语义增强的多模态虚假新闻检测
2021-07-23亓鹏曹娟盛强
亓 鹏 曹 娟 盛 强
(中国科学院智能信息处理重点实验室(中国科学院计算技术研究所) 北京 100190)
(中国科学院计算技术研究所 北京 100190)
(中国科学院大学 北京 100049)
中国社会科学院2020年发布的《中国新媒体发展报告No.11》[1]显示,以微信、微博等为代表的社交媒体已经成为我国公众获取新闻信息的主要渠道.社交媒体的实时性、开放性、便捷性和双向性使得人们可以快速地获取并传播信息.但与此同时,社交媒体低门槛的特点也促进了虚假信息尤其是虚假新闻在网络空间的滋长蔓延.网络虚假新闻不仅使受众深受其害,冲击了主流媒体的权威性和公信力,还产生了经济、政治等多个方面的风险隐患(1)http://www.cac.gov.cn/2020-01/23/c_1581318267502085.htm.近年来,在社交媒体的富媒体化趋势下,用户发布的内容由纯文本向图文并茂的多媒体形式转变.虚假新闻的发布者也开始利用一些极具误导性甚至经过篡改的图片来吸引读者的注意,进一步促进虚假新闻的传播[2].因此,基于社交媒体的多模态虚假新闻检测已经成为近年来的研究热点.
现有研究表明:虚假新闻在表现层面上与真实新闻具有显著的差异性.虚假新闻往往呈现出更加强烈的情感煽动性、主观性[3-4],经常出现“紧急通知”“快转”等高频短语;虚假新闻图片具有低质量、视觉冲击力强的特点[5-6].相比下,真实新闻往往更加客观严谨,配图质量更高.现有的多模态方法[7-9]一般采用通用的循环神经网络(recurrent neural network, RNN)和卷积神经网络(convolutional neural network, CNN)分别捕捉虚假新闻文本及视觉模态表现层面的特性.然而,虚假新闻表现层面的特性与数据集高度相关,这使得在特定数据集上性能不错的方法往往难以良好泛化到新数据集上,容易误判表现层特性不明显的假新闻.
事实上,对于虚假新闻检测任务而言,仅仅关注新闻是如何表述的,即新闻表现层面的特点是不够的,还应该关注新闻具体描述了什么内容,即新闻语义层面的特点.在语义层面上,虚假新闻往往会涉及一些极具争议性的话题,或者存在图文不符等现象.与表现层相比,虚假新闻语义层面的特点往往更难捕获.一方面,新闻作为一种特殊的叙事文体,往往包含人名、地名、机构名及其他专有名词等命名实体.理解这些实体对建模虚假新闻语义层面的特点起到重要的作用,但他们的含义难以简单地通过上下文理解,需要引入外部事实知识.另一方面,在多模态新闻的语义理解中,图片模态经常提供有利于模型预测的关键实体信息(名人、地标、旗帜标志等).例如我们可以通过核对图文中出现人物身份的一致性推断该新闻的可信度.然而,通用的视觉特征表示大多停留在感知层面,无法找到并充分建模这些视觉实体背后的深层语义.另外,通用的视觉语义特征和文本语义处于不同的特征空间,存在语义鸿沟和特征异构的问题.因此,如何充分建模图文之间的语义交互,也是我们需要着重考虑的问题.
为了解决上述挑战,我们提出了一种语义增强的多模态虚假新闻检测方法.首先,我们利用预训练语言模型中隐含的大量的事实知识,更好地理解多模态新闻中的实体概念;其次,在提取通用的视觉特征向量的基础上,利用外部模型显式提取新闻图片中的视觉实体及嵌入文字,得到不同语义层次的视觉特征;最后,我们采用文本引导的注意力机制建模文本与不同层次的视觉特征之间的语义交互,进而得到统一的多模态特征表达.
