学术论文子句语义类型自动标注技术研究
2021-07-17黄文彬王越千步一车尚锟
黄文彬,王越千,步一,车尚锟
(1.北京大学信息管理系,北京 100871;2.清华大学经济管理学院,北京 100084)
1 引言
学术论文是学术成果交流的主要方式,学术论文的文本挖掘也是信息管理学科重要的研究内容。与一般文本相比,学术论文具有以下特点:①学术论文的用词和句法比较规范,这降低了对论文的语句进行语法、句法分析的难度;②学术论文内部有比较严密的逻辑结构,且同一学科或同一类型的论文行文内部结构具有较高的相似性。因此,除了使用一般文本的挖掘方法之外,合理利用上述特点对论文的结构进行解析,将给学术论文的文本挖掘带来极大的便利。
为了提升学术论文的文本挖掘效果,已有不少研究引入了各种理论模型将论文结构化。例如,Swales的CARS(create a research space model)体裁分析模型[1],将论文简介部分分为三个语轮(Move)中的7个语步(Step),但使用的范围一般仅限于论文的特定章节(如摘要、简介等),泛化能力较弱,难以大规模应用到学术论文的全文本分析中;黄曾阳的HNC(hierarchical network of concepts,概念层次网络)理论[2]从词语、语句、句群和篇章4个层级对文章进行解析辅助计算机进行自然语言理解,但语义单元类型过于复杂,提高了标注的难度;陆伟、黄永等[3-6]系列研究则对学术论文中章节的结构功能进行识别,由于其粒度局限在章节层面,故不能实现更细粒度的文本挖掘。
本文期望找到满足以下条件的学术论文结构功能模型,并以此为基础进行论文结构自动标注的研究:①通用性强,适用于不同学科和论文中的不同章节;②模型规则不能过于复杂,且有明显的语法、词汇等语言学特征,方便机器识别;③粒度较细,即粒度要等于或更细于句子粒度。根据上述要求,本文选择了de Waard[7]提出的篇章子段类型的模型作为本研究使用的模型。Waard认为,论文中所有子句可以分为事实(Fact)、假设(Hypothesis)、问题(Problem)、方法(Method)、结果(Result)、意义(Ⅰmplication)和目标(Goal)7种类型。以Huang等[8]一篇论文的片段为例,其划分出的子句包括:
Although parallel browsing is more prevalent than linear browsing online(Fact),little is known about how users perform this activity(Problem).We study the use of parallel browsing(Goal)through a log-based study of millions of Web users and present findings on their behavior(Method).We identify a power law distribution in browser metrics comprising“outclicks”and tab switches(Result),which signify the degree of parallel browsing(Hypothesis).
本文旨在将论文的片段切分成子句(即上段例子中每个括号前的短句子),并用机器学习的方法给每个句子标注相应的语义角色(即括号里的内容)。与现有的学术论文子句语义类型自动标注研究相比,本文的主要贡献在于:
(1)实现了论文全文本子句粒度的语义类型的标注。相比之下,以往研究大多是标注论文章节所属的功能类型,或特定章节中句子的语义类型。
(2)使用了包括论文章节结构在内的更多的语法、词汇、位置特征判断子句的语义类型,提高了语义类型标注的准确度,并结合人工标注一致性实验,探讨导致标注错误的主要原因。
