基于全局-时频注意力网络的语音伪造检测
2021-07-23王成龙易江燕陶建华马浩鑫田正坤傅睿博
王成龙 易江燕 陶建华,3 马浩鑫 田正坤 傅睿博
1(中国科学技术大学信息科学技术学院 合肥 230027)
2(模式识别国家重点实验室(中国科学院自动化研究所) 北京 100080)
3(中国科学院大学人工智能学院 北京 100049)
自动说话人验证(automatic speaker verification, ASV)[1-3]是指通过分析说话人的语音来自动接受或拒绝其身份.它作为一种身份识别技术,已经广泛应用于各种场景,例如:电子购物、电话银行、电子商务等.最近,越来越多的研究表明:ASV系统面临着各种伪造语音攻击的问题.常见的伪造语音可以分为4种方式:语音模仿、录音重放、语音合成和语音转换[4].因此,研究人员设法开发出有效的反欺骗系统,以保护ASV系统免受伪造语音的欺骗攻击.
为了提高反欺骗系统的性能,最近的工作主要集中在2个方面:1)改善音频的声学特征;2)设计新的分类模型.选取能够有效区别真实语音和伪造语音的声学特征尤为重要.Todisco等人[5]将常数Q变换倒谱系数(constant Q cepstral coefficients, CQCC)应用于语音鉴伪中,使用常数Q变换(constant Q transform, CQT)而不是短时傅里叶变换来处理语音信号,其性能优于普通的梅尔倒谱系数(Mel frequency cepstrum coefficients, MFCC).Sahidullah等人[6]用线性滤波代替了梅尔刻度滤波,提出了线性频率倒谱系数(linear frequency cepstrum coeffi-cients, LFCC),使其更加关注高频段特征.此外,Sahidullah等人[6]还尝试了翻转梅尔倒谱系数(inverse Mel frequency cepstrum coefficients, IMFCC),将原先的梅尔刻度翻转过来,使其在高频段分布更密,从而更专注于高频特征.另一种方法是设计新的分类模型,该模型可以学习到真伪语音的区分表示.高斯混合模型(Gaussian mixture model, GMM)是最常用的分类模型.随着深度学习的发展,卷积神经网络(convolution neural network, CNN)的性能,要比直接使用GMM更好[7-10].例如具有最大特征图(max feature map, MFM)激活功能的轻量型卷积神经网络(light convolution neural network, LCNN)[11],通过竞争学习的方法不仅可以分离噪声信号和信息信号,还可以起到特征选择的作用.残差网络(residual network, ResNet)[12]提出了残差模块,解决了网络“退化”的问题,即随着网络模型的加深,学习效果反而变差.这2种方法均被证明是有效的,这表明使用适当的前端声学特征以及出色的深度学习模型对于伪造语音检测都是至关重要的.
虽然以上工作已经取得了比较好的表现,但仍存在2个方面问题:1)现有的卷积神经网络及其变种忽视了每一维上特征图的不同位置强调的信息是不一样的,它们假设送入卷积神经网络的特征图的每一维对结果的影响是相同的.2)当前工作集中关注特征图的局部信息,无法利用全局视图中特征图之间的关系.如何更全面精准地分析利用这些属性特性找到真实语音和伪造语音的区别,将有限的注意力集中在重点信息上是目前语音伪造检测研究所面临的一项重要挑战.
注意力机制在图像识别、自然语言处理、语音识别等领域[13-17]有了很多成功应用.受到这些应用的启发,我们考虑引入注意力机制来解决将有限的注意力集中在重点信息上这一挑战.Lai等人[9]在语音伪造检测领域中引入SE-Net,从全局维度分配注意力权重.Sarthak等人[18]在说话人识别领域引入时频注意力,关注局部的注意力分配.但是他们没有考虑到将全局注意力模块和时频注意力模块联合使用.本文融合了全局-时频注意力模块,同时从全局和时频特征图2个层面的注意力机制为不同的特征赋予不同的注意力权重,实现了真伪语音特征更全面精准的区分,从而保证了真伪语音的准确预测.此外,为了进一步获得更具有区分性的真伪语音嵌入,我们将softmax损失函数替换成了angular softmax[19]损失函数,从优化内积空间到优化角度空间,使得类间距离扩大,类内距离缩小,从而使得真伪语音的区分性更大了.最后,我们在ASVspoof2019公开数据集上进行一系列实验,结果显示所提的模型取得不错的效果,最佳模型的等错误率(equal error rate, EER)达到4.12%,刷新了单个模型的最好成绩.
