基于迁移学习的电力短文本情感分类研究
2021-07-16李海明
李海明, 陈 萍
(上海电力大学 计算机科学与技术学院, 上海 200090)
随着电力改革的深入进行,电力企业愈发重视供电服务和客户服务的质量。运用情感分析对电力短文本进行文本挖掘,对提升客服服务质量和客户满意度都有帮助。但迄今为止,由于没有电网相关的语料库,人工标注也存在数据不准确、耗时且昂贵等缺点,使得利用传统统计学习方法进行情感分析的效果较差。本文采用迁移学习方法,以具有丰富标注信息的酒店评论作为源域,电力文本数据集作为目标域,提出了一种新的基于电力短文本的跨域迁移学习的情感分析方法。
1 研究综述
文本情感分类通过挖掘和分析文本中的立场、观点、看法、情绪、好恶等主观信息,对文本的情感倾向做出类别判断[1]。从用户参与的评论信息中获得人们对某一事物、事件、产品等的喜好、态度,可以为政府制定政策法规与监督社会舆论,企业改进产品质量与服务态度等提供必要的决策依据。
情感分类研究中,有学者重在构建情感词典。但基于词典的分析方法需要研究者有很强的语法敏感性,且现实生活中同一词语可能会被赋予完全不同的涵义,使得传统的分析方法如朴素贝叶斯、支持向量机无法应对。深度学习则可以将神经网络运用于多层网络的学习任务中来处理庞大复杂的数据。在情感分析任务中,其性能不弱于机器学习方法,却可以大大节省人工标注的工作量。如RANI S等人[2]应用卷积神经网络(Convolutional Neural Networks,CNN)来执行印地语电影评论的情感分析。WANG X Y等人[3]提出了用于短文本情感分类的联合CNN和循环神经网络(Recurrent Neural Network,RNN)架构,利用了CNN生成的粗粒度局部特征和通过RNN学习的长距离依赖性。针对中国文本情感分析的困难,XIAO K C等人[4]提出了一种基于CNN的深度学习中文文本情感分析方法,用归一化特征值来克服训练后CNN的特征值不均匀分布的问题,提高了分析的准确性。
注意力机制是一种在神经网络中增加可解释性的方法。在情绪分析任务中,注意力机制有助于将注意力集中在决定输入情绪的重要词语上。WANG Y Q等人[5]提出的基于方面的情感分类方法,将与方面相关概念的额外知识纳入模型,并利用关注度来适当权衡概念与内容本身的区别。PENG Y等人[6]基于目标和背景在隐喻情感分析中的相互作用提供了可靠的情感相关分类特征,提出了一种基于注意力的长期短期记忆(Long Short Term Memory,LSTM)网络的中国隐喻情绪分析方法。
虽然深度学习模型已经在许多情感分析中得到运用,但这些模型从头开始训练,需要大量的数据集,并且收敛速度慢。针对上述问题,尤其当不同领域中存在某种关联时,可以采用迁移学习来提升分类性。TAN B等人[7]探究了远程域迁移学习的新型迁移学习问题,在目标域与源域完全不同的情况下实现迁移学习。HOWARD J等人[8]提出通用语言模型微调(Universal Language Model Fine-turing for Text Classification,ULMFiT),为自然语言处理(Natural Language Processing,NLP)的任何任务实现类似计算机视觉(Computer Version,CV)的迁移学习。