基于IFA-XGBoost的燃气轮机故障诊断
2021-07-16方继辉
方继辉, 李 阳
(1.杭州华电江东热电有限公司, 浙江 杭州 310000;2.上海电力大学 自动化工程学院, 上海 200090)
在燃气轮机运行过程中,受热部分和旋转组件如涡轮叶片一般需要承受高温、高压和剧烈振动等冲击,导致其出现蠕变、氧化、热疲劳和热腐蚀等现象,直接影响燃气轮机的寿命和效率,因此涡轮叶片的状态监测和故障诊断非常重要,是燃气轮机故障诊断的热门研究方向之一[1-2]。目前基于解析模型、专家系统等算法的传统故障诊断方法仍存在较多不足[3]。首先,涡轮的工作环境恶劣,内部结构复杂,难以建立精确的数学模型;其次,涡轮故障中容易存在多重耦合,难以实现准确的故障隔离[4]。近年来,随着计算机技术和人工智能的发展,对非线性问题的处理能力逐步提高,机器学习方法可以通过各类算法挖掘大量数据内部的潜在联系,十分适合复杂系统的建模分析。XGBoost(eXtreme Gradient Boosting)是时下最强大的机器学习算法之一[5],其优点是准确性更高、速度更快,同时支持并行计算,广泛应用于金融、医疗和工业等领域[6]。文献[7]表明XGBoost可以实现对二次设备缺陷程度的精确判断,进而可以很好地辅助检修人员进行设备的维护与管理。文献[8]利用XGBoost进行变压器故障诊断,结果表明,能准确、有效地诊断变压器故障类型,精度高于支持向量机(Support Vector Machine,SVM)和IEC(International Electrotechnical Commission)三比值法。
传统机器模型的超参数数目一般较少,比如SVM只有2个超参数径向基核宽度σ和惩罚因子c,随机森林(Random Forest,RF)也只有2个超参数。由于这些算法的计算量较小,机器可以在很短的时间内采用网格搜索的方法把所有的可能都遍历一遍,最后以3D可视化的结果直接给出最优超参数。但是对于复杂的机器学习模型如XGBoost,其超参数数量较多,因此需要通过更好的方法来对其参数进行搜索,以保证分类结果能够满足实际工程的需求。
萤火虫优化算法(Firefly Algorithm,FA) 是一种新型基于群体搜索的随机优化算法,相比遗传算法和粒子群算法,FA的搜索结果不太依赖于自身参数的设置,具有较高的稳定性,但存在收敛速度慢、易陷入局部最优等问题。为此,将种群多样性的位置更新策略和动态步长更新措施引入FA,得到改进的萤火虫算法(Improved Firefly Algorithm,IFA)。通过IFA对XGBoost的超参数进行寻优,建立IFA-XGBoost故障诊断模型,并利用某电厂的运行数据进行实验,验证了IFA-XGBoost具有更好的搜索性能。
1 XGBoost算法
XGBoost是一种集成了许多分类回归树(Classification And Regression Trees,CART)的算法,基本思想是把多棵性能差的树模型组合成一个性能相对好的模型[9],直到接近训练数据的复杂度时模型性能达到最优。模型可以表示为
(1)

K——树的总数目;
fk——函数空间F中的一个函数;
xi——输入的第i个样本;
F——所有可能的决策树。
一般的集成学习算法很难具体列出所有的CART,而XGBoost使用梯度提升策略,在整个过程中通过添加新的树来拟合之前的学习误差。具体推导过程为[10]
(2)
得到的XGBoost算法的目标优化函数为
(3)
式中:L——损失函数;
yi——真实样本值;
Ω(fi)——f(i)对应的正则项;
f(t)——t次求导后的全部决策数;
Ω(ft)——全部决策数经过求导后对应的正则项;
n——树的数量;
A——常数。
模型的目标函数由损失函数和正则项两部分组成,XGBoost把损失函数的泰勒公式在ft=0处展开到二阶,新的目标函数为
(4)
式中:gi,hi——该处一阶和二阶导数。
(5)
(6)

