基于高光谱成像技术的红景天品种神经网络模式识别方法
2021-07-14钟玉琴曲明亮
李 涛, 钟玉琴, 曲明亮
(四川大学 华西药学院,四川 成都610041)
红景天为红景天属(Rhodiola)植物,其药用历史悠久,种类繁多,临床应用广泛,为药食同源之品.红景天在全球有90余种,我国红景天属植物资源丰富,有73种2亚种7变种,占全世界红景天资源的85%左右,主要分布于我国西南和西北地区[1].红景天主要以根和根茎入药,主要活性成分为红景天苷、酪醇、没食子酸等,具有抗氧化、抗疲劳和抗缺氧等作用[2-4].但是,由于红景天药材的需求不断增加,红景天野生植物资源逐渐减少以及其植物来源的复杂性,市场上红景天药材的假冒伪劣产品层出不穷.其中,大花红景天和狭叶红景天虽为同属植物,但是临床应用有明显差异,大花红景天有益气活血、通脉平喘的功效[5],而狭叶红景天有清热解毒、消肿的作用[6].而且,现代研究表明,大花红景天和狭叶红景天虽然具有相似的化学成分,如红景天苷、酪醇、没食子酸、咖啡酸、对香豆酸等,但在化学成分含量上存在较大的差异[7].因此,迫切需要建立一种能够快速、有效鉴别大花红景天和狭叶红景天的方法.
高光谱成像技术(hyperspectral imaging technology)是近年来发展迅速的一种结合了成像和光谱技术的无损检测新技术.在高光谱图像中,可以同时提取目标样本的光谱信息和图像信息[8].高光谱成像技术具有光谱分辨率高、信息量更全面、成本低廉、操作简单、准确度高等一系列优点,因此被广泛地应用于植物的品质检测[9-11]和品种鉴别[12-14].本文基于高光谱成像技术结合PLS-DA与神经网络模式识别方法,利用高光谱成像技术提取大花红景天和狭叶红景天的反射光谱信息,经过光谱预处理后分别采用载荷系数法(X-loading weights,X-LW)、连续投影算法(successive projections algorithm,SPA)和竞争自适应重加权算法(competitive adaptive reweight sampling method,CARS)方法对高光谱数据进行降维,建立基于全波长和特征波长的大花红景天和狭叶红景天的偏最小二乘判别分析(partial least squares discriminant analysis,PLS-DA)、概率神经网络(probabilistic neural network,PNN)和广义回归神经网络(generalized regression neural network,GRNN)模式识别模型,实现对大花红景天和狭叶红景天的无损、快速和准确的分类与鉴别,以保障红景天临床用药的安全、有效,并为红景天药材的质量控制、品种鉴别和临床应用奠定基础.
1 材料与方法
1.1 仪器与材料高光谱成像系统包括SisuCHEMA-FX17高光谱成像光谱仪(芬兰SPECIM公司)、光卤素灯、CCD相机、移动平台、控制箱和计算机等.光谱范围为935~1 720 nm,光谱分辨率为2.8 nm.
2018—2019 年的7—8月在四川省阿坝藏族羌族自治州和甘孜藏族自治州采集不同批次的大花红景天和狭叶红景天的药材鲜品(表1),经四川大学华西药学院李涛鉴定为景天科红景天属植物大花红景天Rhodiola crenulata(Hook.f.et Thoms.)H.Ohba和狭叶红景天Rhodiola kirilowii(Regel)Maxim.将大花红景天和狭叶红景天的新鲜根和根茎药材清洗干净,经干燥、粉碎和过80目筛后,再干燥至恒重,备用.

表1 大花红景天和狭叶红景天的样品来源Tab.1 Sample sources of Rhodiola crenulata and Rhodiola kirilowii
1.2 方法
1.2.1 红景天高光谱图像的采集与黑白校正 在完全不透明的黑色箱体中进行红景天高光谱图像采集.为了得到清晰的高光谱图像,在图像采集前先设定初始值,经过反复的调试后,最终确定相机的曝光时间、物镜到样品的距离和移动平台的速度分别为5 ms、20 cm、45 fps.由于受到各波段下光强度不均匀和传感器暗电流的影响,获得的红景天高光谱图像的噪声往往较大,因此,采集反射率接近100%的白色校正板的高光谱图像为白色参考图像,然后盖上镜头盖采集黑色参考图像,计算得到黑白校正的图像.
