基于问题类别自动分类的参与者推荐
2021-07-08刘晔晖赵海燕陈庆奎
刘晔晖,赵海燕,曹 健,陈庆奎
1(上海市现代光学系统重点实验室,光学仪器与系统教育部工程研究中心,上海理工大学光电信息与计算机工程学院,上海 200093)2(上海交通大学 计算机科学与技术系,上海 200030)
1 引 言
开源软件开发已经成为一个趋势.在开源社区中,开发者需要共同参与Issue(问题)解决过程(Issue Resolution Process).如果Issue持续得不到解决,将大大影响整个软件项目的进度,也将挫伤开发者的积极性.因此,为每一个Issue来寻找潜在的感兴趣的开发者具有非常显著的意义,也引起了学术界的兴趣.近年来,一些学者提出了不同的方法,他们从Issue内容的相似性[1-3]、Issue提出者与开发者之间的社交关系[4,5]以及Issue的特征,例如是否包含代码等[6,7]出发来提出相应的Issue参与者推荐方法.
Issue解决过程本质上是一个软件维护过程.早在1976年,Swanson等人就对软件维护进行了分类[1].后来,一些研究者又加入了新的分类.在研究者们的推动下,ISO/IEC 14764的标准中对不同的维护类型进行了定义,其中,纠正性维护的目的是改正已经发现的错误,而适应性维护是为了增加软件新功能,完善性维护则为了提高软件的性能,预防性维护是对已开发号的软件进行进一步的更改,目的是避免将来再出现错误.
不同的维护活动类型,即不同的Issue类型对于Issue解决过程中开发者的参与应该存在潜在的影响.因此,本文提出了3个相关的问题,并通过设计相应的模型来进行回答:
1)我们能否对Issue的类别通过计算机进行自动的类别判断?
2)在Issue解决过程中,是不是某些开发者会倾向于参与特定类别的Issue的解决过程?
3)如果前两个问题成立,那么把Issue的类别信息自动添加后,能否提高参与者推荐算法的性能表现?
为此,我们在Github上挑选了若干个代码仓库,这些代码仓库具有一定的流行度,也具有一定的代表性.为了开展我们的经验性研究,我们通过爬虫获取了这些仓库中的Issue信息.数据集的详细信息见表1.