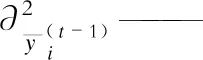
XGBoost的损失函数表示为
(7)
式中:N——全部训练样本个数;
pi——模型预测类别对应的概率。
在训练过程中,模型性能向着损失函数减小的方向提升,而模型性能又取决于其超参数。详细的超参数信息如表1所示。

表1 XGBoost的超参数
由表1可以看出,确定一个完整的XGBoost模型需要给定众多参数值,如果给定的参数值选取不当则可能导致分类结果不好。因此,有必要对众多超参数进行优化,以有效提升模型对样本的分类准确率。
2 改进萤火虫算法
FA算法寻优主要包括初始化群体、荧光素更新、移动概率更新、位置和决策域更新等阶段,其中位置和决策域更新是最重要的部分,其原理可以表示为
(8)

β——个体i被发光更亮的个体j吸引时后者吸引能力大小;

α0——步长因子;
ζ——随机数,ζ∈(0,1)。
由式(8)可知,个体位置的更新结果主要由发光强度更高的萤火虫决定。经过若干次迭代后,由于全局搜索的随机性太弱,搜索空间会收敛在局部区域,所以引入种群多样性策略和自适应步长因子对FA的性能进行改善。
种群多样性的表达式定义为[11]
(9)
式中:M——问题空间的维度;
xim——个体i在第m维的分量值;

将式(8)更新为
(10)
式中:ω——根据种群多样性和迭代次数变化并且具有随机性的权重;
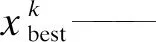
ω的计算公式为

