基于粗粒度数据流架构的稀疏卷积神经网络加速
2021-07-23吴欣欣李文明范东睿
吴欣欣 欧 焱 李文明 王 达 张 浩 范东睿
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
2(中国科学院计算技术研究所 北京 100190)
3(中国科学院大学计算机科学与技术学院 北京 100049)
由于严格的计算、存储、能耗等资源的限制,领域专用加速器[1-2]成为CPU和GPU的可替代方案.随着应用的不断发展,卷积神经网络(convolutional neural network, CNN)模型也随之变得庞大和复杂.例如Alexnet[3]和VGG16[4]中分别包含6 000万、1.38亿个参数.庞大的参数对加速器的计算、访存产生沉重的负担.为有效缓解这些问题,提出了很多减少模型参数的方法,如剪枝[5]、低秩分解[6]等.这些方法利用模型参数的冗余特性[7]将密集网络变成稀疏网络.由于CPU和GPU处理稀疏网络效率很低,近年来出现了许多领域专用的稀疏网络加速器[8-13],它们能够充分发挥稀疏网络计算和存储的优势从而实现高能效.
然而由于算法和结构的强耦合性,这些领域专用加速器牺牲了灵活的结构特性,这使它们很难应用新的算法.例如Dadiannao[14]加速器由于没有稀疏支持所以不能加速稀疏网络.Cnvlution[8]则是完全修改Dadiannao的结构以实现对稀疏网络的支持.SCNN[9],EIE[10],ESE[11]等加速器在很好地支持了稀疏网络后却不支持密集网络.
粗粒度数据流架构通过灵活的指令调度实现不同的应用.其在大数据、科学计算[15]、神经网络[16]等领域的应用中表现出良好的灵活性、性能和能效优势.粗粒度数据流架构由相对简单的控制电路组成处理单元阵列,阵列之间可以直接通信,从而避免了对内存的频繁访问.基于一种类数据流执行模型——Codelet执行模型[17],应用程序被编译器编译为Codelet有向图(Codelet directed graph, CDG)映射在处理单元阵列中.在CDG中,Codelet由指令组成,有向边则表示Codelet之间的数据依赖性.当Codelet中所需的数据和资源都满足时,Codelet就会被触发执行,这种执行模式最大程度地提高了Codelet指令级并行性和数据级并行性.本文基于粗粒度数据流架构,通过研究稀疏网络中权值的数据特征及指令特征,优化网络映射和执行方式,最大程度地提高结构效益.
在粗粒度数据流架构中,处理单元阵列运行时首先经过初始化将CDG中的Codelet指令从内存加载至处理单元阵列的指令缓存区中.当某个Codelet所需的条件满足后,内部的指令逐条被发射执行.对于CNN的密集卷积层,每个通道的卷积操作以CDG图的形式映射到处理单元阵列上.由于规则的计算特性,不同通道形成的CDG图内的Codelet指令是相同的,所以Codelet指令只需加载一次即可在所有通道中实现卷积运算.
然而,当处理单元阵列执行使用剪枝方法如文献[5]获得的稀疏网络时,会产生2个问题:1)现有的逐条执行指令方式使得权值中存在的0值相关指令无法自动跳过,从而产生了无效的计算,浪费了计算资源.2)当稀疏网络被映射在处理单元阵列上时,由于不规则的结构特性,造成非0权值相关指令分布不均衡的现象.它们都增加了网络的执行时间,阻碍了网络性能的提升.
基于这2个问题,本文基于粗粒度数据流架构分别使用2种策略解决它们并实现稀疏网络的加速.本文的贡献有3个方面:
1) 通过分析稀疏网络中卷积层权值的数据特征和指令特征,根据数据特征生成相应指令的控制信息,然后在每个处理单元内增加指令控制单元并根据指令的控制信息检测并跳过0值相关的无效指令,从而去除无效数据运算.
2) 通过分析现有的指令映射和执行方式,并根据稀疏权值的数据特征,设计了适用于稀疏卷积网络的负载均衡的指令映射算法,从而保证了处理单元阵列的负载均衡.
3) 通过对这些方法实施Benchmark,本文实现的稀疏卷积层比密集卷积层具有平均1.55倍的性能提升以及63.77%的能耗减少.同时与GPU(cuSparse)相比,Alexnet和VGG16网络分别获得2.39倍和2.28倍的性能提升.与Cambricon-X相比,分别获得1.14倍和1.23倍的性能提升.
1 相关研究
稀疏卷积神经网络的出现有效地缓解了硬件资源的需求.为了充分利用稀疏网络在存储、计算方面的优势,出现了很多加速稀疏网络的专用加速器.这些专用神经网络加速器利用稀疏网络中激活和/或权值数据的稀疏特征,通过不传输0值数据或使用数据选择模块以跳过0值数据从而消除0值计算,最终实现稀疏网络的加速.
EIE[10]利用稀疏网络中权值稀疏和激活稀疏,结合权值共享的压缩方法设计了稀疏矩阵向量乘单元,仅将非0操作数传给运算单元.然而它只加速了全连接层,未对卷积层实现加速.Eyeriss[18]基于最小化数据移动功耗的数据流模型,实现了卷积运算中的所有数据的复用,同时还通过门控逻辑检测激活数据中的0值并跳过它实现了加速器的节能效果.然而它仅具有节能效果而没有加速效果,同时也不能对权值稀疏的网络进行加速.为了实现稀疏加速,Cnvlutin[8]完全修改Dadiannao[14]的微结构,解耦了Dadiannao的多运算通道,并利用激活稀疏,仅传递非0激活值给运算单元,实现了卷积层的加速.但是它却没有利用权值的稀疏.这些加速器或者加速了全连接层(如EIE),或者利用了激活的稀疏性实现了节能(Eyeriss)和卷积层的加速(Cnvlutin),而没有实现卷积层加速或者利用权值稀疏性实现卷积层的加速.
Cambricon-X[12]利用权值的稀疏性,设计了数据选择硬件模块实现了非0数据的筛选,加速了卷积层和全连接层.Cambricon-S[13]使用软硬件协同设计,在软件层面实现粗粒度的剪枝方法消除网络的不规则性,在硬件层面设计神经元和突触的选择单元,实现卷积层和全连接层的加速.SCNN[9]基于笛卡儿乘积,对卷积层和全连接层的稀疏权值和激活进行加速.虽然这些专用加速器都取得了很好的性能和功耗,但是由于算法和结构的强耦合特性,它们丧失了灵活性而无法适用新的算法.与这些加速器对比,数据流体系结构提供了更高的灵活性和更广的应用范围.针对不同的应用特点,它可以用于数据中心实现FFT,Stencil等高性能应用[19],也可以用于实现神经网络的加速[20].