本文的主要贡献包括3个方面:
1) 提出了新颖的语义增强的多模态虚假新闻检测方法.通过融合外部知识以及显式的视觉实体提取,更好地理解多模态新闻中的实体语义,从而更充分地挖掘多模态虚假新闻的语义线索;
2) 采用文本引导的注意力机制建模文本与不同层次的视觉特征之间的语义交互,更好地融合多模态异构特征;
3) 在真实世界的微博数据集上对本文提出的方法进行验证.与当前较好方法相比,我们的模型能够大幅提高虚假新闻检测的准确率.
1 相关工作
根据研究对象的不同,虚假新闻检测可以分为事件层面的检测和微博层面的检测.事件层面的检测利用同一事件下所有微博的信息联合判断该新闻事件的可信度.但是事件形成往往需要一定时间.一些重大的虚假新闻可能在事件形成前已经在社交媒体上广泛传播,在非常短的时间内产生较大的消极影响.微博层面的检测是指判断单条微博消息的可信度.与事件层面的检测相比,这种方法在实际应用中可以做到实时检测,因此得到了研究人员的广泛关注.本文的研究专注于微博层面的虚假新闻检测.
大多数现有的研究利用文本内容和传播过程中产生的社交上下文检测虚假新闻[10].基于文本内容的检测方法主要基于虚假新闻特定的语言风格建模,包括早期提取语言学特征、主题特征等手工特征的方法[11-13],以及近年来基于深度模型自动学习数据高层特征的方法[14].基于社交上下文的方法主要包括基于用户行为可信度的方法[15-17]以及基于传播网络的方法[18-21].
近年来,一些工作开始关注视觉模态在虚假新闻检测中的作用[5-6,22-26].虚假新闻图片主要包括篡改图片和误用图片两大类[6].篡改图片指使用工具故意进行像素级改动或是算法自动生成的非真实图片,而误用图片一般指未经刻意修改,取自其他事件或是图片内容被错误解读的真实图片.现有基于视觉模态的研究主要利用图片的取证特征[23]、语义特征[6]、分布特征[22]以及上下文特征[24-25]等进行虚假新闻检测.
文本模态和视觉模态为虚假新闻检测提供了各有侧重、相互补充的信息.因此,结合多模态信息进行虚假新闻检测的方法也备受关注.文献[7]第1次通过深度神经网络的方法将多模态信息引入到虚假新闻检测中,他们提出了一种带注意力机制的循环神经网络融合文本、视觉及社交上下文的信息.为提高模型在新的虚假新闻事件上的泛化性能;文献[8]利用对抗学习的方法,引入事件分类这一辅助任务,引导模型学习到更具泛化性能的与事件无关的多模态特征;文献[9]利用“编码器-解码器”结构来构建多模态新闻的特征表达.上述方法在多模态虚假新闻检测上具有一定的有效性,但是由于缺乏足够的事实知识,不能充分理解多模态新闻事件的深层语义.针对这一问题,文献[27]从外部知识图谱中提取文本实体对应的概念知识融入多模态的表达中,从而获得更好的语义理解能力;文献[28]提出利用图神经网络建模文本、知识以及图片中的物体之间的交互.上述方法通过引入外部知识图谱的方式增强对新闻文本语义的理解,但是在对图片语义信息建模以及多模态异构特征融合上仍存在欠缺之处.
因此,针对已有工作的不足,我们提出了一种语义增强的多模态虚假新闻检测方法,不仅能够利用外部知识深入理解文本及图片的语义信息,也能充分融合不同模态的异构特征.
2 语义增强的虚假新闻检测方法
我们的任务是判断给定的单条多模态新闻为真新闻或假新闻.图1展示了我们提出的语义增强的多模态虚假新闻检测模型,主要由文本语义编码器、视觉语义编码器、多模态特征融合以及分类4部分组成.