1.2.2 感兴趣区域(ROI)的选取 采用ENVI 2.0软件中的感兴趣区域(ROI)提取工具,在10批大花红景天和10批狭叶红景天粉末样本的高光谱图像的中央区域分别取大小相近的4个矩形作为实验样本的感兴趣区域,共得到80个感兴趣区域,然后求每个感兴趣区域内所有像素点的平均光谱作为实验样本的光谱反射光谱数据,最后得到一个80×224的数据矩阵(80为红景天高光谱样本数,224为波段数)用于数据分析.
1.2.3 光谱的预处理 多元散射校正(multiple scattering correction,MSC)是一种由Martens等[15]提出的的光谱预处理方法,它不仅可以消除由样品颗粒度、不均匀性带来的散射和噪声,还可以校正漫反射光谱的基线漂移.多元散射校正的过程分别为:1)计算需要校正光谱的平均光谱;2)对每个样本的平均光谱做线性回归;3)计算校正光谱.
1.2.4 特征波长的提取 基于大花红景天和狭叶红景天的全光谱进行建模识别分析,由于数据之间存在共线性和冗余性,将会增加计算量和识别模型的复杂度,影响建模识别分析效果.本实验分别采用载荷系数法(X-LW)、连续投影算法(SPA)、竞争自适应加权法(CARS)提取红景天高光谱特征波长,并采用特征光谱代替全光谱进行建模识别分析,使识别模型的计算量和复杂性降低,从而提高识别模型的预测能力.
采用载荷系数法(X-LW)提取特征波长前首先对高光谱数据进行PLS分析,得到每个隐含变量对应的各波长的载荷系数值,波长对应的载荷系数绝对值越大,代表该波长对识别模型预测效果的影响力越大.因此,可以将某一隐含变量下波长对应的载荷系数的绝对值作为依据进行特征波长的选取[16].本文选择每一个隐含变量下具有最大载荷系数绝对值的波长组成特征提取的变量集.连续投影算法(SPA)是一种通过简单的投影操作使向量空间的共线性最小的前向变量选择算法[17].该方法能从大量的光谱变量中选择含有最低限度冗余信息的变量组,因而,能最大程度的避免光谱信息重叠性的问题,目前已经广泛的应用于光谱特征变量的选择[18].竞争自适应重加权算法(CARS)是一种由李洪东[19]提出的,以适者生存为原则的有效特征波长选择方法.它的原理是以PLS模型回归系数的绝对值作为评价波长的指标,采用自适应再加权采样(ARS)技术筛选回归系数绝对值大的波长,以最小的交叉验证均方根误差(RMSECV)获取最优的变量子集.
1.2.5 化学计量学方法 为了从不同的分类方法中选出最优的判别模型,本实验主要应用了3种分类判别模型,分别是偏最小二乘分析(PLS-DA)、概率神经网络(PNN)、广义回归神经网络(GRNN).
偏最小二乘判别分析(PLS-DA)是一种由PLSR发展而来的多变量统计方法,在光谱数据的判别和分类中有广泛的应用[4].PLS-DA作为一种有监督的分类方法,它可以根据PLSR建立Y(类别变量)与X(光谱特征变量)的回归模型,通过预测值的大小来实现样本的分类识别.在本实验中,定义Y变量为红景天的类别赋值,X变量为光谱的特征变量,采用完全交叉验证建立PLS-DA模型.通过相关系数(R2)、均方根误差(RMSE)参数来评价PLS-DA模型在训练集中的性能,并基于此模型对测试集进行预测.概率神经网络(PNN)是一种以Parzen窗口函数为激活函数的特殊的径向基神经网络[20],它根据概率密度的无参数估计来实行贝叶斯决策从而得到分类结果.这种基于统计原理的神经网络不需要训练样本的连接权值,而是根据模式样本的分布来确定网络的权值,因而,PNN具有收敛速度快和分类能力强的特点,被广泛的应用于模式识别[21].广义回归神经网络(GRNN)是径向基神经网络的一个分支[22],它不仅能够以任意的精度逼近任意的非线性连续函数,而且具有收敛速度快、所需训样本少、网络可调参数少和能够进行全局逼近等优点.在PNN、GRNN中径向基函数的分布密度值(spread)的选取是非常重要的,spread取值会直接影响到判别模型的分类精度[23].当spread过大时,函数拟合越平滑,导致拟合误差较大;过小时,网络性能较差,会出现过适应的现象.因此,对于每个判别模型需要选择合适的spread值.
