基于优化策略和深度学习的低光照图像增强
2021-07-16黄子蒙陈跃鹏
黄子蒙,陈跃鹏
(1.武汉科技大学信息科学与工程学院,湖北 武汉 430081;2.武汉理工大学自动化学院,湖北 武汉 430070)
可见度高的图像能够呈现出目标场景的清晰细节,这对于基于视觉的自动驾驶技术来说是必不可少的,如车辆检测[1],车道识别[2]等。然而,通常在低光条件下拍摄的图像可见度很差,其实际应用价值受到限制。目前,国内外学者已经提出了许多图像增强技术来增强低光照图像,包括基于直方图的方法[3-7],基于非线性单调函数的方法[8-9],灰度映射和基于滤波的方法[10-12],基于Retinex理论的方法[13-15]和基于去雾的方法[16-17]。虽然现有的方法能够取得不错的效果,但由于忽略或错置非线性相机响应函数(Camera Response Function,CRF),可能导致图像增强过度或增强不足。
Ren等人介绍了新相机响应特性的增强框架[18],通过估计图像的亮度成分获得最佳曝光率,然后根据相机响应功能模型获得中等曝光增强效果。但是,与使用估计精确的三通道响应曲线相比,其方法中使用的固定摄像机响应曲线仍会产生增强图像的失真。近年来,深度学习在计算机视觉领域取得了巨大成功[19-21]。与传统算法相比,深度学习方法具有较强的自适应能力,可以通过优化策略获得更强大的模型。
卷积神经网络(CNN)在图像恢复和增强应用中已经证明了其有效性。例如,Li等人训练了深度卷积神经网络(LightenNet)来执行低光图像增强任务[19]。Guan等人试图通过小波深度神经网络去除图像中的条纹噪声[20]。在这些应用中,可以轻松生成与低质量图像相对应的高质量图像。使用这些成对的训练数据,CNN可以用来学习低质量图像与其相应的高质量参考图像之间的映射函数。然而,对于移动设备来说,卷积神经网络技术由于其计算复杂性和模型较大而难以部署。
针对以上问题,本文提出了一种新的融合相机响应模型与深度学习的低光照图像增强方法,通过采用相机响应模型方法生成的数据集训练一个专门设计的深度学习网络用于对低光照图像细节的进一步增强,并且通过实验验证该方法的有效性。
1 融合非线性相机响应函数模型的深度学习方法
1.1 方法流程
本文提出的融合非线性相机响应函数模型的深度方法,基本思路是:a)基于相机响应函数模型,根据输入图像估计最佳曝光率,对曝光不足的区域做增强曝光处理,生成增强曝光的中间图像;b)设计一种轻量级反向残差卷积神经网络 (Lightweight Reverse Residual Convolutional Neural Network,LRNet)来预测中间图像与参考图像之间的残差;c)在网络的最后阶段,将丢失细节信息的输入图像与预测的残差图像进行融合得到最终的增强图像。
整个方法的流程图如图1所示。首先,中间图像采用基于相机响应模型的方法来生成。随后,提出了一种LRNet,它可以直接学习中间图像与参考图像之间的残差映射,以恢复中间图像的细节。

