基于火电厂发电量预测的多目标配煤方法*
2021-07-14茅大钧程鹏远陈思勤
胡 涛 茅大钧 程鹏远 陈思勤
(1.上海电力大学自动化工程学院,200090 上海;2.华能国际电力股份有限公司上海石洞口第二电厂,200942 上海)
0 引 言
当前,煤炭供应局面复杂多变,价格变化剧烈,设计煤种难以保质保量,发电企业通常采用掺烧其他煤种的方式来应对[1]。煤质特性的大幅波动对机组的正常运行造成较大影响,发电量计划存在滞后性与不稳定性,对机组掺烧的效益产生直接影响。受国内实施“发控结合”政策的影响,发电企业在掺烧其他煤种的过程中,不仅要考虑如何根据煤种与自身炉型特点合理配煤,还要考虑在耗煤总量的约束下如何提高发电量来满足计划安排,这对电厂而言是一个难题。
基于以上问题,一方面电厂经营管理层需要根据历史数据对未来发电量进行预测,为掺烧煤种提供一定的参考;另一方面需要研究混煤掺配的优选策略,从燃烧成本的角度提出合理的配煤方式。卞彩凤[2]提出一种将极限学习机算法和递归预测相结合的建模方法,根据历史天气和实际发电量数据预测未来短期日发电量情况。黄伟建等[3]使用具有动态平滑系数和参数的动态三次指数平滑法对发电量进行预测,有较好的预测精度。付轩熠等[4]通过建立以掺烧煤成本最低为目标函数与混煤工业成分要求作为约束条件的单目标模型,得到经济性较优的配煤结果。尽管在配煤方面取得较好的成果,但是针对火电厂发电量预测还没有较好的方法。由于发电量预测和单目标配煤模型结合度不高,电厂仍然使用经验法预估计划发电量,最终通过工作人员经验选择配煤比。
本研究利用上海某火电厂实际发电量数据,分组设置为滚动数据,采用Elman神经网络建立发电量预测模型,利用精度评价后的结果和年度耗煤总量得出混煤平均发热量,根据实际混煤数据,以发热量、机组煤种各成分要求构建控煤目标函数并结合经济目标函数建立多目标配煤模型。通过仿真得到较好的配煤结果,具有一定的实用价值。
1 发电量预测模型建立
目前,火力发电仍是我国主要发电来源,分析和预测发电量对电厂制定经营策略具有重要意义。由于影响发电量的因素难以量化分析、国家控煤政策使发电量计划存在不稳定以及滞后性等问题,选择合适的预测方案十分重要。
近年来,人工智能与机器学习成为热点,对预测模型有良好的效果[5]。对于火电厂而言,发电量是基于时间序列的动态数据,为了避免影响因素相关性强且难以选取的问题,引入可以动态学习的Elman神经网络对发电量历史数据进行滚动预测。Elman神经网络由ELMAN提出[6],是一种反馈式网络,与前馈式神经网络不同的是增加了承接层,能够内部反馈、存储和利用过去时刻的输出信息,充分利用历史数据,促进网络适应数据动态信息特征,提高预测精度[7]。Elman神经网络具有非线性逼近能力强、模型结构简单、计算复杂度小等优点,已应用于风电功率[8]、短期电力负荷[9]、港口货物吞吐量[10]等具有动态数据特征的预测模型中,取得了良好的效果。Elman神经网络结构如图1所示。