2 结果与分析
2.1 大花红景天和长鞭红景天的原始光谱特征和光谱的预处理分别计算大花红景天和狭叶红景天的近红外平均光谱数据,其平均光谱曲线如图1(a)所示.由图1(a)可知,2种红景天的平均光谱曲线的波峰、波谷的位置具有一致性,但是具体的反射率值有所不同.对波段进行MSC光谱预处理后的平均反射光谱图如图1(b)所示.对比图1(a)和图1(b)发现,采用MSC方法进行光谱预处理后的曲线不仅在变化趋势上与原始光谱保持了很好的一致性,还增强了光谱的吸收特性,减少了曲线的离散性.
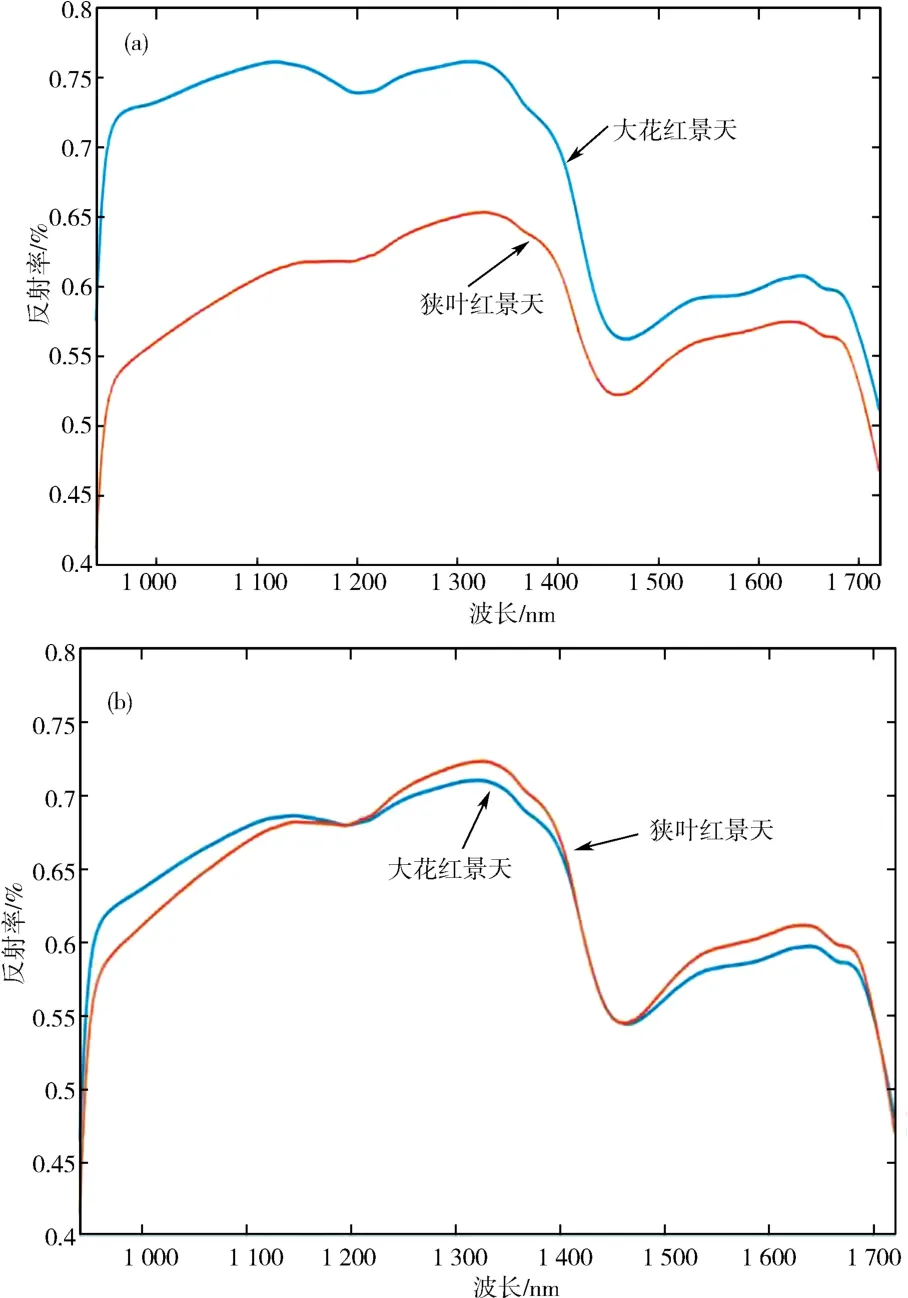
图1 大花红景天和狭叶红景天原始平均光谱(a)和MSC预处理后的光谱曲线(b)Fig.1 Original average spectrum curves of Rhodiola crenulata and Rhodiola kirilowii before(a)and after(b)MSC pretreatment
2.2 特征波长的提取
2.2.1 采用载荷系数法(X-LW)提取特征波长将经过MSC预处理后的大花红景天和狭叶红景天的的反射高光谱数据作为PLS模型的X变量,类别赋值作为Y变量建立PLS-DA模型.建立的PLS-DA模型中,校准集和验证集中X、Y的解释方差随着LVs(隐含变量)个数的增加如图2所示,由图2可知,前10个LVs值对验证集的变量X(图2(a))、Y(图2(b))解释方差分别达到了99.83%和91.70%,可以解释90%以上的样本信息,因此,确定LVs的个数为10.而每个波长对模型分类预测重要性可以根据载荷系数绝对值的大小来判断.因此,本文选择每个LV值对应的载荷系数图中载荷系数绝对值最大的波长作为特征波长,基于X-LW提取的特征波长数为9个,如图3所示.

图2 隐含变量对X变量和Y变量的解释方差贡献Fig.2 Explanatory variance contributions of LVs to X and Y variables

图3 载荷系数法(X-LW)选择的特征波长分布Fig.3 Distribution of optimal wavelengths selected by X-LW
