基于电磁旁路分析的芯片聚类研究
2021-07-14刘俊延贾永杰李雄伟
刘俊延 ,贾永杰 ,李雄伟*,张 阳
(1.陆军工程大学石家庄校区 装备模拟训练中心,河北 石家庄 050003;2.中国人民解放军93498部队,河北 石家庄 050003)
0 引言
随着微电子技术的快速发展,集成电路芯片被广泛应用于金融、通信、交通、军事等关键领域并在电子设备与系统中起到核心的作用。但由于芯片供应链的全球化发展以及利益的驱使,全世界各地都充斥着假冒伪劣芯片的踪影[1]。其存在形式可以被简单地划分为:以次充好、以旧充新、以假充真3种情况[2],这些芯片或多或少在硬件层面上与正品芯片存在着一定的差异。一旦这些假冒伪劣芯片在使用时出现安全问题或故障,极有可能带来巨大的经济损失甚至更严重的后果。因此,如何对芯片进行有效检测,以确保其安全性与可靠性具有重大的研究意义。
然而,假冒伪劣芯片与正品芯片的差异通常难以被察觉,在没有“金片”[3]的情况下,很难通过常规手段识别出二者之间的差异。目前,有很多不同的测试方法可以检测芯片中的各种异常情况。检测方法根据问题的性质而有所不同。传统的芯片检测方法主要可以分为两大类:物理检测方法和电气检测方法[4]。物理检测方法中,电子扫描、X射线和红外光谱分析是目前最准确、最可信的检测方法,但是检测设备昂贵,测试时间长;封装分析等开封芯片的检测方法会对芯片造成不可逆的损坏。这些方法不能对大批量的芯片进行逐一检查,多用于抽样检测。电气检测包括参数测试、烧机测试、功能测试等方法,尽管电气检测方法具有非破坏性和时效性等优点,但这些检测工作都依赖于人的规范操作,并且对于复杂的集成电路芯片,在原始厂商测试手册和设备缺失的情况下,该检测方法无法实施。因此,近年来有许多学者提出从旁路信号[5]分析的角度来达到检测芯片的目的。旁路信号包括功率、电磁、红外等侧信道。其中,电磁旁路信号在硬件检测和密钥攻击等领域备受青睐[6-7]。电磁旁路是与芯片瞬态活动有关的非接触式侧信道,它受到技术、布局和布线、代码、内部滤波、封装、温度和老化等众多电路参数影响,对它们进行任何修改都将会导致电磁信号的变化[8]。
目前,基于电磁旁路信号的芯片检测方法面临两大棘手的问题。一方面,假冒芯片的信号差异可能小到被工艺误差或环境噪声所掩盖;另一方面,目前绝大多数的检测方法是在已经获取“金片”的前提下进行的。基于以上分析,本文提出了基于人工神经网络的芯片聚类模型。首先利用人工神经网络,对信息量庞大的原始信号进行有效的除噪、特征提取和降维等操作,人工神经网络利用计算机的高速运算能力,能够实现高效的自主学习、特征提取和模式识别等功能。然后借助自组织映射神经网络把芯片聚类成簇。当芯片被分成不同的组后,就能够采用其他替代技术[9](例如电子扫描、逆向工程等可信度高的检测手段)对每组中单个或多个样本进行仔细检查,以达到确认芯片真实性的最终目的。
1 聚类模型与算法设计
本文提出的芯片聚类模型能够用于无“金片”情况下的芯片检测,其核心思想是利用卷积自动编码对离散的旁路信号进行特征提取,再通过全连接层的自动编码器进一步对特征降维,最后把特征向量输入自组织映射神经网络进行聚类,芯片聚类示意如图1所示。
