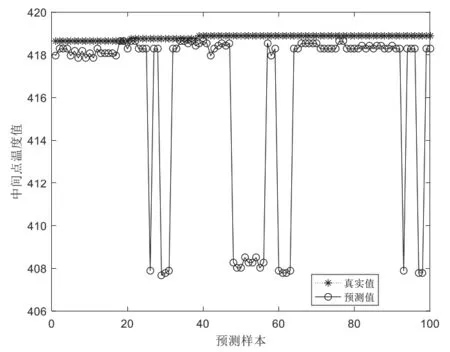
图5 PCA-RF的预测结果Fig.5 Prediction results of PCA-RF

表3 在一定的误差下预测正确率Table 3 Prediction accuracy under certain error

基于PCA降维算法随机森林的正确率大于基于PCA降维算法的BP神经网络的正确率,且是预测正确的样本里其单个元素的误差大部分都小于BP神经网络正确样本的单个元素。同时比没有采用PCA降维算法的随机森林相比,运行时间提高了0.2 s。
4 结论
为了实现对中间点温度进行有效的预测,本文提出了一种基于PCA-RF模型:
1)根据DCS系统采集的历史数据,结合数据的特点引入了PCA降维算法,剔除了数据中影响较小的部分。
2)随机森林与其它算法相比较,有着较好的拟合能力,可以对数据进行预测。
3)通过仿真实验发现,该RF模型与BP神经网络相比较拟合能力有进一步的提高,同时该模型的预测准确率比BP神经网络有很大提高,进一步说明该模型具有一定的应用潜力。
