网站时光机:美国网页存档模式探索
——以Internet Archive为例*
2021-07-21王运彬
吴 倩 王运彬
(福建师范大学社会历史学院 福州 350117)
1 引言
随着信息化时代的到来,网络的高速发展为网页资源提供了利用平台,承载了大量具有时代价值的网络信息。然而网站更新快、互动性强等服务特点使得网站信息逐渐碎片化与易逝化,这些消逝的信息成为了文化资源存档的一大阻碍。作为为社会提供综合性服务、记录与保存社会原始记忆的档案机构,更应及时捕捉网站的每一个“镜头”,为网站的前世今生留下宝贵的记忆,网站档案馆应运而生。网站档案馆是指有关主体有选择性地对具有长远保存价值的网络信息进行捕获、归档、存储等档案化管理的机构[1]。
2 研究背景
2.1 研究述评
我国对网站档案的研究始于2002年北京大学开设的Infomall项目[3],已有的研究成果主要聚集于以下几个方面:①网页归档现状研究。毕云平等分析当前我国对网页档案的主要研究内容,简要介绍美英中的四大网页档案项目[2]74-78;王芳等调查研究了国外网页归档在采集、内容、保存、访问与使用方面的现状[4],对我国的网页归档具有借鉴意义。②网页归档项目研究。李子林等采用网络调查和内容分析法对欧洲代表性国家的网络存档案例进行探索性分析[5];曹玲与颜祥林从建设模式、资源建设、开发利用三个方面对美国国会图书馆网页归档项目的发展变化进行了系统研究,提出值得我国网页归档项目借鉴之处[6];此外还有一些学者对美英法澳等相关经验较为丰富的国家进行网页归档项目研究,为国内外网页归档建设提供经验借鉴。③网页归档工作流程研究。吴硕娜等提出Web归档生命周期模型在运用中的不足及改进措施[7],为网页归档提供理论支持;黄新平分析当前国内外在网页归档的采集与保存等方面的技术运用情况[8],王萍等对国外网页档案资源利用途径与发展趋势进行分析[9]等,分别从网页归档工作过程中的采集、技术、保存、利用方面开展了研究,为我国网页归档指明了努力的方向。
2.2 实践梳理
1996年,Internet Archive网页归档项目在美国诞生,它的成功运行拉开了全球网页归档的序幕。自此之后,国内外纷纷掀起了网页归档的研究与实践热潮,详见表1。
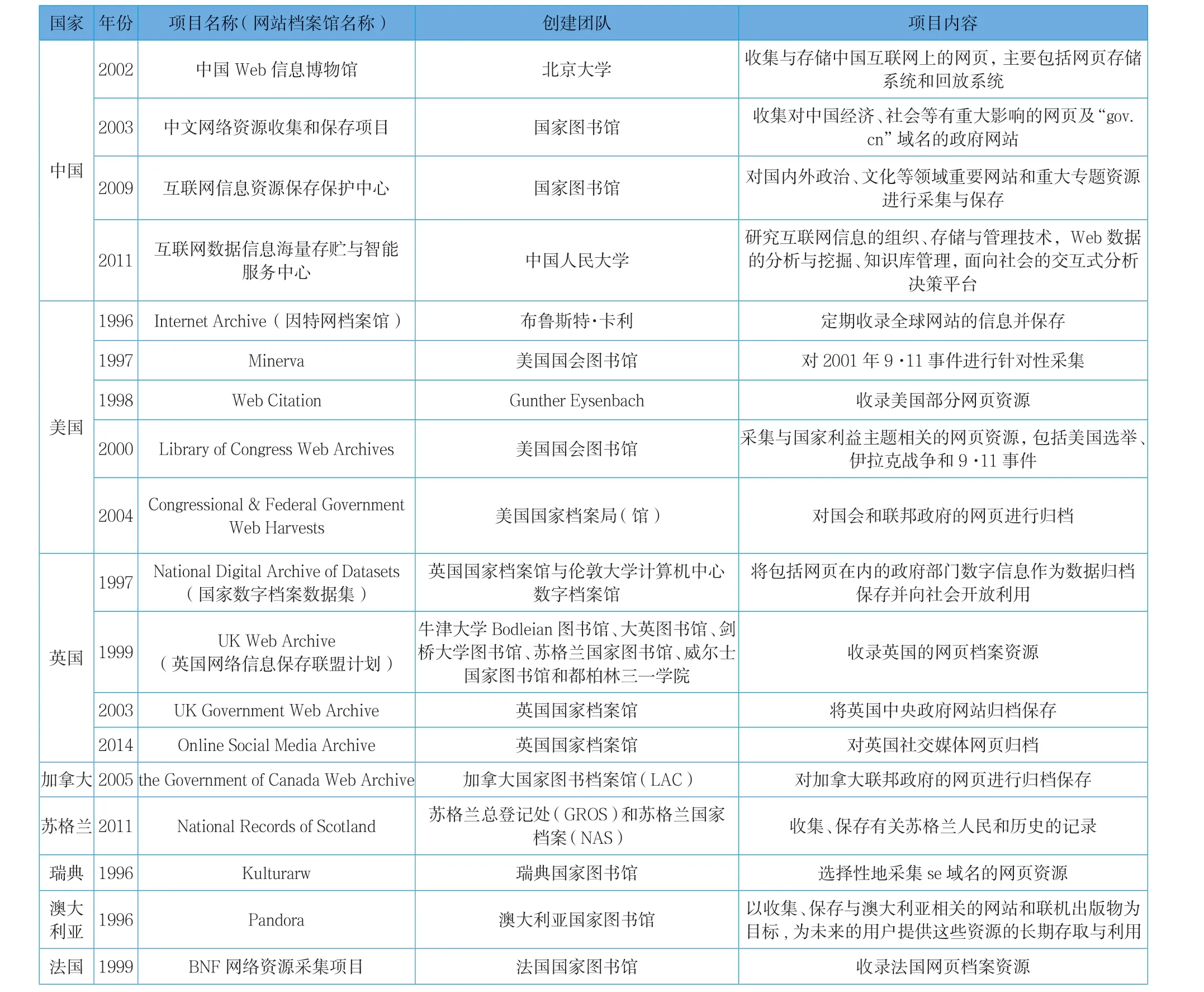
表1 国内外网站档案研究项目表
我国对网站档案馆的理论研究与开发实践的深度与广度与国外仍存在一定的差距。IA作为世界上保存网站最多最广的档案馆,在体系构建、技术开发、服务创新等方面都具有值得借鉴之处。
3 Internet Archive的实践分析