图1 本文方法流程图
1.2 基于相机响应模型的最佳曝光中间图像生成
图像的成像过程可用相机响应模型来解释,相机响应函数(CRF)可用做描述相机响应模型,该模型刻画了相机的曝光量E和图像亮度值P之间的非线性关系[22],其定义为:
P=f(E)
(1)
式中f为相机响应函数。
设P和P¢分别是在同一场景下不同曝光量E和E¢拍摄的图像,且E¢=kE,其中k为曝光比。P和P¢的关系可表示为:
P′=g(P,k)
式中g为亮度映射函数(Brightness Mapping Function,BMF),它刻画同一场景下不同曝光的图像之间的亮度非线性映射关系[23]。由式(1)可得,
P=f(E),P′=f(E′)=f(kE)
因此,CRF与BMF之间的转换关系可以表示为:
g(f(E),k)=f(kE)
于是,相机响应模型也可以用BMF来表达。当BMF已知时,通过对图像P设置不同的曝光比k来生成不同曝光的图像P′,从而起到改变图像像素曝光值的效果。
为了实现更好的增强效果需要找到最佳曝光比,利用式(2)获到仅包含曝光不足的像素灰度值集合:
Q={I(x)|T(x)<τ1}
(2)
式中T(x)为I(x)的光照分量图,τ1为区分曝光不足像素的灰度阈值。于是,曝光不足的像素点信息熵为:
H(Q)=-∑ipilog2pi
式中pi代表Q中每个灰度等级i出现的概率。这样,由图像信息熵最大化原则就可以求解最佳曝光率:
从而得到更加优化的增强曝光中间图像:
P¢=g(P,k)=eb(1-ka)Pka
(3)
对于给定的相机,其BMF是固定的,参数也是固定的。本文使用文献[18]中的参数a=-0.329 3,b=1.125 8,给定一幅输入图像,可以得到更加优化的增强曝光中间图像。
1.3 通过LRNet恢复中间图像的细节信息
通过轻量化网络恢复中间图像信息的方法如图2所示。设P为待处理的低光照图像,P′为生成的中间图像,它可以用式(3)来表示。

图2 轻量化网络恢复中间图像细节
设y是图像P的参考图像,可以表示为
y=yl+yh
式中yl和yh分别是参考图像中的低频分量和高频分量。基于深度学习方法通常使用端到端的方法来表示y。在此过程中,神经网络必须保留所有输入图像的详细信息,这对于许多权重层来说,需要长期储存的端到端关系,容易出现梯度消失/爆炸的问题[24]。本文通过残差学习来解决该问题。设y的初始图像表现形式为F(P),它可以被视为已知的信息。设(y-F(P))为y′,即y的未知信息。则:

本文采用的LRNet如图3所示,具有三种不同颜色的类型模块,分别描述如下:
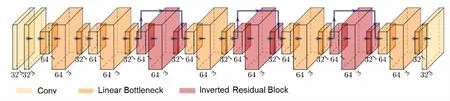
图3 轻量级反向残差卷积神经网络结构
(1)卷积层模块:(带有标准化层和PReLU)采用了32个3×3的卷积核(stride 1,pad 1);
(2)线性瓶颈模块:又由三个卷积层构成,第一卷积层(带有标准化层和PReLU)采用64个1×1的卷积核,第二卷积层(带有标准化层和PReLU)采用32个3×3的卷积核(stride 1,pad 1),第三卷积层(带有标准化层)采用32个1×1的卷积核;
(3)反向残差模块:在线性瓶颈模块的基础上增加了捷径。插入捷径方式的动机与经典残差连接的动机类似:希望提高梯度在乘数层之间传播的能力[25]。反向残差模块有两个优点:(1)重用特征以缓解特征退化;(2)减少计算量和参数数量。这样处理不仅可以加快网络的收敛速度,还可以减少训练样本的数量。由于池化在尺寸缩减过程中可能会丢失图像信息,因此不会在网络中使用。
2 实验结果与分析
在本节中,通过构建道路图像数据集,并使用Caffe来训练LRNet。为了评估本文方法优势,先后通过对自制数据集和公共数据集SICE[26]进行训练,并将训练结果与五种现有的低光照图像增强方法进行了比较。
2.1 自制数据集上的比较
本文自制数据集的图像包含500个在真实场景中捕获的低曝光/中曝光图像对,其中部分如图4所示:第一行为低光照图像,第二行为参考图像。为了避免受到其他因素干扰,只更改曝光时间,同时固定相机的其他配置。在室外环境中,拍摄移动物体(如行人、车辆和摇曳的树木)很难获得一个对齐良好的序列。因此需要通过使用三脚架防止相机抖动,并使用连续包围模式自动捕获一系列曝光图像,以确保只改变曝光。本文通过数据集中图像的多样化,包括街道、道路标识、建筑等场景,来表明LRNet方法的鲁棒性。最后,本文随机将数据集中的图像分为两个子集:460个图像用于训练,其余的图像用于测试。

