基于特征分析的卷积神经网络烟雾识别
2021-07-14殷亚萍凌毅德朱芳华王晓君
殷亚萍,柴 文,凌毅德,朱芳华,王晓君
(1.河北省胸科医院,河北 石家庄 050000;2.河北省肺病重点实验室,河北 石家庄 050000;3.河北省结核病防治院,河北 石家庄 050000;4.河北省肺癌防治研究中心,河北 石家庄 050000;5.河北科技大学 信息学院,河北 石家庄 050000;6.河北省卫生和计划生育委员会 统计信息中心,河北 石家庄 050000)
0 引言
随着科技的迅速发展,利用视频监控进行火灾检测的技术手段被运用于各种不同需求的消防场所。与基于传感器的火灾检测技术不同,机器视觉检测技术的信息采集主要依赖于视频监控系统,具有较高的稳定性和环境适应性。火灾初期阶段,着火点会产生大量烟雾,因此烟雾检测是火灾检测的首要步骤。
烟雾识别技术中,特征分析是十分重要的步骤。烟雾特征可分为静态特征(例如颜色、纹理等)和动态特征(例如运动方向等)。Li等人[1]采用高斯混合分量对烟雾颜色进行分析实现烟雾自主化检测;Chen等人[2]在RGB颜色空间对烟雾像素在R、G、B3个颜色通道中的分布规律进行分析,得到烟雾检测的决策规则;Prema等人[3]使用二维小波分解和三维体积小波分解对烟雾的纹理进行描述,然后建立纹理特征向量并输入分类器进行烟雾探测与识别;Ko等人[4]基于烟雾向上运动的特性提取HOG特征,并提取定向光流直方图作为烟雾的识别特征。Zhang等人[5]利用加权交叉熵值对深度学习中的损失函数进行优化,建立起一套基于注意机制的烟雾检测模型;Zhong等人[6]利用RGB颜色空间和CNN结合的方式对候选烟雾图像进行分类;张斌等人[7]将烟雾的运动特征与CNN算法进行结合,有效地提高了检测能力。但是由于烟雾本身形状变化速度快,形态不稳定,手工提取特征过程中,人为可操作性较高,很难保证特征的真实性。除此之外,利用深度学习的方法进行烟雾的检测识别,将原始尺寸的烟雾图像作为分类器输入极易造成运算量的增加,拖慢处理速度。
针对以上问题,本文提出一种结合目标区域特征分析与卷积神经网络的检测识别(Characteristic Analysis Net_CNN,CAN_CNN)算法。根据烟雾运动特征获取目标区域,分析该区域运动目标的运动方向和颜色特征,将符合条件的图像作为卷积神经网络的输入。与经典卷积神经网络实验比较后发现,本文算法在准确性与鲁棒性方面表现出一定优越性。
1 基于特征分析的卷积神经网络烟雾检测识别
烟雾属于非刚性运动物体,边界不明显,对其进行特征提取过程中极易产生误差,因此本文提出一种烟雾CAN_CNN算法。首先对视频进行归一化并进行相关滤波处理;然后使用高斯混合模型获取运动目标;其次进行坐标标记,对运动目标做运动方向与颜色特征判断;最后裁剪符合条件的目标块并输入到卷积神经网络中完成分类,通过分类结果结合图像块位置坐标在视频帧中标记出烟雾区域。具体流程如图1所示。
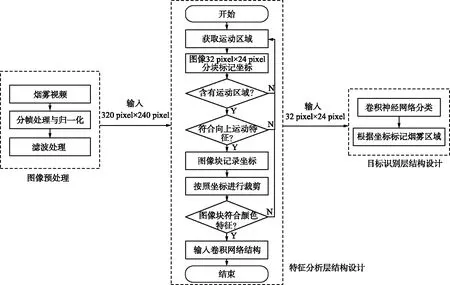
图1 烟雾识别流程
1.1 特征分析层结构设计
1.1.1 疑似烟雾区域获取
烟雾一直处于运动状态,利用这一特性可将疑似烟雾区域提取出来。常用的运动区域检测算法包含三帧差分算法、高斯混合模型和光流法等,由于光流法运算复杂,因此不做考虑。三帧差分算法和高斯混合模型对运动区域的提取效果如图2所示。