Internet Archive自1996年问世以来,在法律建设、技术应用、服务创新等领域都取得了显著的成绩,其所归档的网站也在追溯网站前世、法律凭证与学术研究方面实现了显著的实践效用。
3.1 追溯网站前世
网站信息作为人类实践的产物,反映了社会及个人真实的实践活动,具有一定的原始性与真实性。1996年,Internet Archive开发了网页回放器(Wayback Machine),允许用户查看过去时间点的网站,包括已失效的网页信息。大多数人到Wayback Machine是为了从中找到丢失的页面,所访问的网页中约65%的网站已在万维网上消逝[10]。人们只需在IA网站上输入所需的网站域名,在时间条上选择某个时间节点,便可得到该网站在该时间节点的快照信息。如在检索框中输入“www.google.com”,便会出现谷歌网站的时间条,选择2015年2月28日,即可得到当天不同时间点捕捉到的谷歌网站。IA的网站回溯功能得到了广泛的应用,如2004年7月14日,杰弗里·塔克使用IA来说明Mises.org网站八年来一直存在;人们可通过IA查询已经消失在万维网上的FreeMarketNews.com网站所记载的哈里·布朗、蒂博尔·马汉和托马斯·克纳普等所作出的贡献[11]。
3.2 法律凭证价值
网站信息记录了社会与人类的实践活动,具有一定的原始记录性,这与档案的基本属性相一致,也能作为重要的法律凭证之一。自问世以来,IA被广泛应用于各种法律诉讼,已然成为法律诉讼中证据的重要一环。如2004年10月,诉讼方美国回声星通信公司(EchoStar)使用Wayback Machine的快照作为Telewizja Polska网站过去内容的证据,这可能是第一次用IA收集的网页数据作为证据[12]。除此之外,我国颁布的《最高人民法院关于互联网法院审理案件若干问题的规定》(2018)、《最高人民法院关于修改〈关于民事诉讼证据若干规定〉的决定》(2019)等法律规定也为网页等电子存证平台的法律效力提供了法律背书。
3.3 学术研究价值
网站承载着众多时代的网络信息,如新闻、文章报道、博客数据等分布于各领域的数据资源,是学术研究的重要资料来源。一旦网站崩溃或在万维网上下线,这些重要的资料就可能会随着网站一起消失,而网站档案馆的出现拯救了这些资源,为学术研究领域保留了财富。2006年3月17日,杰西· 沃克使用了Wayback Machine使他唯一的作品得以问世,这是一篇当时已不再在网上提供的文章;2015年12月,乔纳森·费恩戈尔德使用Wayback Machine找回他写的一篇被黑客入侵的旧文章[13]。除作为学术研究的资料来源以外,网站档案也可作为网站自身发展与创新的研究素材,促进网站的服务优化与技术创新。
