基于云计算的高校学生学业预警技术研究
2021-07-09姜志鹏张晓明王子俊李心超王嘉伟
姜志鹏,张晓明,王子俊,李心超,王嘉伟
(北京石油化工学院信息工程学院,北京 102617)
学业预警系统作为学生进行自我评估以及诊断的一个平台,能够及时给予学生预警风险提示,从而使学生及时端正学习态度,避免非正常毕业甚至毕业失败的现象发生。而高校人才培养质量在一定程度上与毕业率直接关联。因此,无论是高校还是学生,学业预警研究都得到了广泛重视。Yang等[1]提出了2种基于CNN框架的创新预警方法,称为1-CLIR和3-CLIR,即通过将学生的课程参与信息转化为图像信息来进行预警分析;而Raza Hasan等[2]则根据学生的学业信息、视频学习软件等数据,利用数据挖掘以及机器学习建立了一个基于树模型的监督分类预警模型。这些模型在一定程度上都有效地缓解了学生挂科以及延期毕业的现象,但是由于专业的多样性以及课程的易变性,导致预警模型的准确度降低。魏茜[3]提到了现在学业预警存在的问题,忽视了出现学业预警的根本原因和存在严重的滞后性。而喻铁硕[4]研究了缺乏实际应用、预测模型单一、缺少预警和预测相结合的措施、缺少预测预警对学生个人的影响。金义富[5]建立了新的学业预警系统——两类六级系统及反馈机制。朱东星[6]提出的关联规则在高校学生学业预警中的应用中,通过课程与毕业情况的联系,仅对以后修读这些课程的同学能够起到预警作用。钱红兵[7]提出的技术扩展了预警类别,其中包括失联、学业以及贫困预警。刘博鹏[8]利用学生的行为、个人属性和历史成绩等3方面数据,根据学生未来不同课程动态进行影响因素的选择,利用支持向量机对学生成绩进行预警。野金花等[9]则基于学生日常数据采用距离判别法、Fisher判别法以及贝叶斯判别法建立了预警模型并进行了实验对比。目前高校教务管理系统储存着大量的学生数据,但这些数据没有得到挖掘和利用。同时,随着云计算技术的广泛应用,预警系统不应只停留在传统的教务系统中。
为了解决预警模型的低普适性以及不易上手等问题,笔者从系统实用出发,采用公有云平台完成大规模数据存储和智能计算。将专业教学计划要求与已有数据共同分析来进行成绩预测与毕业预警,将更具有可靠性与普适性。采用LightGBM决策树算法快速完成预警模型的构建。同时,在移动端设计微信小程序让学生随时随地可提交数据和查询结果。