文本基于粗粒度数据流架构,其通过灵活的指令调度可以有效支持不同的应用,同时依据应用的特点充分利用其指令和数据的并行性.
2 背 景
2.1 粗粒度数据流架构
数据流架构分为细粒度数据流架构和粗粒度数据流架构.在处理单元阵列之间2种数据流架构都使用由操作数驱动的数据流执行模式,即一旦指令所需的操作数可用,则指令被允许执行[21].而在处理单元内部,细粒度数据流仍使用数据流执行模式,如TRIPS[22],WaveScalar[23].粗粒度数据流则使用控制流执行模式,即使用程序控制器(program counter, PC)执行指令,例如TERAFLUX[24],Runnemede[25].与细粒度数据流相比,粗粒度数据流具有控制流易编译和数据流并行性的优点,所以本文的研究基于粗粒度数据流架构.
图1是一个实例化的粗粒度数据流加速器(dataflow processing unit, DPU),它由微控制器(micro controller, MicC)、处理单元(processing element, PE)阵列和片上网络(network on chip, NoC)组成.微控制器MicC和PE阵列通过2D Mesh网络相互通信.而在PE内部,主要由流水执行单元(pipeline execution unit)、Codelet选择控制器(codelet choosing controller)、指令缓冲(instruction buffer)、数据缓冲(operand buffer)以及Codelet状态寄存器(codelet status register)组成.
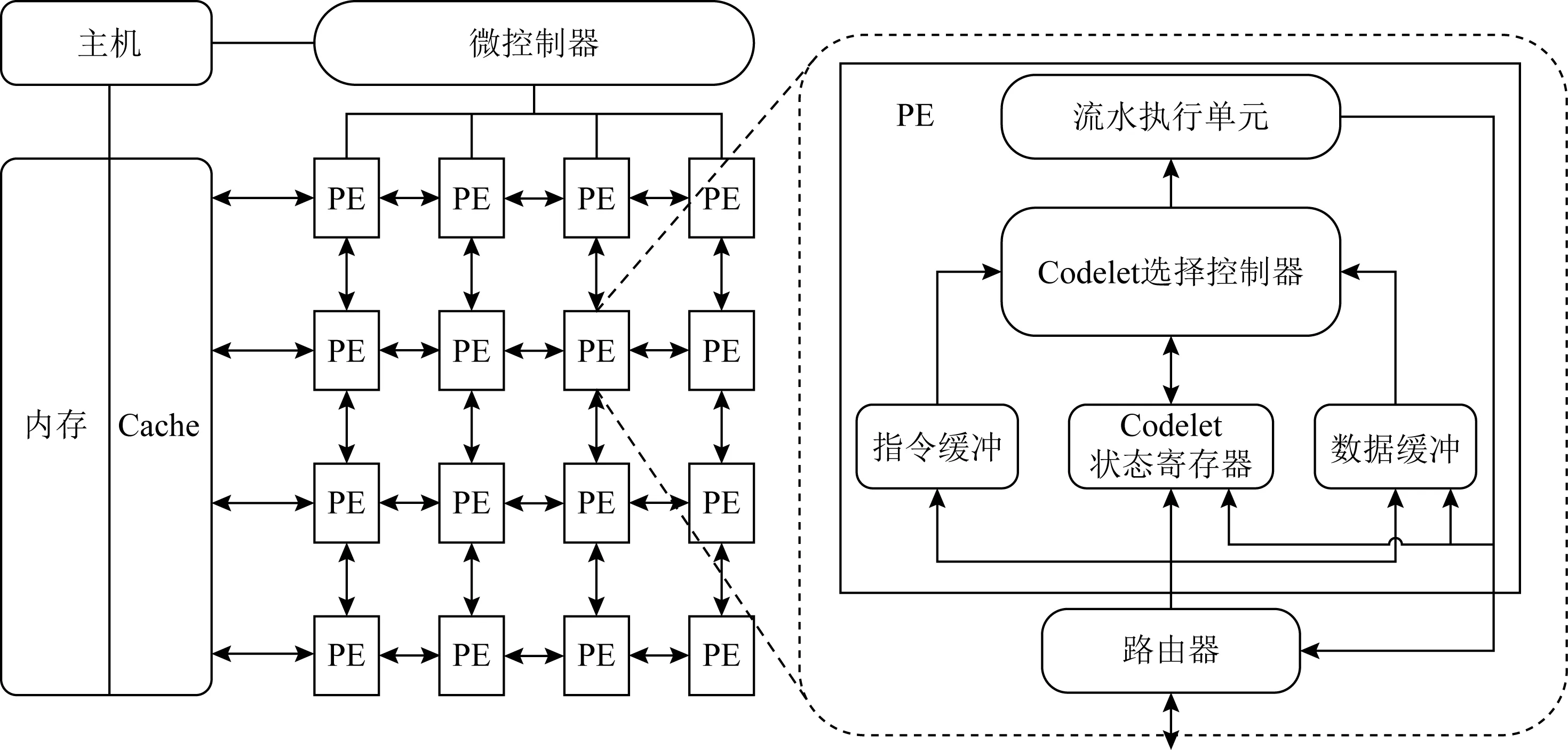
Fig. 1 Structure of the coarse-grained dataflow accelerator图1 粗粒度数据流加速器的结构
MicC管理PE阵列的执行过程,并且还负责与主机(host)进行通信.当主机向MicC发送启动信号时,MicC启动PE阵列,PE阵列完成初始化工作,即将内存(memory)中的Codelet指令加载至PE的指令缓冲区中,PE阵列执行时根据Codelet状态寄存器选择就绪的Codelet,并从指令缓冲区中获取所选的Codelet指令,送入流水执行单元逐条执行指令.当PE阵列执行结束后,MicC还会收集PE的执行信息,并向主机发送结束信息.
为了实现PE内计算单元的高利用率,应用被编译成Codelet模型.Codelet模型是一种类数据流并行执行模型[17].基于该模型,所有程序被编译成多个Codelet,每个Codelet内部由一系列指令组成,所有的Codelet根据数据依赖性被连接成Codelet图,然后被映射在PE阵列中,如图2所示.当1个Codelet所需的数据和资源满足后,就可以被发射和执行.基于Codelet的执行模式最大化Codelet级指令并行和数据级并行.