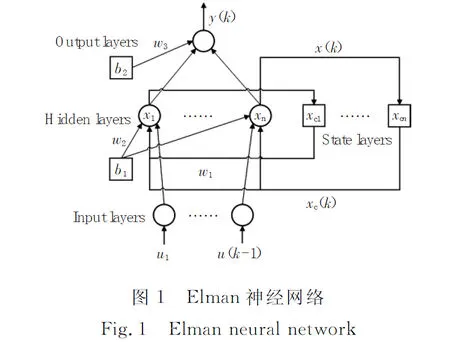
图1 Elman神经网络Fig.1 Elman neural network
Elman神经网络计算公式为:
x(k)=f{w1xc(k)+w2[u(k-1)]}
(1)
xc(k)=αxc(k-1)+x(k-1)
(2)
y(k)=g[w3x(k)]
(3)
式中:k表示时刻;u,x,xc和y分别代表输入层、隐含层、承接层和输出层向量;w1,w2和w3分别代表承接层到隐含层、输入层到隐含层和隐含层到输出层的权值矩阵[11];f(x)和g(x)分别为隐含层和输出层的传递函数,分别采用tansig函数和purelin函数;α代表自反馈因子,α∈[0,1]。
Elman神经网络误差指标函数E(k)为:
(4)
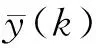
采用均方根误差(root mean squared error,RMSE)和平均绝对百分比误差(mean absolute percentage error,MAPE)对预测性能进行评价,计算公式为:
(5)
(6)
式中:wpi为发电量预测值,kW·h;wri为发电量实际值,kW·h。
2 多目标配煤模型设计
随着国家控煤政策的实施,只追求某一方面最优的单目标配煤模型已无法满足现状需求,火电厂急需一种适应现状的多目标配煤方法。
2.1 优化指标选定
建立配煤模型的前提是选定优化指标,本研究结合电厂实际生产中各变量的平衡点,提出煤炭价格指标、平均发热量指标和煤质约束指标为优化指标。
平均发热量指标可以根据国家对电厂耗煤总控制量和发电量得到,计算公式为[12]:
(7)
式中:Qave为平均入炉发热量,MJ/kg;η为厂用电率,%;wf为年度发电量,108kW·h;hg为供电煤耗,g/(kW·h);mh为年度耗煤总量,104t;105为单位换算系数。由于年发电计划不会及时给出,所以此处wf为年度发电量预测值,计算得出的煤炭平均发热量作为配煤指标之一[13]。
由于优化算法中约束条件会增加求解难度,本研究将煤质约束条件转化为煤质约束指标,主要原理是根据约束条件的违反程度构建煤质约束指标函数。约束条件中涉及的煤质特性参数包括发热量(Qad)、硫分(w(Sad))、灰分(w(Aad))、挥发分(w(Vad))和水分(w(Mad))。具体建立过程如下:
根据电厂锅炉设计标准,配煤模型约束条件可以表示为:
Subject to:si(x)-Ci≤0,Dj-δj≤tj(x)≤Dj+δj
(8)
式中:si(x)和Ci分别表示混煤个体硫分、灰分和水分的预测值和设计值,%;tj(x)和Dj分别表示设计煤种混煤个体发热量、挥发分预测值和最优值;δj表示发热量(MJ/kg)和挥发分(%)容忍值,其中D1-δ1=Qave。
一个个体违反约束条件程度可表示为:
(9)
所以,煤质约束指标为:
(10)
V(x)作为惩罚值会随着混煤煤质的偏离程度而改变目标函数的大小。
2.2 目标函数建立