Fig. 1 Framework of our semantics-enhanced multi-modal fake news detection model图1 语义增强的多模态虚假新闻检测模型结构图
2.1 文本语义编码器
文本作为新闻事件的叙述主体,包含了丰富的信息,为新闻可信度的判定提供了不同层次的线索.现有方法大多利用循环神经网络等对输入文本的上下文信息进行建模,捕捉文本表现层的模式[7,9,14,27].然而,由于特征提取过程缺少相应事实知识的参与,这类方法对新闻文本中命名实体的理解能力有限,进而难以充分捕捉虚假新闻语义层面的线索.
近期一些工作[29-30]表明,以BERT[31](bidirec-tional encoder representations from transformers)为代表的预训练语言模型不仅具有强大的建模能力,通过在大规模预训练语料上的学习,其内部已经学习到了某些句法知识和常识知识.在BERT的基础上,百度提出了一种知识增强的语义表示模型ERNIE(enhanced representation from knowledge integration)[32].ERNIE的结构与BERT类似,都是利用多层的Transformer[33]作为基本的编码器,通过self-attention机制实现对上下文信息的建模.与BERT不同的是,ERNIE对词、实体等语义单元进行掩码,并扩展了一些知识类的中文语料进行预训练,能够更好地建模实体概念等先验语义知识,从而进一步提升模型的语义表示能力.ERNIE不仅能够作为上下文编码器产生句子的表达,还可以作为知识存储器,在产生句子表达的时候隐式地利用模型中存储的大量事实知识.因此,我们使用ERNIE作为文本模态的特征提取器,同时建模文本在表现层及语义层的特点.
具体地,我们首先在虚假新闻分类任务的数据集上对ERNIE进行微调.对于输入句子T=[w1,w2,…,wn],其中wi代表句子中的第i个词,ERNIE会先对其进行编码,添加[MASK],[SEP],[CLS]等标记,然后进行训练.我们提取[CLS]对应的768维的特征向量作为输入句子的最终语义表示如式(1):
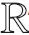
(1)
另外,社交媒体上存在很多以文字型图片为主体的新闻,即新闻的主要文本用图片的形式表示.我们使用百度预训练的OCR文字检测模型(2)https://ai.baidu.com/tech/ocr提取图片中的文本信息.经过数据预处理后,可以将图片中识别到的文本表示为词序列O=[w1,w2,…,wn],其中wi表示句子的第i个词.为充分建模输入文本T与图片文本O的语义交互,我们将两者拼接成一个序列,用[SEP]进行分隔,输入到ERNIE网络中,得到对应的语义表示:
xto=ERNIE(T[SEP]O).
(2)
2.2 视觉语义编码器
与真实新闻的配图相比,虚假新闻图片往往具有更低的图片质量,更具视觉冲击和情感煽动的图片风格[6].因此,现有方法大多通过卷积神经网络提取颜色、边缘、纹理等层次化的视觉特征来建模图片的质量及风格特性.然而,由于缺乏外部知识的引入,这类通用的视觉特征表示大多停留在感知层面,无法充分建模新闻图片的深层语义.
事实上,新闻图片往往包含一些极具新闻性的视觉实体,包括名人、地标、旗帜标志以及一些敏感目标等.准确识别这些实体有助于我们更加充分地理解多模态新闻的语义,从而更好地捕捉虚假新闻的线索.例如,通过对图片进行名人及地标识别,可以发现图片中所展示的人物及地点与新闻文本描述不符;通过识别图片中的敏感标志及物体,可以强调文本中的相关实体,从而更好地理解多模态新闻的争议点.因此,为充分建模虚假新闻图片的语义特性,我们一方面提取图片的视觉特征向量建模其质量及风格特性,另一方面引入外部模型显式提取图片中的视觉实体建模其深层语义.
2.3 多模态特征融合
至此,我们得到了文本的表达xt,文本及图片文本的联合表达xto、视觉实体序列的表达E以及视觉特征向量序列的表达V,本节将介绍如何融合上述多种异构特征得到一个统一的多模态表达.
