基于改进YOLOV3 算法的弹库目标识别方法研究
2021-07-18何伟鑫邓建球刘爱东丛林虎
何伟鑫,邓建球,刘爱东,丛林虎
(海军航空大学 岸防兵学院,山东 烟台 264001)
0 引言
随着我军实战化水平的提升,存储导弹等火工品的导弹仓库工作日益繁忙,弹品及其对应的数量不断增加,对于弹库的管控提出了新的要求。目标检测技术是深度学习领域研究的一大重点,其核心是机器通过卷积神经网络对特征进行提取以及学习,而后搭建其对应的网络。目标检测技术是当前深度学习以及图像处理领域的研究热点。因此将目标检测技术应用于弹库目标的识别,能够辅助人员对弹库目标的管控同时将人工智能技术应用于弹库,是目前我军信息化、智能化建设的主流。
传统的目标检测方法将基于机器学习的分类算法以及特征提取进行结合以实现检测。文献[1]使用Ad⁃boost 算法与Haar 算法训练级联分类器对人脸进行检测,效果较好。文献[2]利用改进Grassberger 熵对目标属性进行提取,并结合随机森林对是否包含目标进行预测,使得其准确率进一步提升。随着深度学习技术成为研究热点,卷积神经网络(CNN)在图像处理领域获得了不可忽视的成就,出现了大量以深度学习为基础的目标检测算法。文献[3⁃4]将R⁃CNN 算法应用到目标检测领域中,并且获得了较大成功,而后又提出了系列改进算法Fast R⁃CNN[5]及Faster R⁃CNN[6]。不过Faster R⁃CNN算法检测精度虽高,但其实时性较差。为提升检测速度,文献[7]提出one⁃stage 的YOLOV1 算法,该算法使用CNN 直接对目标类别以及位置进行预测,但其检测精度不理想,于是又提出YOLOV2[8]算法,该算法在YO⁃LOV1 的研究基础上新增批归一化[9](Batch Normaliza⁃tion,BN)层,使得训练速度得到提升,使用锚框(anchor box)以及更高分辨率的分类器以提升精度。同样,基于one⁃stage 思想,文献[10]提出多尺度预测的SSD 算法,不同尺度特征图对不同尺寸的图象进行预测,既能保证精度又能兼顾速度,但预测层对浅层特征的表达能力较弱。而后文献[11]进一步提出YOLOV3,该算法采用Dark⁃Net53 网络结构,利用多尺度特征预测目标,既保持了检测速度又提升了检测精度。但YOLOV3 网络较YO⁃LOV2 算法,网络结构更为复杂,卷积层数目大幅增加,加大了小目标在深层卷积过程中特征消失的风险[12]。
为提高YOLOV3 算法检测精度,本文在YOLOV3 算法的基础上进行改进:用DenseNet 网络改进原模型的DarkNet53 网络,以提高特征提取能力;以soft⁃NMS 算法替换原模型的NMS 算法,提升了模型的检测精确率。
1 相关算法原理
1.1 YOLOV3 算法原理
YOLOV3 组成结构为DarkNet53 网络及多尺度预测网络,分别对目标特征进行提取以及预测。DarkNet53包括由卷积构成的残差块和卷积层。
图1 为残差结构示意图,其中加号代表相加操作,可表示为:

图1 ResNet 结构图

式中:x以及F(x)为残差层的输入,F(x)是x经过两次卷积所得输出。两卷积层的卷积核为1×1 和3×3,步长为1。同时,YOLOV3 网络为提高性能,卷积层后面均加入BN 层以及线性单元[13](leakyReLU)。添加BN 层能够使得训练过程收敛得更快,而激活函数leakyReLU 能够防止网络中产生梯度消失的情况。
图2 为YOLOV3 网络结构参数。大小为416×416 的图像输入到DarkNet53 网络后输出三种尺度的特征图。图2 左侧的数字说明与之对应的是残差迭代的次数,网络最终输出5 种尺度大小的特征图[14],分别为:208×208,104×104,52×52,26×26,13×13。