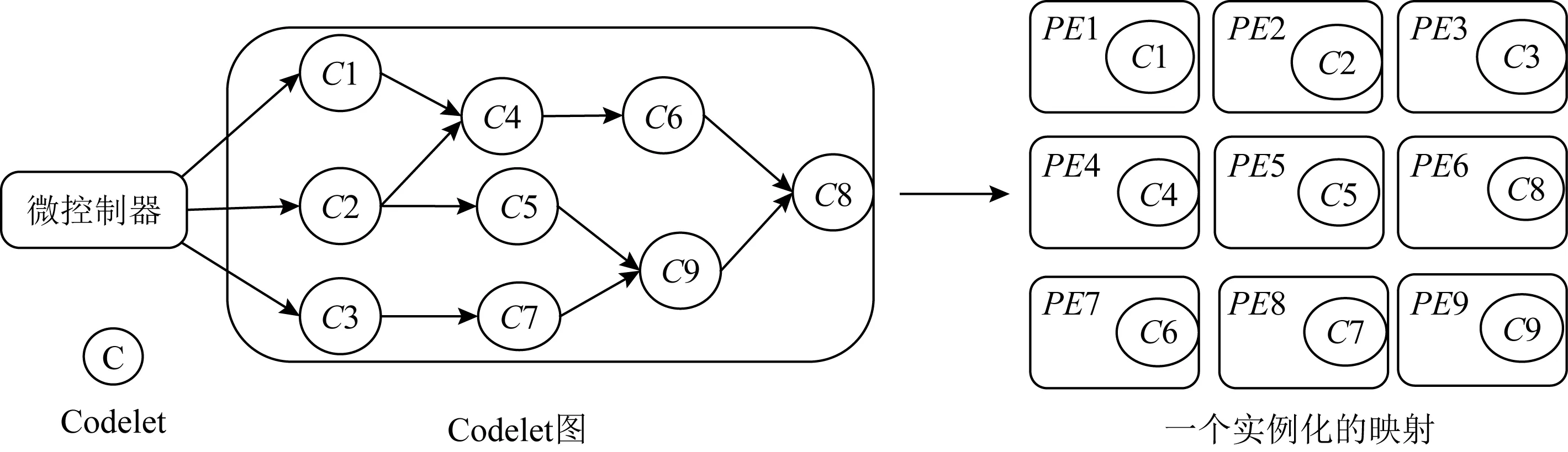
Fig. 2 Codelet graph and mapping图2 Codelet图和映射
DPU的指令格式如图3所示,每条指令由指令码、源操作数索引、目的操作数索引组成.DPU指令包含了基本的运算指令(Add,Sub,Mul,Madd)、访存指令(Load,Store)以及PE之间直接通信指令(Copy).

Fig. 3 Instruction format图3 指令格式
2.2 卷积神经网络
CNN主要由多个卷积层组成,它们占据整个网络处理的约85%的计算时间[26],这些卷积层执行高维的卷积计算.卷积层在输入特征图(input feature map, Ifmap)上应用滤波器(Filter)以生成输出特征图(onput feature map, Ofmap).卷积层的输入数据由1组2D输入特征图组成,每个特征图称为1个通道(channel),多个通道的输入组成1个输入批次(batch),每个通道的特征值都与1个不同的2D滤波器进行卷积运算,所有通道上的每个点的卷积结果相加得到1个通道的Ofmap.表1显示了卷积层运算的参数描述,卷积层的计算:
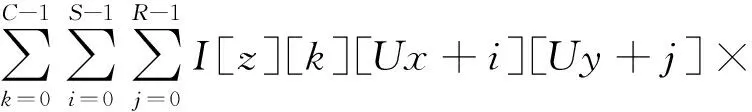
(1)

Table 1 Network for Different Pruning Methods表1 卷积层参数描述
基于Codelet模型,卷积层的每个通道运算以CDG图的形式被映射到PE阵列中顺序执行.每个通道相同的执行方式使得它们共用1套Codelet指令,如图4展示了2个通道执行1次卷积操作需要的指令.
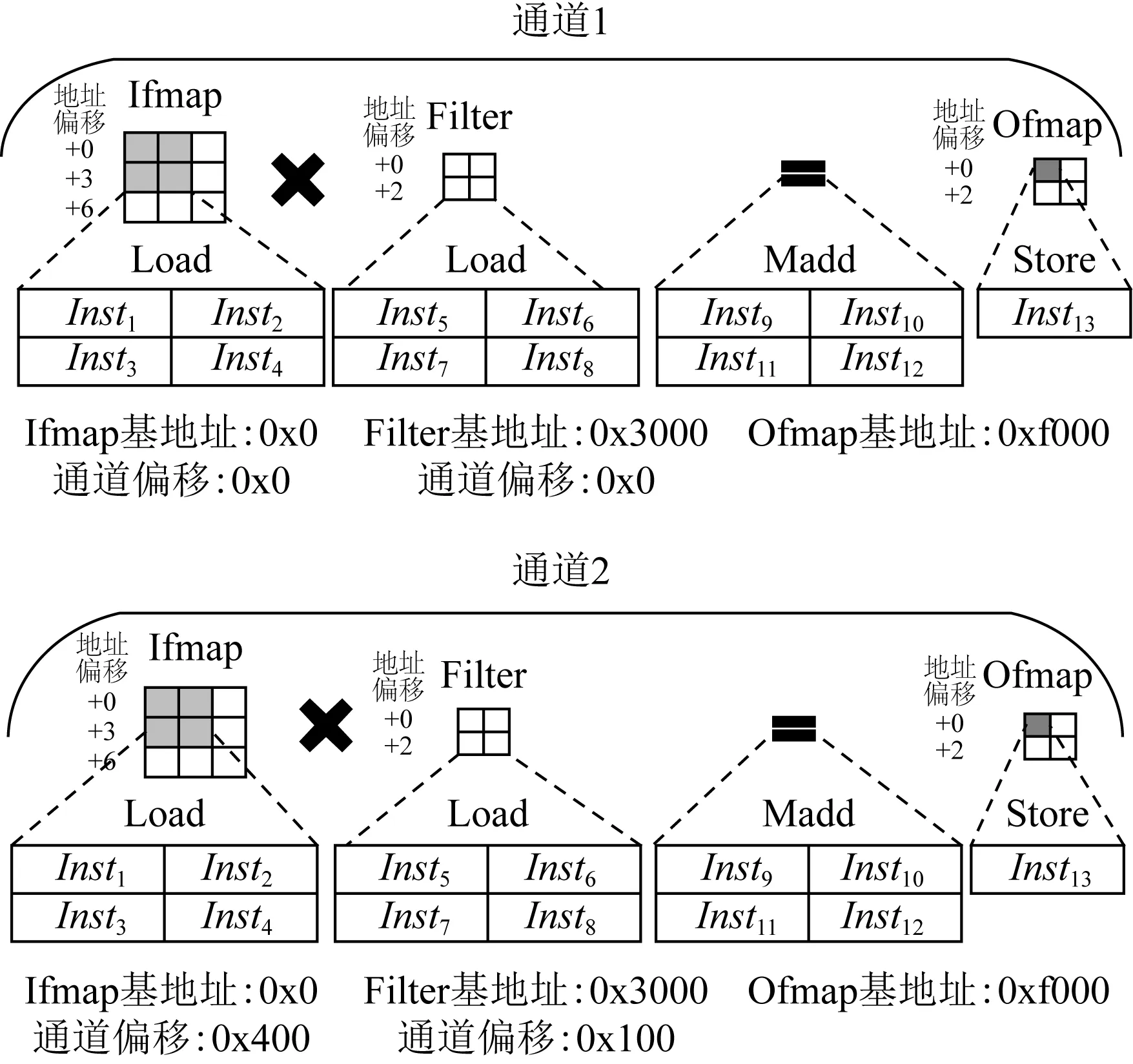
Fig. 4 Convolution instructions for two channels图4 2个通道的卷积运算指令
结合图3的指令格式和卷积的计算式(1),在通道1中,Ifmap需要4个Load指令(Inst1到Inst4),它们具有相同的基地址(0x0),不同的地址偏移量(分别为0,1,3,4)和不同的操作数索引index0(分别用I0,I1,I2,I3表示).滤波器Filter也需要4个Load指令(Inst5到Inst8),它们也具有相同的基址(0x3000),不同的地址偏移量(分别为0,1,2,3)和不同的操作数索引index0(分别用W0,W1,W2,W3表示).执行乘法累加运算需要4个Madd指令(Inst9到Inst12),它们具有相同的操作数索引index2(O0),不同的操作数索引index0(分别为I0,I1,I2,I3)和不同的操作数索引index1(分别为W0,W1,W2,W3).卷积计算完成后,需要Store指令(Inst13)来存储Ofmap值.与通道1相比,通道2通过使用不同的数据执行相同的卷积运算,该数据由通道偏移量、指令中的地址偏移量和基址索引index0获得.对于每个通道相同位置的数据,其通道偏移量不同(Ifmap分别为0x0,0x400,滤波器Filter分别为0x0,0x100),但是由于操作数索引index0,地址偏移量以及基地址索引是相同的,所以它们的指令也是相同的.例如,2个通道的Inst1指令的基地址、地址偏移和操作数index0分别为0x0,0,I0.因此,只需要从内存加载1次指令,卷积操作就可以持续执行,从而确保了PE阵列计算资源的充分利用.