TAN S B等人[9]将朴素贝叶斯和期望最大化(Expectation-Maximum,EM)算法的一种半监督学习方法应用于跨领域的情感分析中。总之,现有的迁移学习方法大多是通过学习一个新的特征代表来增强或取代源特征空间,以减少源领域与目标领域的情感特征的差别,但当目标领域与源领域之间的差别很大时,这种方法的性能显著下降。
通过以上综述可以发现,目前对于文本情感分析虽然取得了不少成果,但还存在以下几个问题:首先,因保密性原因,可搜集到的有限数据数量无法支撑进一步的实验;其次,缺乏语料库时进行人工标注费时费力;最后,若采用迁移学习方法,会因源域与目标域的差异导致最后的分析效果不尽如人意。为解决以上问题,本文提出了一种基于跨领域迁移学习的情感分析方法用于电力短文本情感分类。具体而言,使用基于注意力机制的长短型记忆神经网络(Attention-Based Bidirectional Long Short Term Memory Networks,Attention Bi-LSTM)作为基础模型,通过共享网络结构与参数进行参数迁移,并在网络模型中引入域自适应层来减少源域与目标域的差异。
2 基础模型
2.1 Bi-LSTM网络
RNN是传统前馈神经网络的扩展[9]。然而,标准RNN存在梯度消失或爆炸问题,作为其变体,LSTM通过组合存储器单元来捕获长程依赖性。LSTM架构有3个门和1个单元存储器状态。正式的LSTM中的每个单元格可以计算为
it=σ(WxiXt+Whiht-1+Wcict-1+b)
(1)
ft=σ(WxfXt+Whfht-1+Wcfct-1+b)
(2)
ct=ft⊗ct-1+it⊗tanh(WxcXt+Whcht-1+b)
(3)
ot=σ(WxoXt+Whoht-1+Wcoct+b)
(4)
ht=ot⊗tanh(ct)
(5)
式中:i——输入门;
b——偏参;
t——时间状态;
σ——sigmoid激活函数;
Wxi,Whi,Wci,Wxf,Whf,Wcf,Wxc,Whc,Wxo,Who,Wco——矩阵权重,下标表示门和单元之间的连接;
ht-1——作为输入、输出一个在0和1之间的数给Ct-1记忆单元的输出值;
ft——遗忘门,决定信息的丢弃;
ot——输出门,决定信息的输出;
ht——隐藏层的向量。
所有这些状态的尺寸大小都与隐藏矢量大小相同。权重矩阵下标表示每个门和单元之间的连接。
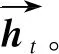
(6)
(7)
(8)
2.2 Attention Bi-LSTM模型
为解决Bi-LSTM网络无法检测哪个词语是句子级别情绪分类的重要部分这一问题,采用基于注意力机制的Attention Bi-LSTM来捕捉句子中发生情绪变化的关键部分。图1为Attention Bi-LSTM进行情感分析的概述,图2为其具体的执行步骤。

图1 Attention Bi-LSTM情感分析概述

图2 Attention Bi-LSTM情感分析执行步骤