图片中可能存在多个视觉实体,但并非所有检测到的实体都对虚假新闻分类的任务有帮助,融合所有的实体信息可能会导致信息冗余甚至引入噪声.经过观察,我们发现能够与文本对应的视觉实体往往更加重要.因此,我们对图片中识别到的多个视觉实体E=[e1,e2,…,en]进行基于文本引导的注意力机制的融合.我们首先根据文本特征xt,计算每个视觉实体ei的重要性:

(3)
其中,W为随机初始化并在训练过程中联合优化的参数矩阵,f(·)为激活函数.我们对权值进行归一化:

(4)
并根据得到的权重对不同的视觉实体表示进行加权求和,得到最终的视觉实体表示:
(5)
同样地,图片的不同区域对于语义理解也具有不同的重要性.因此,我们对图片不同区域的特征向量V=[v1,v2,…,vn]进行基于文本引导的注意力机制的融合,得到最终的视觉特征向量表示:
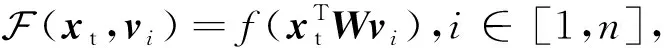
(6)

(7)

(8)
经过上述操作,我们得到了原始文本以及图片文字的联合表示xto,图片的视觉实体表示xe以及图片的视觉特征向量表示xv.这些特征从不同角度建模了输入的多模态新闻不同层次的语义信息,具有一定的互补性.我们将这些特征拼接在一起,得到该条新闻最终的多模态表示:
x=xto⊕xe⊕xv,
(9)
其中,⊕是拼接操作.
2.4 分 类
在得到输入新闻的多模态表示x之后,我们将其输入全连接层,并将全连接层的输出通过softmax层产生分类标签的分布:
p=softmax(WCx+bC),
(10)
其中,WC和bC是模型的参数.我们采用交叉熵作为模型的损失函数:
L=-∑[yflogpf+(1-yf) log(1-pf)],
(11)
其中,yf是样本的真实标签,1表示该样本为假新闻,0表示该样本为真新闻;pf表示该样本被预测为假新闻的概率.
3 实验与分析
3.1 数据集
在目前的虚假新闻研究中,公开的多模态数据集比较少,故在本文的后续实验中主要讨论在中文微博数据集上的性能,但是本文提出的模型同样也适用于英文多模态虚假新闻数据集.这是因为本文提出的模型主要关注文本及图片深层语义的提取和交互,与文本语言的表现形式关系不大.语言形式对模型的影响将在今后进一步的工作中进行验证.
本文采用Jin等人[7]基于中文新浪微博平台构建的虚假新闻数据集.该数据集包含微博官方谣言举报平台上从2012-05—2016-01所有官方认证为假的新闻消息,以及从新华社的热点新闻发现系统采集的同时期的真实新闻的微博消息.由于社交媒体平台上的消息存在一定噪声和冗余,为保证数据集的质量,Jin等人去除了重复图像、过小的图像以及垃圾图像等.为更好地验证模型在新的新闻事件上的泛化能力,在划分训练数据、验证数据及测试数据时,本文先将所有数据进行聚类,得到不同的事件.在此基础上对所有数据进行事件级别的划分,从而保证训练数据、验证数据以及测试数据不会包含同一事件的新闻.由于整体数据量比较小,本文按照3∶1∶1的比例划分最终的训练集、验证集和测试集,相关数据指标如表1所示.

Table 1 Statistics of the Dataset表1 数据集统计指标
3.2 实验设置
本文使用准确率(accuracy)和假新闻类别上的F1值、精确率(precision)及召回率(recall)作为评估指标.在模型的实现上,预训练的ERNIE模型来自GitHub上的开源项目Transformers[38].在对VGG19进行微调时,采用了图片翻转等数据增强的策略提升模型的泛化性能.句子的最大长度设置为128,batch size设置为64.使用ReLU作为非线性激活函数,使用Adam方法[39]优化损失函数.