通过采用装饰者模式对采集模块进行设计之后,可以较灵活地对采集到的数据进行必要的处理;同时,在不改变原有代码结构体系的情况下,允许今后对数据进行进一步的运算处理和改变数据处理方法的调用顺序,符合了面向对象的“开闭原则”。
4 Internet Archive的开发亮点
IA在追溯网站前世、法律凭证与学术研究等方面都发挥着重要的作用,充分表明美国已具备成熟的网页归档经验,主要体现在丰富的馆藏资源、新型的技术软件、以用户为主的服务理念与多元的协同合作等方面。
4.1 丰富的馆藏资源为基础
为深入了解IA的网页馆藏资源,笔者统计了IA近五年的网页归档数量,详见图1。2016—2020年,IA的网页归档数量呈直线上升的趋势。截至2021年2月21日,IA已采集超过5 380亿的网页,提供超过60pb的免费书籍、电影、软件、音乐等资源以满足用户的多元化需求。其中IA的互联网档案软件收藏是世界上最大的老式和历史软件库,提供对数百万程序、光盘图像、文档和多媒体的即时访问。除此之外,IA具有极高的数据存储能力,拥有超过2 790亿个网页的Internet Archive也仅保存了15pb的数据[14]。由此可见,Internet Archive所存储的庞大网页数据库为用户查找与利用过时或已逝的网页信息提供了丰富的馆藏档案资源。
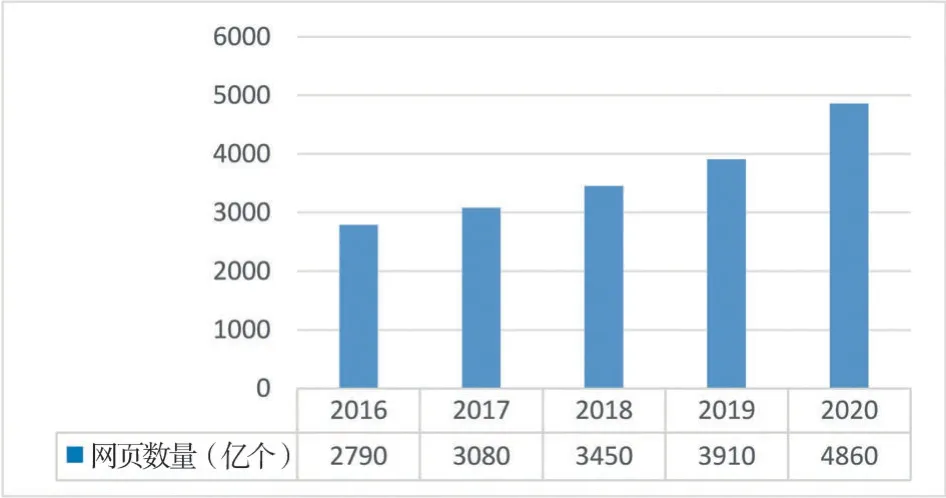
图1 2016—2020年IA归档的网页数量图
IA的丰富馆藏资源自然离不开它的资源采集策略。所谓网页采集就是及时获取网络上值得保存的档案信息资源,并通过各种软件与技术方法将其进行收集与归档,从而提供给社会利用。IA是当今世界网页采集量最大的项目,主要采用的是多种采集策略相互结合的复合式网页采集方式,包括广泛式采集与专题采集。IA同IIPC 的图书馆成员共同负责开发了Heritrix爬虫软件,实现对国家域名范围内或整个互联网的网页等其他在线资源的自动化采集。此种采集方式直接对网页进行收集而不修改,对同一网页的不同时间节点多次抓取,不遗漏任何信息,在最大程度上保证网页信息的精确度与完整度。除此之外,IA还对突发事件及重要专题进行采集,如民间音乐项目、社区精神与宗教、故事片、电视档案、美国专利和商标局文件等专题。IA收录了丰富的馆藏资源,为满足用户的网站档案利用需求提供了资源保障。
4.2 新型的技术软件为手段