1 学业预警系统设计
实用的学业预警系统既要基于真实可靠的大量学生数据源,又要以学生为中心,充分利用移动互联网技术满足学生管理和应用需求。在预警技术上,学校已有统计方法提供了准确的毕业阈值。而在分类和预测方面,基于机器学习算法构建的模型能够适应学生各类数据分析需要,提供预测和预警功能。该设计思路为预警系统的设计提供了基本框架。
1.1 系统架构设计
学业预警系统架构如图1所示。
用户通过微信扫码启动预警系统,之后将数据上传到云端;数据上传到云端且同步成功之后,预警模型便会对用户数据进行预测,再返回数据到云端。此时,用户便能在系统的结果页面查询自己的预警信息。另外,根据用户留存在云端的信息进行本地再预测分析,随后发送1份预警分析报告至用户邮箱中。
公有云存储服务商提供必要的加密技术,对用户数据进行加密存储,进而保障用户隐私数据安全。数据传输时,公有云存储服务商采取有效的安全防护技术,保障通信通道内的安全。因此,利用公有云进行数据的存储以及传输,其安全性与可靠性得以保障。
1.2 网络信息交互流程设计
网络数据交互流程图如图2所示。
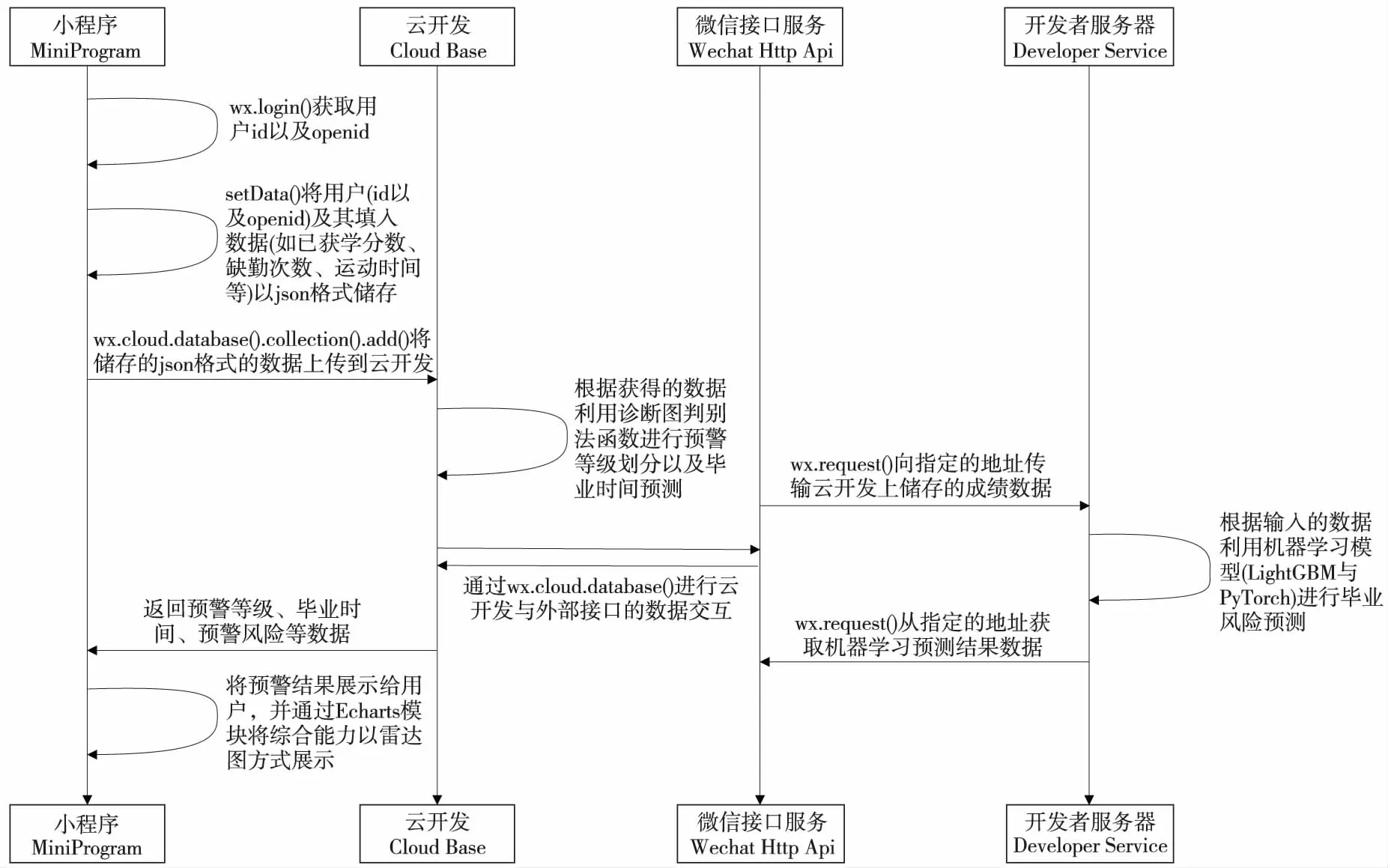
图2 基于云计算环境的网络数据交互图
首先,利用往届毕业生的成绩等信息作为机器学习算法的训练数据。通过移动互联网技术,用户在前端界面输入自己的成绩、入学时长等信息后,系统便可在后端通过网络智能技术(机器学习算法)从云端数据库下载并分析用户的网络数据。最后,将结果通过移动互联网平台反馈给用户。从而解决高校学生对自己目前定位不清楚,导致延期毕业甚至无法毕业的现象。
在前端,由于微信小程序的便捷性以及低依赖性,采用微信小程序作为用户的交互界面。在用户输入完信息并提交之后,便可立即从云数据库中获取用户信息并在后端利用机器学习模型对用户信息进行预警预测。再利用统计学设计出的学业诊断模型来对用户的毕业年限以及预警等级进行预测,方便用户发现自己不足之处并加以改正。
在后期预警等结果完成之后,通过相关系数可以对用户还未学习的课程进行成绩预测,并记入数据库中以便后续使用。
2 预警方案与算法设计
系统的主要功能是进行预警,其预警规则和标准便成为系统实现的关键。为此,采用的解决方案是将统计学与机器学习相结合,作为预警的评判规则。
2.1 基于诊断图模型与机器学习模型的综合设计思路
