基于MIC和XGBoost的火电厂发电量预测
2021-07-22陈思勤沈玉华
陈思勤,胡 涛,沈玉华,曹 阳,李 婧
(1.华能国际电力股份有限公司 上海石洞第二电厂,上海 200942; 2. 上海电力大学 自动化工程学院,上海 200090)
0 引言
随着经济的快速增长,电力需求明显增大〔1〕。我国的能源结构决定了火力发电仍然是最主要的发电方式〔2〕。由于国家大力发展绿色经济,开始实施“发控结合”政策,要求电厂控制耗煤量的同时保证发电计划按时完成。但是发电计划往往存在滞后性,不能及时为电厂提供参考,所以火电厂发电量预测逐渐成为研究热点之一。
火电厂发电量预测大致可以分为长期(年度)、中期(月度)、短期(日度)和超短期(时分)预测〔3〕。近些年来,很多学者尝试对火电厂发电量数据进行深入研究。文献〔1〕根据传统发电模式对月度发电计划采用平均分配的方法计算,一定程度上兼顾节能与经济效益〔4〕。文献〔2〕将极限学习机算法和递归预测相结合,建立火电企业短期日发电量预测模型,提高了预测精度和泛化能力〔5〕。文献〔3〕采用具有动态平滑系数和参数的动态三次指数平滑法对火电厂月发电量进行预测,证明该模型具有良好的精度和较高的实用性〔6〕。虽然已经取得一定成果,但是仍然存在发电量数据影响因素难以分析、时间序列算法参数难以设置和预测周期短等问题,导致真正适用于火电厂发电量预测的方法较少。
针对上海某火电厂实际发电量数据进行深入分析与研究,首先对原始数据中异常值、缺失值和非数值型值做数据预处理工作;再考虑影响发电量的因素,并利用最大互信息系数(MIC)特征选择方法筛选影响因素〔7〕;最后采用极端梯度上升(XGBoost)算法建立火电厂发电量预测模型,得到了较高的精度,为火电厂安排月度检修计划、运行方式和发电计划等提供了参考意义。