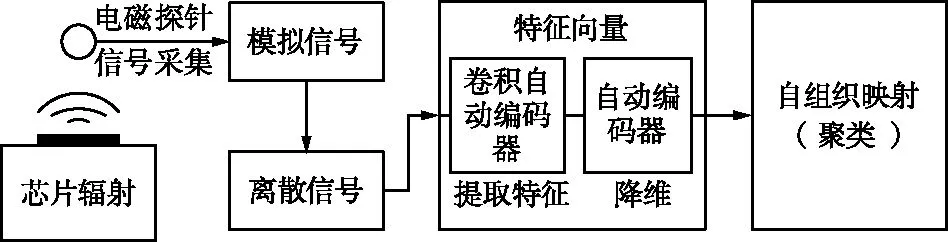
图1 芯片聚类示意
1.1 特征提取
原始的电磁信号采样点多、数据量大,包含了大量的无用和冗余信息,直接对原始信号进行分析会降低结果的准确性,且效率极低。因此需要从原始信号提取出更具有代表性的特征向量集合。自动编码器作为一种无监督的神经网络结构,通常被应用于特征提取、数据降维和去噪等场景[10]。最简单的自动编码器可以由一个输入层、一个隐层和一个输出层构成,通过输入层到输出层的数据重构实现自动学习隐含特征的目的,其中隐层作为输入数据提取出的特征。这种神经网络前半部分为编码器,后半部分为解码器。式(1)描述了自动编码器的训练过程:
(1)
式中,h和g分别为编码器与解码器的映射函数;θ为其内部的训练参数。自动编码器与主成分分析(Principal Components Analysis ,PCA)方法相似,二者都是无监督学习中的代表性方法,但是比PCA性能更强且更为灵活,PCA无法表征非线性的变化,利用神经网络中非线性激活函数,自动编码器能够对更为复杂的数据执行非线性变换,从而学习到比PCA等技术更有意义的数据投影[11]。
由于电磁信号属于时间序列信号,本文使用卷积层、上采样层和池化层代替传统的全连接层,以避免损失信号中的序列信息并且能够解决信号不对齐的问题。本文搭建的卷积自动编码器网络结构如图2所示。

图2 卷积自动编码器结构
由于电磁信号的幅值范围在[-1,1]区间内,为保证输出信号能实现对输入信号的完美重构,最后一层卷积层的激活函数采用tanh函数:
(2)
其余的激活函数则采用relu函数,以防止过拟合并减少梯度消失:
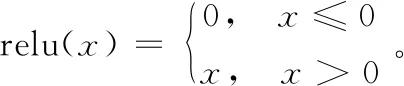
(3)
本文的提取特征被分为2个阶段:第一阶段如图2所示,编码过程使用卷积层和池化层提取原始信号中的特征,解码阶段使用上采样层和卷积层实现编码层的信号重构;第二阶段为全连接层的自动编码器,通过把第一阶段编码层提取的特征展平作为第二阶段的输入,实现进一步的特征提取和降维。中间隐层的数据作为整个卷积自动编码器提取的最终特征:
(4)
通过自动编码器的无监督学习,数据量庞大的原始信号最后在编码层输出为10维的特征向量,由于卷积核的参数共享性,大量节省了特征提取所消耗的时间。由于本文的自动编码器仅用于特征提取,在自动编码器训练完成后,只保留其编码器部分的网络结构和参数,将编码器的输出层与后续用于聚类的自组织映射神经网络输入层拼接起来,形成一个自动化的芯片聚类网络模型。
1.2 自组织映射神经网络
提取到原始信号经过压缩的特征向量后,需要对其进行聚类识别。自组织映射神经网络作为一种无监督竞争型神经网络,其作用是将样本集根据相似度进行聚类,这些类称之为簇。该类神经网络通常只有2层,一层是输入层,一层是竞争层,2层之间神经元双向连接,竞争层之间横向连接,方便获胜神经元对其临近神经元节点的内星权向量进行调整。本文搭建的自组织映射神经网络结构如图3所示。

