适用于资源受限设备的移动应用类别实时识别方法
2021-07-16张美璟许发见
陈 旖 张美璟 许发见
(福建警察学院计算机与信息安全管理系 福建 福州350007)
0 引 言
近年来,移动互联网发展迅猛,截至2019年2月,中国手机网民规模达8.17亿,网民中使用手机上网人群的占比为98.6%[1]。相比于传统的桌面计算机,在使用场景上,手机更贴近生活环境,使用频率高,移动范围广;在信息类型上,手机蕴含更多的个人信息;在软件种类上,手机以移动应用(App)为主。其中,手机上安装的移动应用App的类型及使用频率在用户画像刻画[2]、用户习惯研究[3]方面具有较高的价值。例如:频繁使用购物App的用户往往被打上购买欲强的标签;反复开启同类购物软件,可能反映出某类用户存在比价习惯等。因此,对手机上安装的App类型与使用频率进行识别和统计,可以为进一步的数据挖掘提供数据,具有很好的参考价值。
然而,移动互联网产生的数据量极为庞大,如果采用离线识别的方式进行分析,需占用大量的存储空间并消耗大量的带宽进行文件传输。如果采用在线实时分析,则需要在网络设备上直接处理数据,而常见的网络设备往往计算能力受限,因此要求识别方法应避免占用过多的系统资源。
针对移动App识别的问题,文献[4]提出了一种通过HTTP报文user-agent字段进行识别的方法,但由于多数应用并未遵循规范,未使用该字段标记自身类型,使得该方法目前可用性较低。文献[5]提出了一种基于视觉感知特性的应用识别方法,其采用HTTP报文的头域和请求信息作为输入构建样本图像,再将其输入二维卷积感知网络模型进行分类器训练。该方法对流量样本有较好的适应性,但其计算量大,需采样后再进行离线计算。文献[6]提出了一种基于模式匹配的识别方法,其使用HTTP报文的Host、URI、cookie等字段构建样本库,并使用模式匹配算法对未知报文进行分类。该方案需要进行深度包检测来读取HTTP字段,然而当前App开发已逐步使用加密的HTTPS协议来取代HTTP协议,这使得该方案无法读取到对应的HTTP字段,导致其可用性变弱。
基于上述研究,本文提出一种适用于资源受限的网络设备的App识别方法。利用App运行时会访问特定域名集合的特性来进行识别,可支持使用HTTPS的App。该方法设计了一套轻量级的转换机制,可将采集到的报文数据流转换为对应的低维度向量,再将向量作为支持向量机的输入进行训练和识别。另一方面,为避免占用过多的系统资源,方法使用了布隆过滤器来过滤无关IP地址,并设计了背景流量过滤机制来减少调用分类器的次数。这使得方法对系统资源占用小,可实现在运算能力较弱的接入网关上直接对手机App进行实时在线识别。此外,由于本方法仅使用临时IP标识用户,可避免App用户的具体身份信息被泄露。
1 相关网络技术
随着移动互联网技术的发展,当前的移动应用开发行业已经形成了较为通用的开发范式和框架,App使用的网络技术存在普遍的相似性,其典型的访问过程如图1所示。
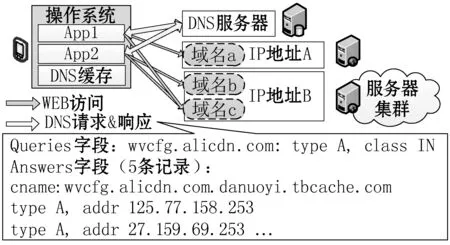
图1 App访问服务器的典型过程