图4 部分自制数据集
将本文的方法与五种现有的低光照增强方法,如:LIME[16]、NPE[27]、Dong[17]、LECARM[18]和 RetinexNet[28]进行比较。如图5所示,LIME方法处理后的图像非常明亮,许多明亮的区域已经饱和。NPE方法处理后的图像在亮度较高区域产生了较为严重的失真。Dong方法处理后的图像有很多夸张的边缘,使图像看起来像一幅艺术画。LECARM处理后的图像增强效果不明显,图像亮度整体偏暗。而RetinexNet处理后的图像失真比较严重,出现了偏色和伪影的问题。本文方法处理后的图像整体亮度较为均衡,在恢复出道路标线的同时,也保证了道路两旁的物体没有过度增强,看起来比较自然,有利于人眼的视觉观察。


图5 不同方法的增强结果对比
定量比较使用常用的四个指标:SSIM和PSNR进行定量评估,NIQE用于评估自然保存,LOE用于评估亮度失真。SSIM和PSNR越高,增强的图像与参考图像越接近,NIQE和LOE值越低,图像质量越高。所有最佳结果都以粗体显示,如表1所示。本文方法生成的测试图像具有平均值更高的 SSIM、PSNR 和更低的NIQE。对于LOE平均值,它落后于LIME 和NPE。正如Guo等人[16]所说,使用输入的低光照图像本身来计算LOE是有问题的。因此,使用文献[29]中使用参考图像的方法来计算LOE,类似于计算SSIM和PSNR,并表示为 LOEref。这样,本文的方法更具有一定的优势。
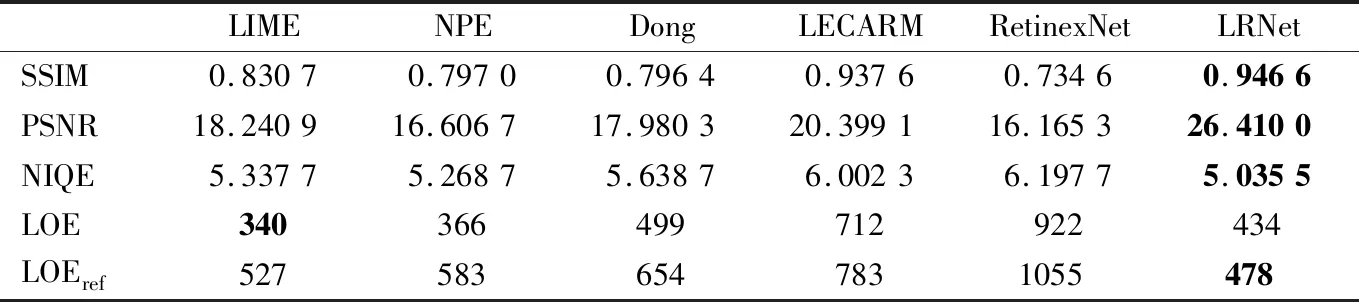
表1 不同方法增强结果在自制数据集上的定量比较
2.2 公共数据集上的比较
为了进一步证明本文方法的鲁棒性,本文还对公共数据集SICE进行了实验。表2显示了本文方法和五种现有的低光照增强方法的定量比较。由于SICE数据集的对比度很高,某些图像看起来不太自然,因此只选择了一部分图像作为参考。可以看到,虽然在LOE和LOEref中,略落后于NPE排在第二位,但是在SSIM和PSNR上,本文的方法优于其他所有方法。对于非参考指标NIQE,本文方法也可以得到较低的值。实验结果说明本文方法在恢复图像细节质量上具有一定的优势。
3 结论
本文提出了一个新的融合非线性相机响应函数模型的深度学习方法,以提高低光照图像质量,为智能导航和自动驾驶提供高可见度的图像。本文的主要思想是使用LRNet来学习残差图像,而不是简单的端到端映射,从而利用残差图像的简单性让网络有效地学习细节。此外,本文还创建了一个包含500个曝光不足图像对的新数据集,使网络能够恢复低光照图像清晰的细节,更接近真实的参考图像。本文在自制数据集和SICE数据集上进行了实验,并比较了本文的方法与五种现有的方法,证明了本文的解决方案在可视化比较、SSIM、PSNR、NIQE和LOE指标的定量比较方面的优势。