本研究将影响目标函数的优化指标进行分类,煤炭价格指标影响配煤经济性,平均发热量指标和煤质约束指标影响计划完成性、机组运行安全性和环保性。
电厂对混煤价格十分重视,实现配煤掺烧方案经济效益最大化是一直追求的目标,所以建立的经济目标函数表达式为[14]:
(11)
式中:β为经济系数;Xj为第j种煤的混配比例,%;Pj为第j种煤的价格,元;n为单煤种类数。
为了改善发电量计划滞后性对电厂管理、配煤工作造成的负面影响以及为了积极响应国家控制耗煤总量的政策,采用平均发热量指标反映耗煤量和发电量之间的平衡点,保证混煤发热量接近平均发热量可达到控制年耗煤量的效果;为了使混煤满足设计煤种煤质,采用煤质约束指标保证机组正常运行,当混煤发热量、硫分、灰分、挥发分和水分都在约束范围内时,V(x)=0,目标函数在寻优时更有优势;当超出约束范围内时,V(x)>0,目标函数增大,个体不易留下来。两种指标组合建立控煤目标函数表达式为:
Fc,min=γ(Qp-Qave)+εV(x)
(12)
式中:γ和ε为控煤系数;Qp和Qave分别为混煤发热量的预测值和平均值,MJ/kg。
3 NSGA-Ⅱ算法改进
随着绿色能源的发展,国家对耗煤量的控制越来越严格,燃煤配比优化问题逐渐成为一个复杂的多目标问题且涉及的变量往往是相互制约的。NSGA-Ⅱ算法[15]在解决双目标优化问题时表现较好,可以在各个目标函数之间进行权衡,求得各目标函数中最大或最小的最优解,故本文直接使用目标函数作为NSGA-Ⅱ适应度函数,不断寻优并对算法本身进行改进以应用于配煤模型中,并通过仿真测试其寻优效果。
针对多目标配煤模型,具体的NSGA-Ⅱ算法步骤如下。
步骤1:编码、参数设定以及种群初始化。
由于配煤模型的特殊性,采用实数编码方法,主要考虑三种单煤混配的情况,针对编码的遗传算子只有前六位有效,其中前三位是10种煤库中随机三种单煤编号,后三位是单煤对应的掺烧比例,根据实际情况将变量范围定义为:lmin={1,1,1,10,10,10};lmax={10,10,10,80,80,80},且三种混煤掺烧比例之和为100%。
为了平衡各指标之间的影响,设置了经济系数和控煤系数,通过赋予其合适的数值来调整目标函数的偏好程度,由此可以大大增加算法在寻优过程中的效率和灵活性。实际生产中,锅炉对煤质约束十分严格,因此ε取值要比γ最少大20倍,这样可以使得寻优过程中,不满足约束指标的个体在非支配排序后始终被符合的个体所取代,减少了多目标优化算法中无实际意义解的个数。
在已知目标函数和变量范围的前提下,按照编码规则,生成种群并初始化进化代数。
步骤2:非支配排序和拥挤度计算。
根据建立的目标函数,得出各配煤方案的目标函数值,利用NSGA-Ⅱ算法对个体进行非支配排序分层,并计算每个分层单个个体的拥挤度距离。拥挤度距离公式为:
(13)

步骤3:选择操作。
采用二元锦标赛策略每次从种群中选择两个个体,选择其中最好的一个个体进入下一代,重复操作,直到达到原来的种群规模。
步骤4:交叉和变异操作。