IA的技术优势主要体现在其具备的网站搜集与检索软件方面。在网站搜集方面,IA主要运用的是其与芬兰、瑞典等国家图书馆联合开发的Heritrix爬虫软件。Heritrix采取抓取网页而不修改的方式,精确地捕捉每一个完整的网页内容,实现大规模的网页信息采集。在检索方面,IA主要采用的是Alexa搜索引擎与Archive-It检索软件。Alexa是互联网档案馆的创建者布鲁斯特·卡勒的著名作品之一,它通过将自己安装为浏览器工具栏并收集信息,提供了网络爬虫与其他网站的流量信息,可索引数十亿个网页[15]。被广泛使用的Archive-It不仅允许机构收集和保存数字内容的集合,而且会提供每一个集合中所有URI的列表、每个站点存档的次数和日期以及存档站点的全文检索,允许用户快速搜索其感兴趣的主题集合,并直接将网页主题集合链接到机构网站[16],为用户的网页查询提供了重要技术保障。总之,IA开发与采用了多种网页爬虫与检索软件作为网页资源保存与检索利用的核心技术,为网页资源进一步的开发与利用提供了可行性。
4.3 以用户为主的服务为核心
IA一直秉承着“以用户为核心”的服务理念,主要体现在网页收集、网页设计与民众参与三个方面。
网页收集尊重网站拥有者的意愿。IA在利用网站上提供了申诉途径,当IA所采集的网站信息涉及个人隐私或是其他不便公开的范围,用户或网站管理者不希望这些网页被存档时,便可申请退出收集,此时网页爬虫软件便会绕过这些网站。这充分显示IA在网页收集过程中“以用户为主”的原则,充分尊重网站拥有者的归档意愿。
网页设计以服务用户为原则。IA从最初的只是存储数据来支持线下利用的服务方式逐渐转为注重用户的多样化需求、提供原始页面在线访问的服务模式。IA所归档的网页资源是向全世界开放的,用户只需要连接上网络,通过浏览工具在搜索框内输入网址,系统就会自动呈现该网站的历年归档结果与归档日历,用户点击任何一个时间点便可获得该网站此时的状态。IA提供了iOS与Android两种系统的手机App在线服务方式,用户通过网站上开设的App下载窗口便可获得“指尖上的网站档案馆”。除此之外,IA还提供多种语言检索与标题导航,将归档资源按照文件类型、网站与主题进行分类,以满足全世界不同国家的用户要求。
带动民众参与IA建设。IA的优势之一就是来自许多民众上传他们或他们社区创建的项目。民众作为档案馆的一员,只需要注册便可获得一张虚拟卡,通过该卡可以建立收藏列表,为项目提出意见,发表评论,还可以上传自己的项目到档案馆的收藏之中。民众作为档案馆的一员也可将文件上传到IA的书库、文本、图像、电影、音频等资源库,充分实现了“档案众包”的开发模式与“民馆合作”的服务理念。
4.4 多元的协同合作为发展