本文的主要贡献包括2个方面:
1) 融合了全局-时频注意力网络,从全局和时频特征图2个层面的注意力机制为不同的特征赋予不同的注意力权重,实现了真伪语音特征更全面精准的区分;
2) 将softmax损失函数替换成了angular softmax损失函数,进一步提升了模型的性能.
1 相关工作
本节从轻量型卷积神经网络、注意力机制、前端声学特征研究和angular softmax损失函数4个方面介绍相关工作.
1.1 轻量型卷积神经网络
轻量型卷积神经网络(LCNN)最早应用于人脸识别,此后在ASVspoof2017比赛中,第1名的队伍使用了LCNN的方法,随后在语音伪造检测领域中大量被使用.在LCNN中,每一个卷积层都用了最大特征图MFM如图1所示,具体而言就是将原输入层分为2个部分,通过竞争学习,丢弃了输出较小的部分,剩下输出较大的部分.此外,LCNN相较于传统卷积神经网络不仅可以获得更好的性能,还可以减少参数量.本文所提的整体网络框架就在LCNN的基础上进行了改进.

Fig. 1 Max feature map图1 最大特征图
1.2 注意力机制
众所周知,注意力在人类感知中起着重要的作用.注意力机制最早在计算机视觉领域广泛应用[13,20],当一幅场景摆在我们面前时,我们所能注意到的东西是不一样的,换句话说,该场景下我们对每一处空间的注意力分布是不一样的.同样,这种情况也适用于语音场景.最近,一些基于卷积注意力的工作在说话人识别中开展[21-23].文献[24]引入SE-Net到说话人嵌入提取器中来提高对说话人嵌入之间的微妙差异的学习能力.SE-Net可以通过动态地分配通道维度的权重来提高网络的表达能力.具体而言,SE-Net是一个简化的网络,它可以插入基于CNN的网络中,以学习通道之间的相互依赖性,并生成一组通道层面的权重,以强调有用的信息抑制无用的信息.这种从全局考虑长时说话人语音的方法被证实在说话人识别中是有效的.
1.3 前端声学特征
在本节中,我们将介绍在DNN框架下不同的前端声学特征.
1) 线性频率倒谱系数LFCC
LFCC是一种基于三角滤波器组的倒谱特征,类似于广泛使用的梅尔频率倒谱系数(MFCC).它的提取方法于MFCC类似,但是滤波器是线性的而不是梅尔刻度.因此,LFCC在高频区域可能具有更好的分辨率.
2) 翻转梅尔倒谱系数IMFCC
IMFCC也是一种基于三角滤波器组的倒谱特征,与MFCC不同的是,IMFCC采用的的滤波器是逆梅尔刻度,即在高频比较密集,在低频比较稀稠.因此IMFCC也更关注高频区域.
3) 常数Q变换倒谱系数CQCC
CQCC使用常数Q变换(即CQT)而不是短时傅里叶变换来处理语音信号,其性能优于普通的梅尔倒谱系数MFCC.
4) 滤波器组(Fbank)
Fbank是一种基于三角滤波器组的倒谱特征,它的提取过程与MFCC类似,在离散余弦变换之前得到的特征我们就称为Fbank.
5) 语谱图
给定语音序列t(n),Tn(ω)是其经过窗函数ω(n)的短时傅里叶结果.Tn(ω)可以表示为
Tn(ω)=|Tn(ω)|ejθn(ω),
(1)
其中,|Tn(ω)|指的是短时幅度谱,θn(ω)指的是相位谱.
1.4 angular softmax损失函数
传统的softmax损失函数定义为
(2)
其中,N是训练样本的个数,xi是第i个样本,yi是其对应的标签w是最后一层全连接网络的参数.
