数据挖掘在铁路会员价值 分析中的应用研究
2021-07-22黄巍,刘峰
黄 巍,刘 峰
(1.中国铁路北京局集团有限公司 北京铁路客户服务中心,北京 100860;2.中国国家铁路集团有限 公司 客运部,北京 100844)
0 引言
2017年12月20日铁路部门正式推出“中国铁路畅行常旅客计划”,强丽霞[1]认为铁路部门出台“中国铁路畅行常旅客计划”意味着铁路正式迈入以忠诚计划为平台的客户关系管理新领域。丁杨军等[2]认为客户关系管理是保持企业健康可持续发展的关键,通过搭建数据分析模型对客户消费行为进行分类,制定精准营销策略,进而实现企业利润最大化。丁晓银等[3]认为在大数据技术蓬勃发展的今天,机器学习、人工智能、数据挖掘、语义分析等技术已经广泛应用于客户价值分析领域中。张浩然[4]认为企业利用大数据技术对已有客户信息数据进行分析,应用多种数据分析算法挖掘客户对企业的价值,运用数据分析结果改善企业营销方式、降本增效、提高利润是企业发展的重中之重。
国内外大量技术和理论文献广泛论述了使用数据挖掘技术分析客户消费行为数据,帮助企业依据客户分类价值制定相应的营销策略。刘朝华[5]认为数据挖掘技术可以应用到以客户为中心的企业决策、分类分析和客户管理的各个不同领域和阶段,如客户群体分类分析、交叉销售、客户盈利能力预测分析和客户满意度分析等方面。徐晓敏等[6]综合应用RFM模型和K-means聚类算法对客户交易数据进行挖掘,结合客户全生命周期各阶段特点,给出不同客户在不同阶段价值提升的相应策略。罗亮生等[7]通过改进RFM模型分析航空运输企业会员价值。刘婷婷等[8]使用LRFMC指标模型和K-means聚类算法挖掘航空公司会员出行数据,为航空公司针对不同客户采取个性化的营销方案提供科学依据。
在参考上述文献的基础上,从数据挖掘的角度出发,结合“中国铁路畅行常旅客计划”会员出行数据特点,通过改进传统RFM模型,构建RFMICT会员价值评价模型,运用K-means聚类算法,聚类出具有类似特征的客户类型,针对各类型客户的典型特征进行会员价值判断,对生成的会员价值分析结果进行可视化应用分析,为铁路运输企业提出分类会员个性化营销建议。
1 相关理论和分析方法
1.1 RFM模型理论及RFMICT模型构建
RFM模型首先于1994 年由 Hughes 提出[9]。RFM模型由最近消费时间间隔(Recency,R)、消费频率(Frequency,F)及消费金额(Monetary,M) 3个指标组成。最近消费时间间隔(R)表示客户距观测日最近一次消费时间间隔,消费频率(F)表示在观测期间内客户消费总次数,消费金额(M)表示在观测期内客户消费总金额。在3个指标变量基础上再细分2类,便在R,F,M维度上产生了8类客户,客户价值模型如图1所示。

图1 客户价值模型Fig.1 Customer value model
单纯的RFM模型并不适用于铁路会员价值分析。例如,2个会员在观测期间内消费同样的金额,其中一个只购买二等座、出行距离远;另一个只购买商务座,出行距离近。二者的购买力水平和服务需求存在明显差异,对于铁路运输企业来说,二者会员价值和提供服务的成本也相差较大。因此,需要在RFM模型基础上增加平均乘车间隔(I)、客户关系长度(C)和客单价(T) 3个指标来弥补RFM模型缺陷,构建RFMICT模型评价指标,综合评价会员价值。