(11)
式中:rand——随机生成0~1之间的小数;
div(0)——初始时刻种群多样性指数;
div(k)——第k代种群的多样性指数;
p——一个线性下降函数。
p的计算公式为
(12)
式中:imax——最大迭代次数;
iter——当前迭代次数。
在式(11)中:在算法前期ω为负数,萤火虫背向最优解方向进行不规则移动,能够在更大范围内进行搜索[12];在算法后期ω=0,实现了更精细的局部搜索。引入种群多样性策略动态调整了前后期不同的寻优范围,避免了过早陷入局部最优的现象。
此外,式(8)中步长因子为定值,虽然在算法前期能够实现大范围搜索,但是在后期如果继续保持固定的步长,那么萤火虫可能会因为振荡而无法收敛。因此,将固定的步长因子α0调整为自适应步长因子,公式为
α=α0p
(13)
那么萤火虫位置更新的表达式为
(14)
综上所述,将式(14)代替式(8)得到IFA算法,可以在不同的阶段进行充分、有效的搜索。
3 IFA-XGBoost故障诊断模型
3.1 涡轮叶片故障机理
长期运行在恶劣工作环境中的涡轮叶片要承受高温、高压和剧烈振动等冲击。保险公司指出:涡轮叶片断裂是燃气轮机最主要的故障,占燃气轮机总故障的42%。导致该故障发生的原因主要有以下3类[13]。
一是疲劳,由于涡轮经常的起动、加速、减速以及停车,各部件要承受复杂的循环载荷作用,最终引起高周疲劳、低周疲劳或热疲劳,使得叶片断裂。二是蠕变,由于涡轮的排气温度不断增加(从20世纪50年代1 150 K到现在2 000 K),蠕变将导致叶片的塑性变形过大甚至产生蠕变断裂[14]。三是腐蚀,高温燃气对叶片的腐蚀包括冲刷造成的腐蚀和对金属叶片的氧化腐蚀。腐蚀会降低叶片的性能,当腐蚀达到一定程度,叶片材料性能不能满足要求时,就会发生断裂。
叶片断裂不容小觑,叶片状态的实时监测和定期维护对保证燃气轮机安全运行有重要意义。将上述3种异常状态和正常状态的类别分别用编号1~4来表示。
3.2 数据处理和特征提取