3.3 实验1:虚假新闻检测性能比较
3.3.1 对比方法
为了验证本文提出方法的有效性,我们实现了3类代表性的方法进行性能对比.其中,attRNN方法由参考文献[7]作者提供,其他方法由本文作者根据论文描述复现.
1) 基于单文本模态的方法
① TextCNN.采用文献[40]提出的卷积神经网络进行文本分类.使用了3种不同大小的卷积核,高度分别为3,4,5.每一种卷积核的数目均设定为100.
② BiLSTM-Att.循环神经网络是文本分类任务中一种经典的建模方法.本文选择双层的LSTM[41]和注意力机制堆叠成的网络作为对比方法.其中,网络的隐层单元数被设定为128.
③ BERT.预训练语言模型近年来在各类自然语言处理任务中表现优越.采用在本文任务数据集上微调后的BERT模型作为对比.预训练的BERT模型bert-base-chinese来自GitHub开源项目Trans-formers[38].
④ ERNIE.采用在本文任务数据集上微调后的ERNIE模型作为对比.预训练的ERNIE模型nghuyong/ernie-1.0来自GitHub开源项目Trans-formers[38].
2) 基于单视觉模态的方法
① VGG19[34].在目前的多模态虚假新闻研究中,VGG19被广泛用作视觉特征提取器.本文将在ImageNet数据集[37]上预训练的VGG19模型在本文任务数据集上进行微调.
② ResNet152[35].将在ImageNet数据集上预训练的ResNet152模型在本文任务数据集上进行微调.
3) 基于多模态的方法
① attRNN.文献[7]提出了一种基于注意力机制的循环神经网络,用于融合文本、视觉及社交上下文3种模态的特征.其中,文本部分采用LSTM进行建模,图片部分采用预训练的VGG19进行特征提取.为了对比的公平性,在具体实现时,我们移除了处理社交特征的部分.
② EANN.文献[8]提出了一种基于事件对抗机制的神经网络.通过引入事件分类器作为辅助任务,引导模型学习到与事件无关的多模态特征.该模型分别采用TextCNN和预训练的VGG19进行文本及视觉模态特征提取,并将2种模态特征进行拼接,作为虚假新闻的多模态特征表达,输入到虚假新闻分类器及新闻事件分类器中.
③ MVAE.文献[9]提出了一种结合多模态变分自动编码器和虚假新闻检测器的多任务模型.其中,文本和图片分别通过双向LSTM及预训练的VGG19进行特征提取,两者的拼接特征被编码为一个中间表达,用于重构输入特征及虚假新闻分类.
④ KMGCN.文献[28]提出了一种知识引导的多模态图卷积网络.该方法从外部的百科知识图谱中提取文本中出现的命名实体所对应的概念作为外部知识.该方法对每条输入的多模态新闻都会构建一个图,图的节点包括文本中的单词、文本实体所对应的概念以及图片中识别到的物体名称,节点通过预训练的Word2Vec词向量进行初始化,边的权重设置为2个单词的PMI值.通过2层图卷积网络及最大池化得到图表达用于虚假新闻分类.