1 数据处理与特征选择
1.1 原始数据预处理
随着大数据时代的到来,各行各业的数据量剧增,相应的数据维度也明显增加。在实际生产过程中,数据是杂乱无章的,往往不能直接进行分析,数据预处理工作变得尤为重要。数据预处理工作包括:数据收集、异常值处理、数据类型转换等〔8〕。
收集上海某火电厂数据库中与发电量相关的历史数据,对数据中存在的较多空缺值、负值、无效值和重复值进行清洗。其中,空缺值填补为0,负值替换为平均值,无效值和重复值直接剔除,不仅减少了异常数据对特征选择的影响,还保证了数据的完整性和全面性。数据类型众多,有连续型、离散型、数值型、定序型等,需要通过重新编码的方式将数据类型统一为数值型。
1.2 基于最大互信息系数的特征选择
最大互信息系数(MIC)最早由Reshef等人于2011年提出〔9〕,用来解决两个线性或非线性变量之间的关联程度,受异常值影响较小,并有较低的复杂度和较高的鲁棒性,被其他研究者广泛使用于机器学习的特征选择当中。
给定某一自变量X={x1,x2,x3,…,xn}和因变量Y={y1,y2,y3,…,yn},n为样本数量,则X和Y两个变量之间的互信息定义为〔10〕:
(1)
式中:p(x,y)代表X和Y的联合概率密度函数;p(x),p(y)分别为X和Y的边缘概率密度函数。
