一种用于行人再辨识的批次分块遮挡网络
2021-07-08张灿龙常松雨李志欣王智文
张灿龙,常松雨,李志欣,王智文
1(广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林 541004)2(广西科技大学 计算机科学与通信工程学院,广西 柳州 545006)
1 引 言
行人再辨识旨在对不同监控场景中的行人进行身份再认,可广泛应用于智能安防、人机交互、相册聚类等领域.受行人图像分辨率变化大、拍摄角度不统一、光照条件差、行人姿态变化大等因素的影响,行人再识别仍然是一项极具挑战性任务.
近年来,基于深度学习的行人再识别[1-12]被广泛关注.人体是高度结构化的,因此通过对人体样本对的相应部件和整体姿态的比较[5-8],能有效提高身份识别的准确率.而利用注意力机制[9,10]来捕获关键部位,则能提高人体部件的定位精度.通过度量学习[10-12]则可在同等的部件定位和姿态估计条件下进一步提高行人分类准确度.以上基于部件定位和姿态估计的行人再辨识方法能获得较高的识别率,但其需要额外的姿态估计和语义信息,从而大大增加了问题复杂度.
也有研究使用分割的方式[1]处理行人部件匹配问题,它们将输入图像的卷积特征映射图从上到下分割成固定数量的水平条带,然后从这些条带中聚合特征,来提高特征提取的性能.然而,将多个分支的特征向量聚集在一起通常会导致复杂的网络结构.为此,本文提出批次分块遮挡网络(BPNet)来改进这些问题.BPNet是一个由全局分支和特征遮挡分支组成的网络,其中全局分支用于对全局特征进行学习和编码,特征遮挡分支是一个具有特征遮挡功能的双分支结构,用于对局部细节特征进行学习和编码.所设计的批处理分块遮挡模块与现有的遮挡模块不同之处在于:批处理分块遮挡模块中批处理是训练过程中参与单一损失计算的一组图像,遮挡是指在单次迭代中为一批图像删除相同的块,加强对局部区域的注意特征学习.
分块遮挡是具有分块特性的正则化方法,它使遮挡结构具有分区的功能,从而形成遮挡子分散,而总遮挡面积不变的特点,增强了对差异较大的场景训练的鲁棒性.另一方面,有规律的遮挡提高了网络结构的精确度,如果采用将头部和脚部特征分别存储的随机性删除特征方式[2],则有可能会使网络因找不到对应的语义而无法完成局部特征学习.
2 批次分块遮挡网络
所提出的批次分块遮挡网络如图1所示,由主干网络、全局分支、批次分块遮挡分支组成.
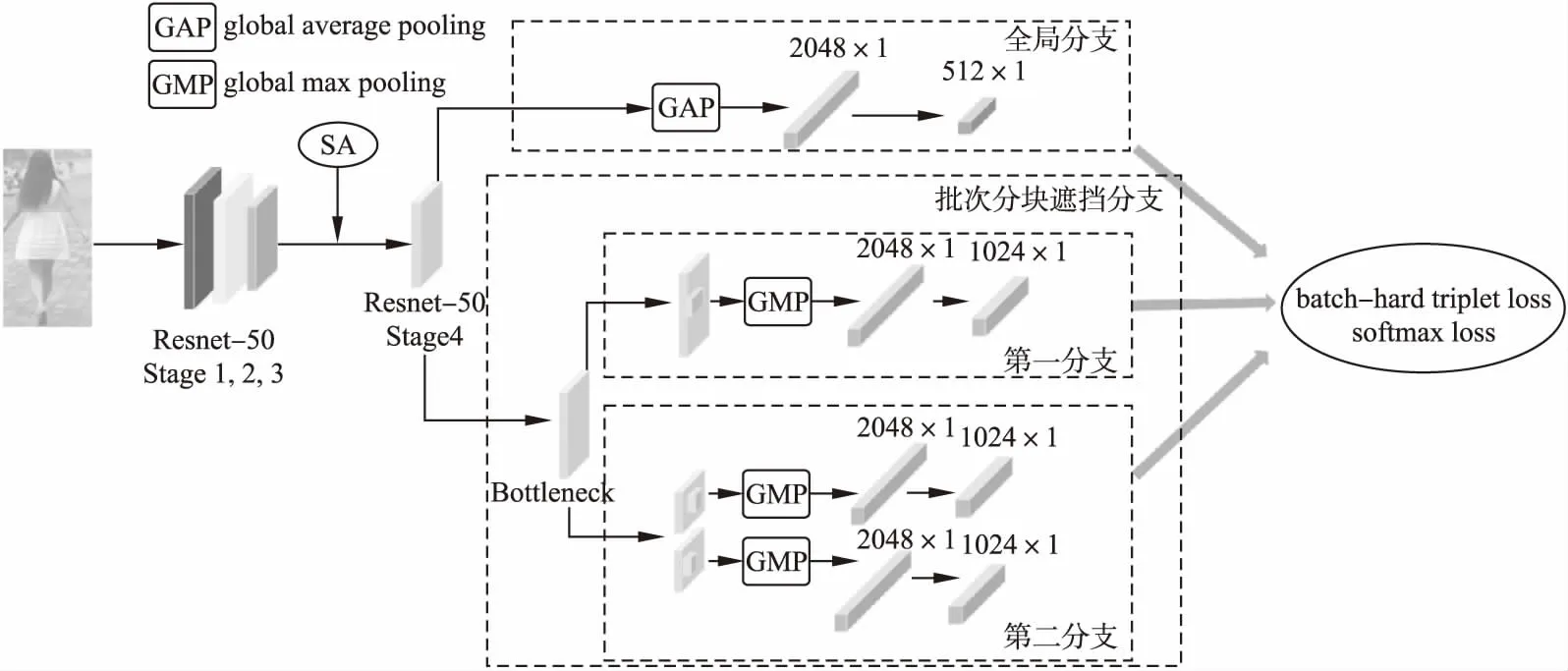
图1 批次分块遮挡网络结构Fig.1 Batch part-mask network