(a) 烟雾图像
由图2可以看出,高斯混合模型获取到烟雾运动区域十分完整,三帧差分算法提取的运动区域存在大面积空洞。综合2种算法实验效果,本文选取高斯混合模型进行运动区域的获取。
1.1.2 烟雾运动方向特征
视频中不仅包含烟雾,还包含有其他运动物体,例如云层、飞机等,因此还需要添加其他特征滤除干扰物体。烟雾运动方向为整体向上,基于图像块分析烟雾运动方向,可滤除掉大部分运动干扰。烟雾运动方向示意如图3所示。

图3 烟雾运动方向示意图
烟雾的运动方向可划分为:水平向左(180°)、水平向右(0°)、正上方(90°)、正下方(270°)、左上方(135°)、右上方(45°)、左下方(225°)和右下方(315°)。从0°方向依次进行编号,正左方编号为“5”,左上方编号为“4”。将320 pixel×240 pixel图像按照32 pixel×24 pixel大小进行坐标标记,分别计算间隔帧图像对应位置图像块的中心图像与八邻域图像质心点距离,8组质心距离差距最大的方向即为运动方向。如果经过计算物体在2,3,4方向移动,则满足烟雾向上运动特征,计算过程如图4所示。
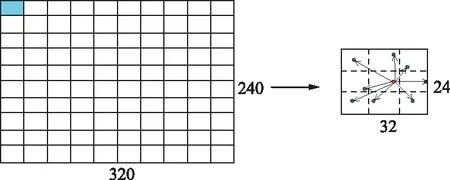
图4 运动方向计算示意
设(xt(n0),yt(n0))为第t帧图像的第n块图像块(n∈[1,100])的中心图像运动区域质心点坐标,(xt(ni),yt(ni)),i=1,2,…,8表示其八邻域运动区域质心坐标。(xt+k(n0),yt+k(n0))表示第t+k帧图像中第n块图像块的中心图像运动区域质心点坐标,(xt+k(ni),yt+k(ni)),i=1,2,…,8表示其八邻域运动区域质心坐标。第t帧与t+k帧图像中图像块的八邻域质心距离n与Li(t+k)可表示为:
(1)
第t帧与t+k帧图像第n块图像块的对应八邻域质心距离差为:
ΔLi=Lt+k(ni)-Lt(ni),i=1,2,…,8,
(2)
则第n块图像块中运动物体的运动方向可表示为:
i=max(ΔLi)。
(3)
1.1.3 烟雾颜色特征
颜色特征算法实现过程相对简单,且更加稳定,因此特征分析层的第2个特征选取烟雾颜色特征。结合文献[2]提出的烟雾颜色特征规律,烟雾颜色分布在R、G、B三通道分布规律一致如图5和图6所示。
从图5和图6可以看出,浅色烟雾和深色烟雾在RGB三分量的值相差较小,且都处于50~150之间。

(a) 浅色烟雾图像

(a) 深色烟雾图像
综上所述,烟雾颜色特征大致符合文献[2]提出的规则,只是由于摄像头,图像环境等因素,根据大量数据实验结果对规则进行了调整。
利用现有数据集进行多次实验,对文献[2]提出的规则稍做修改,如式(4)所示:
,
(4)
式中,α取值范围为15~20;L1=50;L2=150。
1.2 目标识别层设计
1.2.1 结构设计
烟雾的浅层特征并不能完全反应出烟雾本质,还需利用卷积神经网络进行深入的特征挖掘。浅层特征用于滤除掉部分干扰图像,降低卷积神经网络的工作量,利用多层卷积分析烟雾图像深层复杂的特征。网络自动学习过程中,参数通过反向传播机制不断进行优化更新,解决人工定义参数与特征提取的问题[8]。
网络的结构设计直接影响到整体模型的性能,本文网络结构共包含3个卷积层、3个池化层、1个全连接层和1个输出层,结构示意如图7所示。