3.3.2 结果分析
表2列出了对比实验的结果,观察可得到结论:
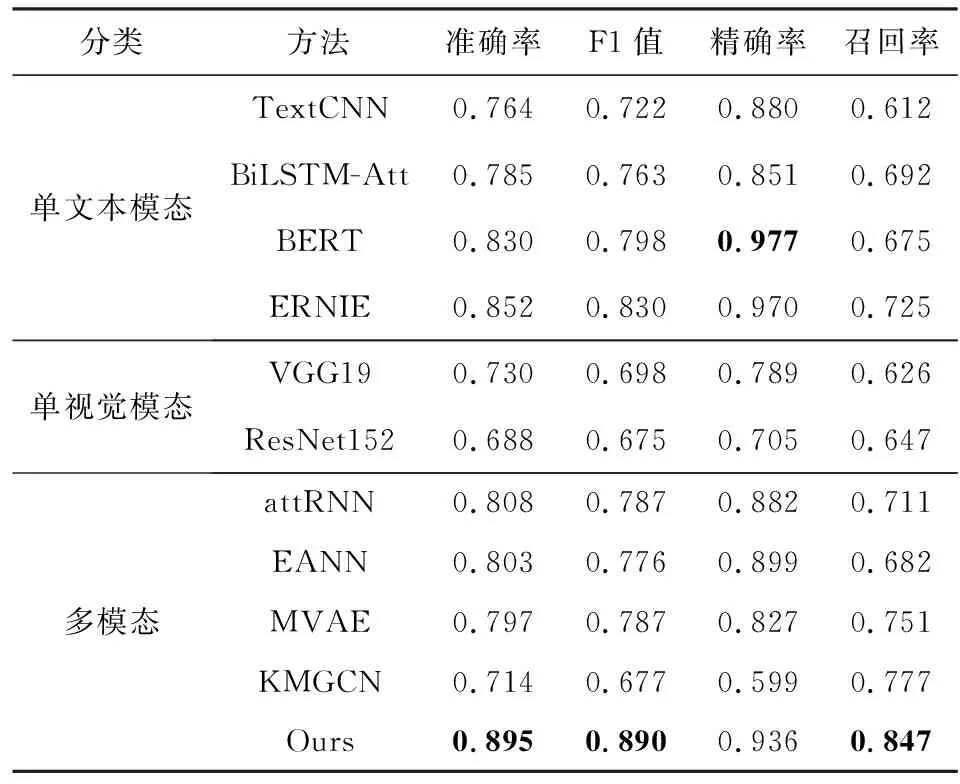
Table 2 Performance Comparison of Different Methods表2 不同方法的性能比较
1) 我们的方法在分类准确率上显著超过其他对比方法,说明本文提出的这种语义增强的多模态模型确实能够有效提升虚假新闻检测的性能.尤其在虚假新闻的召回率上,我们的方法超出其他方法7个百分点以上,说明我们的模型可以通过充分挖掘多模态语义线索,检测到被现有方法遗漏的虚假新闻.
2) 在基于多模态的方法中,KMGCN显著低于其他对比方法.主要的原因可能是GCN对于微博这类短文本的建模能力较差,在此基础上无法很好地体现外部知识的作用.另外,KMGCN仅提取了图片中的物体标签信息,对于图片语义建模不充分.
3) 基于单文本模态的方法要优于基于单视觉模态的方法,说明虚假新闻检测主要依靠文本线索.基于多模态的方法要优于具有相同子网络结构的单模态方法,说明文本和图片模态能够为虚假新闻检测任务提供互补的线索.其中,我们提出的方法与ERNIE相比,准确率提升了4.3个百分点,进一步证明了图片语义特征的重要性.
4) 在基于单文本模态的方法中,预训练语言模型要优于CNN,RNN等传统的文本建模方法.这种提升一方面来源于Transformer更强大的建模能力,另一方面受益于预训练语言模型从大量预训练语料中学习到的语言学知识.ERNIE的效果要优于BERT,这说明增加实体概念知识可以增强对新闻的语义理解,进而提升虚假新闻的检测效果.
3.4 实验2:消去分析
3.4.1 对比方法
为验证不同的模型组件对实验结果的影响,我们设计了5种模型的变体,对模型进行消去分析.
1) 去掉ERNIE.对文本及图片文本进行建模时,用双向LSTM结合注意力机制的网络结构替换ERNIE;获取视觉实体表示时,用预训练的Word2Vec词向量替代ERNIE生成的词向量表示.