表1 Issue数据集的信息Table 1 Information of Issue dataset
有不少人对Issue进行了类别研究,本文中我们参考了Murgia等人对Issue的分类[8].目的是要对Issue进行自动的类别判断,这显然是一个有标签的分类问题.我们提出并实现了一种基于卷积和注意力机制的Issue自动分类深度神经网络模型;在此基础上,我们对开发人员是否对Issue的类别具有倾向性进行了研究,结果证明,某些开发者在参加Issue结果过程时,会倾向于选择特定类型的Issue;基于上述结果,我们对Issue进行特征化表示,同时对开发者也根据历史数据进行向量化表示,在此基础上,可以计算开发者对某一Issue的兴趣,从而实现针对特定问题的开发者的自动推荐.
后面的文章的章节组织方式为:在第2节中我们对Issue解决过程的研究现状、特别是开源软件开发中的Issue解决相关研究进行了介绍;第3节提出了基于深度学习的Issue分类模型;第4节对开发者在志愿参与Issue解决过程时是否对特定的Issue类别具有倾向性进行了研究;第5节介绍了开发者推荐算法;第6节介绍了推荐实验的结果,并围绕这些结果进行了讨论.最后,文中对将来可以开展的工作进行展望.
2 研究现状
在开源社区中,经常会累积大量的未解决的Issue.等待开发者主动来解决这些Issue通常耗费大量的时间,甚至于某些Issue无人问津.将推荐方法运用到开源社区的Issue解决过程中,有助于提高Issue解决的速度、Issue解决的比例以及Issue解决的质量.为此,许多研究者们进行了不同的探索.例如,Kamineni等人提出了一种估计Issue语义相似度的方法以搜索相似的Issue[9,10];Dong等人设计了一个回答者推荐系统,它将Issue推荐给有针对性专业知识、能够回答该Issue的开发者,他们同时还揭示了对Issue进行及时处理可以促进提问者和回答者之间的互动性,从而能够进一步激励开发者参与到Issue解决过程中去并积极地改进他们的答案[11];Wang等人同样采用了语义技术来推荐参与者[12].虽然这些方法也能够为Issue来推荐开发者,但是本文研究的是Issue类别如何影响开发者的积极性,以及自动化标注Issue类别是否能够提高推荐效果,在这一方面,目前尚无其他人的研究.
对Issue进行分类在机器学习上是一个分类问题.同时,我们所依据的又主要是Issue相关的文本,因此它可以归为文本分类问题.在信息检索等领域,文本分类技术也是其中的一个核心技术.利用机器学习技术对文本进行自动分类已经经过了较长时间的研究,有许多方法被提了出来.我们可以利用文本分类的方法对Issue进行分类.例如,Fan等人提出根据Issue的文本摘要对Issue进行分类,经过实验,他们发现支持向量机能够取得较好的性能[13].
然而,在现实中,文本具有多样性,这容易造成传统的机器学习文本分类器的泛化能力不强.另一方面,如何选取合适的特征进行文本分类也是一个挑战.而深度学习的非线性表达能力,其逐层进行特征提取的工作过程能够较好地解决文本分类中的一些技术挑战,所以受到了普遍应用,例如,Fan等人按照word2vec模型从大规模语料库中训练汉语单词向量,然后基于词向量获得汉语问题语义特征向量[14];Liu等人则提出了一种基于LSTM-CNN的问题答案匹配方法[15].
目前,在对Issue进行开发者推荐中,还没有系统的考虑问题类别对开发者积极性的影响.为此,首先要进行的一个研究是是不是开发者确实对Issue的类别具有选择性.为了对这一假设进行检验,我们使用的是基于关联规则挖掘的方法.如果能够发现具有显著性的关联规则,则说明这个假设对于某些开发者是成立的.而开发者推荐的基本过程是针对每一个Issue,去计算每个开发者与这个Issue的匹配程度,匹配程度高,那么这个开发者就可以得到推荐.为此,需要从每个开发者过去参与的Issue中学习开发者的特征.
3 基于深度学习模型的Issue自动分类方法
3.1 Issue自动分类模型
为了进行文档分类,在机器学习中,许多模型都被尝试使用,例如逻辑回归,支持向量机、朴素贝叶斯、决策树等.在应用这些模型前,我们首先需要进行特征提取和特征选择.特征选择的结果对最后的性能具有非常显著的影响,而特征选择又高度依赖于经验和对业务知识的理解.所以特征选择是一个困难的工作.深度学习方法能够在原始特征表示的基础上,通过大量的参数学习自动获得抽象的、有效的特征,从而降低了特征工程的工作量和难度.因此,深度学习受到了普遍的关注.
尽管深度学习也已经成功的应用于文本分类的任务,但是并没有针对Issue分类的深度学习模型.本文中使用了一种深度学习模型,它结合了词嵌入、卷积神经网络,并添加了注意力机制,从而实现了对Issue的自动分类.
在该模型中,它包含了以下的主要步骤:
1.对数据进行预处理.首先对收集到的Issue的标题以及它们的内容进行整理和清洗,先把Issue的标题和描述文本合并成一个文本,然后对该文本进行分词,去除停用词、数字和非字母,将文本转成小写,提取词干等一系列文本的操作.
2.训练与验证.按照Issue的标号对数据进行排序.然后,将整个数据集平均分割成11份,通过“十折交叉验证”的方法在数据集上进行模型的训练与验证[16].该部分又可以分为3个小步骤:
1)利用训练集训练一个分类模型,这里我们采用了CNN模型来获取问题的特征.
2)通过采用注意力机制对CNN模型提取出来的文本特征进行进一步的学习.
3)在验证集上进行验证,将测试集中的Issue进行同样的文本处理后作为输入,从而可以获得文本类别.
3.对分类模型的预测效果进行测试.由于前面使用了“十折交叉验证”对模型进行了训练,所以我们使用10轮预测结果准确度均值作为该分类模型的最终评价效果.
本文所提方法的核心是基于混合3层卷积神经网络和注意力机制的问题分类方法(Atten-3CNN),其模型结构如图1所示,该模型的思想主要包含以下3个方面:

图1 Atten-3CNN模型结构图Fig.1 Atten-3CNN model structure
1.文本向量化.假设一个文本中包含的词语个数为l,词汇表大小为D,如果对文本进行one-hot编码需要的矩阵为l×D,通过word2vec进行词向量化(分类器的词向量维度为d),得到的文本可以用l×d表示.
2.采用3层CNN提取文本特征.根据Song等人的研究结果可知,采用3、4、5的卷积核使CNN分类效果更好[17].因此,我们选用了3×d、4×d、5×d的卷积核对l×d矩阵进行卷积操作,也就是用矩阵Wj×d(j=3,4,5)与文本矩阵进行相乘,如公式(1)所示.
Sj=Wj×d·S[i:i+j-1]
(1)
其中,j表示卷积核大小,Sj∈Rl-j+1表示进行卷积后的特征向量,i=1,…,l表示文本矩阵的行下标.
接着,将3层卷积操作后得到的文本特征向量进行池化操作.此处,我们对每一个特征向量取其最大值:
vj=max(Sj)
(2)
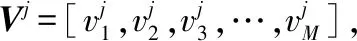
3.注意力机制(Attention).通过注意力机制来调整特征权重.该过程主要分为权重学习和文本特征更新两步:
1)权重更新.对M个卷积核抽取得到的特征,通过学习算法自动调整各个特征对最后分类结果的影响程度(即权重aj),Attention模块如下:
cj=tanh(Wj⊗Vj+bj)
(3)
aj=softmax(cj)
(4)

2)更新文本特征.新的文本特征是把注意力权重与CNN提取的文本特征进行相乘,如公式(5)所示:
(5)
4.用交叉熵损失函数(categorical_crossentropy)训练模型[18].交叉熵可以衡量两个概率分布的差别,此处,我们用来计算当前训练得到的概率分布与真实分布的差异情况,其计算如公式(6)所示.
(6)
交叉熵值越小,两个概率分布就越接近,我们的预测也就越准确.
3.2 分类准确度
根据Murgia等人在实际问题中的研究,Issue可以分成纠正、适应、完善或预防性维护等类型.在提出Issue时,现代开源平台经常允许提出者添加一些标签,而这些标签与Issue类型有一定的关系.表2显示了标签和类型的对应关系.

表2 Issue标签/维护类型对应关系Table 2 Table of corresponding relationships between Issue-labels and maintenance-type
而在Github上,部分Issue上是有标签的,依据这些标签就可以对Issue来分类.我们依据这些标签构建了训练集,训练集中Issue类别分布如图2所示.

图2 训练集Issue类别分布情况Fig.2 Distribution of Issue categories on the training set
我们对Issue分类模型进行了的对比分析,其结果如表3所示.其中,基于深度学习进行的文本分类均采用keras库中的categorical_crossentropy对损失函数进行训练.我们设定epochs=10,batch_size=64,图3显示了Atten-3CNN模型的损失函数在每一轮训练中的变化情况.
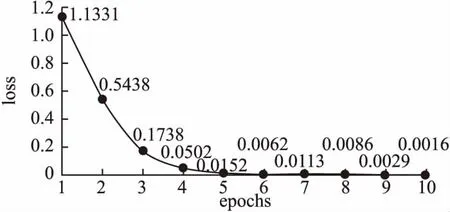
图3 Atten-3CNN模型损失函数变化情况Fig.3 Atten-3CNN model loss function changes
由表3可知,Atten-3CNN获得了最高的预测准确度.这表明,对Issue进行自动分类是可行的.