典型场景下,智能手机安装有多款App,App在启动时会主动与远程服务器通信。App代码中使用域名标识服务器,App会先通过操作系统来访问DNS服务器以获取目标服务器的IP地址,再与其建立TCP连接,最后根据业务逻辑进行Web访问。经过对多款主流App报文的深入分析,可以进一步总结出以下特点。
(1) App普遍使用HTTP/HTTPS协议与远程服务器通信。其中,HTTP使用明文传输,而HTTPS使用SSL/TSL协议对报文进行加密,可以抵抗深度报文检测。随着安全性需求的提升,目前HTTPS协议以被广泛应用于App开发。
(2) App代码中使用域名来标记服务器,而非IP地址。服务器使用域名提供服务地址,可以对外部屏蔽云端服务器的网络IP地址出现变化的情况。例如:服务器可以提供多个网络运营商的IP地址,以优化不同网络用户的访问速度;服务器也可以主动改变域名/IP地址的映射关系,来实现对服务器集群的负载均衡等。
(3) App依赖操作系统进行DNS访问,可直接使用对应API,传入域名来获得IP地址,而无须自己维护域名/IP的映射关系。操作系统从API收到查询请求之后,将先在DNS缓存中查找,若存在缓存则直接返回对应IP;若未找到,则向DNS服务器请求目标域名的IP地址,再返回给App。DNS服务器通过DNS响应报文来回复域名相关的信息,典型响应报文结构如图1所示,其报文中描述了域名“wvcfg.alicdn.com(阿里巴巴缓存服务器)”的信息,包含该域名的别名、多个可用的IP地址、管理机构数据、附加信息等。系统将这些信息加入DNS缓存中,并根据网络变动或超时等策略更新信息。
(4) App与服务器域名及服务器IP之间呈现多对多的关系。一方面,不同App访问的服务器域名存在重叠。这是由于App开发中往往会使用到其他厂商的服务,例如:打车软件使用地图厂商提供的定位与导航SDK;部分App使用了微博、微信的第三方登录接口等。其结构类似于图1中App1和App2都访问了共同的域名。另一方面,域名和IP也并非一一对应。第一,大多数域名存在多个可用的IP地址,如图1的DNS报文所示;第二,不同域名的服务器也可能共用相同的IP地址,例如,高并发的App普遍使用第三方厂商提供的内容分发网络(Content Delivery Network,CDN)来加速数据传输。CDN缓存服务器虽对不同App提供了不同的域名,但实际指向了相同IP地址的缓存服务器。其结构类似图1中App1和App2分别访问了独立的域名b和域名c,但实际上都访问了IP地址B所对应的服务器集群。
根据上述分析,由于App间访问的域名存在重合且域名和IP并非一一对应,网关虽然无法直接通过IP地址识别到特定App,但可以根据App访问指定域名的特性及域名和IP的关系,从一系列报文的IP地址中推测出对应的App。本文方法基于这一特征进行设计。
2 方法和模型
2.1 系统建模
2.1.1应用场景
本文方法典型的应用场景如图2所示。在典型的中大型企业网及校园网中,往往存在核心层、汇聚层、接入层三层结构。核心层一般使用高吞吐、高性能和高可用的大型核心交换机构成,用于内部主干网之间的通信,以及内网与外网间的通信;汇聚层主要用于将众多的接入层设备连入核心层;接入层直接面向终端设备提供网络接入服务。由于终端设备数量众多,因此接入层设备一般数量较大,且价格低廉、功耗低、运算能力弱。