Internet Archive作为全球第一个互联网档案馆,自1996年建成以来就一直致力于多元协同合作的发展模式,主要体现在资源、项目、技术方面的合作交流,详见表2。IA通过与其他图书馆、博物馆、企业等机构合作,共同开发资源采集与存储的新型技术,也获得了一定的资金支持。值得一提的是,IA于2003年7月与澳大利亚、加拿大、丹麦等国的国家图书馆及美国国会图书馆共12个机构联合组成国际互联网保存联盟(International Internet Preservation Consortium,IIPC),它采用责任平等的合作机制,鼓励世界范围内的文化遗产保护机构一起参与网络信息资源保存的工作,目前IIPC已吸纳40多个机构成员[17]。IA与其他成员的合作往往采取一对一的模式,合作之间没有明确的权责。这种合作模式虽具有一定的松散性,但也在一定程度上增强了合作的自主性。机构成员的多元化不仅促进了国际上网站归档的技术交流与经验共享,对资源采集、永久保存、元数据等方面的规范标准及技术的形成与发展也起到了一定的推动作用。
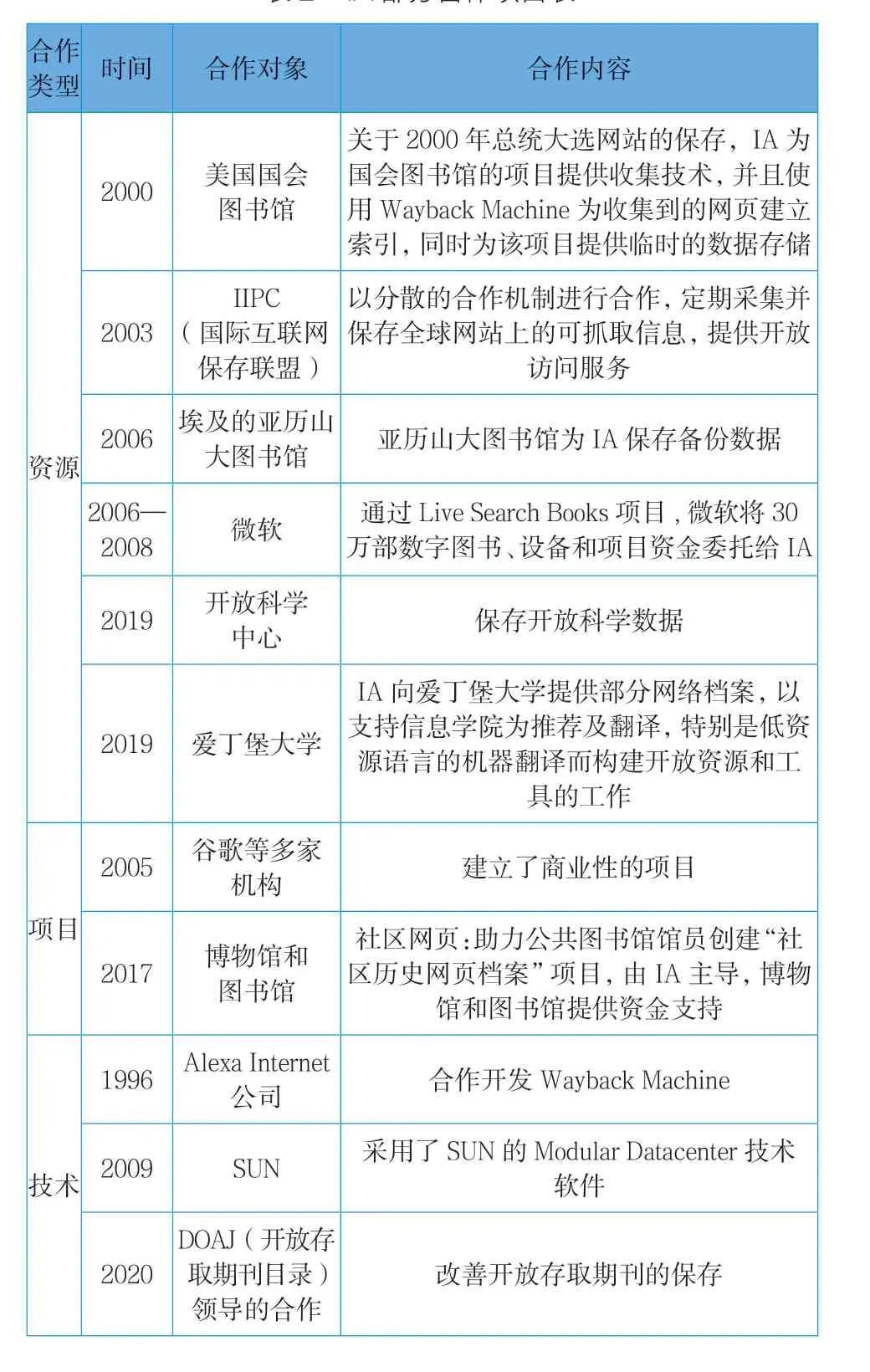
表2 IA部分合作项目表
5 我国网页归档的建设方向
美国IA的网页归档项目起步较早,其丰富的馆藏资源、新型的技术软件、以用户为核心的服务理念与多元的协同合作等方面的开发亮点,在体系、合作、技术、人员、开发与危机防范等方面为我国网页归档的建设与优化指明了方向。
5.1 体系层面:加强顶层设计,形成以档案馆为核心的分布式网页归档体系
2016年4 月,国家档案局印发的《全国档案事业发展“十三五”规划纲要》提出要将“研究制定重要网页资源的采集和社交媒体文件的归档管理办法”作为提升电子档案管理水平的任务之一。但我国仍缺乏对网页归档的统一体系建设,使得各网页归档项目在实践时无章可循。国内网站档案馆可遵循“统一领导,分级管理”的原则对我国网页进行归档。国家层面应建设国家网站档案馆,负责统筹规划和统一管理。各省市级的网站归档工作将依托于各省的市区县级数字档案馆,利用现有的人力、技术、馆藏等进一步发展网站档案的收集与开发利用工作,从而形成以国家档案馆为核心的分布式网站收集模式。
在以档案馆为核心的分布式网站归档体系建设下,我国应实行多种上交制度相结合的综合归档模式。按照网站归档的要求,可将归档制度分为呈缴本制度、自愿归档制度与自动捕捉制度。呈缴本制度是指国家以法律或法令形式规定全国所有出版机构或负有出版责任的单位,凡出版一种出版物必须向指定的图书馆等机构免费缴送一定数量的样本[18]。呈缴本制度同样适用于网站归档,即以国家法律或法令形式规定某些重要网站定期向数字档案馆呈缴网页档案,如政府网站、档案馆网站等。自愿归档制度是指相关部门自愿向数字档案馆定期提交网站或向档案馆申请网站捕捉归档的制度,如社交网站、个人网站等。而其他部门的网站则可由数字档案馆根据国家法律规定将具有归档价值的网站进行自动捕捉。多种制度相结合的综合性归档模式能够弥补各归档制度的不足,以实现网站归档效益的最大化。