(3)进行了基于子句语义类型标注结果的论文主题聚类实验,证明了本模型的价值。
2 篇章修辞结构模型和自动标注回顾
篇章修辞结构是指文章的功能结构,其定义了文章各部分的顺序和修辞功能[9]。随着学术论文的撰写、传播和阅读环境由线下向线上转移,对学术论文的篇章修辞结构进行建模以便于计算机理解,已经成为了一个研究热点。目前,篇章修辞结构模型正在由较粗的段落粒度向较细的句子甚至子句粒度演进。本节将对句子及以下粒度的篇章结构模型和基于这些模型的篇章结构自动标注实验进行回顾。
2.1 篇章修辞结构模型
Teufel等[10]在1999年提出的论证分区模型(argumentative zoning,AZ模型)是一种较早的句子粒度修辞结构模型。AZ模型针对语言学领域论文的结构特点,将句子分为目标(Aim)、背景(Background)、理论基础(Basis)、对比(Contrast)、已有研究(Other)、本文研究(Own)和篇章结构(Textual)7种类型。AZ模型认为,研究者撰写学术论文的目的在于向同行声明其对新发现知识的所有权,因此,这种论文比较注重文中的新知识和已有知识之间的关系,而非对新知识本身的解析。
Mizuta等[11]参考AZ模型提出了嵌套标记模型,突破句子粒度,进入了更细的子句粒度。在子句粒度上,最常见的修辞结构模型是在引言中提及的de Waard的篇章字段类型模型[7]。2008年,de Waard等[12]对篇章子段类型模型进行改进,在保证修辞结构完整的前提下对分类粒度进行细化。除了引言中提及的7种子句语义类型外,改进模型还添加了介绍(Ⅰntroduction)大类和讨论(Discussion)大类。其中,介绍大类分为研究定位(Positioning)、中心问题(Central Problem)、假设(Hypothesis)与结果汇总(Summary of Results)4个小类;讨论大类分为评价(Evaluation)、对比(Comparison)、启示(Ⅰmplications)和下一步研究(Next Steps)4个小类。另外,改进模型还对实体(专有名词、图标、引文)和关系(实体间关系、实体本身和实体在文中表示的关系、同一篇文章中不同类型子句的关系、不同文章中子句的关系)进行了定义。
2.2 篇章结构自动标注
科学论文篇章结构自动标注是指给定一定粒度的文本片段,要求判断其功能类型。具体到句子粒度,则要求对给定论文文本中的每个句子进行语义类型自动标注。语义类型自动标注通常通过机器学习方法实现。从使用的特征上看,常用特征有句子在文中的位置特征、语法/句法特征与词汇特征,特别是和动词有关的词汇特征;从使用机器学习模型上看,常用的模型有朴素贝叶斯(naive Bayesian model,NBM)、条件随机场(conditional random field,CRF)、支持向量机(support vector machine,SVM)等传统分类模型,深度学习的应用相对较少;从实验语料上看,大多数研究只对论文的部分章节(如摘要)进行标注,对论文全文进行标注的研究较少。
Guo等[13]对篇章结构解析及其影响进行了一项较为完善的研究,其对AZ、CoreSC和摘要section headings模型(共有目标、方法、结果和结论四种句子语义类型)3种篇章修辞结构模型进行研究,抽取了上个句子类型、句子位置特征、bi-gram、动词信息、词性等11个特征,训练了朴素贝叶斯、支持向量机、条件随机场3种模型,对15种生物医药领域期刊的1000篇文献的摘要部分进行了句子语义类型的自动标注。为了检验篇章结构解析的实际效果,该文还请领域专家阅读了未经标注、经人工标注和经自动标注的3种不同篇章结构解析方式的论文摘要,并记录其在阅读时回答论文相关问题的耗时和答案的一致性。实验结果证明,该文使用的自动标注模型能在基本不影响回答的正确率的情况下有效缩短耗时。