本文使用的注意力机制策略是对Bi-LSTM网络提取后的全局特征向量进行处理,合并Bi-LSTM层中每一个时间步获取的信息,以不同的权重大小重新分配整个序列内不同的特征向量,进行相加后得到新的特征向量。经过注意力机制处理后新的特征向量即为Attention Bi-LSTM模型当前的状态,记为A。
(9)
式中:at——注意力权重。
Bi-LSTM网络接收各词向量输入序列Xt后输出提取隐藏特征向量序列Ht,注意力机制的当前状态A由该特征向量序列中的所有特征向量重新分配后得到
Mt=tanh(XtHt+b)
(10)
再使用Softmax函数对注意力权重值归一化,为
(11)
式中:Mi——输入门的特征向量。
最后,将Attention机制的输出A,输入Softmax层进行分类预测。预测结果为
(12)
式中:wa——注意力机制当前状态a的矩阵权重。

(13)
3 跨领域迁移模型
3.1 概述
本文参考文献[10-11]给出了一个用于电力短文本的情感分类的跨领域迁移学习框架。图3为跨领域迁移模型。
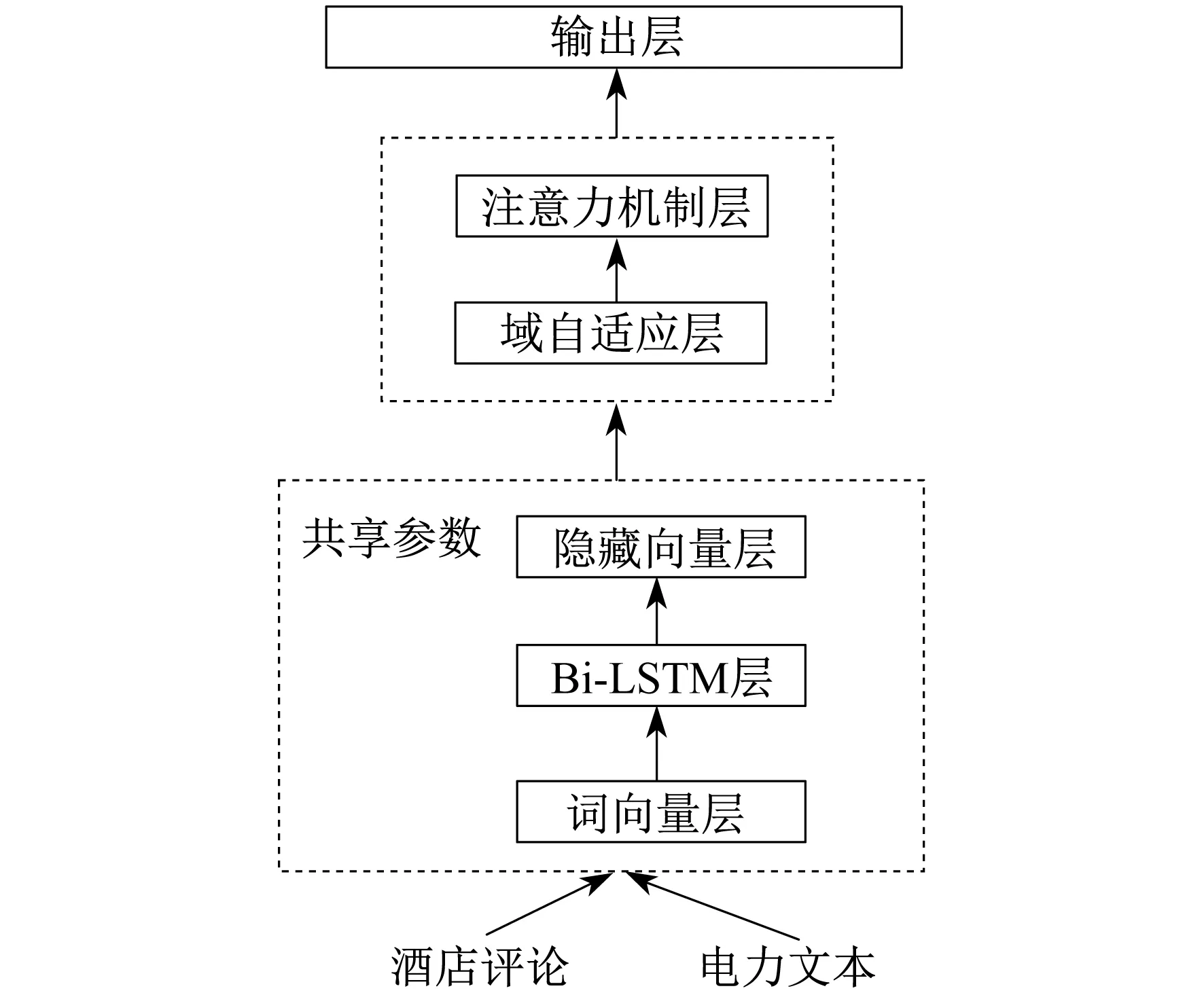
图3 跨领域迁移模型
由图3可以看出,自下而上每个输入句子被转换成嵌入向量序列,然后将其馈送到Bi-LSTM,依次将上下文信息编码成固定长度的隐藏向量;再将隐藏向量输入到注意力机制模型中,重新分配各维向量得到权重;最后将注意力机制层的输出向量输入Softmax函数进行分类。在源/目标域中共享词向量嵌入层和Bi-LSTM层,但使用不同的注意力机制层和Softmax层。利用域自适应层保留两个域之间的特定域知识,将隐藏向量直接馈送到源/目标域特定的注意力机制层和Softmax层中以预测最终的分类标签。
3.2 域自适应层
由于源域和目标域具有不同的语言样式并且涉及大量不跨域共享相同语义的特定于域的术语,即目标域和源域都具有特定于域的“领域知识”,因此在源域上训练的分类模型可能在目标域上不具有最佳性能。为有效利用源域中强大的特征表示,又能减少源与目标之间的差异,本文引入了一个域自适应层,添加在目标域的Bi-LSTM层之后。这样既能学习到源域的强大特征表示,又能充分学习到特定领域知识。本文使用的域自适应策略是特征扩充的方法[12],假设输入特征空间为X∈n,Ds是源域数据集,Dt是目标域数据集。经过特征扩充后,特征空间映射为x∈3n。源域的映射策略为目标域的映射策略为因此,经过特征扩充后,源域的特征空间为:Ts(a)=ms⊗a=[a1,a2,0],a=[a1,a2,a3]∈Ds,目标域的特征空间为:Tt(b)=mt⊗b=[b1,0,b3],b=[b1,b2,b3]∈Dt。
3.3 基于跨领域迁移学习的情感分析算法描述

具体算法描述如下:通过交替训练方式,首先使用源域数据集训练Attention Bi-LSTM模型,然后使用目标域数据集重新训练Attention Bi-LSTM模型,源域和目标域共享Attention Bi-LSTM模型中的词向量层和Bi-LSTM层的网络参数与网络结构,但源域和目标域使用不同的注意力机制层和Softmax输出分类层。
3.4 跨领域迁移模型训练