将两种变量X和Y组成一个按顺序排列的集合Q={xi,yi},i=1,2,3,…,n,定义一个将自变量X划分为a段,将因变量Y划分为b段的网格S,通过统计落在网格中散点的频率计算出p(x,y),p(x),p(y),在网格内部计算得到互信息I(X,Y)。由于网格划分的方式不唯一,所以需要选取互信息值最大的网格(a×b)划分方式〔11〕。划分网格S下Q的最大互信息值为〔12〕:
MI(Q,a,b)=maxI(X,Y)
(2)
将互信息值进行归一化组成特征矩阵M(Q)a,b:
(3)
最大互信息系数的计算公式为:
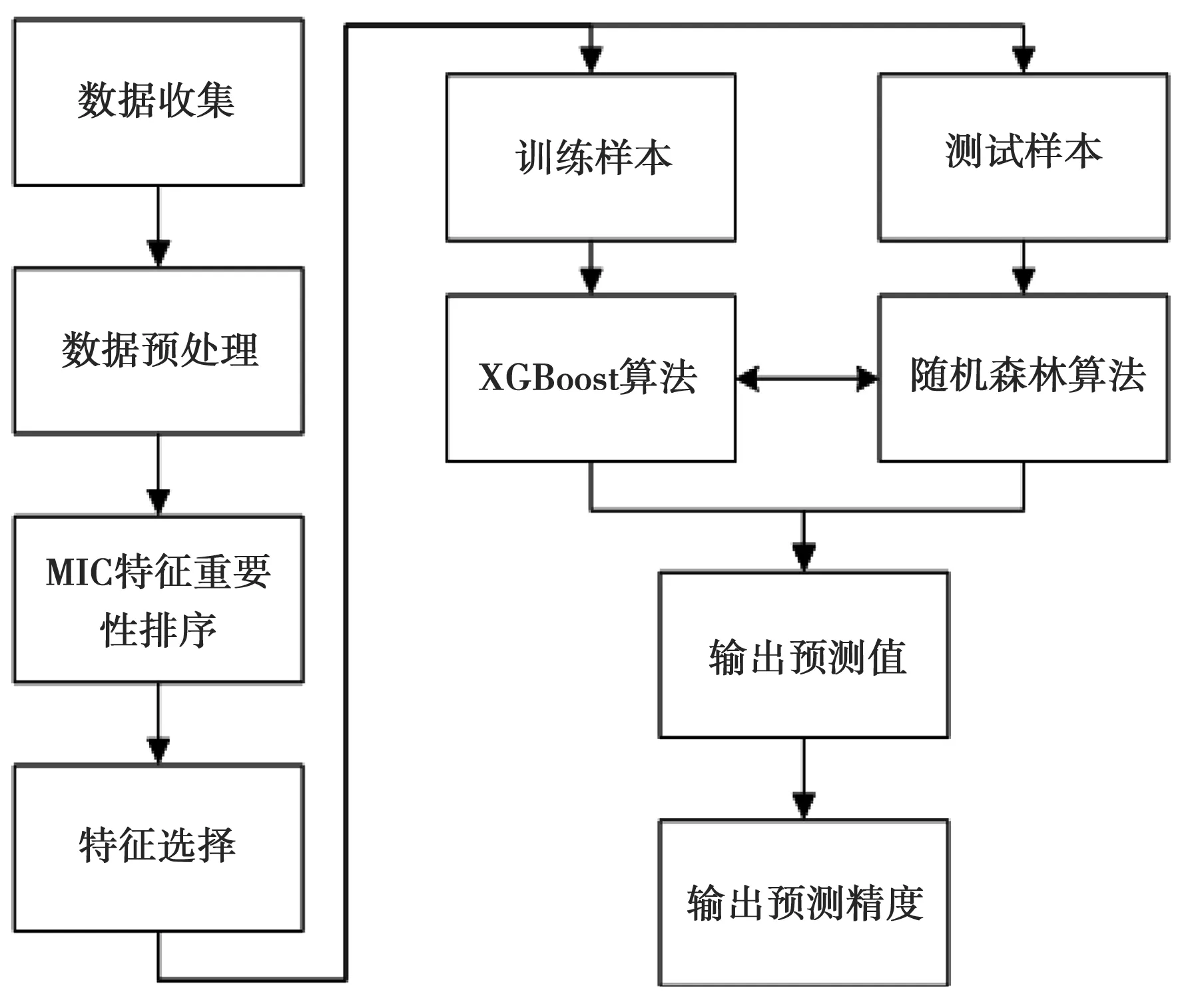
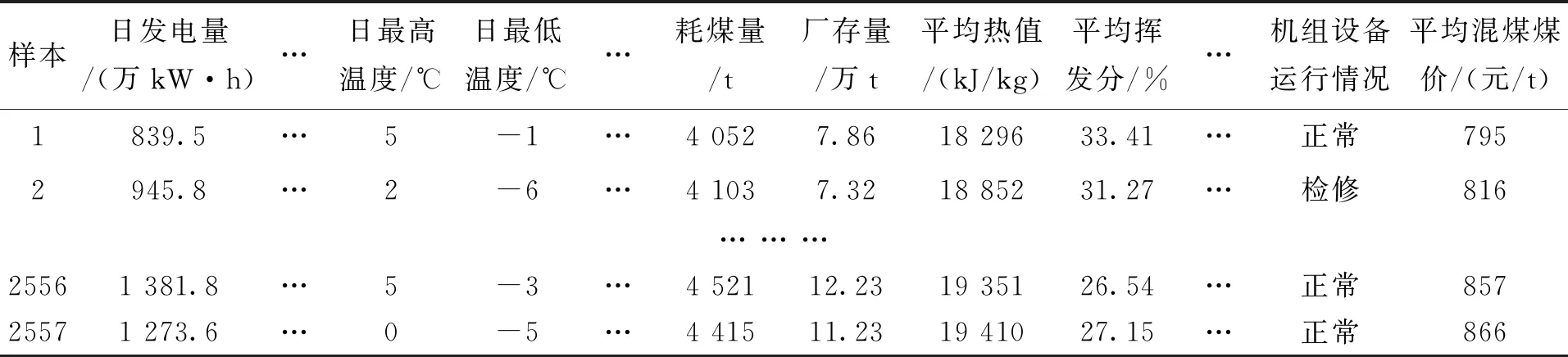
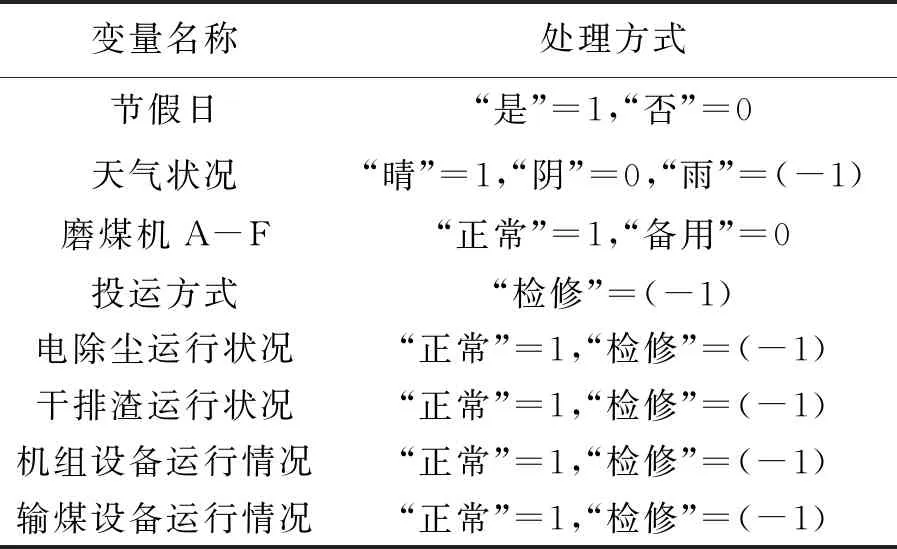
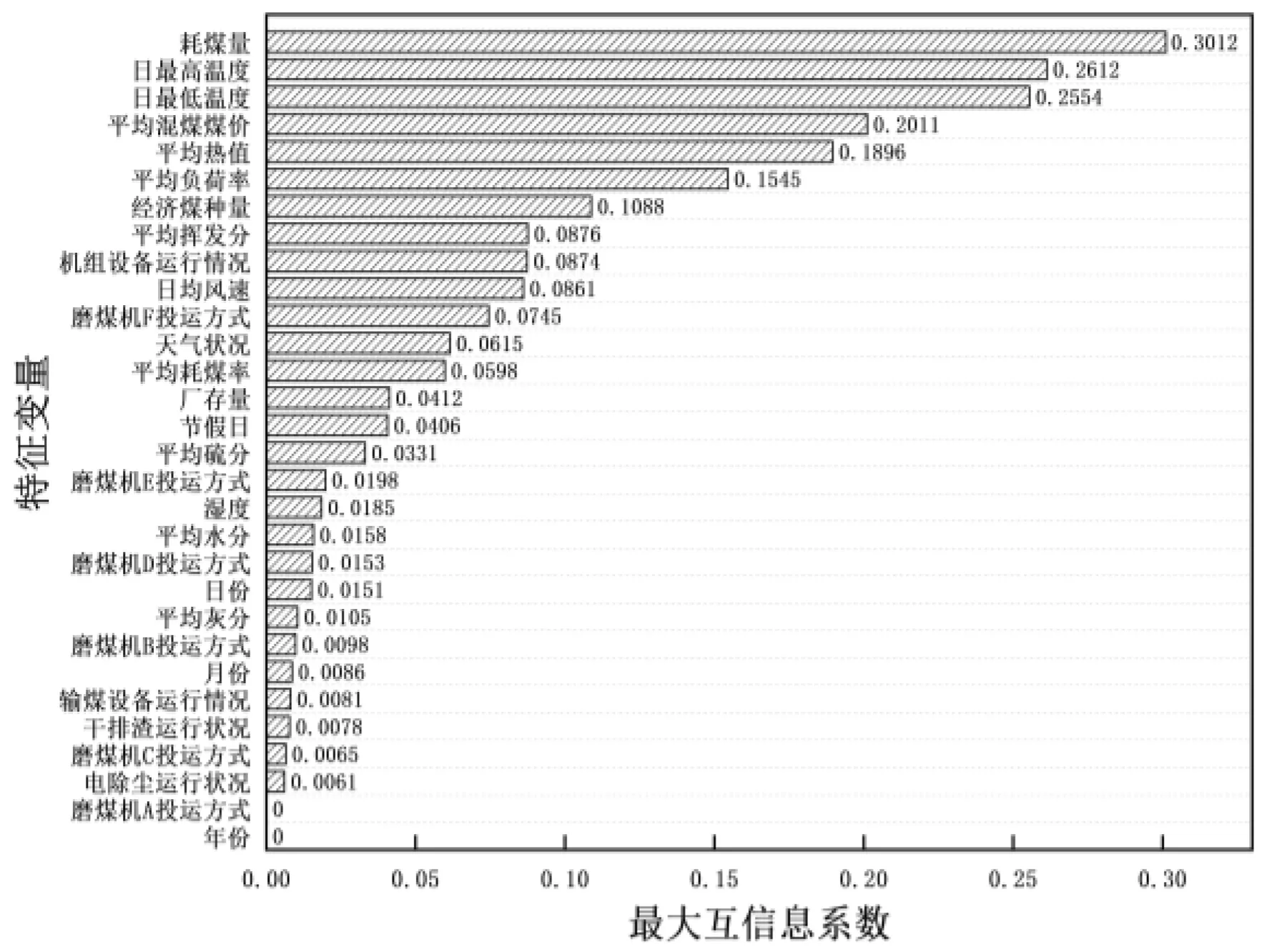
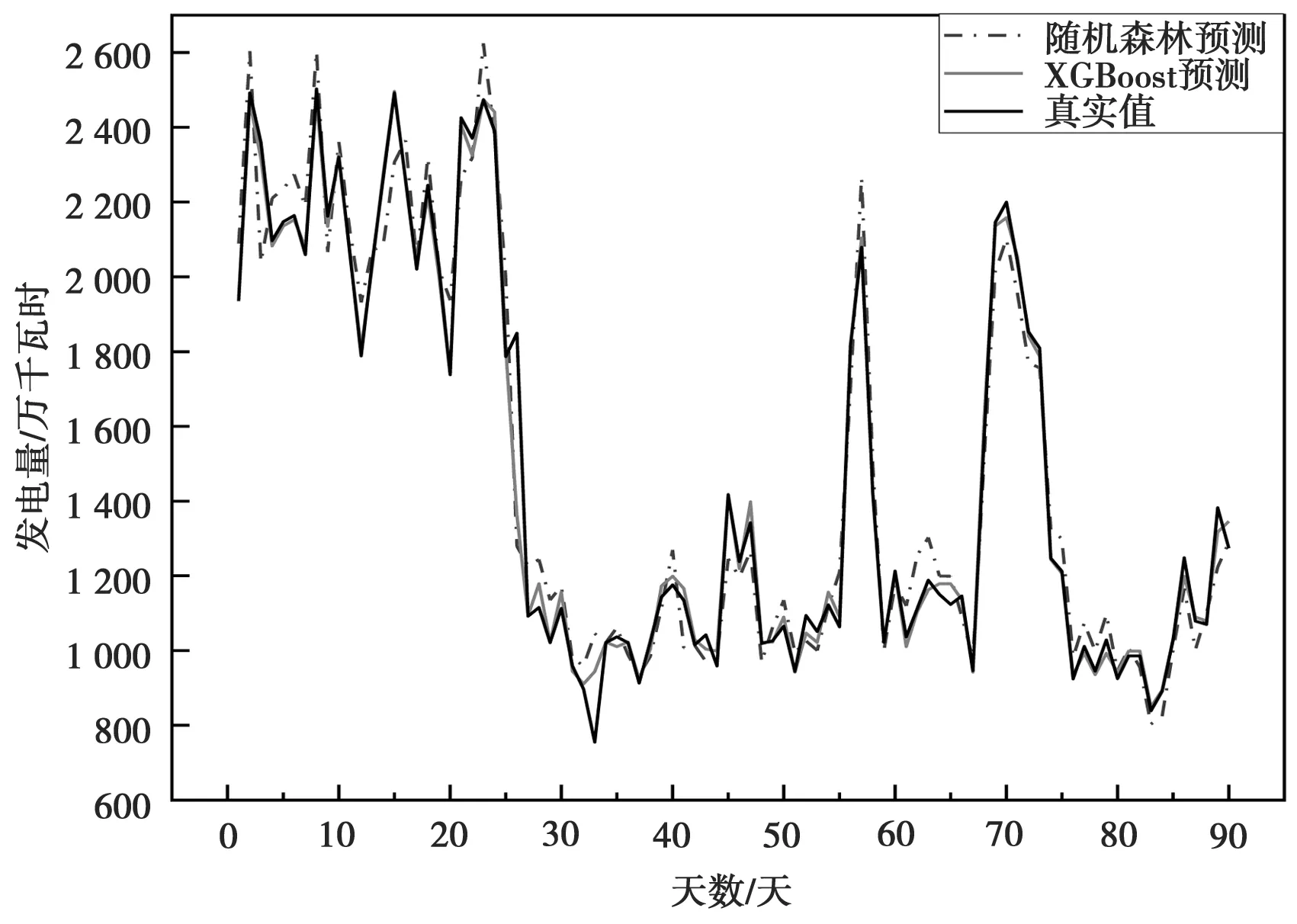
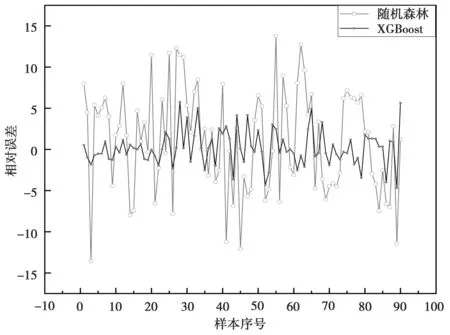
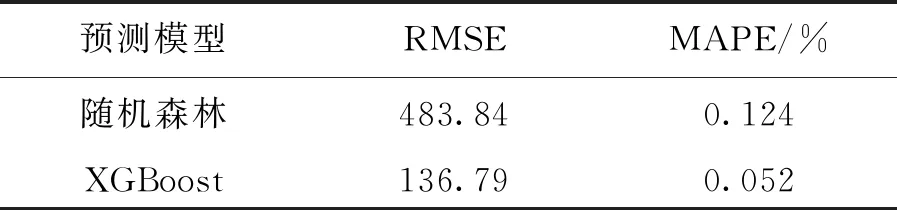
MIC(Q)=maxab (4) 式中:B(n)为网格划分(a×b)的上限值,一般给出B(n)=n0.6。 电厂给定一个多变量数据集L={l1,l2,l3,…,lm,k},m为特征变量个数,k为目标变量,可以用MIC(li,k)计算得到特征变量与目标变量之间的相关性,MIC(li,k)越大说明两者相关性越强,MIC(li,k)越小说明两者相关性越弱,MIC(li,k)等于0说明两者不相关。也可以用MIC(li,lj)计算得到两个特征变量之间共线性,当MIC(li,lj)很大时,选择其中任意变量作为特征变量均可〔13〕。 