为了增加种群收敛程度及有针对性地更新种群,提出一种求解随约束指标变化的动态交叉概率PCD与变异概率PMD的方法。
(14)
(15)
式中:Pc为普通交叉概率,一般取0.6,最大取0.8;PM为普通变异概率,一般取0.05,最大取0.1。个体违反约束指标程度越大,交叉变异概率越大,使个体朝最优方向趋近。
步骤5:精英策略。
将好的父代种群保留下来与子代种群组合,进行非支配排序和拥挤度计算,共同竞争选择合适的个体成为新一代种群。
步骤6:判断进化代数。
判断进化代数是否大于最大迭代数,如果大于,完成迭代,输出最优解集,选择合适的配煤方案;否则,进行下一次循环。
基于发电量预测的多目标配煤方法流程如图2所示。

图2 总体配煤方法流程Fig.2 Flow chart of overall coal distribution method
4 实例分析
控煤政策要求电厂总耗煤量存在上限值,为了合理经营电厂,发电量预测成为电厂目前较为重视的内容。对上海某火电厂从2014年1月到2020年12月共计84个月度历史发电量数据进行研究,具体数据见表1。

表1 发电量数据Table 1 Data of electricity generation
为了避免单输入单输出模型精度较低对发电量影响因素分析的影响,且为了充分利用数据本身的规律,本研究提出一种可更新的滚动时序模型,将数据进行分组输入,经过对发电量数据进行多次预测试验,形成滚动数据集(见表2)。

表2 滚动数据集Table 2 Rolling data sets
本研究中确定Elman神经网络结构输入层为6个神经元,隐含层为6个神经元,输出层为1个神经元[16]。84个月发电量数据形成78组滚动数据,前66组数据作为训练集,后12组数据作为验证集,对数据进行归一化处理。
对2020年12个月发电量进行预测,并与差分整合移动平均自回归模型ARIMA(autoregressive integrated moving average model)、灰色预测模型GM(grey model)的预测值进行比较,三种算法预测结果及相应的预测误差见图3和图4,混煤煤质误差见表3。

由图3、图4和表3可知,将滚动数据输入Elman神经网络得到的发电量预测结果精度更高,将12个月的预测结果相加可以得到电厂年发电量值。
2019年是实施“发控结合”政策的第一年[17],依照国家规定,上海某火电厂在2020年耗煤总量控制在236.78万t,与上一年有较大差距。本研究根据公式(5)的计算,将耗煤量政策、预测发电量值和配煤平均发热量三者联系起来,既可以保证发控结合,也可以为配煤工作提供一定参考。
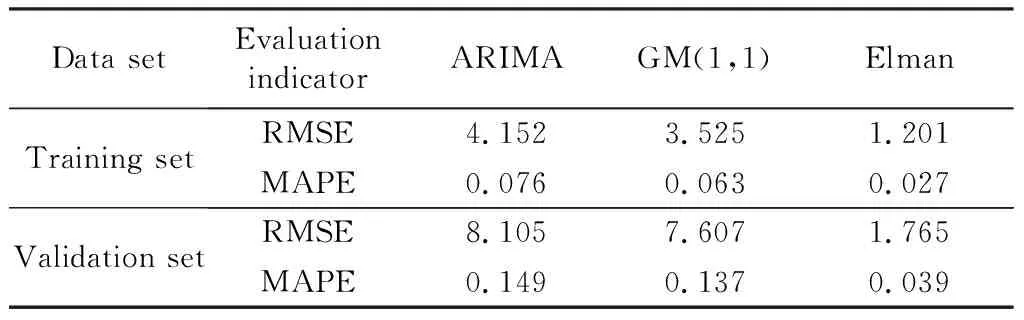
表3 混煤煤质误差Table 3 Error table of mixed coal quality