每一台机组有上百个属性,其中过半属性表示排气端特征、燃料情况、各阀门与断路器的开闭状态,需要将这些无影响或影响很小的变量剔除;而涡轮输出功率、涡轮膨胀比、高压转子转速、低压转子转速、涡轮排气温度、压气机进口导流叶片转角位置、压气机压比、燃油流量变化量、滑油压差等9个状态参数可以表征涡轮叶片故障征兆[15]。为了减小模型复杂度,进一步挖掘故障信息,从这9个参数当中进一步提取故障特征,分别用X1,X2,X3,…,X9表示。由于不同属性值相差很大,并且具有不同的量纲,因此必须进行归一化操作以避免某些特征的数值太小而被淹没。采用标准化方法进行转换,公式为
(15)
σ——标准差;
采用核主元分析(Kernel Principal Component Analysis,KPCA)方法实现非线性数据降维,构造模型的输入特征向量。选用累计贡献率E>95% 的变量作为选取主元的依据[16]。由于前6个主元累计贡献率为 96.38%,将其作为判断故障类型的特征向量,分别命名为T1~T6。各参数贡献率如表2所示,部分样本的特征向量及对应的状态类别如表3所示。
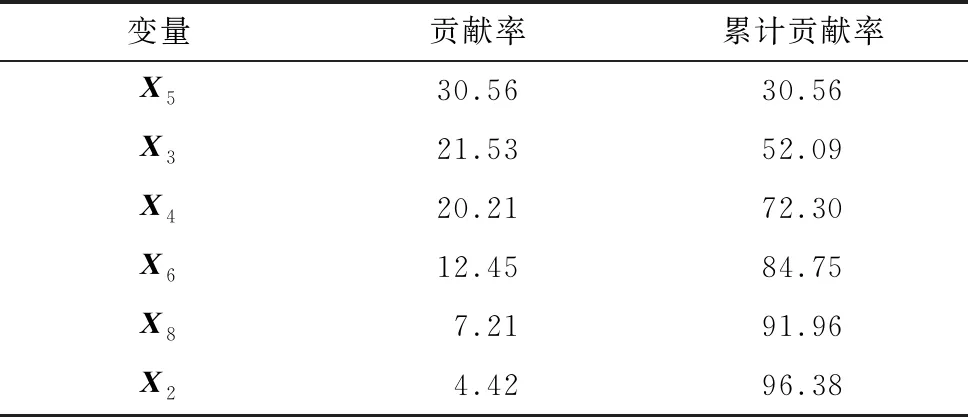
表2 核主元贡献率及累计贡献率 单位:%
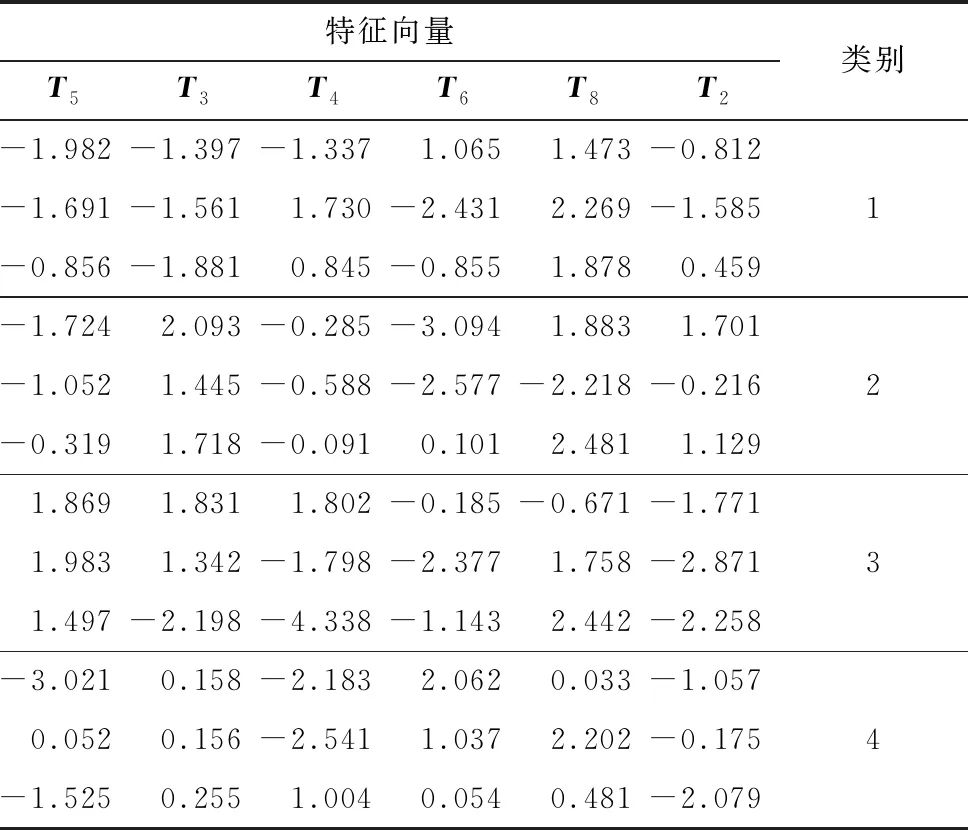
表3 KPCA提取的特征向量及对应的状态类别
3.3 IFA优化XGBoost超参数
树最大高度max_depth和学习率learn_rate等超参数的选取对模型的性能有着很大的影响,因此通过IFA算法对XGBoost的超参数进行寻优。在此过程中,每个萤火虫个体xi代表XGBoost的超参数max_depth,learn_rate,num_leaves,min_child_weight,subsample的组合,其编码为矢量格式,适应度函数值Fitness选择XGBoost的损失函数Loss。在IFA-XGBoost训练过程中,每一个萤火虫个体代表一组超参数,其适应度值的大小直接体现了对应模型性能的优劣,将性能最好的模型用于燃气轮机涡轮叶片的故障诊断。IFA优化XGBoost超参数的流程如图1所示。