使用Adam优化算法以端到端的方式训练跨领域迁移的情感分析模型,采用的学习率为0.001。通过参数迁移的方式共享源域和目标域中词向量嵌入层和Bi-LSTM层的网络结构及参数[13]。即ωs和ωt分别为源域和目标域的模型参数集,共享模型参数为ωs,shared=ωs∩ωt=ωt,shared=ωshared。
由于源域和目标域都有不同的数据集,因此使用替代优化策略,交替训练每个域的数据。在训练期间,使用每批次20条语句来训练100个时期。训练时对词向量嵌入进行微调,以调整实际数据分布。为避免过度拟合,在输入词向量特征表示Bi-LSTM层之前使用丢失训练,丢失概率为0.5。域自适应层、注意力机制层和输出层分别各自训练。在每次迭代周期中,根据给定域的损失函数执行梯度更新。
最后,更新共享参数和各个域的特定参数,并重复上述迭代,直到停止为止。
4 实验与分析
为了验证跨领域迁移学习情感分析方法的有效性,将基于真实电力短文本数据集与近几年来其他流行的情感分析方法进行了比较。实验中使用的数据集、预训练的词向量嵌入、参数设置、实验细节以及结果分析如下。
4.1 数据集
目标域数据集:获取了某县级电力企业的客服工单,提取其中受理内容与回访内容约1 050条为研究语料。此外,通过网络爬虫算法从新浪微博中爬取热门电力事件的评论信息约900条,也作为研究语料。随机打乱手动标注的各条语料的情感状态,其中70%划分为训练集,20%划分为测试集,10%划分为验证集。表1为目标域数据集样本例。

表1 目标域数据集样本例
源域数据集:使用谭松波老师整理的酒店评论语料[14]。语料规模为10 000篇,从携程网上自动采集并经过去重整理而成。选取其中一个子集,平衡语料、正负类各3 000篇。同样将酒店评论数据集中70%划分为训练集、20%划分为测试集、10%划分为验证集。表2为源域数据集样本例。

表2 源域数据集样本例
4.2 参数设置
数据预处理:采用jieba分词工具,去除分词列表中的停用词和标点符号。
预训练词向量:使用预先训练的词向量嵌入代替随机初始化。词向量嵌入使用gensim工具包的word2ve,经在中文百度百科语料预训练而成[15],词向量维度为60维。源域和目标域都使用相同的词向量嵌入。
超参数和初始化设置:超参数包括初始学习率(0.01)、训练时期(100个周期)、批量训练样本大小(20个句子)、丢失训练的丢失率(0.5)、LSTM隐藏层向量维度(60维)。 所有其他模型参数在[-1,1]范围内随机均匀初始化。
4.3 算法步骤
跨领取迁移学习情感分析算法的步骤如下。
输入:源域数据为Xs=(x1,x2,x3,…,xn)
目标域数据为Xt=(x1,x2,x3,…,xn)
源域:
(1) 初始化模型参数ωs;
(2) 词向量嵌入;
(3) 输出Bi-LSTM层隐藏状态向量;
(4) 进入注意力机制模型,重新分配向量权重;
(5) 采用Softmax输出分类结果;
(6) 保存共享参数ωshared。
目标域:
(1) 学习共享参数ωshared;
(2) 初始化特定模型参数ωt,spec;
(3) 词向量嵌入;
(4) 输出Bi-LSTM层隐藏状态向量;
(5) 进入域自适应层,充分学习特定领域知识;