于此同时,为了减少内存访问,节省数据移动能耗,需要充分利用数据复用的特性[18].在PE阵列中,每个PE内可实现卷积复用,PE之间可通过Copy指令实现Ifmap和Filter复用.图5显示了在6个PE中实现1个Ifmap与2个Filter的卷积操作,在图5中,PE1,PE3,PE5使用相同的滤波器Filter1与Ifmap的不同行执行卷积操作得到Ofmap1的不同行.同样地,PE2,PE4,PE6使用相同的滤波器Filter2与Ifmap的不同行执行卷积操作得到Ofmap2的不同行.由于它们使用了同一个Ifmap,所以在PE之间还可以复用Ifmap.在每个PE内部滤波器以滑动窗口形式应用在Ifmap上计算Ofmap一行的所有值.不同数据的复用减少了内存访问,节省了数据移动能耗.
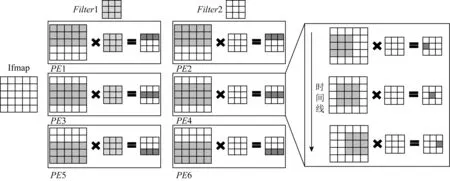
Fig. 5 Data reuse opportunities in PE arrays图5 PE阵列中存在的数据复用机会
由于大模型CNN对硬件资源的挑战,研究人员提出许多压缩CNN模型的方法(例如,剪枝[5]、低秩[6]、短位宽[27]),这些方法极大地减小了模型大小,且对结果精度不产损失或者仅有轻微的损失.这其中,使用修剪方法生成的稀疏网络是有效的方法之一.先进的剪枝方法[5]通过训练—剪枝—再训练的步骤分别将Alexnet和VGG16的网络参数减少到原来的11%和7%.
3 稀疏卷积神经网络指令执行分析
3.1 存在无效指令
在稀疏卷积神经网络中,剪枝操作将网络中的一些权值置为0.基于Codelet模型,DPU编译器将每个卷积层应用编译为CDG图映射在PE阵列中,于是在Codelet中存在与0值相关的指令.由于卷积神经网络主要为乘加运算,而0乘任何数都为0,所以稀疏卷积的运算中存在0值相关指令的加载和执行以及0值数据的加载和计算,这些可以被认为是无效数据的指令和数据.执行无效的指令和数据不仅占用了加速器的硬件资源,造成资源浪费的同时还造成加速器的功耗的增加以及PE阵列执行时间延长.
图6展示的是1个PE内执行1次卷积运算所需的指令,可以看到为了得到Ofmap的1个值,Ifmap的I0到I8以及Filter的W0到W8需要Load指令(Inst1到Inst18)将数据从内存加载至PE中,接着还需要Madd指令(Inst19到Inst27)执行卷积运算.在这些指令中,由于W2,W3,W5,W7的值均为0,所以Inst12,Inst13,Inst15,Inst17为无效的Load指令,相应的Madd指令Inst21,Inst22,Inst24,Inst26也为无效的指令.为了去除0值数据的加载和计算,需要消除与0值有关的指令.然而在PE阵列中,Codelet内指令逐条执行的方式无法跳过这些无效指令,从而使它们占用了PE阵列的计算资源,造成计算资源的浪费,也不能加速稀疏网络的执行过程.