2.1 主干网络
首先用ResNet-50网络的前4个卷积层作为主干网络来提取尽可能多的图像特征.在经过这4个卷积层之前,首先经过一个步长为2的7×7卷积和一个池化层,使得输出图像尺寸仅为输入图像尺寸的1/4,这种方法可以大大减小计算量,使用7×7这样的大卷积可以扩大滤波的视野,避免模型在刚提取图像特征时就陷入了局部细节而无法关注全局特征.然后依次经过4个由相同的残差模块不断叠加而组成的卷积层.
为了与re-ID网络进行对照,本文在不改变ResNet结构的基础上对主干ResNet-50网络做了轻微的修改,在第4个卷积层之前没有使用下采样操作.故得到的特征图大小不变,是一个尺寸为2048×24×8的特征图.与ResNet网络最大的不同之处在于本网络将res_conv4_1块之后的后续部分划分为3个独立的分支,共享与原始ResNet-50类似的体系结构.
2.2 自我关注注意力模块
在第3卷积层和第4卷积层之间添加了自我关注注意力模块(SA attention)[14]调整非局部模型,使批次分块遮挡网络在训练过程中高效且广泛的分离空间区域关系,网络结构如图2所示.

图2 自我关注注意力模块Fig.2 Self-attention module
第3卷积层输出图像X的特征首先被转换为2个特征空间f,g以计算注意力,其中f(x)=Wfx,g(x)=Wgx.
(1)
sij=f(xi)Tg(xj)
(2)
βj,i表示在合成第j个区域时模型参与第i个位置的程度.这里,C是通道的数量,N是来自先前隐藏层的特征的特征位置的数量.注意层的输出是O=(O1,O2,…,Oj,…,ON)∈RC×N.
(3)
此外,我们还将注意力层的输出乘以比例参数,然后加回输入要素图.因此,最终输出为
yi=γoi+xi
(4)
其中γ是可学习的标量,并将其初始化为0.引入可学习的γ可使网络首先依赖于局部的邻域中的线索,然后逐渐学习为非局部证据分配更多权重.
2.3 全局分支
在这个主干网络上半部分添加了一个全局分支,它和ResNet的前一个卷积层合并成ResNet-50主干网络.对于全局分支,首先将输入的特征图转化为2048维的特征向量.而后通过1×1的卷积层、一个批处理归一化层、一个ReLU层将特征向量降低为512维.
全局分支使用的是与ResNet-50网络相同的全局平均池化(Global Average Pooling,GAP),此外,全局分支通常被用在多分支网络体系结构中[13],来提供全局特征表示,监督对特征删除分支的训练,并将特征删除分支应用于学习良好的特征映射.