利用统计学对本专业的大学4年各阶段所需学分以及相关专业教学计划进行研究,并利用Excel软件设计出学业状态诊断模型,如图3所示。
由图3中可以看出,将学业状态进行了6个等级的划分,分别用绿色、蓝色、黄色、橙色、紫色、红色表示,分别对应为无风险、无风险、低风险、中风险、高风险、紧急。并且通过学分与学期2个参数便可快速将用户进行定位,从而预测出用户的毕业时间以及所处预警等级。
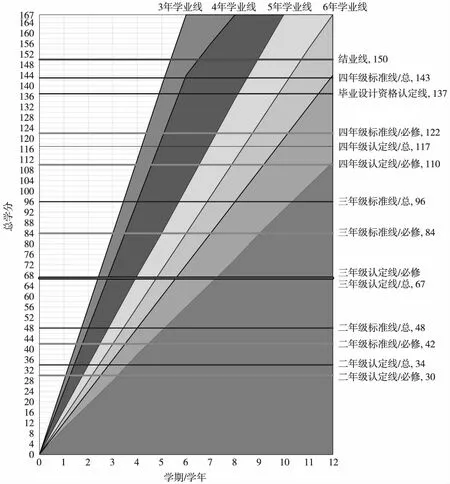
图3 计算机科学与技术专业的学业状态诊断模型
再对该图进行代码化,写成函数并封装起来。将此函数与机器学习的预测结果进行综合判断。最后,将两者预测的结果进行逻辑与操作,如果为真则返回毕业的讯息,其余情况均返回未毕业的讯息。
2.2 基于LightGBM的预警模型优化设计
LightGBM是一个快速、分布式、高性能的基于决策树算法的梯度提升框架,可以快速处理大量数据。LightGBM的参数可大致分为3类,即学习控制参数、核心参数以及IO参数。
LightGBM的调参基本流程包括选择较高的学习率、对决策树基本参数调参和对正则化参数调参。优化的参数如表1所示。

表1 LightGBM优化参数一览
为了使调参流程自动化,采用了网格搜索算法,基于sklearn里的GridSearchCV功能。
完整的搜索步骤如下:
(1)确定max_depth和num_leaves;
(2)确定min_data_in_leaf和max_bin;
(3)确定feature_fraction,bagging_fraction和bagging_freq;
(4)确定lambda_l1和lambda_l2;
(5)确定min_split_gain。
2.3 成绩预测
数据扩充之后进行成绩预测。若需对任意1科成绩进行预测(除第1学期外),需要进行以下处理步骤:
(1)对所有学科进行相关性分析,最重要的是得到每科课之间的相关系数;
(2)提取上学期3门专业课以及1门选修课(或相关课)的相关系数;
(3)归一化处理,求权;
(4)计算预测成绩。
2.4 模型评估指标
为了更加全面且准确的将模型自身的性能反映出来,且基于二分类的机器学习任务,选择了分类任务常用的2个指标作为评估指标,即AUC、混淆矩阵。
2.4.1 AUC