图2 YOLOV3 网络结构图
YOLOV3 对图像进行预测的特征图尺度大小分别为:52×52,26×26,13×13。但在输出结果前,首先要对特征进行融合,把高语义低分辨率及低语义高分辨率的特征进行拼接,于是高分辨率的特征也能够具有较多语义信息。该过程可分为以下步骤:开始在尺度为13×13 的特征图执行卷积5 次,卷积核大小分别为1×1,3×3,1×1,3×3,1×1,步长全部是1。接着卷积核大小为3×3,步长全部是1,卷积核减少到原来一半个数的卷积层,从而降低维数。然后对特征进行上采样,倍数为2,之后拼接上级特征(尺度大小26×26),重复以上操作与特征图尺度为52×52 进行拼接。最后再融合尺度大小为13×13,26×26,52×52 的特征图得到预测结果。
得到预测结果的三种尺度的特征图,其特征图的每个网格得到3 个预测框,每个预测框预测目标相对每个网格的偏移量得出中点(x,y),高宽(h,w),对是否含有目标物体的置信度p,所有类别分数值进行预测。三个尺度特征图共输出10 647×(13×13×3+26×26×3+52×52×3)个预测框。YOLOV3 对输出的预测框首先通过置信度阈值筛选,而后非极大值抑制(NMS)算法对对同一目标的冗余候选框进行剔除以获得最终预测结果[14]。
1.2 DenseNet 原理
CNN 的高速发展,学术科研人员提出了很多非常优秀的网络模型,其中GoogleNet、VGGNet、ResNet 等网络模型均获得了非常好的效果。但是随着网络层数的加深,模型的性能并非越来越好,在训练模型的过程中可能因为网络层数过多导致产生梯度消失的现象。因此研究人员提出一系列的解决办法来防止梯度消失,比较典型的是ResNet 网络提出了一种残差结构使得信号可以在输入层和输出层之间高速流通。文献[15]基于这个思想理念提出一种全新连接模式:将网络中每个Dense 块的所有层均进行连接,以将网络中的所有层之间的信息流最大化,这样网络中的任意层都会接收来自前面任一层的信息输入。
图3为该连接示意图,这种连接方式较为密集,因此将这种结构称为DenseNet。DenseNet 可缓解网络层数加深和变宽之后带来的梯度消失问题。该网络摆脱传统网络模型加深变宽的思想,从特征角度去考虑。将特征不断重复使用以及设置旁路(Bypass),使得使用少量的卷积核就可以生成大量的特征,最终模型的尺寸也比较小,使得网络不仅大量缩减了参数量,还在一定程度上减缓了梯度消失问题的产生。图3 中每一个Denseblock 中特征图大小相同,不同的Denseblock 间设置卷积层以及下采样层。最后一个Denseblock 后,经过classification block,由采样层及全连接层组成,最后通过softmax 得到prediction 结果,输出分类概率。