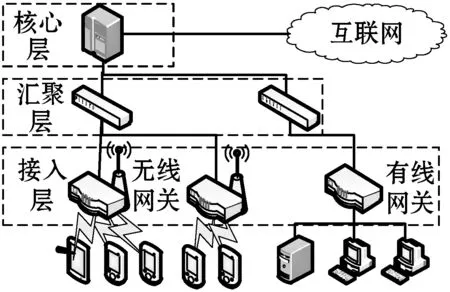
图2 典型应用场景
本方法适合部署于接入层设备,其优势在于:① 可充分利用大量输入层设备的剩余算力,无须部署独立的运算服务器;② 采用分布式运算,避免单点集中式运算中出现运算性能、网络吞吐等瓶颈;③ 核心层、汇聚层对性能、可靠性有较高要求,在接入层增加非关键性的功能对网络整体的影响较小。
由于接入层设备的运算和内存资源往往受到限制,因此在方法设计中需要避免占用过多的系统资源。
2.1.2模型训练与应用过程
本文方法分为两个步骤进行:第一步采集样本数据,并在计算机上训练模型并生成参数;第二步将训练得到的模型及参数部署到实际的接入层设备上,并进行相应指标评估。
模型训练的过程如图3所示。首先需要从环境中采集目标App的通信样本集合,以及其他无关App的通信样本作为背景流量样本。接着,从通信样本中过滤出DNS报文,并解析生成域名/IP地址的映射表和域名集合。再根据样本报文的IP地址,将App样本中所有报文映射到域名集合中,从而将一个样本文件生成一个对应的向量。向量的每个维度对应一个域名,其大小表示样本中访问该域名的次数。由于生成的向量维度很高,本文方法基于Jaccard包相似度设计了一种降维算法,用于对样本向量进行降维。经过降维后的样本向量集合再作为训练集输入支持向量机(Support vector machine,SVM)进行分类训练。另外,本文还设计了一种背景报文过滤器,以降低方法对系统计算资源的占用。在训练过程结束之后,将输出域名/IP映射表、降维算法参数、背景报文过滤器参数、SVM分类器模型参数,供识别过程使用。

图3 模型训练流程
识别的过程如图4所示。在接入设备上,识别程序循环抓取报文,如果抓取到DNS报文,则解析报文并更新域名/IP映射表。如果抓取到通信报文,则将其IP地址使用布隆过滤器检查,如果其IP地址属于某个域名,则将其加入到滑动窗口队列中。识别程序周期性地将滑动窗口中的报文映射到域名集合,并进行降维,得到待检测的向量。再将向量使用背景报文过滤器进行检查,如果检查通过再使用SVM分类器进行分类,得到分类结果。
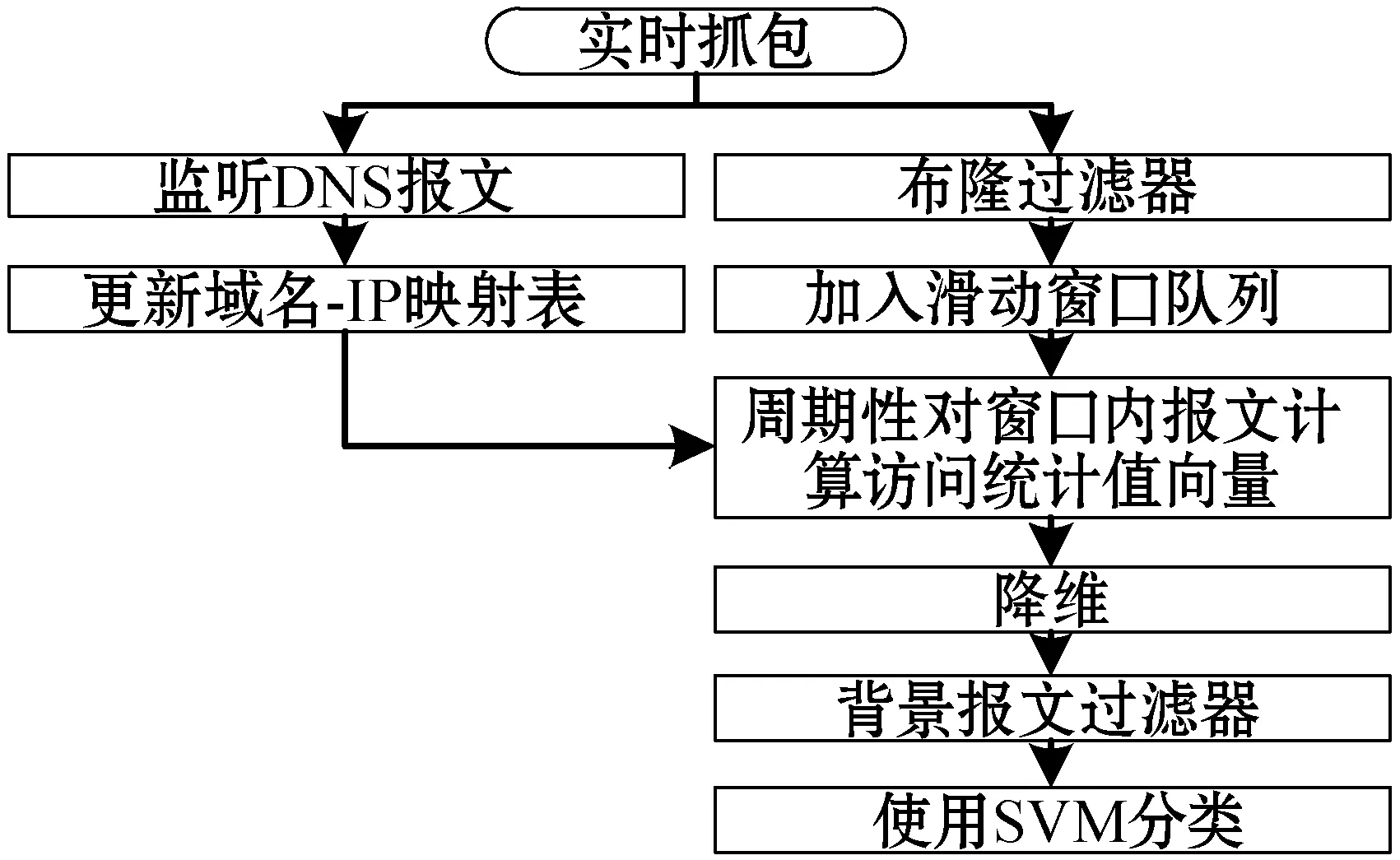
图4 运行中识别流程
2.2 样本采集和数据变换
2.2.1报文样本采集
在样本采集环境中,存在一台运行嵌入式Linux系统的无线网关、一台安卓智能手机、一台通用计算机。其中,安卓智能手机通过Wi-Fi连接无线网关,使用USB线连接计算机,并开启USB调试模式,且禁止后台App运行;计算机通过网线连接网关,可使用SSH协议登录网关的控制台,并可通过安卓调试桥(Android Debug Bridge tools,ADB)连接上安卓手机的开发调试服务。