2.2.2 采用连续投影算法(SPA)提取特征波长本研究中设定最大提取波长数为40,运行SPA算法,根据预测均方根误差(RMSE)最小的原则确定提取特征变量的个数为20个.图4(a)是RMSE随选取的有效波长的变化情况,从图4(a)中可以看出,当提取的有效波长数增加到20个时,RMSE值达到最小为0.124 6,因此,采用SPA算法提取了20个特征波长.与全波段相比,基于SPA算法提取的特征波长只占全波段变量数的8.9%(图4(b)).

图4 SPA算法中RMSE值随最佳波长数的变化和特征波长的分布Fig.4 Variation of RMSE with the number of optimal wavelengths and the distribution of optimal wavelengths selected by SPA
2.2.3 采用竞争自适应重加权算法(CARS)提取特征波长 在应用CARS算法进行特征波长选择时,设置用于交叉验证的最大潜在变量(LVs)数为30,蒙特卡罗采样次数为100.采用10折交叉验证计算PLS模型的交叉验证均方根误差(RMSECV),并根据RMCECV最小的原则选出的最优变量的组合.CARS方法进行特征波长选择的过程如图5所示,图5a为变量数随采样次数的变化图,总体来说随着采样次数的增加,变量数减小,但是变量数在前期锐减,后期变得明显缓慢,说明变量的选择是一个前期粗选、后期精选的过程.在图5b中,当采样次数为17时,PLS模型的RMSECV达到最小为0.089,这表明采样次数在1~17过程中在剔除无关的变量,而之后RMSECV增加,说明剔除了重要的光谱信息.图5c是变量选择过程中各波长变量相关系数的变化趋势,每一条线代表一个变量随着采样次数变化的回归系数路径,最长的竖线对应了图5b中采样次数为17时RMSECV的最小值.CARS算法选择的33个特征波长,如图6所示.

图5 CARS算法中特征波长的提取过程Fig.5 Process of CARS wavelength extraction

图6 CARS算法选择的特征波长分布Fig.6 Distribution of optimal wavelengths selected by CARS
综上所述,X-LW、SPA和CARS三种波长选择方法分别提取了9、20、33个特征波长,选择的特征波长如表2所示.