RFMICT模型指标包括以下参数:消费间隔(R)表示会员最后一次乘车的日期距离观测截止日期的天数,d;消费频率(F)表示会员初次乘车日期至观测日期间的总乘车次数,次;消费金额(M)表示会员初次乘车日期至观测日期间的总票价,元;平均乘车间隔(I)表示会员在观测期间内每次乘车间隔的平均值,d;客户关系长度(C)表示会员入会时间长短,d;客单价(T)表示会员在观测期内每次购票均价,元。通过上述6个指标便可以综合性地评价铁路会员消费行为价值。例如,会员总消费金额多、消费频率低、平均乘车间隔长、客单价高,说明会员出行基本选择高等级席别,会员更在意铁路运输企业提供的服务品质;会员总消费金额多、消费频率多、平均乘车间隔短、客单价低,说明会员基本选择铁路出行,对铁路运输企业忠诚度高,会员更在意积分累积和兑换等活动政策。由此可见,上述6个指标可以综合评价铁路会员价值,精细划分客户价值。
1.2 K-Means聚类算法理论
在确定了属性指标以后,就需要根据属性划分类别,研究采取大数据聚类分析中应用最为广泛的一种聚类算法——K-means聚类算法。K-means聚类计算过程是:在所有数据中随机选取K(K≥2)个点作为初始聚类中心,计算所有数据与K个聚类中心的欧式距离,将距离聚类中心较近的点聚为一类,得到K个簇[10];再次计算K个簇的聚类中心,比较新旧聚类中心是否相同,不断重复这一过程,直到前后2次聚类中心相同时停止。
1.3 手肘法和轮廓系数法
确定K值的大小是K-means聚类算法是否准确的关键,研究采用手肘法确定最佳K值。手肘法是通过观察误差平方和大小来选择K-means聚类K值的一种算法,其算法计算原理为:随着聚类数K值的增大,聚类划分会更加精细,随着每个簇的聚合程度逐渐提高,其误差平方和(SSE)会逐渐减小;当K值小于真实聚类数时,SSE对应的曲线斜率下降幅度会很大,而当K值与真实聚类数相等时,SSE对应的曲线斜率下降幅度会骤缓,K与SSE会形成一个类似于手肘形状的折线图,而“肘部”对应的K值则为当前聚类数据集的真实聚类数。但该方法也存在一个问题,即在应用于某个具体的数据集时,会出现不明显的“肘点”,此时K值的确定就会出现较大的偏差,进而影响最终的聚类结果[11]。
为了解决手肘法存在的问题,研究采用轮廓系数法进行辅助判断。轮廓系数法是通过计算分离度与内聚度来评价聚类效果好坏的一种算法,其计算方法原理为:分别计算聚类簇中每个向量的轮廓系数,系数的取值范围为[-1,1],取值越接近于1说明聚类效果越好;将簇内所有轮廓系数求平均得到每个聚类的轮廓系数,最终通过选择轮廓系数最大值来确定最佳K值。鉴于上述2种算法的特点,研究采取手肘法和轮廓系数相结合的方法确定最佳K值。
1.4 数据抽样和数据标准化
1.4.1 数据抽样理论