对App采样时,计算机先通过控制台命令,在网关上使用抓包工具TCPDUMP对无线接口进行抓包,再通过ADB命令触发待采样的App运行。待抓包结束之后,计算机通过命令控制TCPDUMP工具停止抓包并生成cap格式的抓包文件,再使用ADB命令控制手机关闭App进程。对该App的采样到此结束,计算机在进行延时等待后,将对下一App进行采样。在对所有App完成报文采样后,计算机将把抓包文件下载到本地。
本文针对安卓市场上不同类别且下载量较大的50款App进行采样,在不同的时间点,共采样40轮。将其中30轮作为训练样本,其他10轮作为测试样本。
2.2.2数据探索与预处理
使用分析工具Wireshark对采集的样本文件进行数据探索,可以发现App通信样本中存在共性。本方法根据这些共性,制定出如下几项样本预处理的规则:
(1) 以握手报文数量作为访问服务器频繁程度的度量。App每次启动时,TCP的握手报文数量一般大致相同。这是因为App会与哪些服务器通信、将创建几个TCP连接通信,都是程序中固化的。而App的通信报文数量不稳定,这是因为App的缓存更新功能往往是周期性执行的,更新周期及数据大小差异等原因,都导致通信数据量并不稳定。
因此,本文方法在统计App与某个服务器之间的通信报文数量时,仅统计其中TCP握手报文个数。
(2) 统计握手报文的时间范围为10秒。启动过程中,App往往先显示启动图片,同时与服务器进行频繁的通信。大部分的TCP握手报文都集中在首个握手报文发出后的10秒内发出。因此,本方法选取App启动后,首个握手报文发出后的10秒内的握手报文进行统计。
(3) App以一组10个为单位进行分组识别。现实环境中,App类型繁多。若把所有待测App一起进行分类训练,将大大增加训练的难度,影响模型分类质量。
为解决上述问题,本文方法将App进行分组训练。首先将待分类的App按10个一组进行分组,得到数据集F={F1,F2,…,FI},共I组数据组,若出现App数量不足一组时,则填充全0的样本。若使用F1数据来训练模型时,则待检测App组成的数据集为FApp={F1},而其他App样本则作为无关的背景报文组成数据集FBG={F2,F3,…,FI}。在训练过程中,F1-FI将迭代作为FApp训练模型,最终生成多组模型参数。在检测阶段,待分类的数据可被多组不同参数的模型进行分类,进而得到分类结果。
按上述分组策略,本文方法以组为单位处理数据。故可将采集的50款App样本分为F1-F5共5组。其中F1包含A0-A9共10款应用,分别为淘宝、支付宝等常用App。在后续内容中,以F1为例展示一组数据的处理效果。即以F1作为FApp,以F2-F5作为FBG。
2.2.3样本数据变换
处理报文样本时,首先遍历集合FApp中所有样本文件,从DNS报文中解析所有域名,再剔除未被访问域名,从而生成域名集合N={n1,n2,…,nx},以及域名/IP的映射表。之后,再独立解析FApp中每个样本文件,先将文件中首个握手报文出现的10秒内的所有握手报文过滤出来,再将握手报文访问的IP地址输入域名/IP映射表,得到报文访问的域名,并将对应域名的统计值加1。处理结束后,每个文件都会生成一个数据记录。定义向量d=(Cn1,Cn2,…,Cnx)来表示该数据记录。其中,Cnx表示该样本中App向域名nx发出的握手报文个数。如果将每个域名nx看作一个轴,则Cn1-Cnx可以看作样本在各个轴上投影的值。故可以将样本文件生成的记录用向量d来表示,其维度等于域名集合N的元素个数。