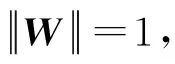
(3)
其中,θi,yi是矢量Wyi和xi之间的夹角,为了进一步让真伪语音的分类间隔扩大,我们引入了一个参数m,使得cos(mθ1)>cos(θ2),就得到了angular-softmax损失函数,其表达式为
La=
(4)
其中,m是固定的角度间隔,m值越大角度间隔越大.
2 本文所提框架
在本节中,我们首先介绍全局-时频注意力网络的总体框架,然后分别介绍2个注意力模块,它们分别捕获时频局部信息和全局信息.
2.1 全局时频注意力网络总体框架

Fig. 2 Global and temporal-frequency attention based network图2 全局-时频注意力网络
总体注意力过程可以概括为
X′=Mg(X)⊗X,
X″=Mtf(X)⊗X,
(5)
X‴=X′⊕X″,
2.2 全局注意力模块和时频注意力模块
1) 全局注意力模块
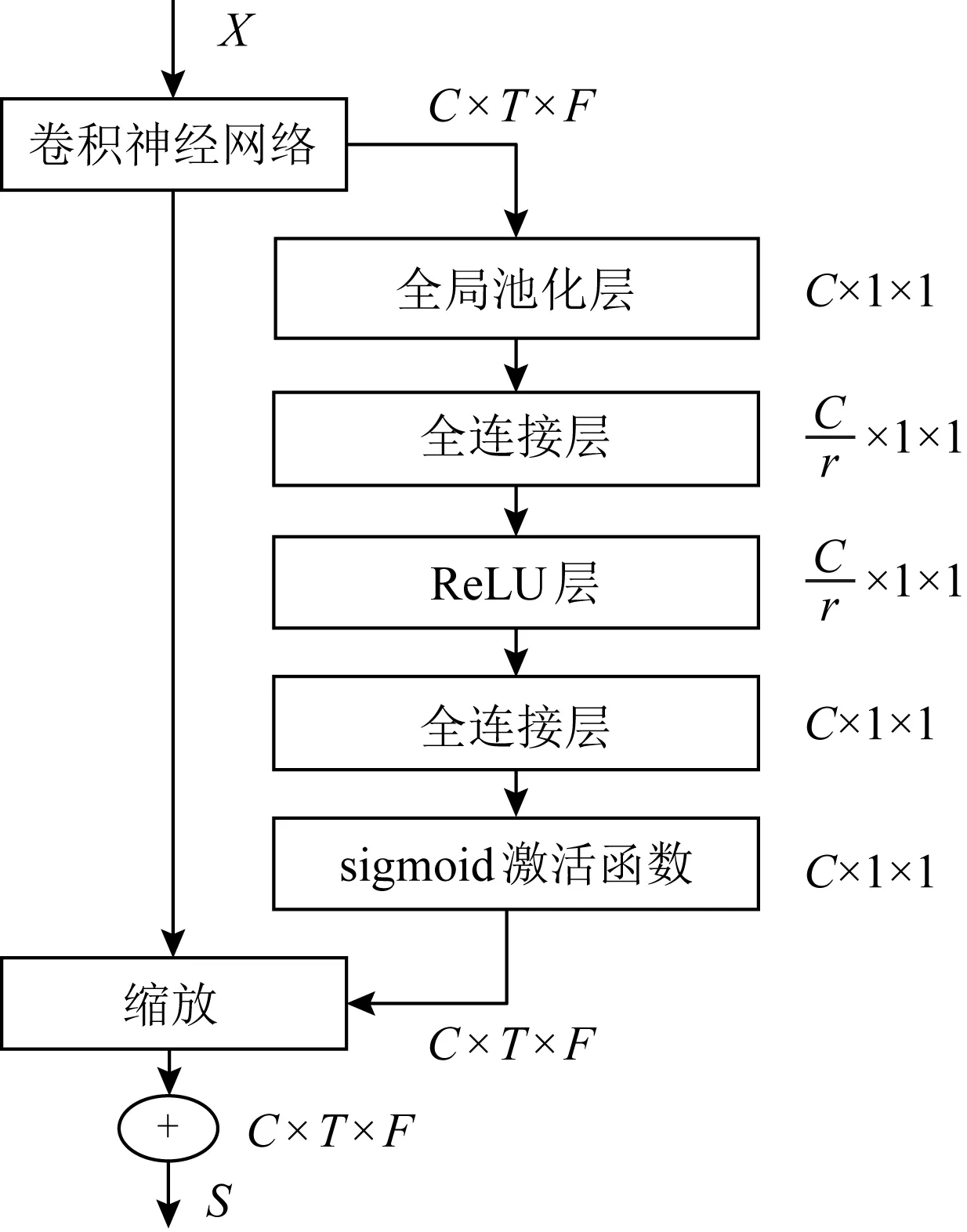
Fig. 3 Global attention module图3 全局注意力模块
(6)
其次是激活操作,它类似循环神经网络中门的机制,通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z)),
(7)
其中,δ指的是ReLU激活函数,σ指的是sigmoid激活函数.