图3 DenseNet 示意图
表1为DenseNet系列网络以及ResNet网络在CIFAR以及SVHN 数据集上的结果[16]。从表1 中可以看出,DenseNet 的效果明显优于ResNet。
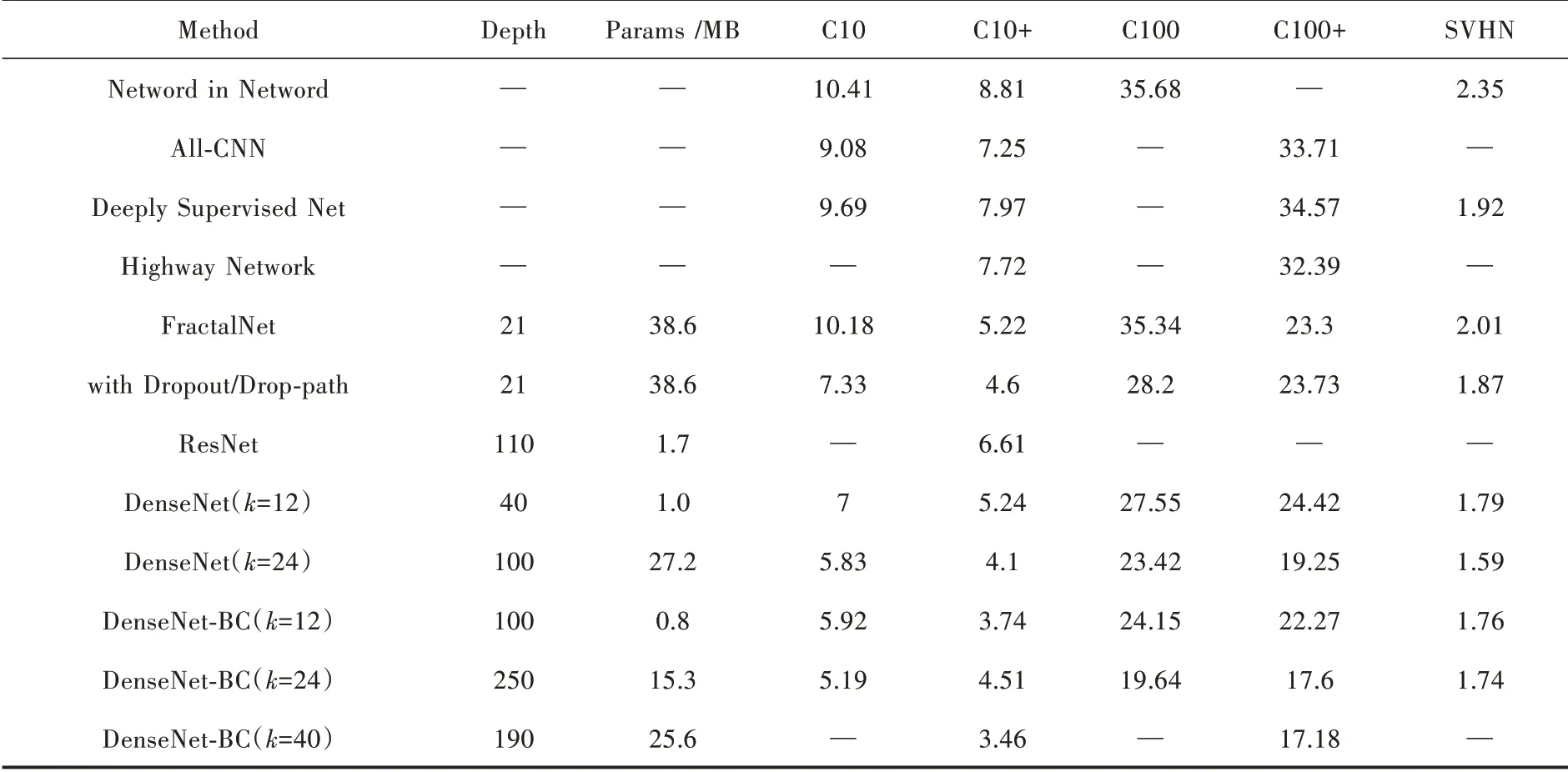
表1 各模型实验结果对比
1.3 非极大值抑制算法
非极大值抑制(NMS)算法被广泛应用于计算机视觉领域。该算法的目的为剔除多余候选框从而寻找到最佳的物体检测框。图4 为该算法示意图。