Dasigi等[14]提出了一个基于长短时记忆模型(long short-term memory,LSTM)的科学论述标注系统(scientific discourse tagging,SDT)。SDT根据在PubMed语料中训练得到的词嵌入模型,使用注意力(Attention)机制获取句子的向量表示作为LSTM的输入,按照Waard篇章子段类型模型七种子句语义类型,将PubMed中75篇文章的4497个子句进行标注。该文对注意力机制的可视化分析显示,虽然没有进行专门的特征工程,但注意力机制仍能捕捉到句子中对语义类型产生关键影响的词汇,如“suggest”“analyze”等动词。
为解决经过标注的训练数据不足对监督学习模型效果的限制,陈果等[15]将主动学习的方法应用在论文摘要语句的功能识别中,利用结构化摘要训练学习器,并选择少量重要的非结构化摘要进行标注,减小数据标注的工作量的同时达到较好的训练效果。Kiela等[16]提出了一种无监督的聚类方法完成篇章结构的自动标注任务,其以AZ模型和摘要section headings模型为分类标准,使用球面Kmeans、期望最大化高斯混合模型(expectation maximization-Gaussian mixture model,EM-GMM)和 多级加权图3种聚类模型,对15种生物医药领域期刊的1000篇文献的摘要部分中的句子进行聚类,并且试图通过聚类结果探索新的语义类型,使结构模型更适合特定的学科领域。
3 子句语义类型自动标注实验
本文使用de Waard的篇章字段类型模型[7]进行子句语义类型自动标注研究。整个实验流程如下:首先,对论文语料进行预处理,人工标注训练集和测试集,并训练得到一个子句语义自动标注的机器学习模型。其次,选取100篇论文进行聚类实验,使用自动标注模型对论文中每一个子句进行语义类型标注,通过几种结构化程度不同的模型,如纯文本无结构数据、LDA(latent Dirichlet allocation)模型、子句语义模型等,对这些论文进行主题聚类,通过对比聚类结果论证子句语义自动标注模型在文本挖掘等应用上的价值。
3.1 数据获取与预处理
由于本文采用的子句语义类型模型是针对实证研究类论文而构建的,因此,将实验语料中的论文也限制为实证研究,而不是综述类文章或纯理论文章,即论文必须具有方法部分和实验/系统构建部分。本文选择论文的具体规则包括:①文章是用英语撰写的;②文章长度适中(2000~20000词);③论文结构符合ⅠMRD或ⅠMRC结构,即论文至少要有表示引言、方法、结果、讨论(或结论)的章节。
本文选择了“Web信息提取”“文本信息提取”“浏览日志分析”和“购买记录分析”四个主题,使用Google Scholar分别以“web information extraction”“text information extraction”“browsing log analysis”和“user behavior analysis”为检索词进行检索,并人工选取相关性排名最靠前的30篇符合论文选择规则的论文,将其中4篇加入训练集、1篇加入测试集、25篇加入后续聚类实验语料。因此,本文的数据集共有120篇论文,其中16篇作为训练集、4篇作为测试集、100篇作为后续聚类实验。实验数据的集具体统计信息如下:训练集中共有16篇论文,3658个字句,经过人工标注;测试集共有4篇论文,909个字句,经过人工标注;聚类实验语料共有100篇论文,27085个字句,未经人工标注。