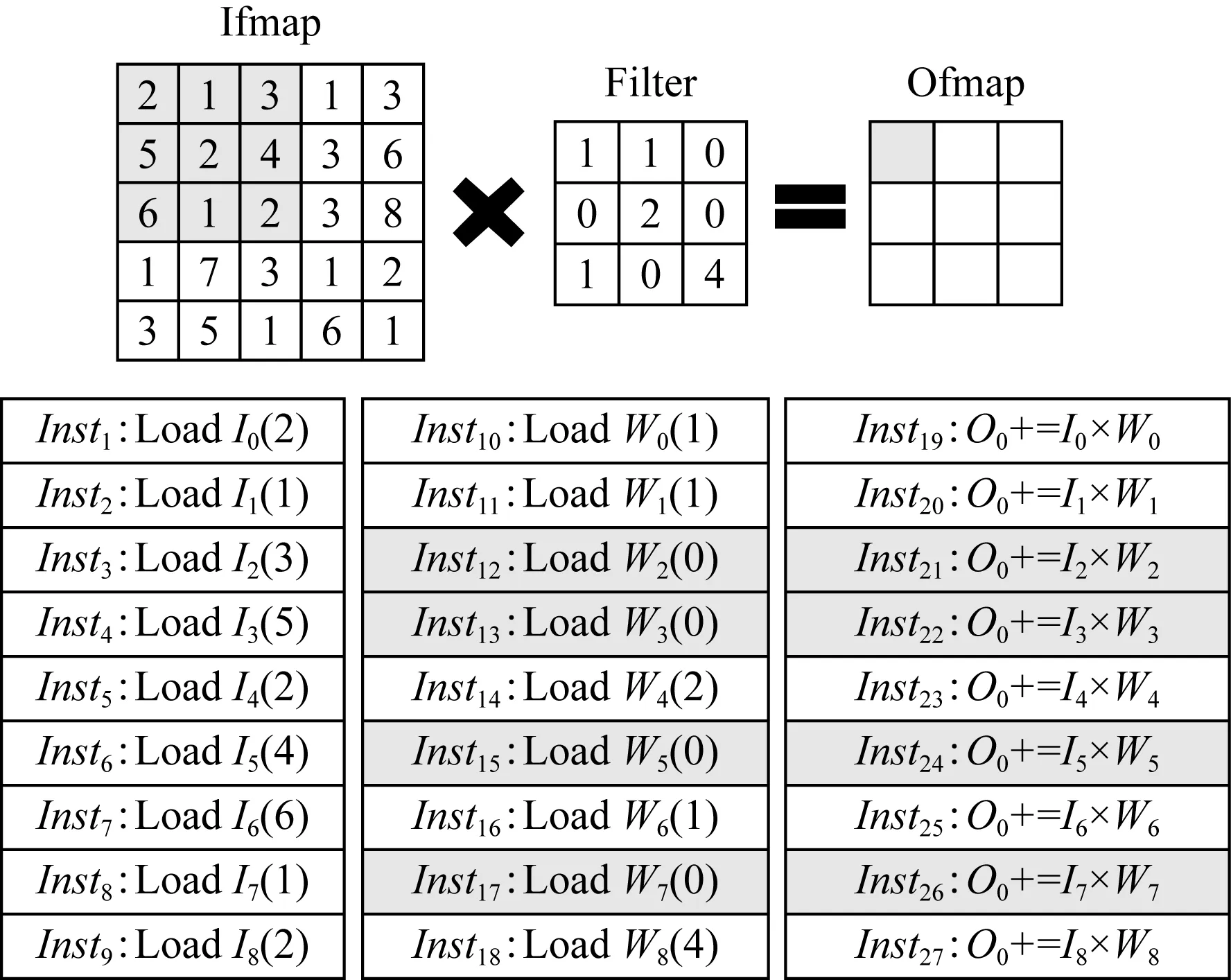
Fig. 6 Instructions for calculating an output value图6 计算一个输出值需要的指令
如果在编译阶段只生成有效指令,则可以去除无效指令的执行.然而,由于剪枝操作造成稀疏网络不规则的运算特性,使得每个通道的Codelet指令不再相同,从而使它们无法使用同一套指令,于是PE阵列在执行不同通道的运算时需要重新从内存加载指令,而指令的加载会造成PE阵列空闲,极大地延长了卷积的执行时间.图7展示了Alexnet(Conv 2到Conv 5)和VGG16(Conv 1_2到Conv 5_3)两个网络密集卷积和稀疏卷积的初始化时间和执行时间占比.从图7可以看到,对于密集网络,初始化时间即指令加载时间仅占总时间的1%,基本可以忽略不计.而对于稀疏网络,可以看到PE阵列的执行时间明显减少了,但是由于指令加载时间很长导致稀疏网络的总时间比密集网络还长,所以这种策略无法加速稀疏卷积网络.
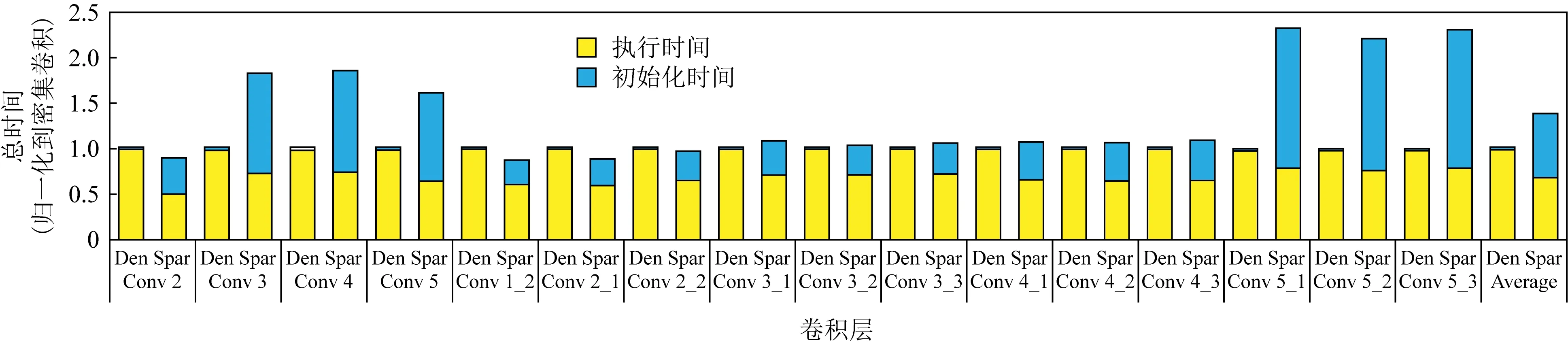
Fig. 7 Comparison of time between dense convolution and sparse convolution图7 密集卷积和稀疏卷积的时间对比
由于在粗粒度数据流架构中,每个PE内是控制流的执行模式,即通过PC方式获取Codelet内的每条指令,因此可以增加指令控制结构以使PE阵列在运行过程中检测0值相关指令并跳过它们,从而消除0值相关的操作.
3.2 指令执行不均衡
在消除0值相关指令后,使用Han等人[5]的剪枝方法获得的稀疏网络,当网络映射在PE阵列上时存在非0值相关指令分布不均衡的问题.负载的不均衡导致硬件资源利用率降低和性能下降.如图8所示,2个PE分别被映射2个剪枝后的滤波器Filter.由于剪枝操作,每个Filter中的非0权值个数不同,导致它们有效指令数不再相同.图8中PE1和PE2分别有10个,7个非0值,由于一个权值相关的指令有Load,Madd,Copy指令,如果只执行1次卷积运算(如图6所示),PE1和PE2中与Filter相关的有效指令分别为30条(10条Load指令,10条Madd指令和10条Copy指令)和21条(7条Load指令,7条Madd指令和7条Copy指令).假设一条Load,一条Madd和一条Copy指令分别需要1个cycle,2个cycle,1个cycle的执行时间,则PE1和PE2分别需要40个cycle和28个cycle.显然PE1比PE2的计算忙碌,阻碍了整体性能的提升.为了利用稀疏网络的计算和存储优势,稀疏网络需要被有效的处理.