图3 自组织映射神经网络结构
输入层神经元数为特征向量个数,接收来自编码器的输出数据。竞争层采用50×50的平面型拓扑结构,该平面拓扑结构能够从芯片聚类结果反映出一定的实际物理意义,竞争层神经元越密集,对数据越敏感,但是训练参数也会越多,时间会更长。
每个竞争神经元节点与输入层之间的权值为该节点的内星权向量如图4所示。

图4 内星权向量
向输入层输入经过归一化的特征向量,通过与竞争层所有神经元节点经过归一化后的内星权向量做内积,寻找到获胜的竞争节点:
Y=XW,
(5)
式中,X为输入的10维特征向量;Y为竞争层输出值,取值范围[0,1],可以理解为2个向量之间的夹角余弦值,该值越大说明余弦相似度越高;W为输入层到竞争层之间的权重矩阵(10×(50×50));之所以要进行归一化处理是为了方便计算特征向量与内星权向量相乘正好为二者的夹角余弦值:
(6)
在50个竞争神经元Y=[Y1,Y2,...,Y50]中,最大值对应优胜神经元。通过调整优胜邻域内竞争神经元的内星权向量,能够防止某些始终无法获胜的竞争神经元变为“死神经元”:
Wn+1=Wn+η×(X-Wn),
(7)
式中,W为竞争神经元的内星权向量;η为学习步长,一般而言,学习步长要随着迭代次数上升而逐渐变小,这样能够在一开始迅速捕捉到输入特征的大致结构,随后精细化地调整权重达到学习输入特征的目的。本文的学习率由迭代次数和优胜邻域共同决定:
(8)
式中,n为迭代次数;nm为预设最大迭代次数;a为拓扑结构的边长。
优胜邻域随着迭代次数上升,邻域范围逐渐收缩,使得竞争层中的相邻神经元存在一定的相似性而又不同:
(9)
自组织映射神经网络聚类算法的步骤描述如下:
① 初始化竞争神经元内星权向量;
② 对输入的特征向量和神经网络权向量进行归一化处理;
③ 从打乱的训练集中随机抽取训练样本输入神经网络;
④ 通过竞争层输出值得出获胜的竞争节点,并求得获胜节点的领域和用于更新内星权向量的学习率;
⑤ 对优胜节点邻域内竞争节点的内星权向量进行调整,使之更加接近于特征向量;
⑥ 判断结束条件,未达到结束条件则重复步骤②~⑤;
2 实验设计及结果分析
2.1 实验设计
实验选取3种不同型号但功能特性极其相似的8051系列单片机芯片(STC89C52RC 40I、STC89C52RC 40C和AT89S52)各10块。其中,STC89C52RC 40I和STC89C52RC 40C分别是宏晶公司生产的工业级和商品级芯片;AT89S52是Atmel公司生产的一款低功耗、高性能CMOS 8位微控制器,同上述2款芯片相同,都是8051核;为了保证充足的训练样本,每块芯片采集10条信号。
实验环境搭建如图5所示,采用DH1719A-3稳压电源供电,CRUX-A微动控制器对采集平台进行控制,将LANGER RF-B 3-2型电磁探针采集到的电磁信号和EMV-Technik电压探头采集到的触发信号传入Tektronix数字示波器,并在计算机上对存储的信号进行分析和后续操作。

图5 实验环境
2.2 实验步骤
2.2.1 旁路信号采集