2) 去掉OCR文本.移除提取及处理图片文字的部分.此时输入信息的多模态表示由原始文本的特征表达和原始文本引导下的视觉特征向量、视觉实体向量拼接而成.
3) 去掉视觉实体.移除提取及处理图片中视觉实体的部分.此时输入信息的多模态表示由原始文本和图片文本的联合表示及原始文本引导下的视觉特征向量拼接而成.
4) 去掉特征向量.移除处理图片视觉特征向量的部分.此时输入信息的多模态表示由原始文本和图片文本的联合表示及原始文本引导下的视觉实体向量拼接而成.
5) 去掉注意力机制.移除视觉实体及视觉特征向量在文本引导下的注意力机制.此时多个视觉实体向量和视觉特征向量分别通过平均操作进行融合.
3.4.2 结果分析
表3列出了消去分析的实验结果,可以得到2个结论:

Table 3 Ablation Study表3 消去分析
1) 移除模型的任何部分,模型的分类准确率都会出现一定程度的下降,这说明了模型各元素的有效性.
2) 按照移除后模型分类准确率的下降程度,可以将各模型组件的重要性排序如下:ERNIE>图片文本>视觉实体>视觉特征向量=注意力机制.这说明对于虚假新闻检测任务,文本比图片发挥的作用更重要,图片的高层语义比低层语义更重要.
3.5 样例分析
为了更加直观地展示本文方法的优越性,我们对比了本文模型和表2列出的对比方法中性能最好的ERNIE模型在测试集上的预测结果,并对ERNIE模型无法检测但本文模型能够成功检测到的多模态虚假新闻进行分析.图4展示了3条代表性的样例,分别体现了图片的视觉特征向量、视觉实体和图片文本对于虚假新闻检测的重要性.

Fig. 2 Examples of multi-modal fake news detected by our model图2 本文模型成功检测的多模态假新闻示例
① 该假新闻示例已被新浪微博社区管理中心判定为不实信息 https://service.account.weibo.com/show?rid=K1CaJ6g5f7aYd.新闻文本已在不影响语义的前提下进行删减展示
② 该假新闻示例已被新浪微博社区管理中心判定为不实信息 https://service.account.weibo.com/show?rid=K1CaJ6wpc66kl.新闻文本已在不影响语义的前提下进行删减展示
③ 该假新闻示例已被新浪微博社区管理中心判定为不实信息 https://service.account.weibo.com/show?rid=K1CaJ7Apk7aci.为避免引起读者不适,新闻图片及OCR文字中的谩骂言语已被隐去
图4(a)中的新闻配图清晰度较低,重压缩造成的块状效应明显,说明该张图片很可能是从网上下载的来自其他事件的过时图片,而非在本次事件中现场拍摄的图片.本文模型通过提取图片的视觉特征向量对图片质量进行建模,可以判断该条新闻为假的可能性较大.图4(b)中,通过提取图片中的视觉实体,可以识别出该条新闻配图里的人物为女演员瑞切尔·蕾·库克(Rachael Leigh Cook),而非文本中所说的比尔盖茨的女儿.本文模型通过提取图片中的视觉实体并利用预训练语言模型中隐含的事实知识,可以发现图文语义的冲突点,作为虚假新闻的线索.图4(c)为以图片为主体的多模态新闻,其原始文本中包含的信息量较少,不足以提供假新闻判定的线索.只有对图片进行文字提取,才能充分理解该条新闻的语义,从而发现虚假新闻的线索.
4 总 结
针对现有方法对于多模态新闻语义理解不足的问题,本文提出了一种语义增强的多模态虚假新闻检测方法.通过隐式利用外部模型中存储的大量事实知识,更好地理解多模态新闻的深层语义.提取不同语义层次的视觉特征,并采用文本引导的注意力机制建模图文之间的语义交互,从而更好地融合多模态异构特征.实验结果表明:本文提出的方法在准确率上大幅超越当前最好的方法,证明了基于语义增强方法的有效性.