由于FApp中包含十类不同App,可将App按类别使用A0-A9进行编号,并使用DA0来表示A0类样本生成的向量d组成的集合。则FApp中所有文件处理完成之后,最终将生成集合DApp={DA0,DA1,…,DA9}。
图5直观地展示了DApp中数据的分布特点,其数据来源于淘宝、支付宝等10款常见的App。其中,横轴上的每个点分别对应集合N中的一个域名nx;纵轴上的一个点分别对应DA0-DA9中的一个向量d;横轴与纵轴交汇点的灰度值表示样本向量d在域名nx上的映射值Cnx,也反映出该样本对域名nx访问的频繁程度。
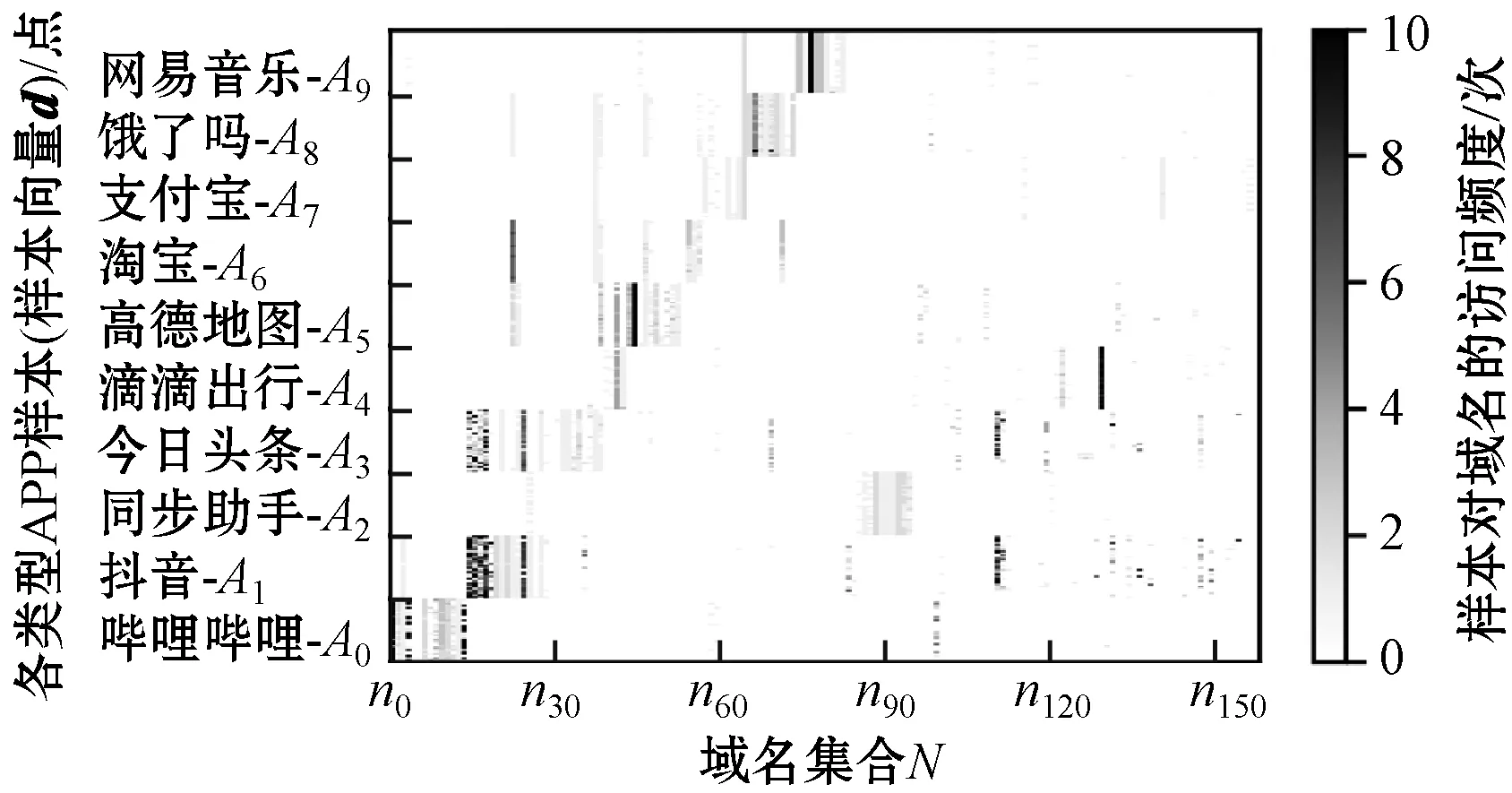
图5 App访问域名的分布特点
可以看出,同类型App生成的向量d相似度高,而不同类型App生成的向量d差异较大。不同类型App访问的域名存在少量重合。
2.3 降维与过滤背景流量
2.3.1降 维
从数据探索中可以看出,App样本生成的向量d的维度较高,其数值约在100~200之间。向量d的维度过高将导致运算量大且内存占用多。因此,需要对d做降维。
常见的降维方法有主成分分析(PCA)等。PCA技术可用于对高维空间下的点进行分析,得到新的若干条最关键的坐标轴。原始的高维数据可以投影到这些关键的坐标轴上得到新的数据。这些新的数据的维度较小,并能较好地体现原有数据的特征[7]。
以图5中的A0-A9进行实验,将集合DApp中所有的向量d组成矩阵M。其中,矩阵M的行数等于样本数量,由于存在10个App,每个App有30个样本,故共有300行;矩阵列数为向量d的维度,为157。使用PCA对M进行降维,保留90%的信息,得到降维后的矩阵M的列数为26。若再继续降低保留的信息量,则出现降维效果增加缓慢,而特征损失增加较快的情况。这将导致样本信息损失较多。考虑到网络设备的内存和运算能力较弱,使用分类器对26维的数据进行运算对系统性能影响依旧较大。因此,由于应用环境的限制,PCA技术不是本文方法最佳的降维方案。
在考虑了设备运算能力和实际数据特征的基础上,本文设计了一种基于Jaccard包相似度的降维算法。在PCA技术中,算法会从数据中寻找最佳的数据轴。而在本环境的数据中,已知矩阵M中存在10类App样本,且同类App样本之间相似度高。因此,本算法新建立一个10维的空间,空间中的轴分别代表A0-A9十类App,各轴之间相互正交。原数据向量d转换到新空间上的向量j的转换过程可分为两步处理:
(1) 由样本报文变换得到的样本向量集合DApp={DA0,DA1,…,DA9}来计算各App的样本向量均值集合Dmeans=(dA0-means,dA1-means,…,dA9-means)。计算过程即将同类App的样本向量进行向量加法运算后,除以样本数量。设某个编号为Ay的App存在样本集合DAy,集合中包含d0-dk共k个样本向量,则该App的样本向量的均值dAy-means=(d0+d1+…+dk)/k。