图7 神经网络结构示意
输入层Input:输入图像为经过特征分析层处理的图像,大小为32 pixel×24 pixel×3的彩色图像,经过归一化后像素区间缩小到[0,1]。
卷积层Conv_1:卷积核的大小直接影响到特征提取的范围,如果卷积核设计过小,无法避免会提取到部分低参考量信息,增加网络计算量的同时降低模型性能,因此本层的卷积核规格为5×5,步长设计为1,卷积核数量为32。选取Relu作为激活函数,特征图谱(Feature Map)是像素信息经过Relu非线性变换的结果,大小为32 pixel×24 pixel×32。
池化层Pool_1:采用MaxPooling,池化核规格为2×2,步长设计为2,数量为32,得到的特征图谱大小为16 pixel×12 pixel×32。
卷积层Conv_2:功能与Conv_1相同。本层卷积核规格为5×5,步长设计为1,数量为64,同样利用Relu函数进行非线性变换,得到的特征图谱大小为16 pixel×12 pixel×64。
池化层Pool_2:采用MaxPooling,池化核大小为2×2,步长为2,个数为64,得到的特征图谱大小为8 pixel×6 pixel×64。
卷积层Conv_3:本层烟雾特征已经缩小,防止卷积核体积过大而错失烟雾特征信息,因此设计本层卷积核规格为3×3,步长设计为1,数量总计128。
池化层Pool_3:采用MaxPooling,池化核设计为2×2,步长距离为2,个数总量为128,得到的特征图谱大小为4 pixel×3 pixel×128。
全连接层F1:设置神经元数量为1 024。使用Relu作为激活函数,选取dropout方式降低过拟合发生可能性。
输出层Output:包含2个神经元,使用Softmax函数,映射出烟雾图像分类情况。
1.2.2 参数设计
网络结构设计包含部分超参数,本文模型设计的超参数数值为深度学习优化选择随机梯度下降(Stochastic Gradient Decent,SGD)法,SGD参数更新计算如式(5)所示:
(5)
动量参数:0.9,学习率初值:0.01,batch size :100,权重初始化方式采用正态分布函数(truncated_normal),损失函数选取交叉熵函数,定义如式(6)所示:

(6)
式中,p(x)为真实值;q(x)为预测值。
2 实验与结果分析
本文烟雾检测识别实验环境主要参数为:Intel i7 5500处理器,CPU 2.40 GHz,拓展库numpy 1.18.2,matplotlib 3.0.3,tensorflow 1.15.0-rc0.,opencv-python 4.2.0.34,scikit-image 0.14.0。
2.1 建立数据集
使用的烟雾数据集主要来自于袁非牛实验室、韩国启明大学CVPR实验室和比尔肯大学实验室,还有部分来源于网络。经过收集、筛选共得到可用的烟雾视频20个,非烟雾视频17个,视频样例如图8所示。烟雾视频包含室外浓烟视频、室外浅色烟雾视频、室内消防栓烟雾视频、红色背景下室外烟雾视频和野外杂草燃烧烟雾视频等。非烟雾视频包含不同背景下不同运动速度的白云视频,其中含有晃动的树枝、飞鸟,以及高耸的白色建筑等干扰。经过对视频的分割并利用CAN_CNN特征分析层对图像的裁剪等手段,得到可用于模型建立的烟雾图像12 500张,非烟雾图像12 900张,共25 400张。深度学习领域为保证建立模型的可靠性与稳定性,将数据集划分为训练集与测试集。为提升测试结果的准确性以及对模型泛化能力的效果反映的真实性,训练集与测试集选取来自不同视频源的图像集,即训练集与测试集的数据分布并不相同。本次实验数据集中训练集比重为7/10,另外3/10不同于训练集的数据作为测试集。
2.2 模型训练
模型的训练过程可以通过对epoch次数与损失率和检测率的对应变化来反映。epoch是指数据集训练的总轮数。烟雾检测识别模型的建立共进行了2 000轮的训练,每100次进行一次输出。图9为准确率变化图,由图9可以看出,随着训练轮数的增加,模型准确率也在不断提升。在epoch为100时,准确率有一个飞跃式的提升;在100~700之间,准确率整体呈上升趋势,之后准确率没有太大波动,一直处于一个较高的水平;最终训练集准确率为97.95%,测试集准确率为96%,说明模型对测试数据也有着较强的拟合能力。图10为损失值变化图,反映了epoch和损失值之间的关系。模型在100轮训练时,损失值陡然直下;在100~1 000轮之间一直呈不断下降趋势,之后趋于平稳;最终训练集的损失值为0.049,测试集的损失值为0.06,表明网络的参数得到了有效优化。