在数据分析模型和聚类算法确定以后,采用统计学概率抽样的简单随机抽样方法,样本数量依据社会科学领域普遍采用的样本容量范围[12]。即当调查范围为地区性调查时,选取样本量为500 ~ 1 000个;调查范围为全国性调查时,选取样本量为1 500 ~ 3 000个;被调查总体规模1万至10万人时,抽样比例为1.5% ~ 3%;被调查总体规模10万人以上时,抽样比例为1%以下。根据上述样本量抽取标准,确定抽取样本数量为5 000个。随机抽取5 000名铁路会员自2018年1月1日—2019年11月31日的所有乘车记录,共102 013条数据,包括会员ID、会员等级、会员激活日期、性别、出生年份、乘车日期、票价共7个特征属性,上述抽样数据中不存在空值和异常值等情况。
1.4.2 数据标准化理论
从上述抽取数据的7个特征属性上看,各属性在量纲和取值范围上存在较大差异,如果直接运用数据进行建模运算的话,会造成类似于票价这种数值较大的特征属性占据较大的权重,为了消除权重因素影响数据分析的最终结果,需对样本数据进行数据标准化。数据标准化常见的方法有最小最大标准化、零均值标准化和小数定标标准化等。研究按照RFMICT模型,提取对应特征属性并进行数据探索后,决定采用零均值标准化,也称标准差标准化,对6个评价指标数据采取标准差标准化处理,以提高K-means聚类算法结果的准确性。
2 聚类判断及可视化分析
2.1 聚类判断
按照K-means聚类算法、手肘法和轮廓系数法编写程序对铁路会员数据进行聚类分析,数据分析程序自动生成K值分析图如图2所示。由图2可见,当K值为4时出现明显拐点(肘部),当K值为6时轮廓系数值最大,综合判断当K值为6时分类效果为最佳,得到各类别聚类中心和数目结果如表1所示。

图2 K值分析图Fig.2 K value analysis
2.2 可视化分析
根据表1绘制客户出行特征分析雷达图如图3所示。
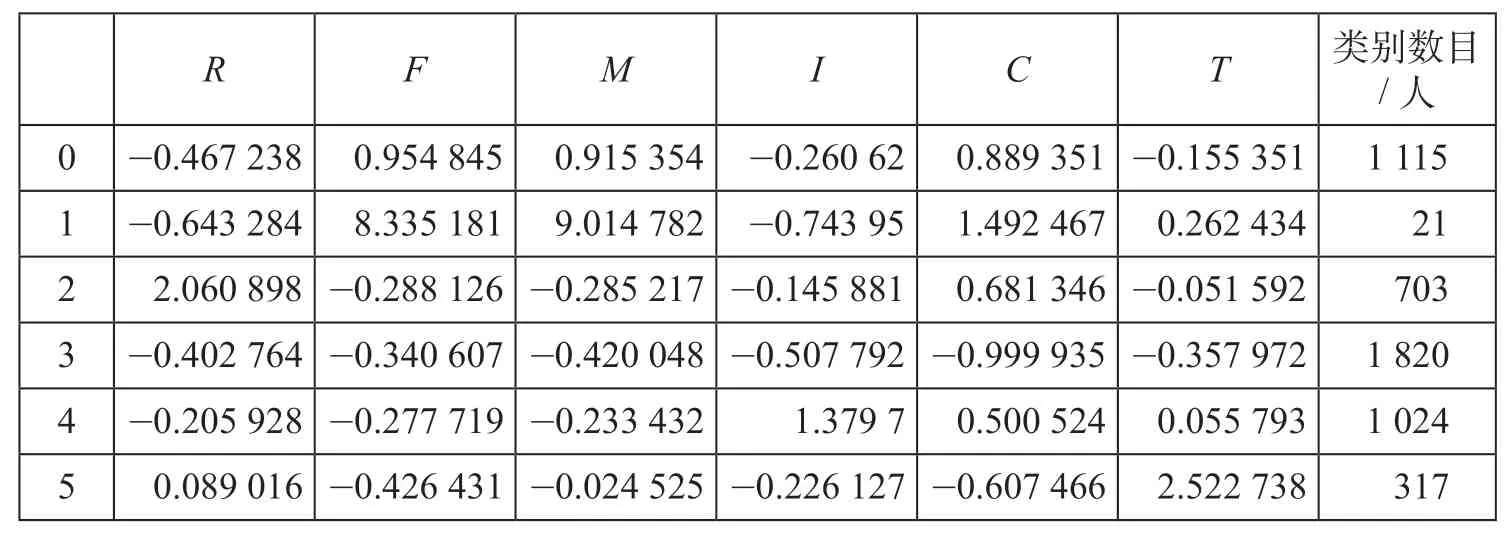
表1 各类别聚类中心和数目结果Tab.1 Clustering centers and numbers by category

图3 客户出行特征分析雷达图Fig.3 Radar chart of customer travel characteristics
由图3可知:①类别0,即雷达图中第2簇人群(黄色曲线),该类会员入会时间较长,观测期内总消费金额和总消费频率略高,消费间隔和平均乘车间隔居中,但客单价较低,对铁路运输企业忠诚度一般,属于游离客户群体,会员价值分类属于挽留型客户;②类别1,即雷达图中第6簇人群(褐色曲线),该类会员入会时间最长,消费间隔最短,总消费频率最高,总消费金额最多,虽然客单价不是最高,但是对铁路运输企业贡献最大,属于最忠诚的客户群体,会员价值分类属于高价值客户;③类别2,即雷达图中第4簇人群(红色曲线),该类会员入会时间较长,消费间隔最长,总消费频率和总消费金额都很低,属于很久没有选择铁路出行,接近流失状态的客户群体,会员价值分类属于接近流失型客户;④类别3,即雷达图中第1簇人群(蓝色曲线),该类会员因入会时间最短,因此所有属性均为最低,属于以新会员为主的新客户群体,会员价值属于培养型客户;⑤类别4,即雷达图中第3簇人群(绿色曲线),该类会员平均乘车间隔最长,其他属性均处于较低位置,属于偶尔选择铁路出行的客户群体,会员价值属于一般价值客户;⑥类别5,即雷达图中第5簇人群(紫色曲线),该类会员入会时间不长,总消费频率和总消费金额略低,但客单价最高,属于存在潜在价值的客户群体,会员价值属于发展型客户。