(2) 使用Jaccard包算法计算待测向量dx与Dmeans中每一类App的样本向量均值的相似度Sy。该算法以两个集合的交集除以并集来计算其相似度。其中,以某个元素在两个集合出现的最小次数作为其在交集中的个数;以某个元素在两个集合中出现的最大次数作为其在并集中的个数。运算时,可将向量的一个维度视作集合中的一种元素,将该维度的数值视作对应集合元素出现的次数。可定义函数INTER和UNION用于计算两个向量的交集与并集,则dx与dAy-means的相似度Sy=INTER(dx,dAy-means)/UNION(dx,dAy-means)。将dx分别与dA0-means-dA9-means进行计算后,即可得到降维后的向量j=(S0,S1,…,S9)。
转换前的dx和dAy-means的维度均等于域名集合N的元素个数,转换后的向量j的维度固定为10。该降维算法的可解释性也较好。其转换过程可视为计算待测点到样本均值之间的相似度,其数值范围在[0,1]之间,同时完成了数据归一化的操作。
图6直观展示转换后的数据,其中:横轴表示新空间中A0-A9十类App对应的数据轴;纵轴表示样本点与对应轴的相似度。图中每条线表示某一类App的样本点在某个轴上映射出的相似度数值。
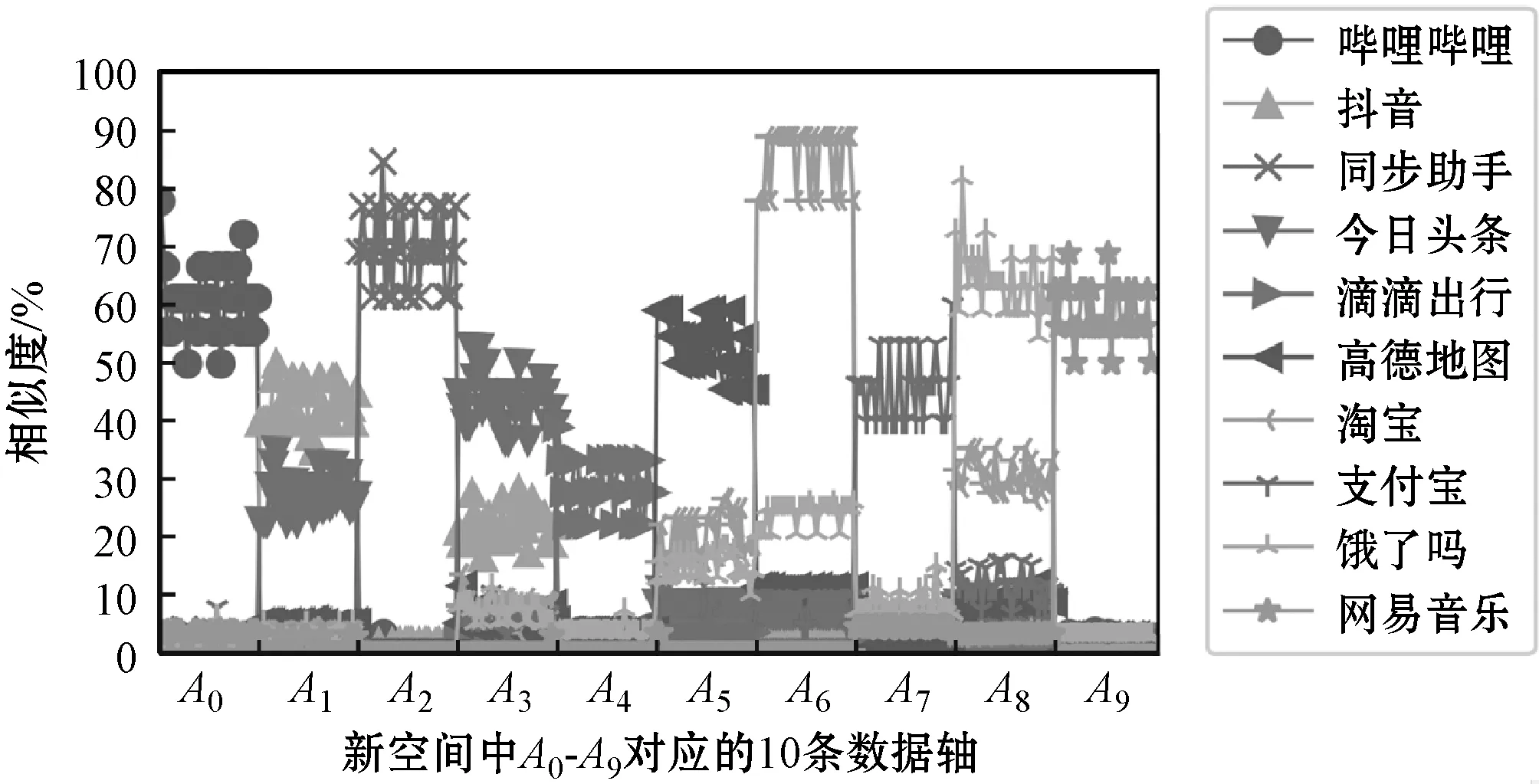
图6 样本降维效果
可以看出,一类App的样本在代表自身类别的轴上的映射的数据值较大,在其他轴上的映射的数值较小。同类样本点在特定轴上映射的数值分布在一定区间内,该特征可被分类器用于识别App类型。
2.3.2过滤背景流量
在移动互联网环境中,数量庞大的App时时刻刻都在生成通信报文,这些报文中仅有少量属于待识别App生成的报文。相对于待识别的App生成的报文,其他App的生成的报文构成了背景流量。背景流量的报文数量庞大,如果都输入到分类器进行判断,将占用大量的运算资源来处理无关数据流量。因此,本文设计了一种背景报文过滤机制来降低背景报文造成的运算资源消耗。
为探索目标App报文和背景流量报文的分布特点,可构造出图7进行分析,其中:横轴表示A0-A9对应的数据轴;纵轴表示样本点与对应轴的相似度。图中深色点为待检测的样本点,浅色点为背景报文样本在对应轴上映射出的相似度数值。背景报文样本的生成过程,即从背景报文数据集FBG中随机选取200个样本,再将样本进行数据转换并降维,降维后的向量值即样本点映射到各轴上的相似度数值。
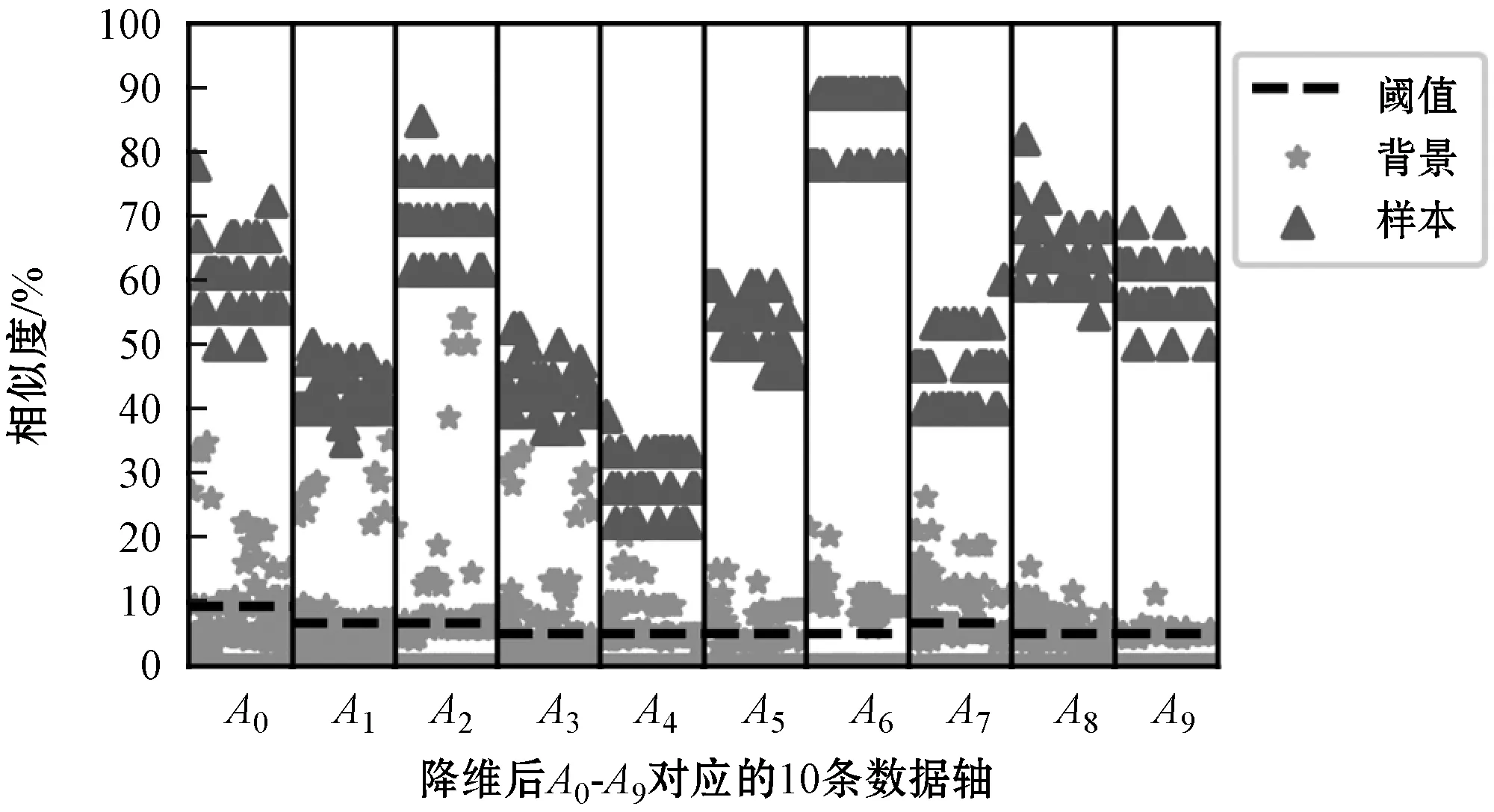
图7 目标App报文和背景流量报文的分布情况
可以看出,某类App的报文样本在代表自身类型的轴上的映射的数据值较大,而背景流量映射出的值较小。过滤机制将利用这一特性计算出一组阈值,如果样本在某个维度上的数值大于阈值,才使用分类器对样本进行分类,否则直接按背景报文处理。本文方法以轴上背景报文样本的上五分位为阈值,即过滤掉后80%的背景报文。各轴对应的阈值如图7中的虚线所示,可以看出,仅20%的背景流量和属于目标App的样本能通过阈值过滤。
2.4 SVM训练