5.2 合作层面:纳入第三方主体,创建国际国内“双合”的运行模式
IA自1996年创建以来,一直秉持着多方合作的运营理念,从而获得了丰富的馆藏资源、高水平的技术与综合人才等,这对于正处于网页归档探索阶段的我国具有很大的借鉴价值。我国网站档案馆应积极纳入如企业、高校等第三方网页归档管理主体,采取国际国内“双合”的运行模式。
国内合作。网站档案馆本质是通过爬虫软件对网页进行采集,将其存储到数字存储库,并通过检索软件等向用户提供网页利用。网站档案馆的运行涉及多领域的知识背景与技术软件,仅靠档案部门无法达到网站档案馆应有的服务效果。基于此,网站档案馆可聚集社会第三方力量的协同合作。如在技术方面,网站档案馆可同相关的数据存储机构、技术开发部门等合作,为网页档案的采集、永久保存与开发利用注入新鲜的技术血液;在资金方面,可从政府投入、社会捐赠等多途径入手,为网页归档提供资金保障;在人才方面,可与高校形成合作,使高校成为网站档案馆的人才储备中心。除与第三方机构的合作外,各网站档案馆也应加强馆际合作,实现网站资源的共建共享。
国际合作。国外的网站档案馆起步较早,建设也相对较为成熟,对于我国处于刚刚起步阶段的网站档案馆建设有值得借鉴的经验与技术软件,因此国际合作显得尤其重要。我国可与美国、英国等网站归档经验较为成熟的国家开展技术方面的合作与交流,引进国外先进的技术软件等。但由于部分网站档案涉及国家机密,我国应视情况选择网站档案国际合作模式,即根据网站性质与内容的不同,有选择性地开展网站归档的国际合作。
5.3 技术层面:引进新技术,形成覆盖网站归档运行周期的保护框架
随着技术的不断发展,档案信息的有效载体日益增多,使得网站呈现格式多样化的档案信息载体,如3D展厅、H5、影像视频等。要让这些数字档案保持原始性、真实性、可读性,就必须不断引进与更新覆盖网站归档的采集、永久保存、网页利用等整个运行周期的技术,为网站档案营造安全的电子档案存储环境,以满足档案的存储与利用需求,形成前瞻性的保护框架。