极端梯度提升(XGBoost)是Tianqi Chen等人于2016年提出的一个分布式梯度增强库〔14〕,是机器学习领域最近几年比较火热的一种十分强大的集成学习方法。XGBoost是梯度提升决策树(GBDT)的高效实现,是加法模型和前向优化算法,能够自动利用CPU的多线程进行并行计算,同时在算法上加以改进提高了精度和模型的泛化能力,防止模型过拟合。 给定样本个数为n,样本特征数为m的一组数据集D:D=(xi,yi)(|D|=n,xi∈Rm,yi∈R)。 XGBoost利用前向分布算法,学习后的加法模型为: (5) 定义目标函数和正则化项: (6) (7) 式中:T表示决策树的叶子节点个数;ω表示每棵决策树的叶子节点输出分数;γ和λ为决策树叶子的惩罚系数。 XGBoost是前向分布算法,通过贪心算法迭代寻找局部最优解: (8) 式中:ft(xi)为本次迭代的决策树。 每一次迭代寻找使损失函数降低最大的决策树,因此将目标函数改写为: (9) (10) 与正则化项相加可得: (11) 定义q函数将输入x映射到某个叶子节点上,则ft(x)=ωq(x),并定义每个叶子节点j的样本集合为Ij={i|q(xi)=j},则目标函数表示为: (12) 式中:Gj=∑i∈Ijgi、Hj=∑i∈Ijhi。 对使目标函数最小的叶节点输出分数ω求导,并代入损失函数中,优化后的目标函数为: 我们知道,无论什么样的学校,每个班都会有差生、优生,但是无论面对的是差生还是优生,教师都应当去爱护他们。和谐的师生关系是促进教学活动的顺利开展的重要条件。