Fig. 8 Filters with different numbers of non-zero values mapped in PE图8 PE中映射的非0值个数不同的Filter
4 稀疏卷积网络加速策略
为维持指令只初始化1次,即只从内存加载1次Codelet指令,同时也要消除Codelet中的无效指令,即0值相关的指令.本文在每个PE内部增加了指令控制器用于对即将执行的Codelet指令进行指令筛选,仅把有效指令传输给PE内的流水执行单元,免去无效指令的执行从而消除无效数据的加载和运算.然而控制单元对指令的筛选需要依赖指令标记信息,根据指令标记信息表征指令是否有效,从而实现筛选的目标.
4.1 指令标记信息的生成
基于卷积神经网络中滤波器Filter的静态特性,即每个卷积层的权值不随输入的变化而变化,所以在每个卷积层被编译器编译成CDG图时,可以根据指令所需的数据特征生成指令标记信息以标记指令是否有效,这些标记信息使用1和0分别表示指令的有效和无效.在PE阵列执行Codelet的指令时,MicC会将该Codelet内的指令标记信息通过2D Mesh网络传输给PE,PE内部的PC根据该标记信息跳过无效指令.图9(a)为1个PE内5×5的Ifmap与3×3的Filter生成1个Ofmap结果的卷积执行过程.在图中,这些相应的指令被加载至PE中,在此次卷积运算中,参与运算的Ifmap的指令标记信息全为1,参与运算的Filter值分别为1,1,0,0,2,0,1,0,4,则其对应的Load指令和Copy指令的标记信息(Filter_flag)为1,1,0,0,1,0,1,0,1.当执行乘加运算时,乘加运算的指令标记信息为Ifmap与Filter对应位置的标记信息的与操作,而由于Ifmap的指令标记信息全为1,所以乘加运算的指令标记信息与Filter的相同,即为1,1,0,0,1,0,1,0,1.最后PE根据这些指令标记信息选择执行或者不执行指令,实现无效指令的跳过.

Fig. 9 Execution flow chart of instruction control unit图9 指令控制单元的执行流程图
4.2 指令控制单元
图9(b)为指令控制单元对Codelet中指令的筛选过程,它通过计算指令标记信息Flag中的2个1之间的距离,得到2条有效指令的间隔,当前PC与该间隔相加获取下一条有效指令的PC值,以使PC自动跳转至有效指令位置,从而跳过无效指令.在流程图中,参数i记录待检测的指令与当前PC所指的指令之间的间隔,Flag_id表示Codelet中的指令对应的标记信息的索引,指令控制单元对指令标记信息逐条检测,直到检测到某条指令标记信息为1或者所有的指令标记信息检测结束,则流程结束.
图9(c)为Codelet指令(对应图9(a)的Codelet指令)经过指令控制单元后最终执行的有效指令,其中Flag为Codelet的指令标记信息,它与Codelet指令一一对应.刚开始,Inst1的Flag值为1,所以PC指向Inst1以执行Inst1指令,执行结束后,PC自动加1指向Inst2,由于Inst2的Flag也为1,所以PC仍指向Inst2并执行.如此执行,直到Inst11执行结束,PC自动加1指向Inst12,因为Inst12的Flag为0,所以指令控制单元中的i和Flag_id均加1以检测Inst13指令的有效性,而Inst13的Flag仍为0,i和Flag_id继续加1,此时Inst14的Flag为1,所以PC更新为PC+2,检测结束,PC跳转到Inst14处执行.之后指令控制单元继续执行直到Codelet中的指令检测完.所以最终PE执行的有效指令为Inst1到Inst11,Inst14,Inst16,Inst18到Inst20,Inst23,Inst25,Inst27.
4.3 负载均衡的指令映射
基于稀疏网络中计算的不规则性,映射在每个PE的Codelet中的有效指令数不再完全相同.为了保证PE阵列有效指令均匀分布和硬件资源的高利用率,需要使用负载均衡的指令映射算法.先前的工作[19]已经提出了基于数据流的负载均衡的指令映射算法(LBC),它基于每条指令在计算单元阵列中的位置为代价,以最小代价位置为最佳映射位置以保证负载均衡.但是对于Codelet执行模式,Codelet内的指令不能跨多个PE映射,使用该算法只能保证Codelet在PE阵列的均匀分布,而不能保证每个PE中Codelet内的有效指令数相同,所以本文使用新负载均衡的指令映射算法.
根据神经网络的执行方式,水平方向的PE使用了相同的输入特征图Ifmap和不同的滤波器,垂直方向上的PE使用了相同的滤波器,所以在现有的执行方式中,PE中有效指令数的分布不均衡来源于滤波器中非0权值数的不同.本文基于滤波器中的非0权值个数实现负载均衡的有效指令映射.
由于垂直方向的PE复用了相同的滤波器,所以它们之间的有效指令数是相同的,基于此本文将PE阵列按列划分为组.对于每个PE组,它们被映射新的滤波器的优先级依赖于已经存在的滤波器中的非0权值个数,拥有的非0权值数越多,其优先级越低.
图10为3×3的PE阵列上映射6个Filter的结果.根据算法要求,PE阵列按列分为3组,分别为G1,G2,G3.组内PE复用相同的滤波器,初始化阶段,每个PE组的优先级设置为0,Filter1首先被映射到G1后,由于Filter1中非0权值个数为5,所以G1的优先级更新为-5,之后Filter2,Filter3分别被映射在G2和G3中,G2和G3的优先级分别更新为-4,-3.对于Filter4,由于当前所有组中G3具有最高优先级,所以F4被映射在G3中,同时G3的优先级更新为-8,同理,Filter5被映射在G2,Filter6被映射在G1中.直到所有滤波器都被映射,算法结束.通过使用负载均衡的指令映射算法,可以看到每组PE内非0权值数分别为7,8,8.它们对应的有效指令条数基本一致,保证了PE阵列的负载均衡.

Fig. 10 Load balancing instruction mapping图10 负载均衡的指令映射
5 实验和结果
本节在实例化的DPU上实施上述提出的方法,实现对稀疏的Alenet和VGG16卷积层的加速.
5.1 实验平台
本文使用中国科学院计算技术研究所自主研发的大规模并行模拟框架SimICT[28]平台,实现时钟精确型的模拟器DPU,它的结构如图1所示,配置信息如表2所示.同时,还使用Verilog实现DPU的设计以及RTL级仿真,并使用12 nm的工艺进行综合.