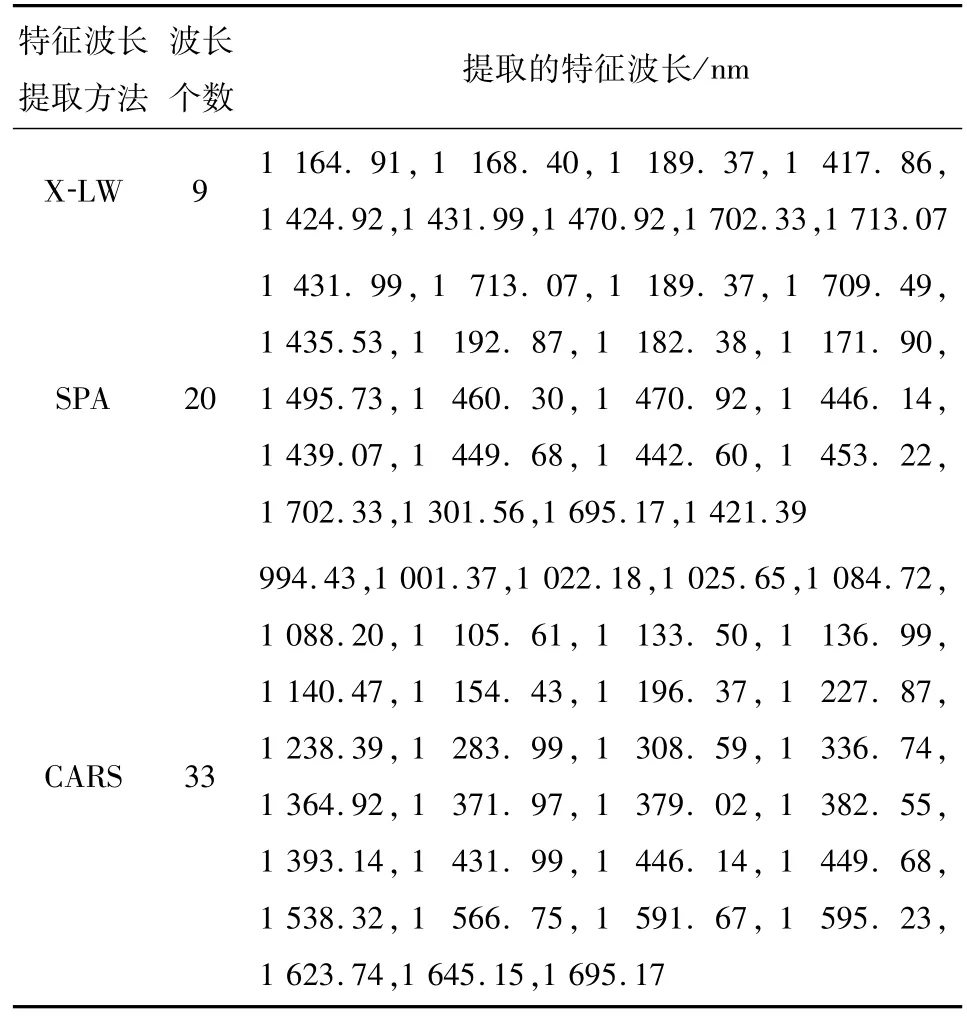
表2 X-LW、SPA和CARS法提取的特征波长Tab.2 The optimal wavelengths selected by X-LW,SPA,and CARS
2.3 建立红景天的分类判别模型在建立红景天分类识别模型前,首先将所有的大花红景天和狭叶红景天样本进行类别赋值,并采用Sample set partitioning based on jointx-ydistances法(SPXY)将经过预处理的红景天样本数据按照3∶1的比例划分为训练集和测试集,训练集和测试集分别包含60个红景天样本和20个红景天样本.在建立PLS-DA模型时,将0.5作为红景天类别判定的阈值,即类别赋值与预测值之差的绝对值小于0.5则判别分类正确,否则错误.神经网络同样采用0.5作为样本分类的阈值.例如,大花红景天的类别赋值向量为[0,1],如果预测类别向量[y1,y2]中y2值大于0.5,y1小于0.5,说明该样本的分类是正确的.样本的赋值和划分结果,如表3所示.