3 模型应用及策略建议
通过K-means聚类算法将会员分为6类,根据各类别会员人数占比绘制客户价值分布表如表2所示。将各类别会员划分为高价值客户、发展型客户、培养型客户、挽留型客户、一般价值客户与接近流失型客户,并根据各客户类型特点提出针对性建议。

表2 客户价值分布表Tab.2 Customer value distribution
(1)高价值客户。最忠诚的客户群体,占比最少,仅为0.4%,建议铁路运输企业在现有服务基础上推出个性化服务,如专属客户经理、行程规划设计、优先消费和乘车体验,满足客户的差异化、个性化需求,为企业创造更多经济价值。
(2)发展型客户。潜在价值最大的客户群体,占比6.3%,建议铁路运输企业推出仅限此类客户群体的营销活动,如积分可兑换部分热门车次、积分兑换优惠折扣、指定期间内乘车多倍积分累积等,通过精准营销,鼓励该类客户群体多消费多积分,促使其向高价值客户转变。
(3)培养型客户。以新会员为主的客户群体,占比36.4%,建议铁路运输企业推出培养此类客户群体忠诚度的营销活动,如有偿发放站车计次服务卡,按照站车服务的内容、次数和有效期不同设定服务卡金额,会员消费金额按照一定比例转化为活动积分存入会员账户,积分可用于兑换车票或参与其他会员活动,增加其对“铁路畅行”品牌的忠诚度。
(4)挽留型客户。游离状态的客户群体,占比22.3%,建议铁路运输企业加强与此类会员的沟通与维系,如通过手机APP对此类会员推送其主要出行线路的购票优惠活动、指定期间内乘车多倍积分累积活动、邀请参加预约接送站、优先进出站等一次性体验服务,建立企业与会员双向互动交流的机制,促使此类会员群体向发展型会员转变。
(5)一般价值客户。偶尔选择铁路出行的客户群体,占比20.5%,建议铁路运输企业增加“铁路畅行”品牌在此类客户群体中的曝光频率,如通过手机APP或短信在节假日、会员生日发祝福语,邀请参加客户服务满意度调查等,增强此类客户群体对“铁路畅行”品牌的认知。
(6)接近流失型客户。入会时间和消费间隔都长的客户群体,占比14.1%,建议铁路运输企业建立会员流失预测模型,对此类客户流失进行预测和分析,发现流失会员的行为规律,制定相应解决措施,改善流失趋势。
4 结束语
研究探索了一种如何在海量会员出行数据中,利用数据挖掘技术搭建模型,聚类会员消费行为规律,分析会员价值类型的方法。提出适用于铁路行业的RFMICT会员价值评价模型,该模型应用于实际脱敏数据后,能够有效对具有相同消费行为的会员进行聚类,通过对模型的聚类结果综合分析,得到了较为理想的会员价值分析结论,证明该模型能够为铁路运输企业的客户关系管理和客运营销分析提供参考。研究提出的RFMICT会员价值评价模型仍有需要改进的空间,如研究所抽取的样本数据并未出现空值、异常值等数据不规范的情况,因此未考虑当数据存在上述问题时的处理技术;在评价指标的选择方面,仅仅依照工作经验选取了自认为最为相关的评价指标开展了聚类分析和研究,对引入其他可能存在相关性的指标并搭建多种评价模型,综合对比各种模型分类结果的优劣性方面仍需进一步深入研究;研究中发现存在一定比例的接近流失型客户,如何选择数据属性搭建流失预测模型,挽回接近流失的会员,降低铁路运输企业客户流失率将是接下来研究的主要方向。