数据预处理过程分为3个步骤:子句切分、标题化归和人工类型标注。其中,子句切分,是指根据一定规则将论文中的句子切分为粒度更细的子句;标题化归,是指将论文中的章节标题统一属于为8种标准章节标题中的一种,以作为特征输入子句语义类型标注模型;人工类型标注,是指人工给每个子句打上语义类型的标签,以作为训练/测试语料。训练集和测试集的预料需要经过所有3个步骤的预处理,而用作聚类实验的语料只经过了子句切分和标题划归2个步骤。
1)子句切分
子句是指“文本中语义完整、不中断的区间”[17],是文本分析中常见的,并且介于句子和从句之间的分析粒度。子句切分将一个句子根据一定规则切分成一个或多个子句。和系统功能语言学注重语法和语义结构完整性的切分方式不同,该切分方法更侧重对子句语义类型或语义功能的描述。本文采用了一种较为简单的启发式的子句切分方法。切分原则如下:
(1)以逗号为切分点,将一个有n个逗号的句子切分为n+1个候选字句。
(2)如果一个候选子句的第一个单词是“to”“by”或“then”,或候选子句中包含多于7个单词,那么将这个候选子句作为一个独立的子句单独输出;否则,将这个候选子句和前一个候选子句合并。
(3)如果这个候选子句是一个句子中的第一个候选子句,或者这个候选子句的前一个候选子句的第一个单词是“to”“by”或“then”,则将其和后一个候选子句合并。
以Etzioni等[18]论文中的一个句子为例,“To address the problem of accumulating large collections of facts,we have constructed KNOWⅠTALL,a domain-independent system that extracts information from the Web in an automated,open-ended manner.”根据上述规则就应该被拆分为“To address the problem of accumulating large collections of fact,”和“we have constructed KNOWⅠTALL,a domain-independent system that extracts information from the Web in an automated,open-ended manner.”两个子句。
2)标题化归
Yang等[19]提出章节标题可以分为传统章节标题(“引言”“理论基础”“文献综述”“方法”“结果”“讨论”“结论”“教学法”和“意义”)、变异标题(“背景”“前人研究”“当前研究”“研究设置和主题”和“实验设计”等在传统章节标题基础上变异而来,但具有相似功能的标题)和内容标题(“第二语言学习者”“L2阅读策略”“音韵学中心度”和“最短路径算法”等表示章节具体内容的标题)。为了将宏观结构信息结合到机器学习模型中,本文将所有标题都转换为“摘要”“简介”“综述”“方法”“实验”“结果”“讨论”和“结论”8个标准章节标题中的一个。通过阅读大量章节标题,本文总结了8类标准章节标题对应的关键词。对于本文数据集中每篇科学文献的每个标题,按“摘要”(Abstract,对应关键词如“abstract”)、“简介”(Ⅰntroduction,对应关键词如“introduction”“background”)、“综述”(Review,对应关键词如“review”“background”)、“方法”(Methodology,对应关键词如“methodology”“method”“model”等)、“实施”(Ⅰmplementation,对应关键词如“implementation”“experiment”“validation design”等)、“结果”(Result,对应关键词如“result”“analysis”“evaluation”)、讨论(Discussion)和“结论”(Conclusion,对应关键词如“conclusion”“future”)的顺序,依次判断每个标准章节标题对应的关键词是否在该标题中出现。如果该标题中出现了某类关键词,那么将这个标题化归为对应的标准章节标题;如果标题中不含任何关键词,那么将这个标题化归为和上个章节相同的标准章节标题。大多数一级标题都是传统/变异章节标题,基本都能通过关键词匹配识别出来;内容标题主要是二级及更低级别的标题,即使内容标题不含关键词,也可以通过化归为和前一个章节相同的标准章节标题实现正确化归。