经过调研计算,电厂用电率5%,供电煤耗290 g/kW·h,年度发电量预测值63.283亿kW·h,可以求出平均发热量为21.55 MJ/kg。理论上只要保证混煤发热量大于平均发热量就可以满足控煤政策,但是混煤研究往往情况复杂,还需考虑其他成分对机组的影响。
对该火电厂锅炉进行动力配煤研究,锅炉设计煤种煤质情况见表4,选取实际12种存煤数据进行混配,结果见表5。

表4 设计煤种煤质Table 4 Design coal type and coal quality
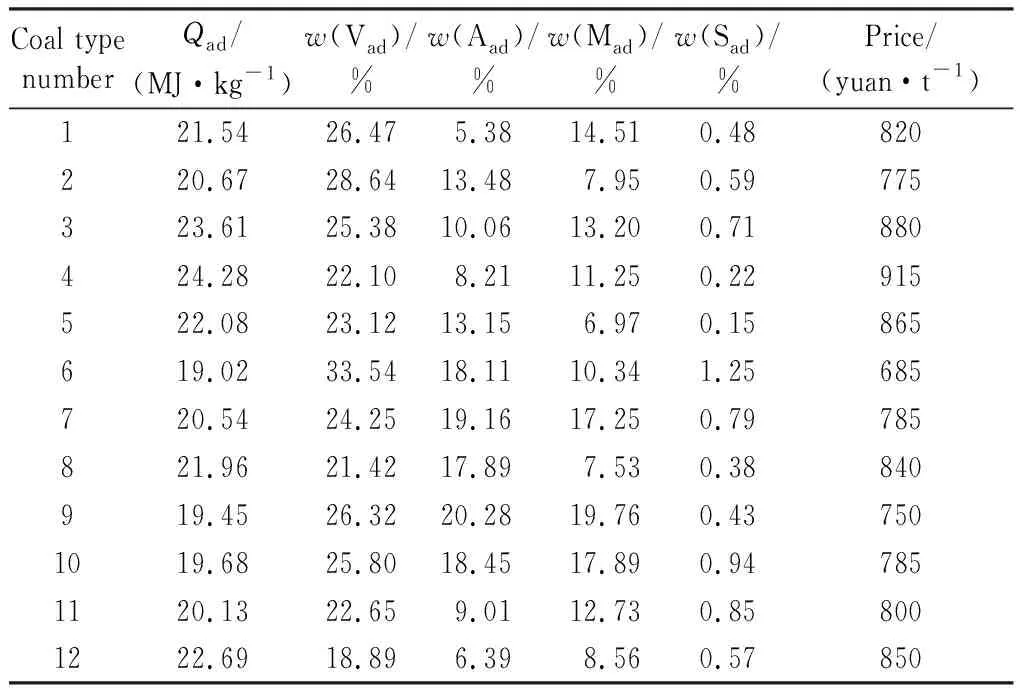
表5 存煤数据库Table 5 Coal inventory database
本研究采用改进的多目标优化配煤模型,追求经济效益与控煤效果的双目标函数最优,在没有特定需求的情况下,赋予同等权重,β和γ分别取0.01和1,为了加强约束反馈,ε取30。种群规模设置为120,迭代次数为200,进行仿真计算后的个体解集分布和进化迭代过程对比如图5与图6所示。

图5 个体解集分布Fig.5 Distribution of individual solution set
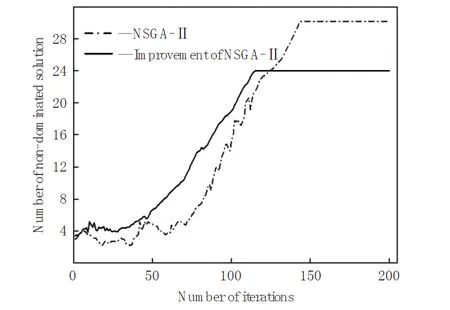
图6 进化迭代过程对比Fig.6 Process comparison of evolutionary iteration
经过改进模型得到的解分布较为均匀,强约束指标缓解了多目标优化算法结果太多难以挑选的问题,部分符合条件的个体见表6。

表6 部分个体解集Table 6 Partial individual solution set
由表6可知,混煤各项指标均满足锅炉本身约束条件,并且混煤发热量值均大于或等于平均发热量,按照模型给出的个体配煤就可实现对年耗煤量的控制。将模型应用于实际配煤过程[18],在年初阶段,煤种丰富且存量充足,污染物排放和设备安全压力小,为追求煤价最低,按照个体2配煤;在年中阶段,为了完成发电量计划,需要提高混煤发热量和发电效率,按照个体3配煤;在年末阶段,发电量指标压力减小,考虑到国家对电厂污染物排放的要求以及脱硫脱硝成本,按照个体4配煤。电厂燃煤情况多变,根据实际情况选择合适的配煤方案[19],对基于发电量预测的多目标配煤模型进行应用性评价,年耗煤量控制在231.23万t,年发电量达到62.891亿kW·h,预测精度较高,真正实现“发控结合”,配煤和脱硫脱硝以及固废处置成本均有所降低,锅炉超温问题得到改善,电厂一年税前利润达到47 903万元。模型为配煤方案提供了多样性和实用价值[20]。
5 结 论
1) 结合历史数据建立基于Elman神经网络的发电量滚动预测模型,将分好的滚动数据输入模型中训练验证,得到较高精度。
2) 根据“发控结合”政策,已知年耗煤量和年发电量数据计算出平均发热量,将其作为多目标优化算法的目标函数,将发电量预测模型和配煤模型联系起来。
3) 将配煤模型约束条件构建为控煤指标并调整算法的交叉和变异概率,使用改进后的NSGA-Ⅱ算法对实际配煤过程进行仿真,得到良好分布的个体,为电厂提供一定的参考意见。