在网站档案收集前期,网站档案馆必须具备多样化档案格式识别、网页重建与深度挖掘技术。一旦发现采集的网页受到硬件破坏、黑客入侵等造成网站数据丢失,网站档案馆必须利用网页重现技术开展网站恢复工作,确保网站信息的可访问与可获取[19]。除对网页进行抓取以外,爬虫软件还需完成对网站中链接的其他一级、二级、三级等网页的采集,有效保证采集的网站与其链接信息之间的联系,形成较为完整的“语境”与电子档案元数据的原始环境。在网站档案保存阶段,网站档案馆应构建符合电子档案长期保存条件的虚拟环境,不断更新数据库的存储能力,如美国IA采购了Sun Modular Datacenter等一系列技术,大大扩充了自身的存储能力。此外,网站档案存储库还需保证网站档案不受网络黑客等的恶意破坏,从而维护档案的真实性与可读性。在档案服务阶段,网站档案馆必须具备档案的鉴别技术,确保输出的网站档案与采集时的电子档案一致,维护档案的真实性。因此,网站档案馆必须与时俱进地更新分布于每一个网站归档运行阶段的管理技术,形成覆盖全周期的技术保护框架,从技术上保障网页档案的真实性与可靠性。
5.4 人员层面:提高人员素养,实现网站归档的前端控制与后端检测
2017年美国国家数字管理联盟(NDSA)的网络档案调查报告显示,开发成功的Web归档程序必须具备归档工具、评估和选择、质量保证等三大技能[20],同时具备这三大技能对于档案工作人员而言难度较大。IA自1996年建成以来就一直秉承着协同合作的态度,与图书馆、州档案馆、学术机构等合作获得技术与人才方面的支持。我国网站档案馆也应在提高档案工作人员的管理技能与科技素养的基础上,引进各领域的专业人员,形成综合性的人才队伍。
爬虫软件的广泛式无选择性的网页采集策略难以保证网站档案的真实性与完整性,甚至导致部分“非法内容”被采集保存,这就要求网站档案管理人员必须加强对网站档案的前端控制与后端检测。在网站存档前期,档案管理人员必须对采集的网页进行鉴别,包括网页的完整程度、密级属性、内容合法性等,确保网站档案采集的准确性与完整性,形成对网站档案归档的前端控制。在网站档案利用后期,档案管理人员要确保用户所需的网站档案可公开且与归档前的网站档案信息相一致,从而保障档案利用的真实性与机密性。网站归档的前端控制与后端检测对档案网站的归档与利用形成前瞻性的保护体系,为实现网站档案的管理与利用提供重要保障。
5.5 开发层面:挖掘网站资源,创新服务理念与资源利用方式
网页档案作为一种数据化信息资源,更大程度上实现了档案信息的可交换性,即以数据化的形式独立存在的网页档案资源在与普通网络信息一样实现无损交换的同时,促进网页档案内容信息的价值实现,从而激发网页资源的显性知识与隐形信息的挖掘与价值提升[21]。然而,现今大部分的网站档案馆都只提供简单的网站采集、永久保存、直接利用等服务内容,缺乏深度与广度的档案资源整合与服务挖掘。档案作为一种信息资源,倘若只是提供简单的归档、保存与利用等服务,则很大程度上降低了其实际价值。基于此,IA也尝试进行了档案资源集成的未来规划。