3)人工类型标注
为方便和他人的实验结果进行对比,本文使用de Waard[7]对子句语义类型的定义对训练集和测试集子句进行标注。实验采用的7种类型标记为事实(F)、问题(P)、研究目标(G)、方法(M)、结果(R)、意义(Ⅰ)和假设(H)。7种类型的具体含义分别是:
(1)事实(Fact):在领域内已经得到认可的观点。
(2)假设(Hypothesis):对一种现象的说明。
(3)问题(Problem):未解决的、矛盾的或不明确的问题。
(4)方法(Method):实验方法。
(5)结果(Result):实验的直接结果。
(6)意义(Ⅰmplication):根据研究目标和已知事实对结果的解释。
(7)目标(Research Goal):研究目标。
3.2 自动标注方法与实验
3.2.1 特征选取
本文统计了一系列语法、句法和词汇特征在不同类型子句上的分布情况后,选择以下机器学习算法特征:
(1)时态。句法实验和心理学实验表明,子句的时态与其语义类型之间存在相关性。例如,de Waard等[20]的相关性分析实验中已经证明,现在时的子句更有可能被预测为事实;过去时的子句更可能被预测为结果。这一特征的可选取值为“过去时”和“其他时态”。
(2)引用。如果一个子句引用了其他文献或指向一个公式/图表,那么通常表明该子句应归类为结果或事实[21]。当一个子句没有引用标记时,则此特征取值为“无”;如果该子句引用其他文献,那么此特征取值为“外部”;如果该子句指向图或表格,那么此特征取值为“内部”。
(3)章节名称。本文根据内容将论文的传统章节标题分为8类:“摘要”“简介”“综述”“方法”“实验”“结果”“讨论”和“结论”。将子句所在章节的传统章节标题作为此特征的取值。
(4)情态动词。“can”“may”等情态动词更可能出现在“意义”子句中[20]。本文将子句是否包含情态动词作为情态动词特征的取值。
(5)词表。本文使用了子段边界(segment-segment boundaries)词典和点互信息(pointwise mutual information,PMⅠ)高频词对两个词典以提取词汇特征。子段边界词典是de Waard[7]统计得出的论文中从一种子句类型过渡到另一种子句类型时常见的标识词。例如,若某个子句是事实类子句,而下一个子句以“we found”为起始词组,这就往往意味着下一个子句不再是事实类子句,而是结果类子句。若某个子句以Waard统计的子段边界词之一为起始词(组),则将这个起始词(组)作为一个特征。为适应本文所用的语料,使用点互信息法[22]创建了高频词对词典,若某个词对中的两个词在同一个子句中出现,则将该词对作为这个子句的一个特征。
(6)词性。本文使用Python nltk工具包对子句中的每个单词的词性进行标注,并将标注结果中的POS(part-of-speech)标签去重后作为词性特征。
3.2.2 机器学习模型