2.4 批次分块遮挡分支
批次分块遮挡分支由两个包含不同擦除模块的分支组成,设单批输入图像经主干网络计算得到的特征张量为T.第1分支中的批量擦除层会随机擦除张量T中的同一区域,将擦除区域内所有位置的值都归为0.第2分支则会先将输入的特征图均分成上下两块,然后在每一块中随机地遮挡一小块,即将遮挡区域内的所有值设为0.设在特征图T上应用第1分支和第2分支的擦除处理后得到的特征张量分别为T′和T″.然后利用全局最大池化得到2048维的特征向量,最后利用三重态损失和softmax损失将特征向量的维度从2048降到1024.
批次分块遮挡分支的目的是学习多个关注的特征区域,而不是只关注主要的识别区域.擦除区域的高度和宽度因任务而异,一般来讲,擦除区域应该足够大,且能够覆盖输入特征图的语义部分.DropBlock[2]提出在输入的图片上随机擦除一大块区域可能会在训练的初始阶段对网络学习造成伤害.所以本文采用一种预训练方式,该方法最初将擦除区域设置的很小,然后逐步增加擦除区域以稳定训练过程.
与全局分支不同,批次分块遮挡分支中使用的是全局最大池化(Global Max Pooling,GMP),因为GMP鼓励网络在最具描述性的部分被遮挡后,能识别出相对较弱的特征.通常强特征容易被选择,导致弱特征很难与其他低值区分开,当强特征被删除时,GMP可以促使网络增强弱特征.在BPNet中,不需要在全局网络分支的监督下改变擦除区域,在训练的初始阶段,当特征擦除分支不能很好的学习时,全局分支能帮助训练.
同样值得注意的是ResNet瓶颈块,它在特征图上应用了一组卷积层,若不存在此瓶颈块,全局平均池化层和全局最大池化层将同时作用于T,使得网络难以收敛.
2.5 多任务学习
批次分块遮挡网络中的3个分支用来学习不同的性能表示信息.全局分支具有更大的接收域,全局平均池化从行人图像中捕获整体但粗糙的特征,而由第1分支和第2分支在遮挡模块的作用下,全局最大池化学习到局部但精细的特征.本批次分块遮挡网络过程中结合多任务学习联合训练.
2.5.1 Softmax损失函数
输入的特征图在进入到批次分块遮挡分支后,我们采用 Softmax分类损失训练该分类识别网络.
(5)
其中,B表示小批次训练样本数量,表示样本Xi经过Softmax层计算的样本属于真实类别yi的预测概率.
2.5.2 硬三重态损失函数
我们使用批量软硬边三重损失来避免边值参数.
(6)
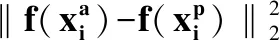
2.5.3 多任务学习
多任务学习(Multi-task learning,MTL)在计算机视觉和图像识别等领域取得了很大的成功,MTL通过共享多个人物之间的关联信息来提升模型效果.本文将多任务学习应用于所提出的BPNet网络结构中,有效的提高了计算性能.
损失函数:本文采用了软边批处理硬三重态损失和Softmax损失这几种常用于各种深度学习的损失函数,总的训练损失为它们在全局分支和特征擦除分支上的总和.所以得出以下公式(其中LG表示全局分支上的损失,L1和L2分别代表特征删除分支上第1分支和第2分支的损失):
L=λ1LG+λ2L1+λ3L2
λ1+λ2+λ3=1
(7)
其中,λ1,λ2和λ3分别为控制全局分支,第1分支和第2分支的权重.根据实验权重自适应得到.
3 实 验
本节在标准的行人再辨识数据集上对提出的具有不同度量学习损失函数的BPNet网络进行了测试.并将BPNet和经典的PCB,PCB+RPP,BDB等网络进行了对比和分析.
3.1 数据集
本文的测试工作主要在两个常用的数据集上:Market-1501[15]和DukeMTMC-reID[16].Market-1501和DukeMTMC-reID 是两个大规模的行人再识别领域通用的数据集.Market-1501数据集包含从6个摄像机视点观察到的1501个身份,包含751人的12936幅由DPM[17]检测到的训练图像和750人的19732幅测试图像.DukeMTMC-reID数据集包含702人的16522幅训练图像,2228幅查询图像,702人的17661测试图像,它们共对应1404个不同的人.训练数据集中的所有图像统一裁剪为384×128,并将完成裁剪后的图像顺序打乱.测试集中的图像被调整为384×128,并且只进行了标准化.
3.2 训练
本网络使用2个相同的GTX-1080Ti GPUs进行分批训练,批处理大小为64.每个身份在一个批处理中包含4个实例图像,因此每个批处理有16个身份.主干网络ResNet-50是从ImageNet[18]预训练模型初始化的.网络使用边缘硬三重态损失来避免边值参数.在训练过程中50轮到200轮学习速率为1e-3,200轮后衰减至1e-4,300轮后衰减至1e-5,整个训练过程包括400轮,实验代码基于Python3.6与Pytorch 0.4编写.