表3 分类算法准确度Table 3 Classification algorithms accuracy
4 开发者志愿参加Issue解决过程时对Issue类型的选择性
人们在作出各种选择时,都有不同的偏向性.例如有些人喜欢解决相对容易的问题,有些人则喜欢解决具有较高挑战性的问题.这就促使我们提出我们的假设,不同的人员可能对不同的Issue类型具有选择性.
我们采用关联规则挖掘的方法检验这一假设是否成立.我们通常用支持度、提升度、置信度来衡量关联规则的质量[19].规则SupX→Y表示事件包含X和Y的概率,规则ConfX→Y表示X发生下Y发生的概率;对规则进行置信度分析可以来确定前提和结论是谁影响谁:如果规则在方向(X→Y)上的置信度显著高于在方向(Y→X)上的置信度时,我们说X影响Y而不是Y影响X;Lift是由规则的置信度以及其结果的支持度的比值,如果Lift=1,则表示X和Y没有相关性;如果Lift<1,则说明规则没有参考价值;如果Lift>1,则表示我们获得的规则有价值.
我们在文献[20]一文中用该方法成功地研究了Issue的特点与开发者是否愿意参与该Issue解决过程的关系.此处我们单独研究开发者对Issue类型的选择性.
表4-表7显示了各种Issue类型与开发人员之间的规则.

表4 issue_category=adaptive→user类型的关联规则Table 4 Association rules of type issue_category=adaptive→user
表4列出了针对适应性类型的Issue的关联规则.例如,规则1中表明,在“realm-cocoa”中,如果Issue类型是适应性的,开发人员“kevinmlong”参与的概率将比一般人增加324%.
同时,我们也检验了其他Issue类型上开发人员的选择性,结果列在了表5-表7中.这些结果表明对于部分人员,确实对Issue类型具有显著的选择性.当然,对于另外一些人员可能还没表现出显著的选择性.这就启发我们,对于Issue类型敏感的开发人员,我们在推荐时需要重点考虑Issue类型与他的匹配.
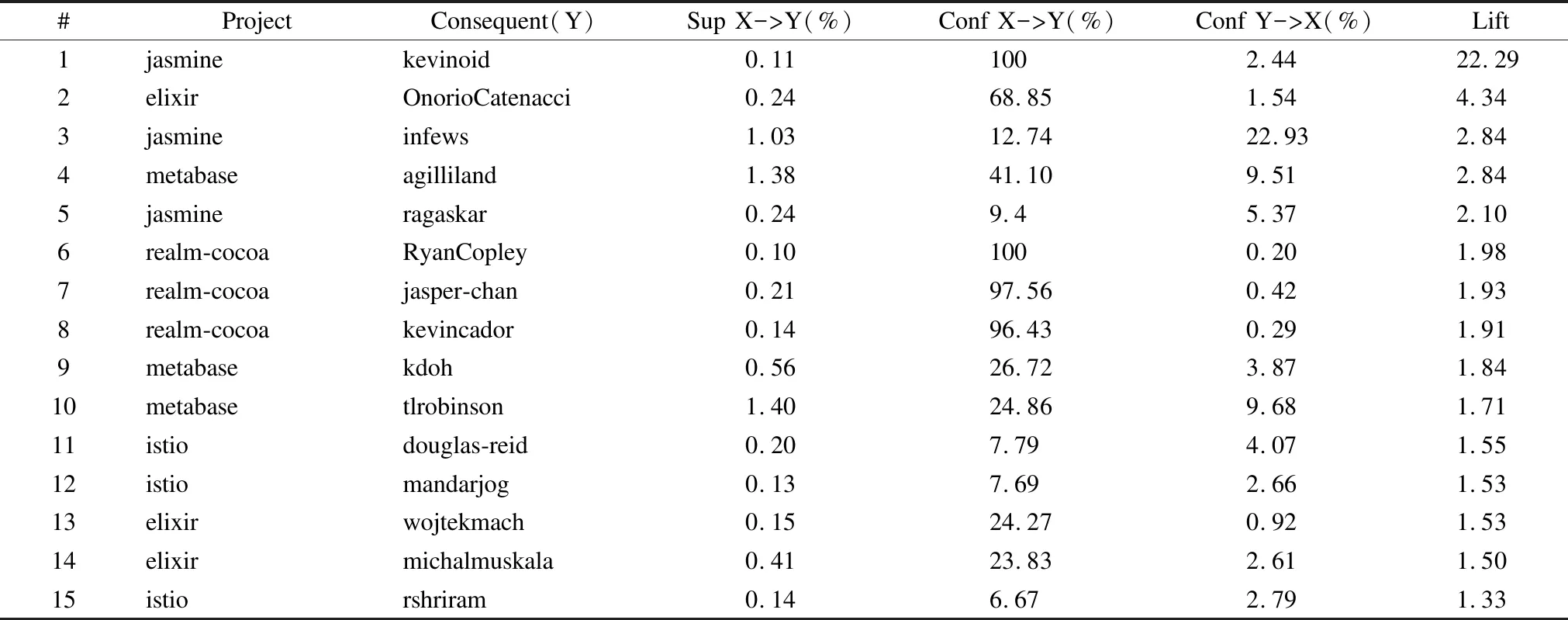
表5 issue_category=corrective→user类型的关联规则Table 5 Association rules of type issue_category=corrective→user