如教师每一个默许的点头、会心的微笑、优美的动作、亲切的抚摸,都能使学生感受到爱的鼓舞。教学过程也是情感交流的过程,很多学生往往出于对某一位老师的喜爱,而喜欢这位老师所教的的一门课程。教师对学生表现出爱心,关怀学生,尊重学生,那么学生就会以一颗纯真的爱心回报教师。 (13) 上式越小代表预测模型越好,XGBoost采用贪心算法,每次尝试分裂一个叶节点,计算分裂后的增益,选择最大增益确定树结构: (14) Gain值越大,说明分裂后能使目标函数减小的越多,模型越好。 对XGboost模型构造主要是对参数进行调整,XGboost的参数主要分为通用参数、提升参数和学习任务参数。通用参数可以设置XGboost的整体功能,提升参数可以选择每一步的上升类型(树或者回归),学习任务参数用来控制理想的优化目标和每一步结果的度量方法〔15〕。 通用参数:booster选择gbtree,silent输入0,其余参数自动指定,无需设置。 提升参数具体设置情况见表1所示: 表1 提升参数设置 学习目标参数:objective选择回归学习目标reg:linear,eval_metric设置为均方根误差(root mean squared error,RMSE)和平均绝对百分比误差(mean absolute percentage error,MAPE)对预测性能进行评价,计算公式为: (15) (16) 式中:dpi为火电厂发电量预测值;dri为火电厂发电量实际值。 