Table 2 DPU Structure Configuration Information表2 DPU结构的配置信息
整个加速器的面积为13.82 mm2,单个PE面积为0.14 mm2,在每个PE增加指令控制单元后,PE面积仅增加了6.64%,整个面积增加了4.33%.在执行稀疏网络时,指令控制单元的能耗为总能耗的0.87%,基本可以忽略不计.
在本实验中,DPU由8×8的PE阵列组成,PE之间通过2D Mesh网络连接.每个PE内部含有1个SIMD8模式的16 b乘累加(multiply-accumulate, MAC)单元.同时还配置了8 KB的指令缓存和32 KB的数据缓存.为了提供高的网络带宽,片上网络由多个独立的2D Mesh网络组成.同时在片外还使用了1 MB的Cache提供快速的内存访问.
5.2 基准测试
本文选取了Alexnet和VGG16网络模型中的卷积层作为实验的基准测试(Benchmark),这些卷积层具有不同的参数规模.每层中剩余权值数据的占比如表3所示.基于LLVM平台设计的编译器,每个卷积层被编译为CDG图被映射在PE阵列中.
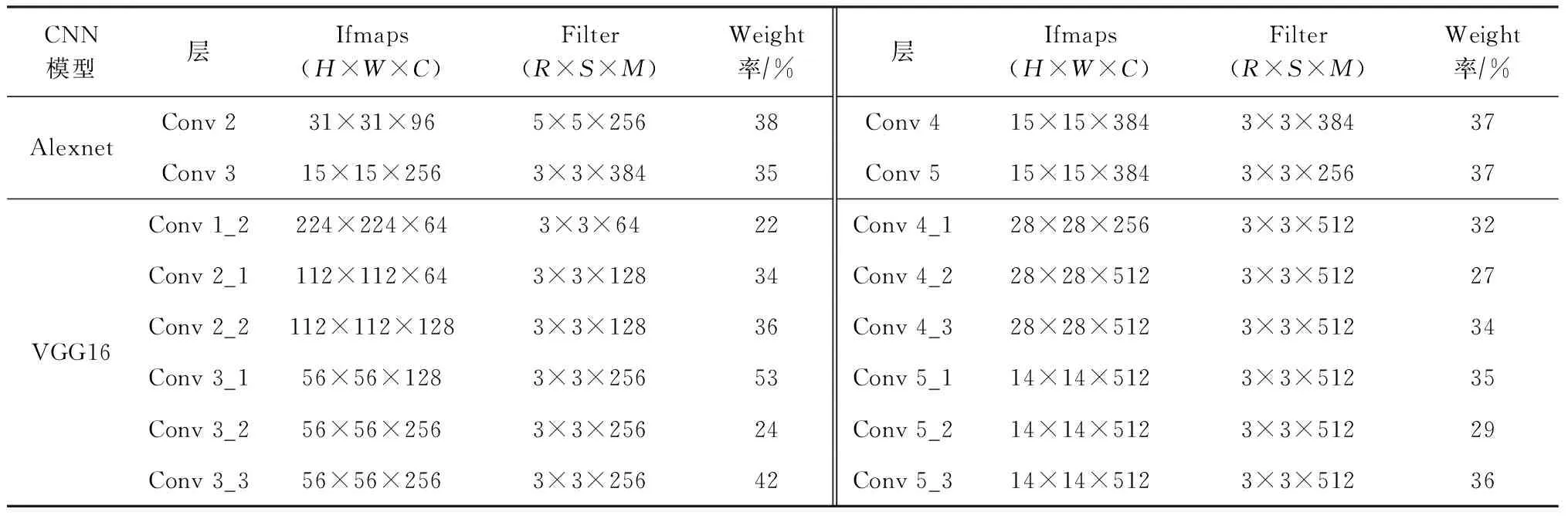
Table 3 Benchmark Configuration Information表3 Benchmark配置信息
5.3 评估标准
通过应用5.2节的Benchmark,本文从不同方面评估了提出的稀疏加速策略.通过与密集网络对比,分别从指令执行次数、性能和能耗方面评估并验证本文提出方法的有效性.同时,本文使用4片DPU实现的稀疏网络与NVIDIA Titan XP GPU和Cambricon-X[12]加速器进行对比,对于GPU分别使用GPU-cuBlas和GPU-cuSparse[29](基于CSR索引)实现密集网络和稀疏网络.而对于负载均衡的指令调度算法,本文使用MAC部件利用率(MAC com-ponent utilization)评估负载均衡映射算法的有效性.

(2)
5.4 结果分析
1) MAC部件利用率
通过使用负载均衡的指令映射算法,保证了PE阵列的负载均衡,图11所示为执行VGG16 Conv 5_1卷积层水平方向的8个PE的MAC部件利用率,由于PE阵列在垂直方向上复用相同的滤波器,所以每列PE具有相同的MAC部件利用率.通过该算法,PE阵列的MAC部件利用率基本保持一致.后续也都是基于该算法实现所有实验.

Fig. 11 MAC resource utilization of Conv 5_1 layer图11 Conv 5_1层的MAC资源利用率
2) 指令执行次数
本文对比了密集卷积层和稀疏卷积层的指令执行次数,从图12中可以看到,由于权值的稀疏性,通过指令控制单元,PE阵列执行时跳过了0值相关指令,使得稀疏卷积层的指令执行次数比密集卷积层平均减少了54.78%,其中Load,Madd,Copy指令执行次数分别减少了3.59%,69.21%,33.74%.在图中,Madd指令的执行次数远远多于Load指令,表明卷积层是计算密集型的运算.Load指令执行次数仅减少3.59%,这因为Load指令的执行包含Ifmap,Filter,Ofmap数据的加载,而Filter数据的占比较小,所以其Load指令的执行次数相比于所有的Load指令的执行,减少的少.