在二元分类问题中,接受者操作特性(ROC或ROC曲线)对应着预测值为阳性的数据中正确的比例。AUC是ROC曲线下的面积,越大越好,1为理想状态。
2.4.2 混淆矩阵
混淆矩阵的测试指标有精准率P、召回率R和综合指标F1。F1兼顾了精准率和召回率的指标,是精准率和召回率的调和平均数。具体公式为:

(1)
3 实验研究
首先完成数据处理,然后进行模型训练和测试,从而获得合理的预测模型。
3.1 数据处理3.1.1 数据增强设计
为了说明基于大数据的高校学生学业预警系统中的有效性,收集了2016届计算机科学与技术专业已毕业学生课程成绩。2016届由3个班级共79人作为样本群体,共提取所有课程的原始成绩记录4898条,数据包含了课程与学生成绩之间的关系。但数据量较少不足以供模型训练,因此在真实数据上进行了扩充处理。具体扩充过程如下:
通过已毕业学生共计79人的所有学科成绩计算得出每科平均分、各科均值μ;输入标准差σ控制分布的幅度,再通过正态分布进行概率计算,得到每个分值出现的概率;最终通过此概率模拟生成新的成绩数据。这样的成绩仍符合正态分布,且更具有实际依据。
3.1.2 数据划分
将数据分为训练集、测试集以及验证集3部分。首先将模拟好的数据集以4∶1的比例进行划分,多数作为训练集,少数作为测试集。并额外模拟2 000组数据作为验证集,最后得到的训练集、测试集、验证集数量分别为8 000份、2 000份、2 000份。
将训练集以及测试集通过numpy的loadtxt函数导入,再将导入的数据通过LightGBM的DataSet方法将数据转换成LGB特征的数据集格式。由于LightGBM支持直接类别特征输入,因此并不需要对数据集进行one-hot编码等操作。通过数据处理之后,数据分为训练集特征集、训练集标签集、测试集特征集和测试集标签集4个部分。
3.2 模型训练
由于GBDT回归树高偏差和简单的特性,参数搜索范围做了初步设置。通过上述步骤,最后得到搜索范围内的最优参数如表2所示。
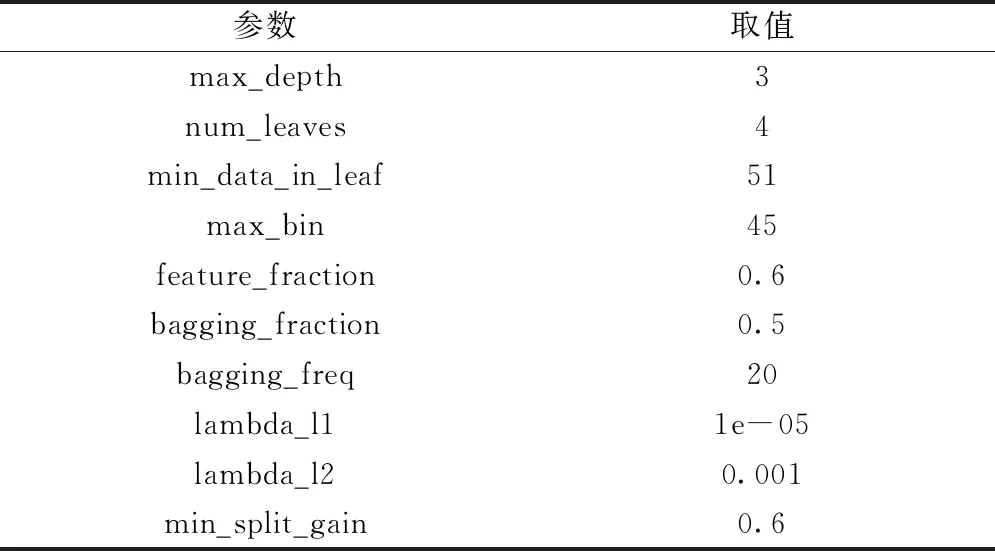
表2 LightGBM局部最优参数
设置好调参所获得的局部最优参数后,对模型进行训练。训练在第416轮中停止并获得最佳的模型准确度,此时Logloss=0.0803,AUC的面积为0.996,都已经接近一个优秀的二分类器的评估标准。基于LightGBM的预测结果混淆矩阵如图4所示。