3.2.1 模型和计算复杂度的比较
表1给出了3种方法的模型计算复杂度和测试速度的比较,这些方法在同一个实验环境下进行,经过对比可以看出本文的批次分块遮挡网络在参数数量、计算复杂度和训练速度方面均优于其他方法.

表1 在Market-1501上模型计算复杂度和测试速度的数据对比Table 1 Comparison of model computation complexity and testing speed on Market-1501 dataset
3.2.2 分块数量的不同对性能影响的比较
主干网络的前几层对输入的图片进行了卷积和下采样,批次分块遮挡网络对输入特征图的遮挡在网络的第4卷积层之后,因为更深处的遮挡不容易丢失过多的特征信息.批次分块遮挡网络的前3层特征图可视化结果如图3所示.

图3 ResNet-50前3层卷积层可视化Fig.3 Visualization of ResNet-50 stage1,2,3
实验中采用新的分割方法进一步对训练图像和图像图库进行分割,并选择具有挑战性的查询图像进行评价.在训练期间,输入图像的大小被调整到384×128,然后通过随机水平翻转和归一化进行扩充.在批次分块遮挡模块中设置的擦除高度比为0.3,擦除宽度比为1.0.在所有的行人再辨识数据集中使用相同的设置.
直观地说,遮挡模块数量决定了零件特性的粒度,当图像的分块数量为1时,遮挡模块学习特征是全局的.当图像的分块数量开始增加时,提高了检索的准确性,然而,本文在Market-1501和DukeMTMC-reid上进行了实验,结果如图4所示,准确性并不总是随着图像的分块数量的增加而增加.当图像的分块数量增加到4以上时,无论是rank-1还是mAP都开始表现出轻微的下降.过度增加图像的分块数量实际上损害了部分特征的鉴别能力,故在实际应用中,采用part=2,batch=64的训练方式.
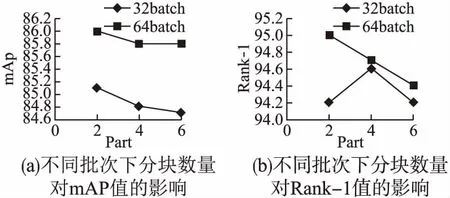
图4 不同分块数量在Market-1501上的对比Fig.4 Comparison of the number of different blocks on Market-1501
本网络中双分支结构的优势在于它既可以学习最显著的外观线索,又学习细粒度的鉴别特征,同时全局分支监督对特征删除分支的训练,使得特征删除分支应用于一个学习良好的特征映射,从而进一步提高性能,两分支相互加强,对优化网络结构都必不可少.
特征删除分支包括第1分支和第2分支,两分支的相同点在于都是通过应用批处理在特征图T上的Part-mask层,提供批量擦除的特征图T′和T″.不同点在于输入两分支的图片,第1分支在整个特征图上按批次进行随机遮挡,而输入第2分支的图片首先被水平均匀分割成上下两块,然后在每块中进行随机遮挡.本文在Market-1501数据集上进行了多次实验分析BPNet网络不同的组成部分对实验结果的影响.每个分支对实验性能的影响对比如表2所示,其中,Baseline指的是Global Branch,Part 1 branch指的是第1分支,Baseline+Part 1 branch指的是Global Branch+第1分支,BPNet指的是Baseline+第1分支+第2分支.由实验结果可以看出,将特征图水平均匀分割成大小相等的两块并在每一块单独遮挡的方法有效的提高了网络的识别精度.
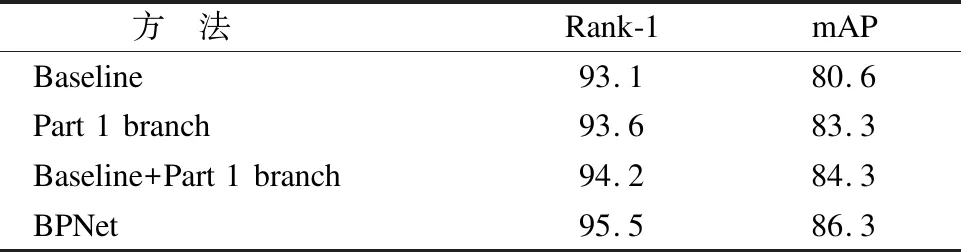
表2 全局分支和特征删除分支在Market-1501上的数据对比Table 2 Global branches and feature deletion branches in comparison of data on Market-1501
Dropout[19]随机擦除输入张量的值,是一种广泛使用的防止过拟合的正则化技术.SpatialDropout[20]随机地将输入张量的整个通道归零,归零的通道是随机分配的.批次Dropout意味着在同一个批次内选择随机空间位置,并将这些位置中删除所有输入特性[22].批次Dropout和批次Part-mask的区别在于批处理时,Part-mask将一块大的连续区域归零,Dropout归零一个个孤立的特征.在Market-1501数据集上Part-mask与其他擦除方法的比较如表3所示.