表3 大花红景天和狭叶红景天赋值和训练集、测试集划分Tab.3 Class assignment and division of training sets and testing sets of Rhodiola crenulata and Rhodiola kirilowii
2.3.1 基于全波长和特征波长的偏最小二乘分析(PLS-DA)判别模型 分别基于全波长、X-LW、SPA、CARS方法选择的特征波长,以训练集为输入建立PLS-DA判别模型.LVs的个数是影响PLS-DA性能的关键因素,它是通过完全交叉验证确定的.由于训练集被划分为校准集和验证集,因此,根据校准集相关系数()、验证集相关系数()值最大,校准均方根误差(RMCEC)、验证均方根误差(RMCEV)最小的原则确定LVs的个数.基于全波长和特征波长建立的PLS-DA判别模型的LVs、、、RMSEC和RMSEP值见表4.比较4种判别模型的、RMSEC和RMSEP,可以看出,全波长-PLS-DA判别模型(=0.98、=0.91,RMSEC=0.06,RMSEP=0.15)和CARS-PLS-DA判别模型(=0.96=0.94,RMSEC=0.09,RMSEP=0.12)的校正性能和预测性能明显优于SPA-PLS-DA判别模型=0.92=0.80,RMSEC=0.14,RMSEP=0.23),在3个判别模型中X-LW-PLS-DA的性能最差(=0.79、=0.74,RMSEC=0.23,RMSEP=0.26).

表4 PLS-DA判别模型校准集和验证集的指标值Tab.4 Indices value of the calibration and the validation in PLS-DA model
在PLS-DA判别模型预测结果中,全波长-PLSDA、SPA-PLS-DA、CARS-PLS-DA判别模型均实现了所有训练集和测试集样本的正确分类,而X-LWPLS-DA判别模型错误分类了一个测试集样本,即1个样本的阈值大于0.5.因此,SPA和CARS选择的特征波长可以代替全波长建立PLS-DA模型进行红景天的分类判别.
2.3.2 基于全波长和特征波长的概率神经网络(PNN)判别模型 基于全波长和特征波长建立PNN分类判别模型,在PNN中唯一需要调整的参数就是径向基函数的分布密度,因此,本文以步长0.01,在0.01到0.1区间内采用循环遍历法选择不同的径向基函数进行试验,分别计算训练集和测试集的预测值和真实值的均方误差(MSE),根据MSE最小的原则选择最优的分布密度值,其寻优结果见表5.比较4种判别模型训练集和测试集的MSE值,可以看出,FULL-PNN和CARS-PNN判别模型对训练集和测试集的预测,它们的MSE值均为0,明显优于其他2个模型.而SPA-PNN判别模型虽然对测试集预测的MSE值与X-LW-PNN相同,但是对训练集的预测略优于X-LW-PNN模型.因此,CARS特征波长提取方法可以代替全波长建立PNN模型进行红景天的分类判别.

表5 基于全波长和特征波长的PNN判别模型参数优化Tab.5 Parameter optimization of PNN model based on full wavelengths and optimal wavelengths
2.3.3 基于全波长和特征波长的广义回归神经网络(GRNN)判别模型 广义回归神经网络中径向基函数的分布密度值也是影响模型分类精度的重要参数,因此,同样采用循环遍历法在0.01~0.1区间内选择不同的spread值进行试验,计算均方误差(MSE)值见表6,可知X-LW-PNN、SPA-PNN、CARSPNN这3种判别模型均在spread值为0.01时,训练集和测试集预测值和真实值的MSE最小,而全波长-GRNN在spread值为0.04时MSE值最小.除此之外,基于全波长和特征波长建立的GRNN模型预测性能均劣于校正性能,且3种模型的校准性能和预测性能的排序如下:CARS-GRNN>全波长-GRNN>SPA-GRNN>X-LW-GRNN.

表6 基于全波长和特征波长的GRNN判别模型参数优化Tab.6 Parameter optimization of GRNN model based on full wavelengths and optimal wavelengths
2.3.4 PLS-DA、PNN和GRNN判别模型比较分析 将0.5作为红景天类别判定的阈值,并分别计算基于全波长、X-LW、SPA和CARS方法提取的特征波长建立的PLS-DA、PNN和GRNN识别模型对训练集和测试集的分类准确率,总结见表7.