在撰写科学论文时,作者通常会遵循一些写作范式,如一个篇章子段通常先陈述事实并提出有关问题,然后根据问题确定实验目的、设计实验,并根据结果做出假设,即某个子句的语义类型可能和上个子句的语义类型存在关系。基于这一特性,本文选择序列标注模型中的条件随机场完成子句类型标注任务。但考虑到不同文章结构存在差异,CRF无法从相邻句子的概率转移中学习到适用于所有论文的模型,因此,本文还使用随机森林(random forest,RF)、随机梯度下降分类器(stochastic gradient descent,SGD)、支持向量机和梯度提升分类器(gradient boosting classifier,GBC)作为补充分类器。这些模型是使用Python软件包sklearn和crfsuite构建的。利用sklearn中的RandomizedSearchCV函数对5个机器学习模型的常见参数进行随机搜索调优。每个机器学习模型随机搜索100次参数,并使用训练集的全部语料进行3折交叉验证。参数调优结果显示,CRF、SVM和GBC这3个模型的效果比较好,说明某个子句语义类型和其上个子句语义类型之间的关系并不像预期的那样重要,这是因为提取了众多的特征,其中包含了一些子句间转移的规则词等,在一定程度上可以弥补序列中相邻子句语义类型转移情况的作用。将这3个表现最好的模型进行集成,即对使用3个模型分别给出的标注结果进行投票作为最终的预测结果。
最终参与集成的3个机器学习模型的部分重要参数如下:CRF使用的训练算法为lbfgs,不设置特征出现最小次数限制;SVM使用的核函数为线性(linear)核函数,正则化系数C=0.167,多分类问题策略为一对多(one vs rest);GBC使用deviance loss作为损失函数,基学习器个数为300,学习率为0.13,节点特征选择算法为friedman_mse,节点特征数上限设为对数个特征(log2),最大深度为2。
3.2.3 实验结果
为了与前人的实验进行比较,本文选择了Burns等[21]提出的特征选取方法和CRF模型作为对比模型,在本文实验的训练和测试集论文全文上进行实验,实验结果和集成模型的混淆矩阵如表1和表2所示。

表1 自动标注全文实验结果
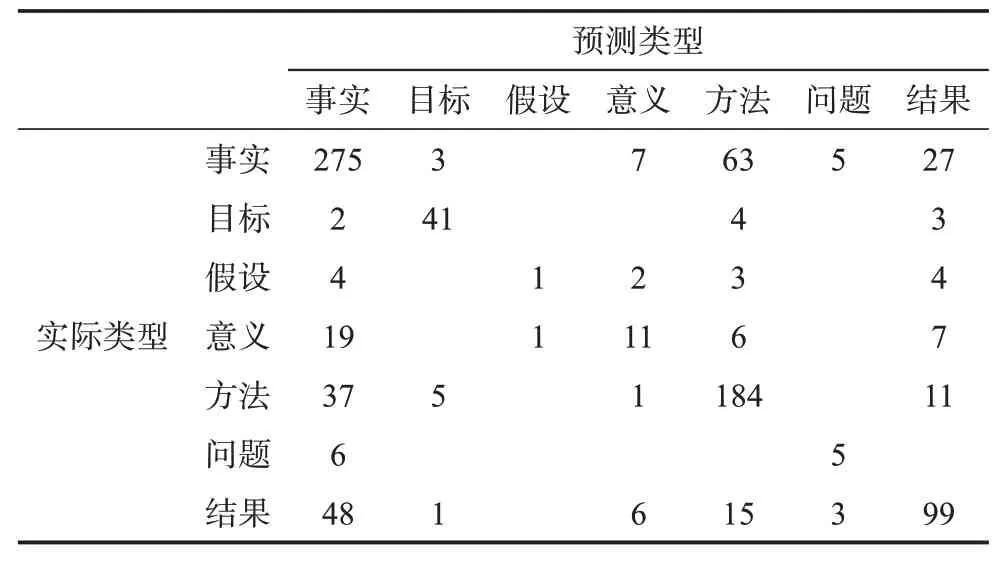
表2 集成模型自动标注全文混淆矩阵
集成模型在标注“目标”类型时效果最佳,大量的“目标”类型都以“To”开头,因此模型可以通过子段边界词典中的词汇特征判断出目标类型。“事实”和“方法”类型的标注效果也相对较好,这是因为数据集中这些类型子句的数量较多,所以更容易找到区分这些类型的特征。然而,此模型在对“假设”和“意义”类型进行标注时表现不佳,主要是由于这几类子句的数量非常少,模型难以找到区分它们的特征。在区分论文全文中的子句类型时,由于本文的模型结合了章节等宏观信息,同时利用了句法和语法层面的微观信息,因此,绝大多数类型的标注效果都优于对比算法。
Burns等[21]是为了通过“结果”章节实现对生物论文中实验的分类而进行的子句语义类型标注实验,因此,其仅使用了论文中的“结果”章节对自动标注结果进行评测。为了将本文提出的集成模型和Burns等[21]的对比模型进行进一步比较,从测试集中提取出每篇论文的“结果”章节进行评测。“结果”章节的实验结果和集成模型的混淆矩阵如表3和表4所示。
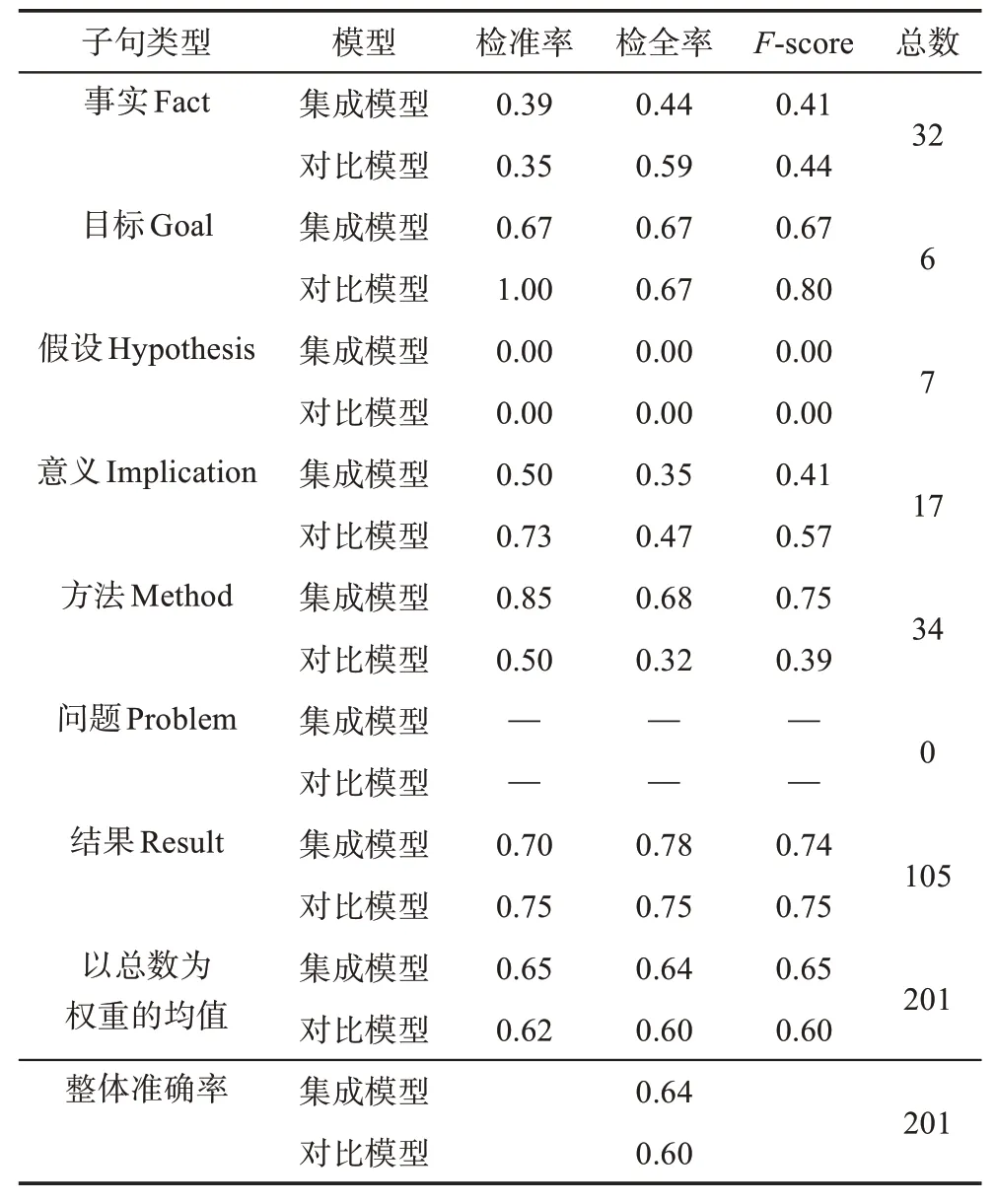
表3 自动标注“结果”章节实验结果
在结果章节中,集成模型的效果虽在大多数指标上仍然优于对照模型,但整体提升效果没有在全文中明显。这是因为对照模型本身就是针对“结果”章节的子句标注问题而提出的,所以在“结果”章节的准确度会提高;而集成模型在不同章节的标注准确度存在波动,因此可能在某些章节上标注准确度高于全文准确度,另一些章节上标注准确度低于全文准确度的情况。

表4 集成模型自动标注“结果”章节混淆矩阵
分析全文自动标注结果和人工标注一致性实验的混淆矩阵,绝大多数混淆都发生在“事实”类型和其他几种类型之间。“事实”类型是七种子句类型中定义最宽泛、外延最广的一类,“事实”类型子句数量占子句总数量的比例也最大。因此,明确对“事实”类型子句的定义,将更有助于完善该子句语义类型模型,并提升自动标注准确率。
3.2.4 人工标注一致性实验