支持向量机SVM的基本思想是寻找一个最优分类超平面将训练样本分开[8]。本文方法使用SVM作为分类器对样本进行多分类。在数据变化阶段中,App和背景流量的样本已经被转换为10维的向量。训练时,将向量的每个维度的数值按序组成数组,作为训练输入;而向量对应的样本类型作为训练输出,将App样本按类别使用数字0至9进行标识。实验中发现,若所有背景样本共用单一类别时,分类准确率较低;而每5~6种背景样本共用一种类别时,准确率较高。故采用经验值,将每6类背景样本共用一个大于9的数值标识。数据集中存在500个样本,其中含10类App作为识别目标,共300个;含40类App作为背景流量,共200个。
训练时,将数据集使用十折交叉验证法来划分训练集和测试集,采用C_SVC类型的SVM分类器,使用一对一法(One-versus-one,OVO)来实现多分类。相比于一对多法(One-versus-rest,OVR),在App版本更新时,OVO可避免对所有的分类器进行重新训练。
2.5 使用模型进行识别
相比于样本采集及训练的过程,使用模型识别的过程还需要增加以下工作:
(1) 使用滑动窗口生成待测样本。在样本采集中,App启动和抓包时间是人为控制的,而在实际的环境中,App启动时间是未知的。为了从环境中动态地生成待测样本,本文方法设计了一个滑动窗口。滑动窗口内存在一个队列,用于保存当前时间点至前10秒范围内的握手报文。当有新报文到达时,加入队列头。窗口存在一个以1秒为周期的定时器,定时器到时时,先删除队尾超时的节点,再遍历滑动窗口队列中所有报文,将报文进行样本数据转换,得到一个待识别的向量dx。进而可对dx进行降维、过滤和识别等操作。
(2) 使用布隆过滤器过滤无关IP。在数据探索中发现,域名/IP映射表中的IP地址数量约为1 500至2 000个。为避免大量使用无关IP的报文被加入队列,本文方法使用布隆过滤器来快速检查报文的IP是否存在于域名/IP映射表中。布隆过滤器由多个哈希函数和一个很长的二进制数组组成,可用于快速检查某个元素是否存在于一个很大的集合中。本文方法的过滤器使用了JSHash、RSHash、SDBMHash、PJWHash四种哈希函数,二进制数组占用1 250字节。根据布隆过滤器的性质,假设哈希函数能均匀地散列数据,有效IP为2 000个的情况下,则有约90.8%的无关IP可被过滤。
(3) 实时更新域名/IP映射表。根据对网络技术的分析,域名与IP地址的对应关系是随着环境而变化的。从样本中生成的域名/IP映射表需要根据运行环境的变化而更新。因此,本文方法在识别环境中也需要实时抓取DNS报文,并根据DNS解析的数据来更新映射表。
3 实 验
3.1 实验环境与算法实现
实验使用一台基于Mediatek-MT7620芯片方案的无线接入网关进行验证,其主频为580 MHz的MIPS架构处理器,内存为123 MB,支持两个百兆以太网口,以及2.4 GHz频段Wi-Fi接入。设备运行OpenWrt系统,该系统是一种适用于嵌入式网络设备的Linux发行版,具有强大的扩展性[9]。