在芯片内部写入特定代码,控制示波器分别采集3种芯片在电压触发信号下降沿至上升沿期间执行MOV A,#DATA指令向外辐射的电磁信号,并将模拟信号转换为离散的数字信号保存。3种不同型号的芯片信号采集情况如图6所示。
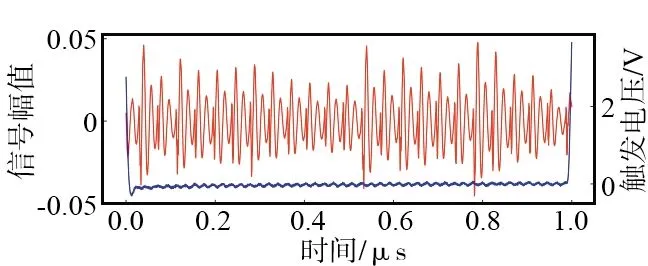
(a) AT89S52信号采集
2.2.2 特征提取
将这3种芯片的原始信号转换为10 000个采样点的离散信号并作为卷积自动编码器的输入,隐层输出的10个数据作为自动编码器学习到的隐含特征。卷积自动编码器训练过程如图7所示。

图7 卷积自动编码器训练过程
当损失函数收敛时,自动编码器训练完成。输出层重构信号与输入信号的皮尔逊相关系数越逼近1,说明重构信号还原度越高,特征提取效果越好。3种芯片的信号重构效果如图8所示。
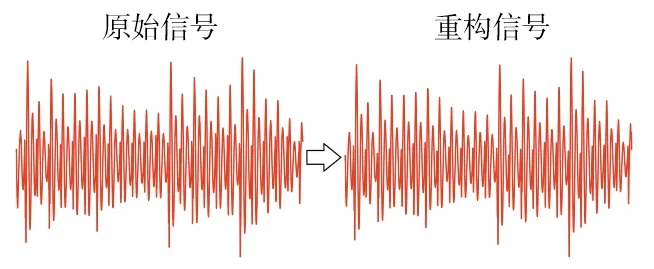
(a) AT89S52信号重构
卷积自动编码器(CAE)与传统的自动编码器(AE)信号重构效果对比结果如表1所示。
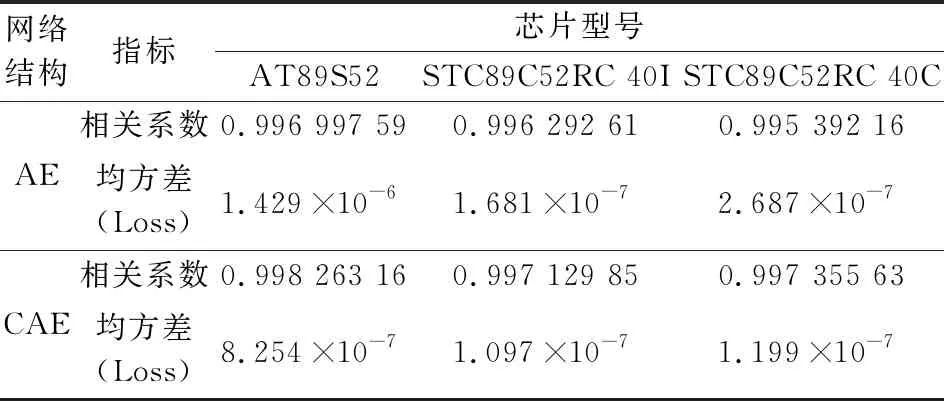
表1 信号重构对比
2.2.3 聚类
自动编码器完成训练后,把输出值作为特征向量输入自组织映射神经网络的输入层,通过自组织映射神经网络的无监督学习,把相似度高的特征向量聚类成不同的簇。实验对3种不同密集程度的竞争层进行研究,聚类结果如图9所示。
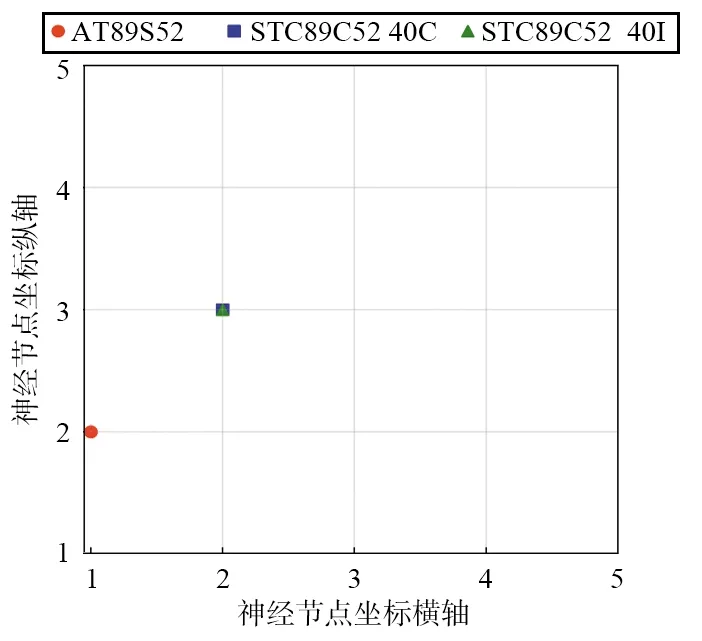
(a) 5×5拓扑结构
聚类结果显示,竞争层的拓扑结构对聚类效果影响较大。当竞争层神经元节点较少时,不易区分出相近的特征向量。采用更加密集的竞争层能够对相似度高的芯片有效区分,但也会使神经网络参数更多,计算量更大。
为验证聚类模型(CAE-SOM)的优越性,本文与其他的组合方法进行对比实验,实验结果如表2所示。

表2 不同方法聚类结果
在实验模拟情况中,假定是不知道每一簇所对应类别的,本文用A、B、C分别表示聚类结果的3簇。分析表中数据可以看出,在没有进行特征提取的方法1中,对原始数据直接采用K-Means方法进行聚类,结果不能对同厂芯片进行有效区分,并且还把AT型的芯片错分成2簇。在方法2中加上PCA的特征提取和降维之后,结果仍然没有太大变化。当在方法3中引进自组织映射网络之后,聚类效果有所改善,但由于特征提取效果不佳,同厂芯片之间的差异无法有效区分。最后方法4采用本文的(CAE+SOM)模型进行聚类,其效果远优于其他方法。
3 结束语
针对无“金片”情况下的芯片检测问题,本文提出了基于电磁旁路信号的芯片聚类模型(CAE-SOM),利用自动编码器自动学习信号数据中的隐含特征,自动编码器训练完成后,只留下编码器结构,把编码器的输出结果输入自组织映射神经网络聚类成簇。一体化的聚类神经网络模型简化了人工操作等繁琐的步骤,经过实验验证,该聚类模型能够在无监督的条件下以更高的精度对芯片完成聚类,其准确率远高于其他方法。为进一步提升模型的准确率,应当提取出更具有表征性的特征,并考虑采用特征融合等手段实现。