表3 不同擦除模块在Market-1501上的数据对比Table 3 Different dropout modules in comparison of data on Market-1501
Part-mask意思是,对于一批连续输入的张量,每个张量随机擦除一块连续的区域[22,23],批次分块遮挡和分块遮挡的区别在于批次分块遮挡对于同一批输入的每一个输入张量都作用于同一区域,而分块遮挡作用于不同的区域.本文提出的批次分块遮挡的可视化结果如图5所示.

图5 第1分支和第2分支的比较Fig.5 Comparison of part 1 branch and Part 2 branch
3.2.3 自适应权重对性能影响的比较
本文做了多个实验来测试不同权重对损失函数的影响,实现结果如表4所示,可以看出,当权重系数自适应时性能明显较高.

表4 不同权重对损失函数在Market-1501上的影响对比Table 4 Different weights on the loss function at comparison of data on Market-1501
3.3 与现有方法的对比
在本小节中,在两个广泛使用的公开行人再辨识数据集上,包括Market-1501,DukeMTMC数据集,将本文提出的方法与现有的行人再辨识方法进行对比.对于每一个待查询图像,将其与所有查询库中的图像进行对比,然后按欧氏距离进行降序排列,并计算积累匹配特性曲线(即CMC).本文把第一匹配率(即Rank-1)精度和平均率均值(即mAP)作为评价指标.与查询图像具有相同身份和相同ID的结果不计算在内.值得注意的是,本文所有实验是在单张图像查询设置中进行的,没有重新排序.如表5所示,从表中可以观察到以下结果:

表5 与现有的行人再辨识方法的效果对比Table 5 Comparison with existing re-id methods
1)相比于传统手工特征,大部分行人再辨识方法都是基于深度学习的方法,这类方法的识别性能有大幅度的提升,这也证明了深度学习在特征表示学习方面的优越性.
2)PCB[13]主要是将输入的行人图片水平均匀分割成P块,在各个模块上应用全局池化,得到256维的特征向量,然后用N类别的softmax损失进行训练.BDB主要包含两个分支,以ResNet-50网络作为主干网络,另一个Drop分支抽取局部关注点信息,随机擦除特征图中相同的区域.
3)本文将PCB[13]的分区策略与BDB[21]的遮挡模块相结合并在主干网络添加了SA注意力模块提出了批次分块遮挡网络BPNet,将输入网络的一部分特征图进行水平均匀分割,在分割后的特征图单独进行遮挡,增加了网络训练集的多样性,不论在DukeMTMC还是Market-1501数据集上都有明显提高.
4)在实验结果表明BPNet对行人再辨识有明显的促进作用,如表5所示.在Duke数据集上达到了88.6%的Rank-1精度,77.2%的mAP精度.在Market-1501数据集上达到了95.5%的Rank-1精度,86.3%的mAP精度,比先前的工作分别高出了1%和2.0%的精度.
4 结 论
本文提出了批次分块遮挡模块来对行人再辨识的神经网络训练进行优化,利用这种训练机制提出了相应的批次分块遮挡网络(BPNet),此网络结构利用全局分支来嵌入突出的特征表示,通过具有分块特性的特征遮挡分支来学习详细的特征,此批次分块特征遮挡网络将输入的一部分特征图在全局进行遮挡,另一部分特征图被水平分为大小相等的两块后在每一块单独进行随机遮挡,对于较大差异的场景的训练增强了稳定性和鲁棒性,提供了更加全面的特征表示.实验结果验证了该网络可以显著改善行人再辨识的检索基准.受原始模型结构、数据采集和实验硬件的限制,许多更先进的结构和方法未能应用到本模型中.下一步工作将研究深度学习与其他机器学习方法结合的行人再识别模型,以进一步提高行人预测的准确率和迁移性.