(6) 进入注意力机制模型,重新分配向量权重;
(7) 采用Softmax输出分类结果。
4.4 结果与分析
将本文提出的基于跨领域迁移学习的情感分析方法与其他4种方法进行对比。
(1) Bi-LSTM方法 由LI D等人[16]提出,只使用Bi-LSTM双向长短型记忆神经网络来提取特征,采用Softmax输出分类结果。
(2) Attention Bi-LSTM方法 由ZHOU Y等人[17]提出,在使用Bi-LSTM来提取特征的同时,加入注意力机制模型以更好地把握文本中的情感。
(3) ConvLSTM方法 由HASSAN A等人[18]提出,利用LSTM作为CNN中池化层的替代,以减少详细文本信息的丢失并捕获句子序列中的长期依赖性。
(4) Transfer Bi-LSTM方法 由LYU W L等人[19]通过共享Bi-LSTM的网络架构与模型参数,实现参数迁移,更好地利用源域中丰富的标注信息帮助目标域分类。
所有实验都对目标域的训练集和测试集进行了10次交叉验证,并在开发集中找到最佳模型参数后,对目标域中测试集再进行分类预测。不同方法的实验效果比较如表3所示。

表3 不同方法的实验结果比较 单位:%
从表3的实验结果可以看出,虽然只采用Bi-LSTM提取特征进行情感分类可以取得不错的效果,但加入注意力机制模型可以更好地提取文本的局部特征,在F值的评价指标上能提升0.11%。采用ConvLSTM方法也能取得不错的分类效果,但略低于加入注意力机制的Transfer Bi-LSTM模型。相比之下,采用本文提出的基于跨领域迁移学习的情感分析方法,在准确率、召回率、F值等评价指标上都有不错的提升。由此可知,本文提出的方法能有效地学习到源域中强大的特征表示,又能通过域自适应层减少源域与目标域的差异,并且通过基于注意力机制模型能更有效地提取文本的局部特征,帮助情感的分类。
在不同方法中加入注意力机制策略,结果如表4所示。

表4 不同方法中加入注意力机制策略的结果比较 单位:%
从表4的实验结果可以看出,在不同方法中加入注意力机制策略,相比于原来的方法都有略微的提升。这说明采用注意力机制可以更好地提取文本的局部特征来捕捉句子中发生的情绪变化。
综上所述,根据迁移学习的特点,训练语料被少量标注的情况下,利用迁移其他领域的训练集样本,采用领域自适应以及注意力机制模型,实验性能比采用相同规模标注训练语料的其他监督方法略高,比只使用迁移学习策略没有进行域自适应的方法F值性能提升了4.32%。本文提出的方法只采用少量的有标注样本便可取得很好的分类性能,大大降低了对大规模人工标注语料的依赖性。
5 结 语
本文提出了一种新的基于跨域迁移学习的情感分析方法,用于电力短文本的情感分类。该方法只使用少量的具有标注信息的电力短文本数据,在现有的Attention Bi-LSTM模型之上加入域自适应层,能有效学习到源域中强大的特征表示,又能通过域自适应层减少源域与目标域的差异,并且通过基于注意力机制模型更有效地提取文本的局部特征,更好地帮助情感的分类。在未来的工作中,将进一步探索句子的语法构造知识与半监督分类方法结合,更好地对电力短文本进行情感分类。