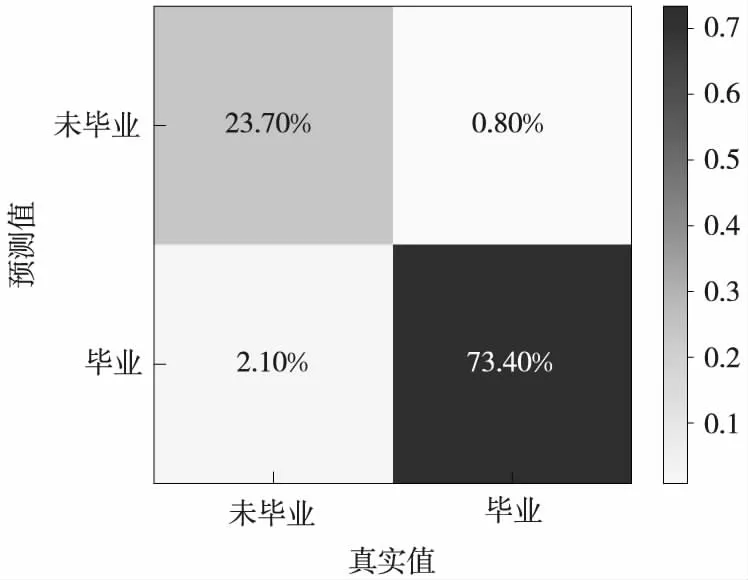
图4 基于LightGBM的预测结果混淆矩阵图
由图4中可以看出,对于毕业与否的正确预测率为97.1%,而仅有2.9%的预测失误概率。表明LightGBM算法对于本实验的特征向量具有更好的分类效果、更快的训练速度和更低的内存占用。
最后得到的模型由1 450棵回归树组成,即该模型是通过1 450棵回归树来进行决策分类。其中,第0、400、800、1 200、1 450棵回归树如图5所示。
图5 决策树计算结果
3.3 模型测试
通过对混淆矩阵的二级指标进行计算,可以得到该模型在测试集上的精准率P为0.934 7,召回率R为0.946 9,F1=0.940 8,都接近1,即该模型在测试集上表现不错。且可以直观地在验证集的混淆矩阵上看出,该模型的预测准确率较好。
而模型在测试集上的Logloss为0.164 922,已经控制在合理范围之内。且AUC为0.983 88,已经接近于1,因此该模型在此数据类别上是一个较好的分类器,可以用于学业预警。
3.4 特征重要性分析
将LightGBM与shap进行结合,从而使模型可解释化,其特征重要性柱状图如图6所示。从图6中可以看出,第59号特征(毕业设计)以及第0号特征(高等数学上)对能否毕业的影响因素最大,于是对第59号特征以及第0号特征进行了关联性分析,得到的结果如图7所示。从图7中可以看出,这2个特征是正相关的,因此也可以得出数学基础与毕业设计的得分也存在一定的关联的结论,即数学基础好的人在毕业设计得分上也应当能取得较为不错的成绩。

图6 特征重要性柱状图

图7 第59号特征与第0号特征关系图
4 结论
该系统首次将机器学习与小程序云平台相结合,其安全性高且易于使用。在预测模型构建上,将机器学习与统计学一同用于决策模型设计,使预测算法更加准确、可靠。通过模型验证得知,毕业与否和部分课程的相关性极大,本次研究也反映出高校教务人员应当对某些特定的课程给予额外的关注,从而提升高校毕业率。所设计的联合决策模型对于测试数据的预测准确率可达97.1%,给未来的学业预警系统的进一步设计指明了一条途径;同时,还可将其推广应用至各专业的学业预警以及学生的个性化管理等领域。