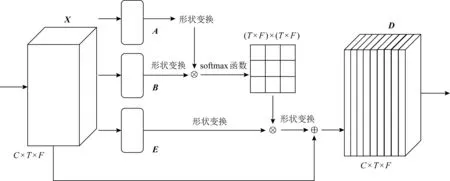
Fig. 4 Temporal-frequency module图4 时频注意力模块
最后是重新分配权重,我们将上一步输出的权重看作是经过特征选择后的每个特征通道的重要性,然后通过乘法逐个通道加权到先前的特征上,完成在通道维度上的对原始特征的重新标定.
2) 时频注意力模块
(8)
其中,sji表示第i个位置对第j个位置的影响,2个位置的特征表示越相似,他们之间的相关性越高.
(9)
其中,α初始化为0并逐渐学会分配权重.从式(9)可以得出,每个位置上的结果特征D是所有位置上的特征与原始特征的加权和.因此,它具有全局前后帧视图,并根据时频注意力图选择性地聚合前后帧.相似的语音特征实现了共同的促进,从而改善了类内部的紧凑性.
3 实 验
3.1 数据集
本文所有的实验都在ASVspoof2019[24]数据集上进行,我们关注的重点是合成语音和转换语音对真实语音的干扰,因此我们采用的是logical access(LA)数据集.数据集的详细说明可以在表1看到.LA数据集包含3个子集:训练集、开发集和测试集.训练集包含2 580条真实语音和22 800条用6种方式合成或转换的伪造语音;开发集包含2 548条真实语音和22 296条用6种方式合成或转换的伪造语音;测试集包含了7 355条真实语音和64 578条未知算法生成的伪造语音.

Table 1 ASVspoof2019 LA Dataset表1 ASVspoof2019 LA数据集
3.2 评价指标
本文采用等错率(EER)来描述系统的指标.等错率是一种权衡错误拒绝率和错误接受率的一项指标.
(10)
EER=Pfa(θEER)=Pmiss(θEER).
其中,Pfa(θ)是错误接受率,是指伪造语音被判定为真实语音的数量除以总的伪造语音的数量;Pmiss(θ)指的是错误拒绝率,指的是真实语音判定为伪造语音的数量除以总的真实语音的数量.错误接受率和错误拒绝率的值相等时,此值就是等错率.