表6 issue_category=perfective→user类型的关联规则Table 6 Association rules of type issue_category=perfective→user

表7 issue_category=preventive→user类型的关联规则Table 7 Association rules of type issue_category=preventive→user
5 依据Issue自动分类进行问答者推荐
经过Issue类别自动分类后,可以把每个Issue表示为以下的两种形式:
I=[textLen,codeyes,codeno,inner,outer]
(7)
I=[textLen,codeyes,codeno,inner,
outer,adap,corr,perf,prev]
(8)
公式(7)表示的是不带Issue类型的表示,公式(8)是带Issue类型的表示,为了便于表达,adap表示适应性Issue,corr表示纠正性Issue,perf表示完善性Issue,prev表示预防性Issue.
为了对开发者的特征进行表达,我们采用了以下的方法:
1)对属性取值进行归一化处理:各项属性的数值范围大小不一在后续计算中将产生不利影响.因此,把不同范围的属性取值进行归一化,其计算方法如公式(9)所示:
(9)
得到的x′ij为第i个样本的第j个属性的数值(i=1,2,…,n;j=1,2,…,m).
2)获取第j个属性下第i个样本占该指标的权重:
(10)
3)计算第j个属性的熵:
(11)

4)计算信息熵的冗余度,它代表了在该属性上的差异性:
dj=1-ej,j=1,…,m
(12)
5)获得各项属性的权重:
(13)
得到了每个开发者的特征表示后,我们需要计算Issue与各个开发者的匹配程度,匹配程度越高的就越优先推荐.由于Issue也与开发者特征一样表示成了相同维度的特征向量,所以可以计算这两个向量的内积,从而得到匹配的分数.我们为这个Issue推荐最高得分的N名开发者.
6 实 验
为了验证加入Issue类别自动分类后的推荐效果,我们进行了一系列的实验.
6.1 评价指标
此处,最重要的是召回率,它的计算方式如公式(14)所示.
(14)
其中,Issues表示Issue测试集,R(i)表示Top-N推荐列表,T(i)表示实际中参与Issue讨论过程的开发者集合.
6.2 结果与讨论
为了分析我们的方法对于不同支持度下的关联规则发现的Issue类型敏感开发者的效果,我们获取了支持度Sup(X→Y)=0.1%和Sup(X→Y)=0.2%时的Issue类型敏感开发者.然后依据Issue与开发者特征的匹配得分,将得分最高的Top-N个开发者进行推荐,表8中是支持度为0.1%和0.2%下的不同结果.
表8中的结果表明,提高支持度可以选出对Issue类型更有选择性的开发者,我们参考了他感兴趣的Issue类型进行推荐,就更有针对性,因此性能也能得到进一步的提高.