2020年7月28日,IA宣称将与滑铁卢大学形成合作,为研究和管理网络档案的学者、研究人员、图书馆员和档案工作者提供易于使用、可扩展的工具,即档案释放项目[11]。档案释放项目是为了给学者提供能将网络档案数据转换为易于使用格式的独立服务,并通过互联网档案集成来实现该项服务,从而达到学者通过一个门户网站就可收集和分析网络档案内容整个运行周期的效果。因此,我国网站档案馆必须在网站档案服务的利用方式、个性化服务与资源增值服务方面有所创新。
在检索方式上,我国网站档案馆应突破当前以关键词检索、URL检索等为主的单一检索模式,引进当前信息检索领域的热点技术,如智能检索、可视化检索、用户画像技术等。这些技术可以提高检索系统的信息查找能力,更具针对性地帮助用户查找到所需档案资源。在个性化服务方面,网站档案馆可根据用户注册的职业、兴趣等信息,提供个性化的服务功能,以提升用户的体验效果,如针对老师的职业属性提供“教学设计”等独有的功能。在资源增值服务方面,网站档案馆可对资源的使用情况及用户的行为进行挖掘与分析,进而提供资源利用情况分析、价值评估、数据可视化分析、“信息找人”等增值服务。如Netflix和Google利用消费者的集体智慧,将观察到的行为信息转化为相关的搜索结果或建议。总之,网站档案作为新时代的信息产物,仍存在着大量值得深入挖掘的价值。为实现网站档案价值的最大化及档案服务的最优化,网站档案馆必须进一步深化“主动式”的服务理念,通过深入挖掘网站档案的资源价值,为用户提供个性化的增值服务。
5.6 防范层面:树立危机意识,形成以网站档案馆为核心的多独立站点存储库
电子档案的不稳定性使得网站档案馆必须具备足够安全的运行系统。在这种情况下,网站档案馆有必要建立档案副本与档案异地备份体系,将档案资源存储分布在多个地理独立的站点上,以提供故障转移和灾难恢复。以美国IA的异地备份功能为借鉴,其于2006 年在亚历山大图书馆设立档案备份,为IA存储的网页档案资源提供了安全保障。因此,我国网站档案馆也应在档案的安全防控方面有所延伸拓展。
我国网站档案馆可建立多个独立物理备份数据存储库,以存储归档的网站档案副本,提供元数据存储空间。存储库一般只作为存储备份网站档案的存储库,不对外提供利用。各物理备份数据库通过数据互通的运行模式自动更新网站档案馆所采集的网站档案,形成信息资源共建共享。但一方存储库检测出某网站档案馆或某存储库受到破坏而出现故障时,各存储库则会自动断开互通的连接通道,进入资源保护状态。此种运行模式通过建立以网站档案馆为核心的多个独立站点存储库,形成安全的异地备份体系,为档案的故障转移与灾难恢复提供重要保障。