图9 准确率变化

图10 损失值变化
2.3 评价指标
烟雾图像检测识别算法中常用3个参数来衡量模型的性能:检测率(DR)、准确率(AR)和误报率(FAR)[9]。一个性能优良的检测模型需要具备高的检测率与准确率和较低的误报率。相关定义如下:
(7)
(8)
(9)
式中,DR为正样本正确检测的概率;AR为全部样本正确检测的概率;FAR为负样本误检为正样本概率;P为正样本数量;N为负样本数量。
2.4 实验效果
2.4.1 模型效果对比
为了更加直观地反映出本文模型的性能,将CAN_CNN网络与AlexNet[10]、VGG16[11]和DNCNN[12]进行效果对比。传统的烟雾检测算法与基于卷积神经网络的特征提取过程存在差异,所以在此不对传统烟雾检测识别算法进行比较。具体比较结果如表1所示。

表1 不同网络模型效果对比实验
由表1可以看出,在测试集数据中,CAN_CNN网络的AR与DR都高于其他3种网络,在CAR方面低于VGG16与DNCNN,但是稍高于AlexNet。整体来说,本文提出的CAN_CNN网络能够实现对烟雾的有效检测,但是还需提升模型的环境适应性,降低模型的误检率。
2.4.2 算法效果对比
模型输出层的输出格式为包含2个概率数值的一维数组,其中之一代表烟雾图像的概率,另一个代表非烟雾图像的概率。如果烟雾图像的概率大于非烟雾图像概率则将图片标记为烟雾图像,反之标记为非烟雾图像。烟雾区域的标记就是根据图像块的坐标,将判断为烟雾的图像块在视频中进行标注。如图11所示,烟雾视频分别包含不同背景下的深色烟雾和浅色烟雾,非烟雾视频包含流动的云、颜色与烟雾相近的天然雾气、晃动的树枝等干扰物体。由检测结果看出,本文算法针对不同颜色、不同背景下的烟雾都有较好的检测效果,干扰视频中,误检率较低,在抗干扰方面有良好的表现。

(a) 烟雾视频1
3 结束语
针对烟雾边缘模糊、易扩散、特征提取难度高问题,提出了基于特征分析的卷积神经网络烟雾检测识别算法。根据烟雾向上运动的特征和颜色特征建立网络的特征分析层,将图像分割为包含烟雾信息的小尺寸图像块,作为目标识别层的输入数据,降低网络计算数量级,提升运算速度与识别率。烟雾运动方向的确定依靠间隔帧图像对应位置图像块的八邻域质心点距离,8组质心距离差距最大的方向满足整体向上且符合颜色特征则将其保留为烟雾图像块。目标识别层使用卷积神经网络结构提取烟雾图像块的深度特征,利用dropout防止过拟合问题的发生。最后根据图像块的坐标将视频图像中的烟雾标注出来。对烟雾检测识别模型建立过程中的参数选取过程与训练过程以及模型的检测效果进行了展示,并通过与其他经典网络的效果对比,结果表明本文提出的CAN_CNN算法具有较高的检测率,可达98.57%。