3.3 实验模型配置与参数设置
本文在基于LCNN的语音伪造检测的基础上增加了批量归一化层和全局-时频注意力模块,在减少其内部相关变量的偏移和加速网络收敛的同时从全局和时频特征图2个层面的注意力机制为不同的特征赋予不同的注意力权重,实现了真伪语音特征更全面精准的区分.其网络结构如表2所示:
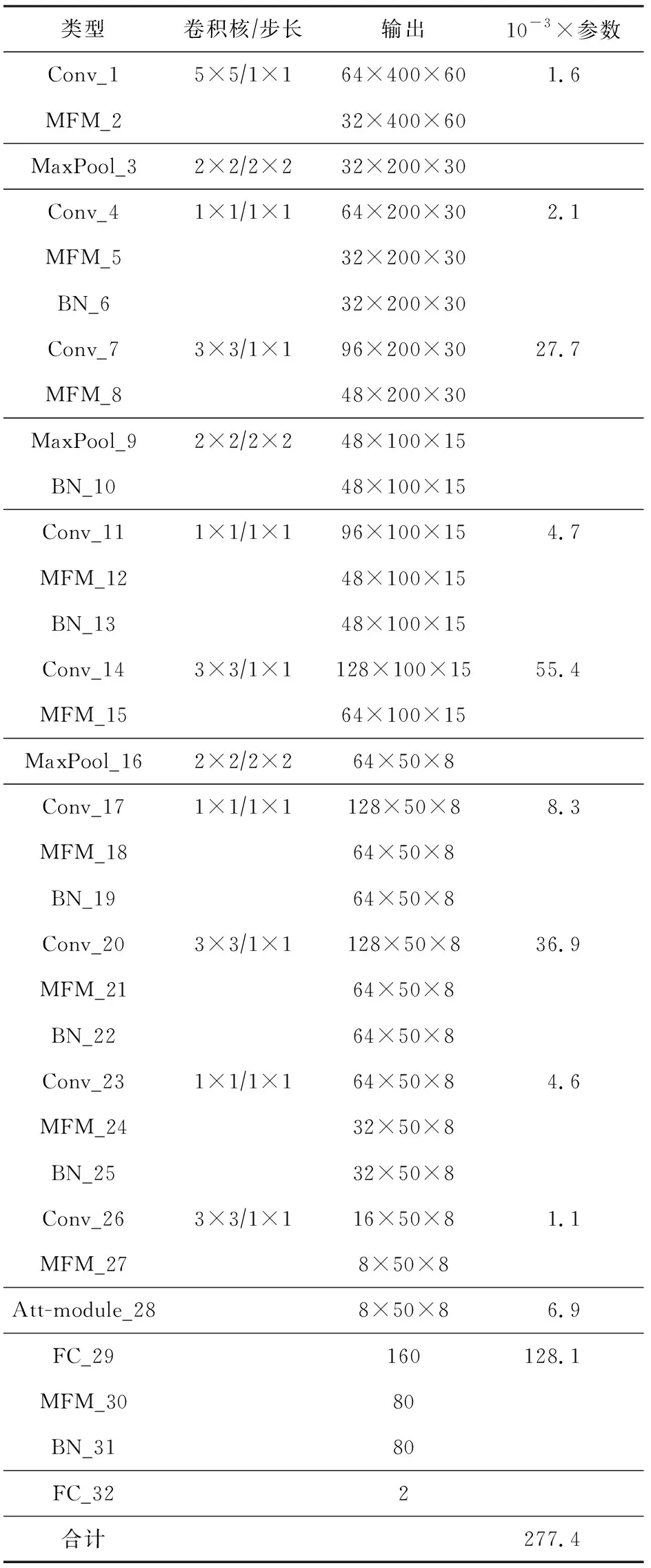
Table 2 LCNN Architecture表2 LCNN网络结构
首先对输入的语音数据进行预处理、特征提取(如1.3节提到的LFCC,Fbank,CQCC,IMFCC等).其次基于全局-时频注意力的LCNN网络,提取语音的深层次非线性因子特征.最后,由全局-时频注意力网络的最后一层输出输入到全连接层,计算真实语音和伪造语音的得分,用于预测真伪语音类别的标签.
为了验证本文所提方法的有效性和声学特征的影响,我们主要设置了11组实验,具体配置为
1) LFCC-GMM.LFCC-GMM是ASVspoof2019提供的基线系统,其中高斯混合数为512.LFCC的提取参照基线系统——窗口长度设为20 ms,FFT维数为512,并且滤波器组数为20,并对其作一阶和二阶差分.
2) LFCC-LCNN.LCNN参照表2,但是没有包含注意力模块,总共有9层卷积层.LFCC的提取方式和LFCC-GMM类似.
3) LFCC-CMVN-LCNN.整个框架与LFCC-LCNN类似,不过在LFCC提取过程中作了均值和方差的归一化处理.
4) CQCC-LCNN.CQCC的提取采用常规的默认值,即每八度音阶96个谱线,窗口大小为1 724,步长为0.008 1.
5) Fbank-LCNN.Fbank的提取窗口长度设为20 ms,FFT维数为512,并且滤波器组数为40.
6) Spectrum-LCNN.语谱图的提取窗口长度设为20 ms,FFT维数为512.
7) LFCC-LCNN-Global&TF.LCNN-Global& TF指的是含有全局-时频注意力模块的LCNN,其结构如表2所示.LFCC的提取方式和LFCC-GMM类似.