基于MIC和XGBoost的火电厂发电量预测模型流程如图1所示: 图1 基于MIC和XGBoost的火电厂发电量预测模型流程图 对上海某火电厂发电量和其影响因素数据进行研究,收集从2014年1月1日至2020年12月31日共计2 557组数据,根据电厂实际情况,正式的电网调度发电计划单一般在一个半月左右下达,所以需要对90天的火电厂发电量进行预测,将2 467组数据定为训练集,90组数据定为测试集,数据中特征变量有年、月、日、节假日、天气状况、日最高温度、日最低温度、湿度、日均风速、耗煤量、厂存量、平均热值、平均灰分、平均挥发分、平均硫分、平均水分、磨煤机A-F投运方式、电除尘运行状况、干排渣运行情况、平均耗煤率、平均负荷率、经济煤种量和平均混煤煤价。原始数据见表2所示。 表2 原始数据集 由原始数据可以看出,其中有很多非数值型数据,无法直接作为特征变量输入模型中,故需要进行数据预处理工作,将所有数据统一为数值型,具体操作见表3所示。 表3 数据预处理 由于数据涉及30个变量,将所有可能影响发电量变化的因子输入预测模型中很容易造成信息重复或特征无效等问题,输入数据过多或者存在共线性都会对模型精度产生重要影响,采用MIC对特征变量进行排序并筛选,结果如图2所示。 图2 特征排序图 由图2可得,磨煤机A运行方式和年份对发电量没有影响,MIC值越大,说明变量对目标值影响越大〔16〕。选取MIC值大于0.1的7个变量作为输入特征变量,包括:耗煤量、日最高温度、日最低温度、平均混煤价格、平均热值、平均负荷率和经济煤种量。利用XGBoost算法得到火电厂90天发电量的预测值,并与随机森林算法进行比较,预测结果对比如图3、预测相对误差如图4、预测性能评价见表4所示。 