图1 IFA优化XGBoost超参数的流程
3.4 燃气轮机故障诊断模型
基于IFA-XGBoost的燃气轮机故障诊断方案如图2所示。首先利用传感器网络采集关键部件的运行参数,把采集到的原始参数KPCA进行特征提取和降维;在离线阶段,对故障数据集进行学习和训练,通过IFA优化XGBoost的超参数来提升分类准确率;在线诊断时,利用训练得到的模型依据特征向量确认样本所属类别,得到相应的故障类型。
4 算例分析
在机器学习的分类任务中,对于多分类问题,只有一个准确率(accuracy)不能全面的对模型性能进行评价,为此引入精确率P、召回率R和F1系数F1,定义为
(16)
(17)
(18)
式中:TPi——样本真实类别是i,预测是i类;
FPi——样本真实类别不是i,预测是i类;
FNi——样本真实类别是i,预测不是i类。

图2 基于IFA-XGBoost的燃机故障诊断方案
根据IFA算法计算得到XGBoost的最优参数,然后建立模型得到测试样本的分类结果。为了体现萤火虫算法改进前后的差异,分别通过IFA和FA进行寻优,其中算法设置为相同的初始值:初始萤火虫种群规模N=50,初始步长因子α0=0.6,最大迭代次数imax=100,光强吸收系数γ=0.75。最优萤火虫个体适应度值变化情况如图3所示。
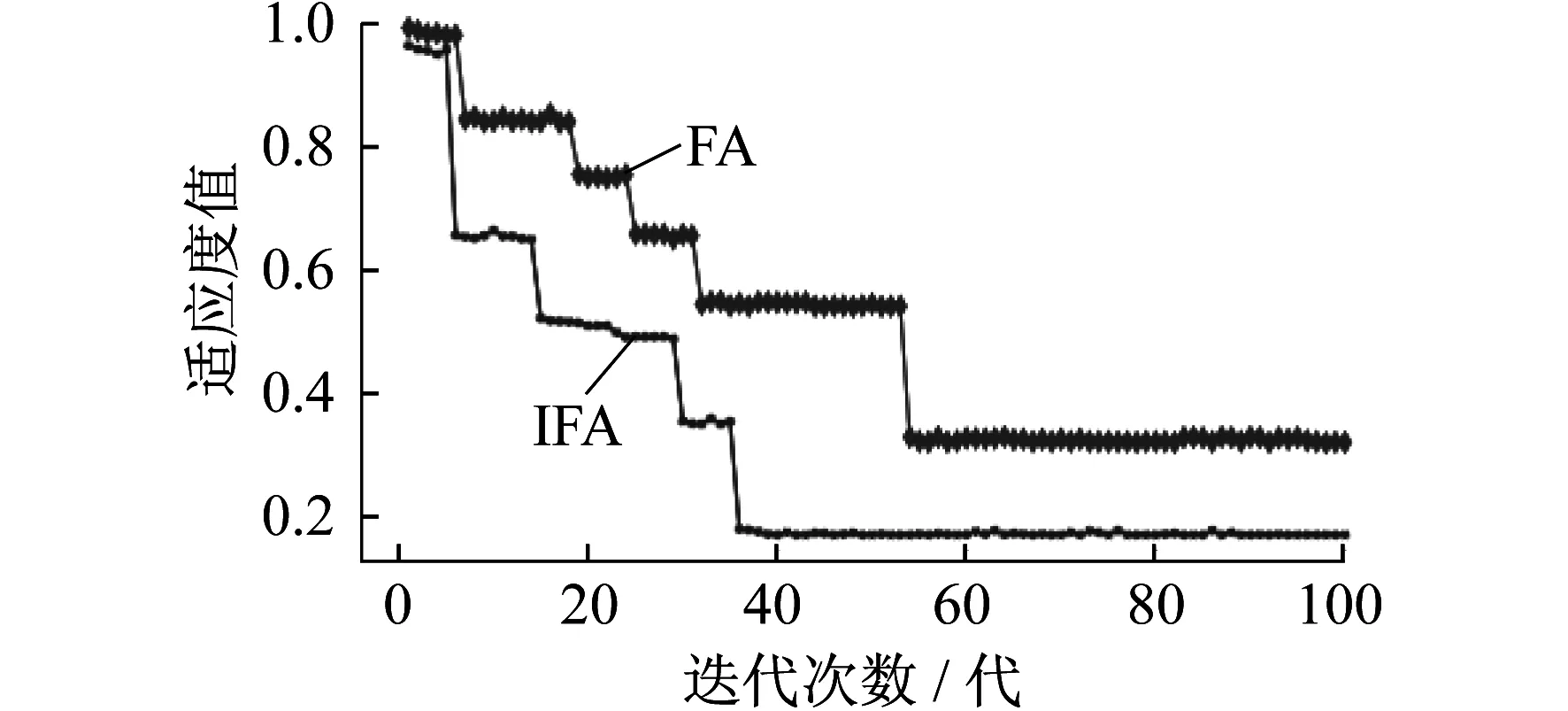
图3 IFA和FA的适应度曲线
由图3可知,在种群规模为50时,FA经过60代的进化收敛于最小适应度值0.321,而IFA在进化到40代时收敛到0.18。由此可见,与FA相比,IFA寻优超参数的速度有一定程度的加快,适应度值的减小意味着IFA-XGBoost的分类准确度更高。IFA和FA寻优超参数的结果如表4所示。

表4 两种算法寻优得到的参数
根据两种寻优算法得到的超参数分别建立IFA-XGBoost和FA-XGBoost模型,未优化的XGBoost采用默认参数值。图4~图6为3种模型的分类效果,在测试集上的分类性能如表5所示。