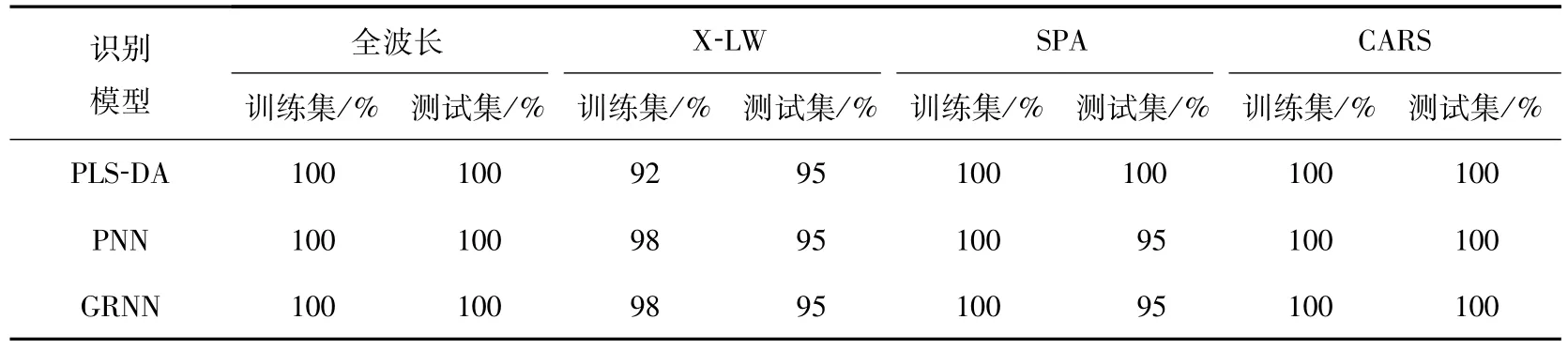
表7 基于全波长和特征波长的PLS-DA、PNN和GRNN模型分类的正确率Tab.7 Classification accuracy of PLS-DA,PNN,and GRNN based on full wavelengths and optimal wavelengths
由表7可知,首先,基于全波长和X-LW、SPA和CARS方法提取的特征波长,建立的PLS-DA、PNN和GRNN识别模型对大花红景天和狭叶红景天的识别率均大于或等于90%,说明可以采用高光谱成像技术结合化学计量学对2种红景天进行品种鉴别.其次,基于全波长和CARS算法提取特征波长的PLS-DA、PNN和GRNN识别模型均能够实现2种红景天所有训练集和测试集样本的正确分类,分类识别准确率达到100%,而其他2种波长提取方法建立的模型对训练集和测试集的分类识别准确率均有一定的下降,且基于SPA提取的特征波长建立的3种识别模型的分类识别准确率均略优于X-LW,因此,3种波长提取方法的分类识别准确率为CARS算法>SPA算法>X-LW.为了减少计算量和精简识别模型,可以采用CARS算法提取的特征波长代替全波长建立判别模型对红景天进行准确的分类与鉴别.
3 结束语
本文基于高光谱成像技术结合PLS-DA与神经网络模式识别方法,建立了大花红景天和狭叶红景天的无损、快速和准确的分类与鉴别方法.采用波长范围为935~1 720 nm的高光谱成像系统进行大花红景天和狭叶红景天的反射光谱采样,在经过MSC方法进行光谱预处理后,分别运用X-LW、SPA和CARS方法提取特征波长简化识别模型,分析比较基于全波长和特征波长建立的PLS-DA、PNN和GRNN识别模型对大花红景天和狭叶红景天分类性能的影响.研究结果表明,CARS算法优于SPA算法和X-LW方法,且基于全波长和CARS提取的特征波长分别建立的PLS-DA、PNN和GRNN识别模型能达到最优的判别效果,6种模型对所有红景天样本的训练集和测试集的分类的正确率均达到100%.因此,建立的基于高光谱成像技术结合PLSDA与神经网络模式识别分析方法,能够实现大花红景天和狭叶红景天的无损、快速和准确的分类与鉴别,为红景天药材的质量控制、品种鉴别和临床应用奠定基础.