图3 预测结果对比图 图4 预测相对误差图 表4 预测性能评价表 由图和表可得,采用XGBoost算法比随机森林预测效果精度更高,更加接近火电厂发电量真实值,为了验证XGBoost算法的性能优势,对预测结果进行评价,XGBoost模型的RMSE和MAPE分别为136.79和0.052 %。提高火电厂发电量的预测精度,不仅可以提前通过预测发电量得出预计的购煤量,有利于采购计划的实施,而且可以根据国家出台的控煤政策灵活调整耗煤量,大力发展绿色经济,对追求少耗煤多发电的电厂具有一定的指导意义。 4.1火电厂发电量数据复杂多变,为了建立良好的发电量数据库,采取数据收集、异常值处理、数据类型转换等数据预处理工作,减少无用数据对模型的影响。 4.2为了避免特征维度过高对模型复杂度的影响,采用最大互信息关系方法进行特征重要性排序和特征选择,得到较好的输入变量。 4.3采用XGBoost算法和随机森林算法建立发电量预测模型,通过对比得出,XGBoost算法的RMSE和MAPE评价指标比随机森林分别小347.05和0.072个百分点,具有更高的预测精度。2 极限梯度提升算法
2.1 XGBoost算法原理
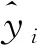
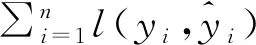
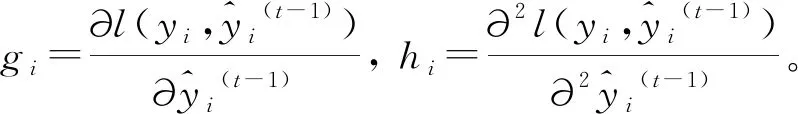
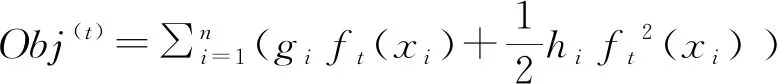
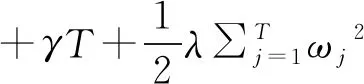
2.2 XGBoost模型构造

3 实例分析
4 结语