为了对自动标注结果产生错误的原因做进一步解释,同时探索这七种子句语义类型的定义可能产生的理解上的问题,本次实验招募了4名志愿者,对测试集中的4篇论文额外进行了两轮标注。要求每名志愿者阅读Waard对7种子句类型的定义,并提供了de Waard的论文原文[7]作为自愿阅读的参考资料。每名志愿者在学习子句类型定义后标注1~3篇不同的文章。志愿者均是至少获得了信息管理与信息系统专业的学士学位,且具有一定的相关领域的英文论文阅读经验,是上述4个主题论文的主要读者群体,因此,志愿者提供的标注结果比较可信。这2份标注的混淆矩阵如表5所示。

表5 人工标注混淆矩阵
2份标注中,仅有61.39%的子句标注结果相同。2份标注的分歧主要在如下3个方面:
(1)介绍论文行文结构的子句。这类子句的主要作用是方便读者阅读,本身含有的信息量不大。如“the[…]results are given in table 2”经常产生“事实”和“结果”间的混淆;“we divide this task into 2 parts”经常产生“事实”和“方法”间的混淆;“in section 3,we[…]”经常产生“事实”和“目标”之间的混淆。
(2)涉及别人实验方法的子句。这类混淆集中在“方法”章节中。如“following the approach used by[…]”经常产生“事实”和“方法”之间的混淆。标注“方法”志愿者认为这句话的确描述了实验方法的一部分;标注“事实”志愿者认为别人在已发表论文中使用的方法是学界周知的事实,所以符合“事实”的定义。
(3)有关实验结果和实验讨论的子句。这类混淆集中在“结果”章节和“讨论”章节中。例如,“we observed two major reasons for changes in[…]”经常产生“结果”和“意义”之间的混淆。志愿者难以把握这类句子中的内容多大比例是数据直接展示的,多大比例是经过作者推理或猜测才能得出的。同时,也存在因为不知道如何标注,于是直接标作“事实”的情况。
在机器学习分类任务中,人们常把人工分类的准确率(human-level)作为机器学习方法的“天花板”,机器学习模型分类的准确率往往难以突破人工分类的准确率。而本实验中人工标注一致性并不能完全代表人工分类的准确率,其主要原因是人工标注实验唯一分类标准是Waard对子句类型的定义,而这些定义在不同的具体情况下的确可以产生不同的理解。如果在训练机器学习模型时,对定义进行了进一步的明确(如在标注训练集时约定好上述几种容易产生分歧的子句的标注方案),自动标注模型的准确度完全可以超过人工标注的一致性。
4 方法应用实例:主题聚类实验
子句语义类型可以用于学术论文的信息抽取和文本挖掘相关的许多场景,下文将通过在100篇文献的聚类实验语料上的主题聚类实验作为示例说明其价值。如果论文在经过语义类型自动标注并抽取出特定类型的子句后构建的特征向量,比使用全文或其他语言模型构建的特征向量在聚类实验中的表现更好,那么说明经过子句语义类型自动标注模型处理后构建的特征向量更能反映论文的主题,即在抽取论文的内容信息上具有一定的效果。
本文使用全文本无结构数据、论文宏观结构模型中“摘要”“简介”“结论”章节、子句语义类型模型中“事实”类型子句和全文LDA主题6种方法对论文进行处理。主体聚类实验具体步骤如下:
(1)对于使用论文宏观结构模型子句语义类型模型的组别,分别抽取出相应部分的内容作为聚类语料。
(2)使用Python nltk中的分词器进行分词,并使用nltk中stopwords工具删除停用词。
(3)使用Snowball-Stemmer①https://snowballstem.org/提取词语的词干。
(4)使 用TF-ⅠDF(term frequency-inverse document frequency)模型确定词语权重。词语频率阈值分别为0.2和0.8,即剔除出现在大于80%的论文中和小于20%的论文中的词语。