图4 IFA-XGBoost诊断结果
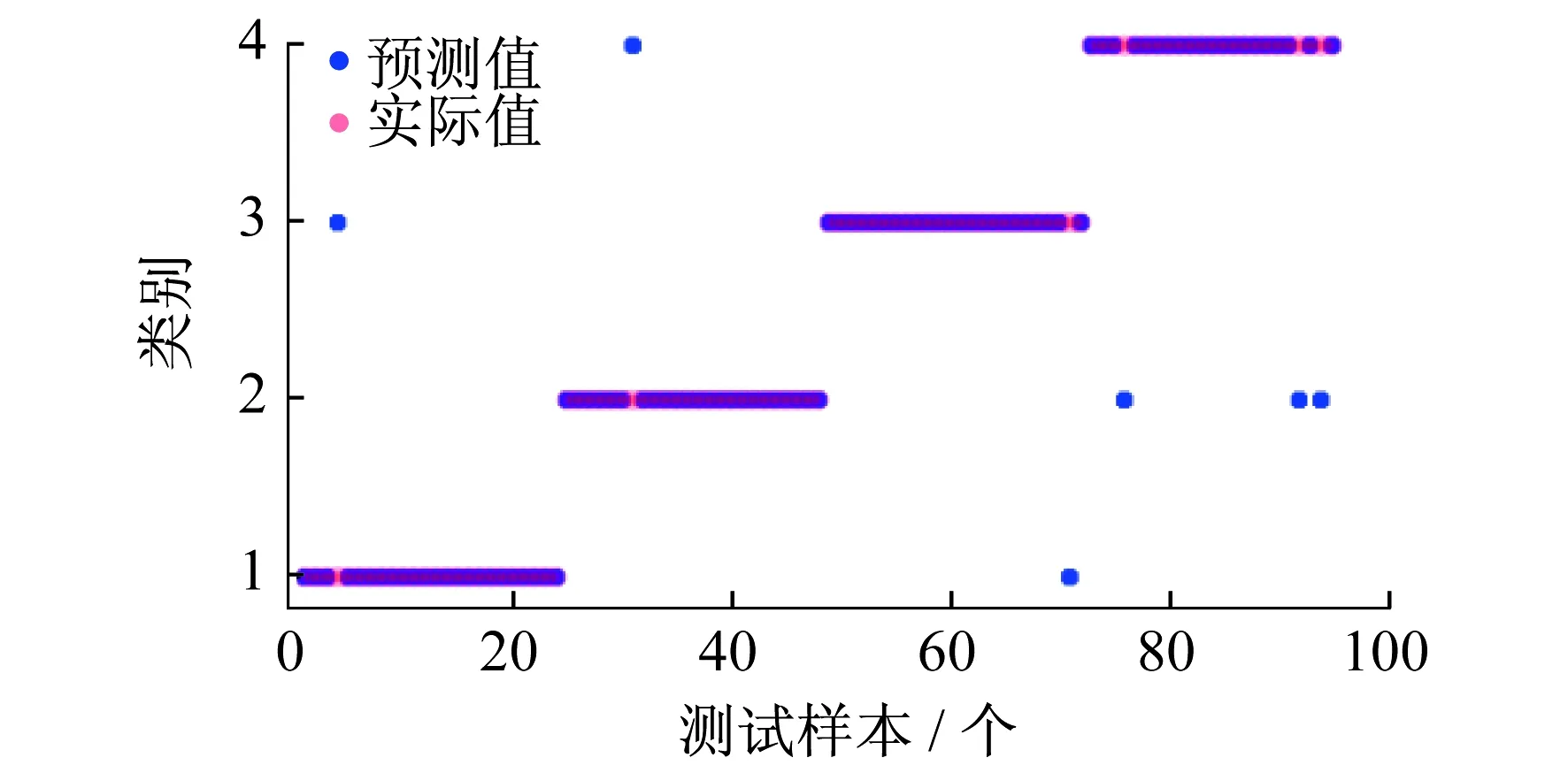
图5 FA-XGBoost诊断结果

图6 XGBoost诊断结果

表5 不同模型的性能对比
从上述分类结果可以看出,采用IFA-XGBoost对叶片的故障类型进行诊断,其精确率和召回率均为0.968 7,准确率为0.968 4,效果优于FA-XGBoost和未优化的XGBoost。这表明IFA具有更好的全局寻优和局部寻优能力,能有效克服局部最优解的问题。从模型的时间复杂度来说,XGBoost由于采用默认参数,所以运行时间最短;IFA凭借引入的位置更新策略和动态步长更新措施能够避免个体陷入局部最优值,所以IFA-XGBoost的训练速度要快于FA-XGBoost。由此可知,IFA-XGBoost对于燃气轮机涡轮叶片的故障诊断具有速度快、效率高等优点。
5 结 论
为解决XGBoost参数选取不当对涡轮叶片诊断结果产生不利影响的问题,本文提出采用IFA算法来优化XGBoost的超参数,建立了IFA-XGBoost故障诊断模型,并与FA-XGBoost和未优化的XGBoost进行对比。结果表明,与FA相比,IFA的收敛效果更好,能够提升XGBoost的性能,IFA-XGBoost以0.9687的精确率和召回率实现样本分类,能更好地应用于叶片状态识别,提高了发电的安全性和经济性。