8) LFCC-LCNN-CBAM.同上,将注意力模块换成了CBAM[15]模块.
9) LFCC-LCNN-Global.整体框架与LFCC-LCNN-Global&TF保持一致,注意力模块只选择了全局注意力模块.
10) LFCC-LCNN-TF.同上,注意力模块方面只选择了时频注意力模块.
11) LFCC-LCNN-Global&TF-Asoftmax.整体框架与LFCC-LCNN-Global&TF类似,不过将softmax换成了A-softmax.
本文所提模型基于深度学习框架PyTorch展开实验.优化器为Adam,其中batchsize=32,初始学习率为0.0005,动量为0.9,模型迭代次数为200.
3.4 实验结果与分析
3.4.1 前端声学特征的影响
为了探究前端声学特征对系统的影响,本文在保持后端分类器LCNN不变的情况下,设置了不同的前端声学特征.实验结果如表3所示.对比5种声学特征,可以看出,LFCC的性能最好,这与先前的分析保持一致,这是由于LFCC的滤波器是线性的而不是梅尔刻度,因此在高频区域有更好的分辨率.此外,对比表3中行5和行6,可以看出对LFCC做了均值和方差归一化后效果反而变差了.这是由于测试集和训练集、开发集的差异较大,因此做了归一化结果变差.

Table 3 The Result of Front-End Acoustic Characteristics表3 前端声学特征的结果 %
3.4.2 全局-时频注意力的影响
由于表3的实验验证了LFCC的有效性,因此接下来我们统一将前端声学特征固定为LFCC,通过更改后端网络分类器来验证本文所提的全局-时频注意力网络的有效性.实验结果如表4所示.分别对比表4行1和行2~5,可以得到结论,加了注意力模块的系统相较于原系统对结果都有提升.此外,我们还对全局-时频注意力模块做了消融实验,以说明不同注意力模块对整体性能的影响.具体而言,我们比较了3种注意力模块:只包含全局注意力模块(LCNN-Global)、只包含时频注意力模块(LCNN-TF)和并行的全局-时频注意力模块(LCNN-Global& TF).表4的行3到行5总结了不同注意力模块安排方式的结果.从结果中,我们可以发现并行地使用全局-时频注意力模块要优于单独使用任一注意力模块,这表明将2种注意力模块并行使用是有效果的.此外,单独使用全局注意力模块的性能要略好于单独使用时频注意力模块.
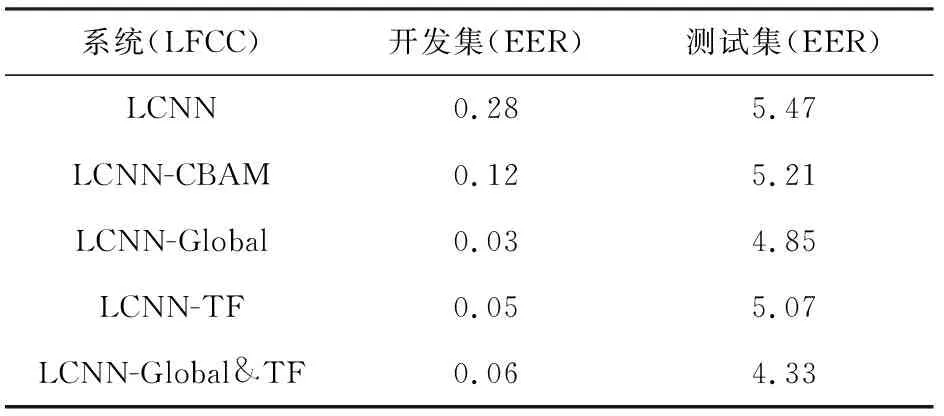
Table 4 The Result of Attention Module表4 注意力模块的结果 %
3.4.3 A-softmax损失函数的影响
我们还验证了A-softmax损失函数的有效性.从表5可以看出,将损失函数从softmax替换成了A-softmax之后,EER从4.33%下降到了4.12%,性能提升了5.1%.这一结果表明:A-softmax损失函数通过优化角度空间,使得类间距离扩大,类内距离缩小,从而扩大了真伪语音的区分性.此外,我们还对表4的5个系统和表6的A-softmax系统做了分数层面的融合,融合后的EER为3.21%.表6中,文献[25]的方法与本文表2的LFCC方法类似,但是由于其没有提供公开代码,不能完全复现,性能比它略低.融合了表4的5个系统和表5的A-softmax系统,总共6个系统.