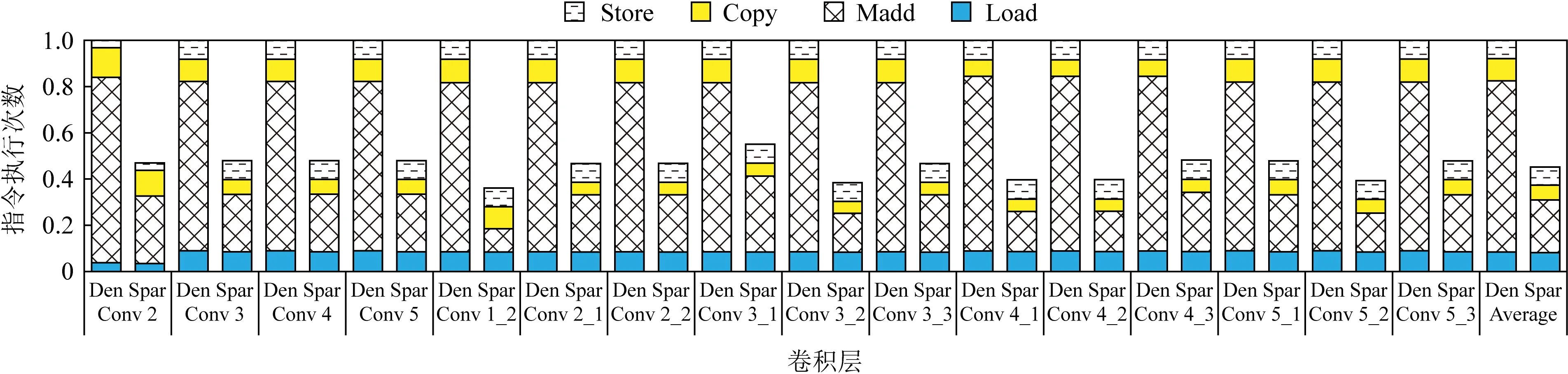
Fig. 12 Comparison of instruction execution times between dense and sparse layers图12 密集层和稀疏层指令执行次数的对比
3) 性能
图13显示了稀疏卷积层的性能,由于神经网络卷积层属于计算密集型层,利用网络的稀疏性去除了无效指令的执行,使总指令执行次数减少,提高了卷积运算的有效性,卷积层平均性能提升了1.55倍.在图中Alexnet的Conv 2层性能提升最多为1.92倍,VGG16的Conv 1_2层的性能提升最少为1.23倍.虽然Conv 1_2层的权值稀疏度最高为78%,但是性能提升却最少,这是因为Conv 1_2层与其他层相比,通道数较少,当通道数越多时,加速器发挥的并行性也会越高.
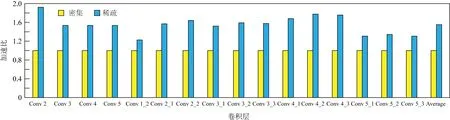
Fig. 13 Performance comparison between dense and sparse layers图13 密集层与稀疏层的性能对比
4) 能耗
图14为执行密集和稀疏卷积层的能耗分解图,可以看到稀疏卷积层能耗平均减少了63.77%,其中乘加部件(MAC)、数据缓存(operand buffer)、指令缓存(instruction buffer)、片上数据传输网络(NoC data transfer)的能耗分别减少了76.38%,68.06%,55.95%,8.68%.相似地,由于Filter数据占比较小,所以对于片上数据的传输能耗也减少的少.

Fig. 14 Energy comparison between dense and sparse layers图14 密集层与稀疏层的能耗对比
5) 与其他加速器比较
图15展示了使用DPU和Cambricon-X实现的稀疏卷积分别相对于GPU基准(cuBLAS和cuSparse)在Alexnet和VGG16网络上获得的平均性能.从中可以看到,对于密集卷积(cuBLAS实现),DPU的性能分别是GPU的1.76倍和1.35倍,Cambricon-X的性能分别是GPU的1.47倍和1.31倍,所以DPU比Cambricon-X的性能分别提高1.19倍和1.03倍.对于稀疏卷积(cuSparse实现),DPU的性能分别是GPU的2.39倍和2.28倍,Cambricon-X的性能分别是GPU的2.08倍和1.85倍,所以DPU的性能比Cambricon-X分别提高1.14倍和1.23倍.实验结果展现了粗粒度数据流架构执行稀疏网络的高性能.
Fig. 15 Speedup of DPU and Cambricon-X over GPU (cuBLAS and Sparse BLAS) baseline图15 DPU和Cambricon-X在GPU(cuBLAS和Sparse BLAS)基准上的加速比
表4列出了DPU,Cambricon-X和GPU的能效对比,可以看到DPU的能效低于Cambricon-X,而DPU的能效是GPU的12.7倍.
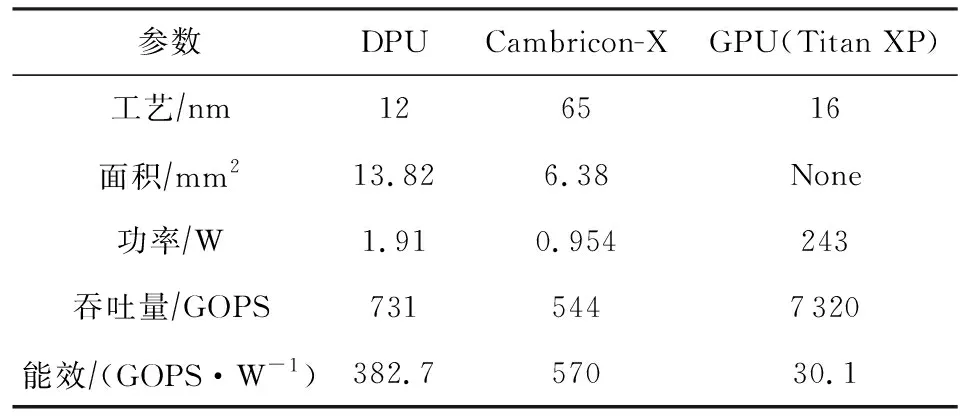
Table 4 Parameter Comparison of DPU, GPU and Cambricon-X表4 DPU,GPU,Cambricon-X的参数对比
7 总 结
本文基于粗粒度数据流架构中指令映射和执行方式,结合卷积神经网络权值数据的特征,设计了指令控制单元去除了卷积运算中无效指令的执行,极大地减少了指令的执行次数,而硬件面积和能耗分别只增加4.3%和0.87%,占比很小.同时还根据卷积中稀疏权值的数据特征设计了负载均衡的指令映射算法,保证了PE阵列有效指令执行的均衡.实验表明,与密集网络相比,本文的方法将稀疏卷积的性能平均提升1.55倍,能耗减少63.77%.与GPU(cuSparse)相比,Alexnet和VGG16网络分别获得2.39倍和2.28倍的性能提升.与Cambricon-X相比,Alexnet和VGG16网络分别获得1.14倍和1.23倍的性能提升.
由于卷积层在整个网络的执行中占据大部分执行时间,所以本文只实现了该层的加速,并没有实现全连接层的加速.虽然全连接的计算可以转化为卷积计算模式,但是现有方法实现对全连接层加速的效果有待验证.未来工作中,将会继续研究稀疏网络的全连接层,对其验证本文的方法,同时利用它的数据和指令特征设计新的指令映射和执行方式实现该层的加速.