表8 Sup=0.1%和Sup=0.2%时Issue类型敏感人群Top-N推荐的RecallTable 8 Recall of Top-N recommendation for problem-sensitive people when Sup=0.1% and Sup=0.2%
在过去的研究工作中,研究者们采用了计算Issue表达的相似度计算或基于评论网络的社交关系进行Issue参与者推荐[20].将我们的方法与这两种基本算法进行性能对比.我们的方法在Top-6,Top-8和Top-10上都比对比的两个算法的最佳效果要好.其中,在realm-coco仓库上,我们的方法的召回率提升了16.71%,而在jasmine仓库上召回率提升了5.46%;在istio仓库上,召回率提升了13.59%,在metabase仓库上效果最为显著,提升了22.5%的召回率.仅仅在elixir仓库上不太显著,提升了0.78%的召回率.
此外,为了显示Issue类别对开发者的影响,我们比较了加入Issue类别(sensitive with issue type)以及不加入Issue类别(sensitive without issue type)时针对Issue敏感人群的Top-N的推荐效果.同时,我们针对所有人群也进行了相同的实验,结果如表9所示.
为了更清晰的展示结果我们将表9中的数据画成图4.从图中可以看出,对于Issue类别敏感人群,在所有的仓库上加入Issue类别比不加入Issue类别可以获得更高的推荐性能.同时,从图4(c)和图4(d)可以看出针对Issue不敏感人群加入Issue类别也可以提高推荐性能,因此在参与者推荐系统中,应该针对开发者对Issue类别的敏感度选取合适的候选者进行推荐.

表9 不同人群Top-N推荐的RecallTable 9 Recall of Top-N recommendation for different groups
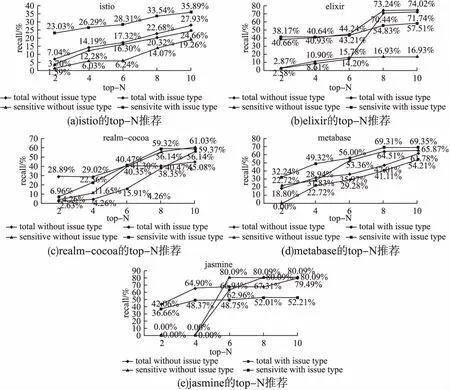
图4 不同算法下参与者推荐Recall比较Fig.4 Comparison of participant recommendation Recall under different algorithms
7 总结和展望
由于Issue是有一定的类别的,因此本文针对添加Issue的类别可能对于开发者推荐有一定的帮助的猜想进行了验证.为了进行这个验证,我们提出了一种Issue自动分类的深度学习模型,经过测试,该模型具有一定的准确性,可以得到应用.然后,我们进行开发者推荐的研究.我们发现,某些开发者对Issue类别具有一定的敏感性,对这样一类开发者推荐特定类别的Issue能够提高推荐效果.我们也发现,对于一些类别不敏感的的开发者,加入问题类别并不起到效果.这也说明,开发者确实具有不同的特性,需要针对他们的特性来提供相应的推荐模型.
本文的工作还有许多可以拓展的空间,例如在本文提出的方法中我们选取了部分特征来刻画开发者的模型,然而,还存在一些潜在的特征可能对开发者参与Issue解决存在重要的影响.在未来的工作中,我们可以加入更多的特征,或者利用一些特征选择的方法,来找到更好的特征以提高开发者推荐的效果.