本文方法的代码实现主要分为两个部分,第一部分是运行在计算机端的模型训练程序,使用Python实现;第二部分是运行在无线网关平台上的识别程序。由于网关只能支持C/C++语言编程,故使用C语言实现了识别程序,经交叉编译后部署到设备上。其中,实时抓包使用了LIBCAP库[10],SVM分类器使用了LIBSVM库[11]的实现。另外,实验中使用LIBCAP库编写了一个报文重放工具,可解析cap格式的抓包文件,并将其中抓取的报文重放到网络接口中。
3.2 识别效果评估
为评估模型识别的效果,实验使用重放工具将测试集对应的抓包文件重放到网络中,由识别程序进行在线识别。因使用十折交叉验证法测试,故识别程序需分别使用10个SVM模型进行识别,重放工具则分别重放10组测试集对应的抓包文件。10组交叉验证共生成500个识别结果。
识别程序在实验中的识别效果如图8所示。可以看出,程序对目标App报文的识别效果较好,并可以正确识别出大部分的背景流量,但部分特征和目标App相似的背景流量可能会被误识别为目标App。可使用准确率P来评估识别效果,准确率P=TP/(TP+FP),其中TP为分类正确的样本数,FP为分类错误的样本数。则在当前的测试集条件下,分类器的识别准确率约为94.4%。

图8 识别结果的混淆矩阵
3.3 资源占用情况评估
为评估本方法对系统资源占用情况,实验中使用top命令以1秒为周期定时采集识别程序所在进程的CPU及内存利用率,其结果如图9所示。可以看出,CPU利用率在0~2%之间波动,呈现周期性变化,这和程序对滑动窗口进行周期性处理的特性相吻合。程序占用约1 025 KB内存,占用率约为0.8%。
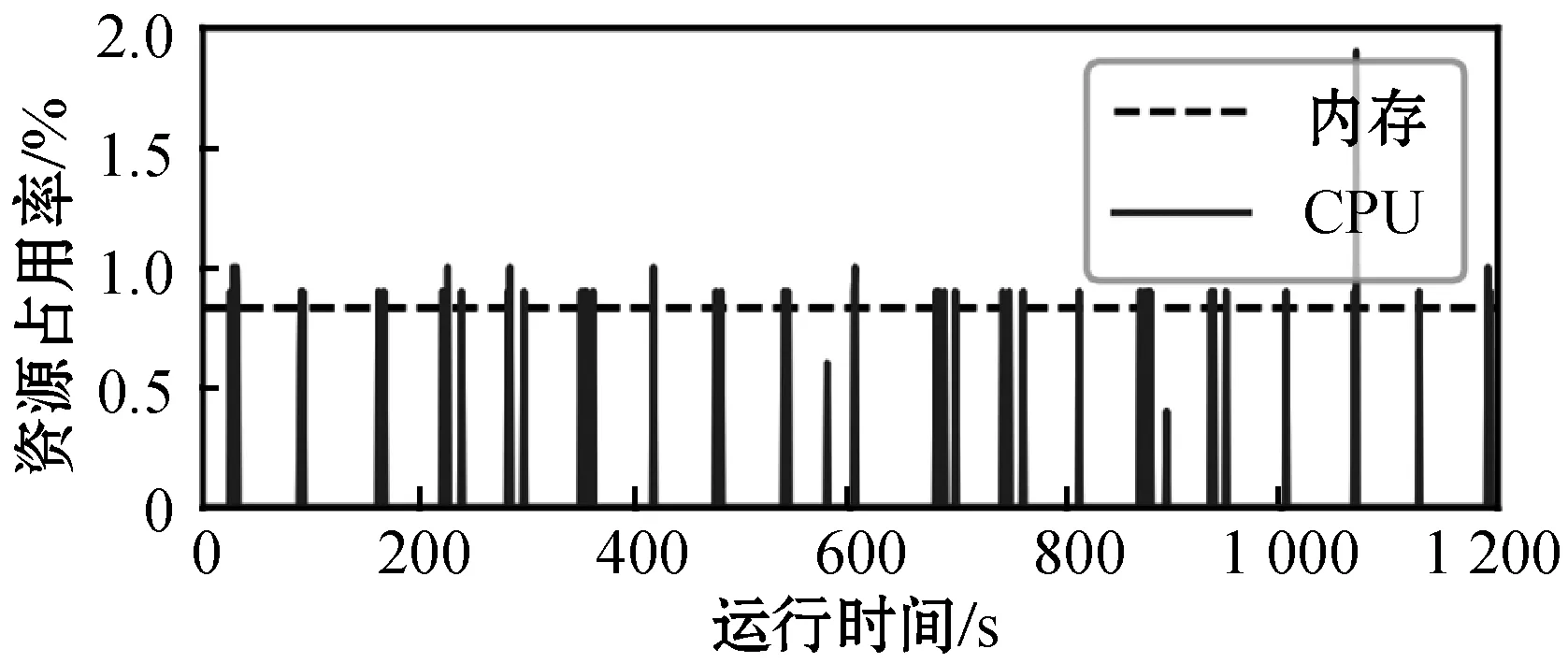
图9 CPU与内存占用率
对于网络设备而言,吞吐量指设备在单位时间内发送的数据量,体现了设备转发报文的能力,是评估设备性能的重要指标。为评估本方法对设备转发性能的影响,设计了一种压力测试实验,该实验中存在两台计算机分别通过以太网连接实验网关,使用网络吞吐量测试工具iperf[12],从一台计算机向另外一台计算机以TCP连接的最大带宽发送数据。在以下三个场景中观察吞吐量的变化:① 识别程序未运行;② 识别程序运行,但环境中未运行目标App;③ 识别程序运行,且环境中存在待识别App周期性启动。
实验结果如图10所示,在场景1和场景2中,设备吞吐量都较为平稳,其均值分别为94.06 Mbit/s和93.96 Mbit/s;在场景3中,设备吞吐量存在小范围波动,其均值为91.64 Mbit/s,较场景1仅略微降低。

图10 系统转发吞吐量
4 结 语
本文针对当前App识别方法运算量较大,难以进行在线识别的问题,提出了一种基于域名访问范围特征的App实时识别方法。该方法的优势一方面在于其处理速度快,可以做到在线识别,避免了离线识别中抓包文件的存储和传输消耗;另一方面,对系统资源占用较小,可以直接在资源受限的嵌入式网关中运行。但本文方法也存在不足之处:(1) 部分App进行大版本升级后,访问的域名集合会出现明显变化,导致识别失败;(2) 同一公司开发的App访问的域名较为相似,易产生误判。这些都是可进一步优化的问题。除了本文方法收集的信息外,用户App使用特征还有很多,如用户年龄段、就职行业与手机平台等,对这些特征的挖掘与分析可作为进一步研究的方向。