图4 NMS 算法示意图
NMS 计算步骤[17]为:
1)把输出的检测框以相应类别置信度降序排列,得边框列表;
2)把置信度值第一的框移入到输出边框列表中,而后从原边框列表移除;
3)求出全部检测框面积;
4)计算边框列表中的所有边框与置信度最大的边框间的交并比;
5)将交并比阈值大的边框从边框列表移除;
6)迭代执行前5 个步骤,当边框列表为空时,程序停止,此时输出列表中的边框即为最终预测框。
NMS 算法的分数重置函数为:
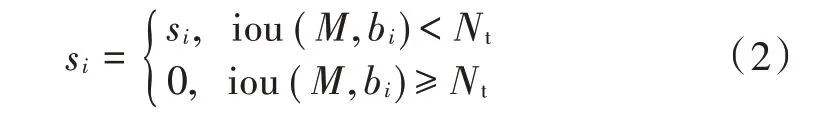
式中Nt表示设定的交并比阈值。在NMS 算法中,使用一个特定的阈值,该阈值的选取对模型输出的准确度至关重要。如果选取较小,可能发生漏检;且该值不能较大,是为了防止同一目标被多个框表示的情况,其实就是保留同一个目标的类别置信度最高的候选框。YOLOV3 算法将该阈值设定为0.5。
2 算法改进
弹库目标数量大、种类多、目标形态较为相似,因此为了使YOLOV3 模型对弹库目标具备更高的检测精度,对原算法做出如下修改。
2.1 使用DenseNet 改进YOLOV3
在训练神经网络时,因为存在卷积层以及采样层,导致特征信息慢慢减少以至消失。而DenseNet 可以比基于残差结构的DarkNet53 网络更高效地对特征信息进行提取[18],减轻了因为层数太多从而造成梯度消失问题,式(3)、式(4)分别为ResNet 以及DenseNet 的特征信息传播方式。

式中:l代表神经网络的层数;H(⋅)表示非线性函数;xl为第l层输出。对于ResNet网络,第l层的输出为上一层的输出与Hl(xl-1)的和,即l-1 层输出以及其非线性转化值之和;而DenseNet 从第0~l-1 层的输出全部进行非线性变换,接着在维度上进行连接得到第l层的输出。DenseNet 相比ResNet 能够实现特征重用,使得网络的计算效率得到进一步提升,因此本文采用DenseNet 提取图像特征。
基于DenseNet,如果将DarkNet53 全部替换为DenseNet,在训练过程中可能出现损失函数震荡的问题,从而会导致检测率不足[17]。因此将第43~59 层,第68~80 层两个部分改为DenseNet 形式,分别设计Dense block,该法既能保留浅层特征又利于预防网络训练中的损失函数震荡。将网络第45~59 层、第68~80 层之间的所有shortcut 层替换为route 层,在第76、78 层之后增加route 层,每个route 层前三层的输出作为该route 层的输入,如图5 所示为实现前后层特征的密集连接。

图5 改进后的网络结构图
2.2 以soft⁃NMS 对检测框进行选择
在弹库的实际工作中,摄像头捕捉到的画面往往存在着许多重叠的火工品,而直接使用传统的NMS 算法很容易将重叠度较大的检测框直接剔除,从而造成漏检。如图6 所示,两种颜色的检测框均为预测结果,但是按照传统的NMS 算法,将会剔除绿色框,从而造成漏检的产生。基于这种情况,本文提出对于交并比较大的预测框,不是直接对其进行剔除,而是减少它的置信度。

图6 传统NMS 检测图
针对此情况,采用soft⁃NMS 替换传统的NMS,利用高斯加权降低交并比值大于阈值的检测框的得分,而非将其粗暴置0,从而减少模型漏检的几率,soft⁃NMS 公式为:

式中σ为常数。
soft⁃NMS 改变传统NMS 对交并比较高的检测框直接去除,以降低其置信度的做法进行替换,使得其存在继续进行比较的可能性,从而减小了正确的检测框被误删的几率,提升了检测平均精度[19]。
3 实验结果分析
本研究中,用P代表精度,用R代表召回率,精度和召回率计算如下:

式中:TP 表示真实正样本的数量;FP 表示被判定为正样本的负样本数量;FN 表示被判定为负样本的正样本数量[20]。
本研究使用平均精度(AP)表示模型的性能。AP定义为:

AP 值越大意味着性能越好。P(R)在这里代表由P和R组成的曲线,图7为一个P⁃R曲线示例[20]。
图7 P⁃R 曲线示例
3.1 实验配置及数据集
本文实验在Ubuntu 16.04 系统下进行,CPU:酷睿i5⁃8400 2.80 GHz,显卡为GTX1060,显存为6 GB,计算机内存为16 GB;使用C 语言以及Python 3.6,同时配套OpenCV 4.1、tensorflow 1.14 等模块支持实验进行。
本实验数据集为在某部弹药保障大队进行获取的5 种火工品图片共2 475 张,以8∶2 的比例划分训练集以及测试集,其中大部分图片均包含多个目标,且实验过程中采用在线数据增强的方式对数据集进行扩充。训练图片之前,会先对图片进行随机的数据增强:旋转、剪切、翻转以及平移等,因为弹库的光照保持稳定,因此不需对光照变化进行处理。
3.2 使用DenseNet 改进YOLOV3 的性能比较
将DarkNet53 相应层改为密集结构,命名为DeYOLOV3,为验证本研究提出方法的有效性,本文将YOLOV3、DeYOLOV3 算法的性能作对比,得出其结果见表2(火工品均未给出具体型号名称)。
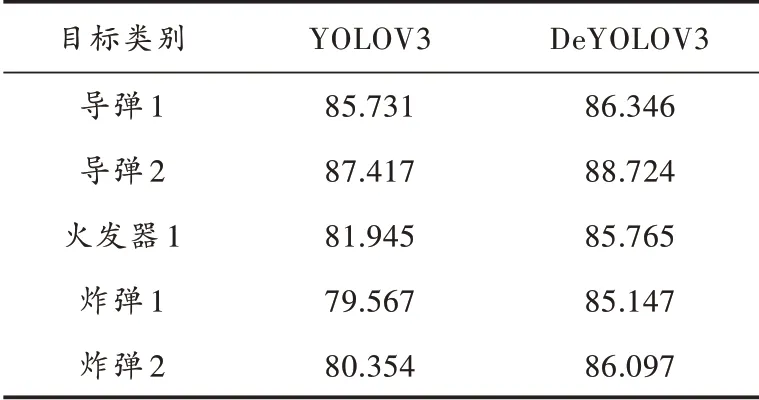
表2 不同方法AP 对比 %
从表2 可得,对比于原始YOLOV3 算法,本文提出的DeYOLOV3 使得各火工品的AP 均有了显著的提高,特别是对于炸弹等目标较小的火工品,AP 的提升更为显著,由此证明,研究提出的DeYOLOV3 的性能优于传统YOLOV3。
3.3 以soft⁃NMS 替换传统NMS
基于DeYOLOV3,使用本研究提出的soft⁃NMS 替换NMS 算法。程序实现后,由于NMS算法没有涉及到未知参数需要进行更新,因此改进NMS 算法后的YOLOV3 模型不需进行训练即可直接进行测试,表3 为其测试结果。

表3 两种NMS 算法的AP 结果对比 %
通过表3 数据可得,改进NMS 算法后,模型对大部分火工品的AP 均有提高,其中导弹1 的提升最高,原因是导弹1 的体积最大,在图片序列里面重叠较大。由此可以得出,本研究提出的改进NMS 方法对弹库火工品的检测精度优于传统的YOLOV3 算法。
4 结语
针对弹库目标种类繁多,数量以及形态各异需加强对弹库管控的实际情况,本文提出结合计算机视觉技术对弹库目标进行检测识别。由于YOLOV3 对小物体检测率不足,本文提出一种基于DenseNet 以及soft⁃NMS 的YOLOV3 改进算法。
利用DenseNet,改进网络能够更加高效地对特征信息进行提取,减轻了因为层数太多造成的梯度消失现象。对NMS 算法进行改进,减少模型对目标的漏检率。通过实验结果表明,本研究提出的改进方法使得YOLOV3 对于弹库火工品的检测精度比传统YOLOV3检测精度更高。