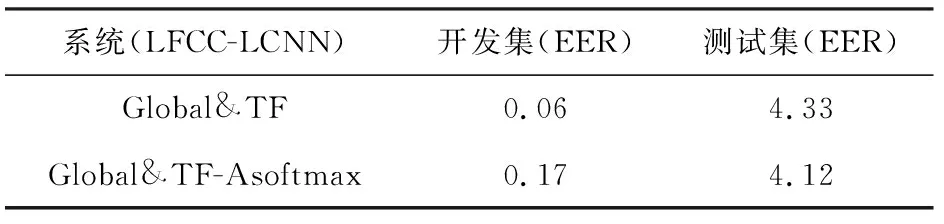
Table 5 The Influence of A-softmax Loss Function表5 A-softmax损失函数的影响 %

Table 6 Comparison of Proposed Method with State-of-the-art System表6 与其他方法比较的结果 %

Table 7 Multi-system Fusion表7 多系统融合 %
3.4.4 与其他最先进的系统对比
为了进一步证明本文所提方法的有效性,我们将本文的方法与其他在ASVspoof2019 LA数据集上的先进系统的结果做了对比.为了公平起见,我们将结果与其他系统的单个系统进行比较.从表6可以看出,本文所提的方法在单个系统中达到了最佳的性能,等错误率达到了4.12%,这个分数也是目前我们能了解到的在ASVspoof2019 LA数据集上单个系统的最佳成绩,进一步地证明了本文方法的有效性.
4 讨 论
据3.4节实验结果可见,本文所提的方法在测试集上的EER均有明显下降.
在单独使用全局注意力模块或时频注意力模块相较于原系统都有性能上的提升.此外,并行使用全局-时频注意力模块会进一步提升系统性能.这是由于全局-时频注意力能够有效地从全局维度和时频维度关注全局和时频特征的有效信息,抑制那些无用信息,从而提高了实验结果.
除此之外,在损失函数层面用A-softmax代替softmax之后,性能进一步提升,在ASVspoof2019 LA数据集上单个系统上取得最佳成绩.这是由于A-softmax损失函数通过优化角度空间,使得类间距离扩大,类内距离缩小,从而扩大了真伪语音的区分性.
5 总 结
语音伪造检测是近年一个研究热点.本文针对目前工作没有考虑到每一维上特征图的不同位置强调的信息是不同的问题,引入了一种基于全局-时频注意力网络的语音伪造检测模型.首先,我们从卷积神经网络输出的三维特征图压缩到只剩下通道维度,再将其经过一个类似循环神经网络中门控制的机制,通过参数为每个特征通道生成权重,其中参数被学习用来显式建模特征通道间的相关性.通过这种办法,我们可以得到特征通道上响应的全局分布.与此同时,我们通过使用加权求和在所有时频特征图上聚合特征来进行更新,其中权重由对应2个时频点之间的相似性决定.此外,为了进一步获得更具有区分性的真伪语音嵌入,我们将softmax损失函数替换成了A-softmax损失函数,从优化内积空间到优化角度空间,使得类间距离扩大,类内距离缩小,从而使得真伪语音的区分性更大了.最后,在ASVspoof2019 LA这个公开数据集中,通过一系列的实验表明本文所提的全局-时频注意力网络模型取得了最好的分类结果,充分证明了模型在语音伪造检测问题上的有效性.
未来的研究工作中,可以针对不同的特征组合拼接或者相位信息的声学特征对语音伪造检测的影响上进行更多的考虑和设计.
作者贡献声明:王成龙进行了该论文的模型设计、实验编码及运行、论文撰写等工作;易江燕进行了前期方法的讨论设计与论文修改;陶建华进行了论文修改;马浩鑫进行了补充实验以及模型调优;田正坤进行了损失函数的代码支持,以及从语音识别角度对方法提供改良;傅睿博从语音伪造角度提出引入全局模块.