(5)使用LDA模型提取文档的主题分布特征,或使用TF-ⅠDF向量空间模型计算文档的距离,使用层次聚类方法对文档进行聚类,并对聚类结果进行评测和解释。
本文使用sklearn中的Agglomerative Clustering层次聚类算法对文档进行聚类。层次聚类算法首先将每篇文档作为1个簇,每次合并距离最小的2个簇,直到剩余的簇数小于设定的终止簇数为止。与Kmeans等常用的原型聚类算法相比,层次聚类算法不需要设定任何初始状态,从而避免了因初始状态不同,导致同样的语料在多次实验中得到不同聚类结果的情况发生。将层次聚类算法终止簇数设为4,文档间距离度量算法使用曼哈顿距离,在合并2个簇时以2个簇中点间距离的最大值(即全链接算法)作为合并判断的标准,使得算法倾向于对2个规模较小的类进行合并,以保证聚类结果中每个簇的大小尽量相同。
本文使用了纯度、互信息和同质性3个聚类效果评价指标。由于“Web信息提取”“文本信息提取”“浏览日志分析”和“购买记录分析”4个主题分属“信息抽取”和“用户分析”大类主题,同一大主题下的两类主题存在内容相似度较高,因此,在纯度和同质性上分别选择了以2个大类为真实类别的2类纯度、2类同质性以及以4个小类为真实类别的4类纯度、4类同质性对聚类结果进行评价。聚类结果的评测和分析如表6所示。
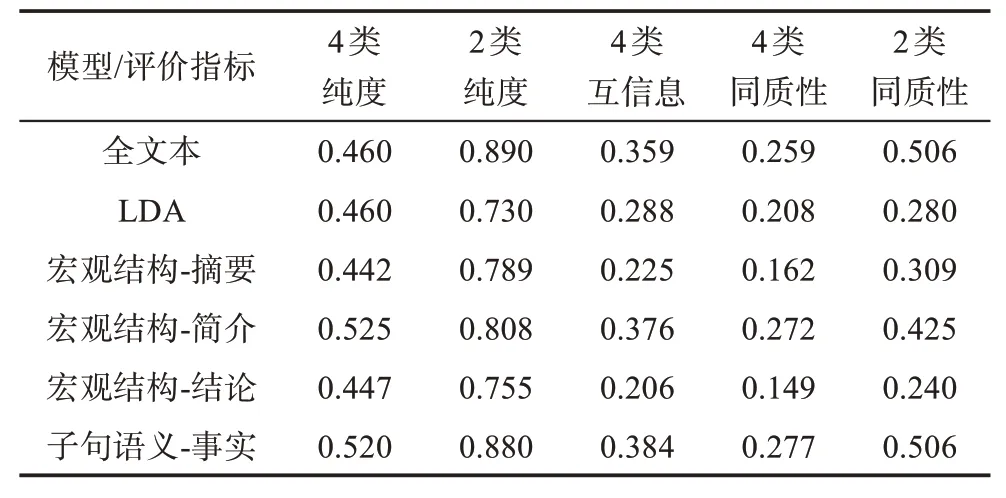
表6 主题聚类实验结果
表6展示了不同模型下聚类的评测结果。综合来看,经过子句语义类型抽取的事实类子句在聚类结果的多种评测指标上都能得到最好或接近最好的结果,使用论文全文本和简介章节在综合效果上仅次于事实类子句,由于论文的全文和简介部分中的事实类型子句占比较大,因此可以达到和事实类型子句相似地较好表现。
图1展示了事实类子句层次聚类效果。其中,点的坐标对应抽取出的事实类子句形成的文档TF-ⅠDF矩阵经主成分分析(principal component analysis,PCA)算法降至二维后的结果;点的形状表示对应文档实际所属的主题;数字表示对应文档在聚类结果中所属的簇。从图1中可知,聚类算法能够较准确地区分“信息抽取”和“用户分析”两大类主题,但对每个大类主题内的两小类主题分辨能力仍有待提高。
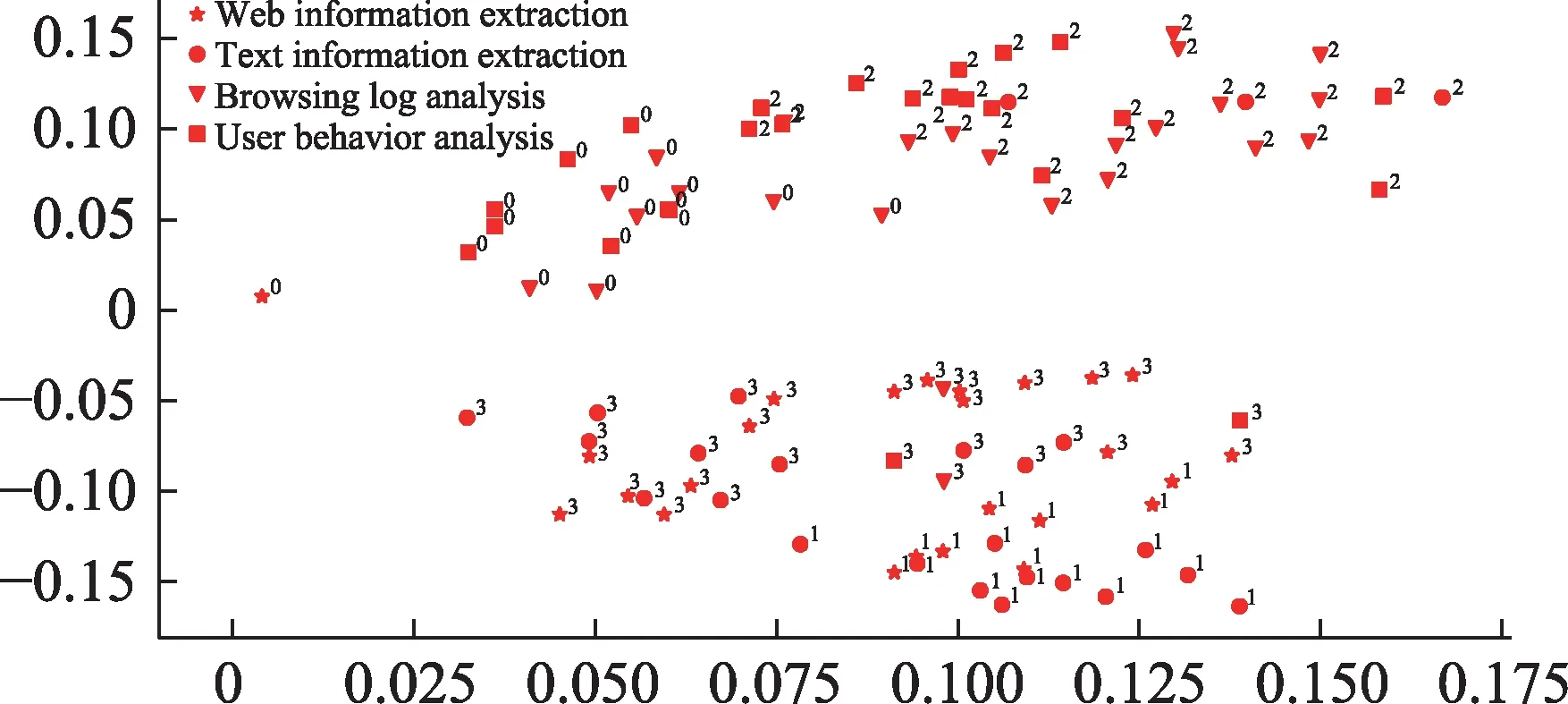
图1 事实类子句聚类效果展示图
5 总结与展望
本文通过引入系统功能语言学中的体裁分析理论,结合自然语言处理领域的句法分析、语法分析和关键词抽取等方法,将论文的宏观结构信息与子句语法特征相结合,构建了能够自动标注子句语义类型的机器学习模型。与已有自动标注模型的对比分析,发现应用子句的章节特征,尝试更多机器学习模型并使用集成学习可以改善子句语义类型自动标注的准确度,且当标注范围从“结果”章节等特定章节扩展到论文全文时依旧有较好的效果。本文通过自动标注模型在论文主题聚类中的应用,证明了该模型在文本挖掘方面的应用价值。另外,本文的主要不足之处在于人工标注困难导致的数据量较小。论文语义模型的多样性和缺乏统一、公开、经过标注的数据集是包括本文的研究在内的许多论文全文本语义模型研究的主要制约因素。
子句语义类型模型在保证不同学科论文普遍适用的前提下,实现了论文在子句粒度上的结构化,可以广泛应用在文本挖掘任务中。本文只选取了主题聚类这一项应用作为示例,其他的应用场景还有:①在抽取式自动摘要任务中,可以利用本模型根据摘要的组成规律,分别选取合适的事实子句、方法子句、结果子句等拼合成一篇抽取式摘要,提升摘要的信息量和结构上的完整性;②在论文的个性化检索任务中,可以利用本模型从论文的假设、方法、结论等方面进行语义层面的信息检索,为用户提供更精准的学术论文检索和分析服务。这些对子句语义类型自动标注结果的应用将是下一步研究的重点。
