一种基于主题模型与迁移学习的文本分类方法
2021-07-02汪满容刘桂锋
包 翔,汪满容,刘桂锋
(江苏大学 科技信息研究所,江苏 镇江 212013)
分类方法作为机器学习中的重要组成部分,其应用领域渗透到了各行各业。传统的分类方法要求满足两个条件:一是用于学习的训练样本和最终用来测试的样本必须符合独立同分布的条件;二是用于学习的样本量必须达到一定的规模才能得到一个较好的模型。但在实际情况中,同时满足以上两个条件非常困难。学术研究中,迁移学习放宽了传统分类方法的两个条件,被定义为:运用已有的知识对不同但相关的领域问题进行求解的一种新的机器学习方法[1]。在迁移学习领域,源领域和目标领域分别被称为训练集和测试集。源领域以及目标领域主题相关但不完全相同。
学者们对迁移学习在文本分类中已经开展了大量研究,跨领域文本分类方法大体上可以分为两种,基于示例权重的跨领域学习和基于特征选择的跨领域学习。基于示例权重的跨领域学习方法聚焦于如何确定源领域中示例的权重,使得能增加与目标领域分布相似的示例的权重,减少与目标领域不相似示例的权重,基于示例权重的跨领域学习方法主要的研究难点在于对不同领域间数据分布差异的衡量,文献[2]提出一种基于监督自适应转移概率潜在语义分析(supervised adaptive transfer probabilistic latent semantic analysis,SATPLSA)的跨域文本分类模型,该模型将原PLSA(probabilistic latent semantic analysis)扩展到有监督的学习范式,通过跨领域定义每个术语的标签信息,在源域中传输知识,自适应地修改了权重值,以控制模型学习过程中来自源域的知识使用比例;文献[3]在构建基于极限学习机的无监督自适应分类器时,结合联合概率分布匹配和流形正则的思想,对输出层权重进行自适应调整,在字符数据集和对象识别数据集上的实验结果表明其具有较高的跨领域分类精度;文献[4]针对传统领域间分布差异度量方法忽略单个样本对全局度量贡献差异性而影响特征迁移算法性能的问题,基于样本局部判别权重的加权迁移成分分析算法,还将线性判别分析引入目标函数,在实现知识迁移的同时,提高算法的类别可分性。
基于特征选取的方法致力于找到一个共同的特征空间,并在这个空间里实现迁移学习,研究难点在于对样本原始结构和标签信息缺乏足够的利用。文献[5]提出的CDELM(cross-domain extreme learning machines)通过匹配两个域的投影方法将源分类器自适应到目标域,并通过流形正则化来探索目标域的结构特性,使最终的分类器更适合目标数据;文献[6]提出了一种跨领域标记LDA(cross-domain latent dirichlet allocation)的方法用于跨领域文本分类,引入组对齐的方法减少领域间语义层面的误差,并能检测到那些有意义的主题;文献[7]研究了极限学习机(extreme learning machines,ELM)框架下的联合域匹配与分类(joint domain matching and classification,JDMC)方法,根据映射特征空间中的边际概率和条件概率分布来衡量源领域和目标领域之间的差异,并将差异降到最小,通过对ELM的输出权重中加入L-范数,选择在两个领域表现相似的信息特征进行知识转移,该方法在预处理中运用PCA(principal component analysis)进行降维。但是以上方法仍存在一些问题,例如文献[4]中用到了构件分布差异权重矩阵,采用广义分解投影矩阵的方法,时间复杂度较高;文献[5]中的方法在一些数据集的效果不佳,不具有普适性;文献[6]所提出的方法参数设定较为复杂;文献[7]提出的方法需要进行参数的预处理。
本研究方法基于特征选取,首先,利用将文本集合成由共同主题和特定主题联合起来的混合模型;然后,通过这两类主题相关性推断不同领域之间主题的映射关系;最后,融合共同主题以及映射后的特定主题形成一个新的特征空间,在这个特征空间中,知识可以有效转移。实验表明该方法能较为准确地预测跨领域的文本分类,为实现更多文本的自动分类提供参考,并在多个数据集中验证该方法的性能。
1 基于主题模型和迁移学习的文本分类方法

1.1 挖掘共同主题和特定主题
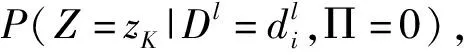
(1)
其中,
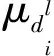
文档的对数似然可以表示为:
(2)

EM算法分为E步和M步,经过推导得到参数的估计值分别为:
E步:
(3)
(4)
M步:
(5)
(6)
(7)
(8)
(9)
1.2 计算不同领域内主题相关性
由于公式(1)中并没有计算跨领域主题之间的共现矩阵,因此本研究将共同主题作为一个桥梁,期望找到跨领域主题之间的关系。
在分析中发现若两个跨领域主题都与共同主题有关联,其间很可能是语义相关的[9],所以本部分的重点有两个方面:一是计算每个领域内共同主题和特定主题之间的相似性;二是推断不同领域内的特定主题之间的相关性。
为了解决第一个方面的问题,本研究采取JS散度(Jensen-Shannon divergence)作为文本-主题分布之间的相似度度量。JS散度被广泛应用在度量概率分布之间的相似度。对于两个分布P和Q,JS散度表示为:
(10)
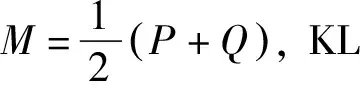
(11)
即如果一个共同主题和特定主题总是在文本中同时出现,则之间有很小的JS散度,这两个主题之间相似度会很大。
对于第二个方面的问题,由于不同领域之间的特定主题不可能共现,所以不能用公式(11)来直接计算相似度,而且JS散度的值域为[0,1]。因此,选择皮尔森相关系数(Pearson correlation coefficient, PCCs)来计算其相似性,PCCs∈[-1,1],绝对值越大,两个变量之间的相关性越大,接近-1表示负相关,接近于1表示正相关。本方法中,源领域和目标领域各自的特定主题之间的相关性表示为:
(12)

(13)
1.3 文本数据的重新表达
以上讨论的是挖掘共同主题以及特定主题与计算不同领域内主题相关性等步骤,现讨论如何将源领域和目标领域的文本映射到一个新的特征空间上,并在该特征空间上进行跨领域的文本分类。
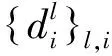
(14)
(14)

综上所述,本方法具体流程如下:
输入:源领域已标注的文本数据集Ds,目标领域未标注的文本数据集DT;源领域文本数据主题个数Ks,目标领域文本数据的主题个数Kt;共同主题的个数K;迭代最大次数T。
输出:目标领域内未标记文本的类别。
S1:初始化公式(1)模型的参数,利用EM算法更新模型参数;
S2:计算共同主题和特定主题之间的相关性,计算参考公式(11);
S3:构建主题映射矩阵U,具体计算参考公式(13);
从上述描述可知本方法的时间复杂度为O(n*m*(K+Ks+Kt)+n),其中n代表样本总量,m代表字典的维数,K表示共同主题的个数,Ks表示源领域的特定主题个数,Kt表示目标领域的特定主题个数。
2 实验及分析
为了测试上述方法的有效性,将分类中常用的准确率(P)、召回率(R)、综合准确率和召回率的F值(F)等指标作为评价标准,与支持向量机(support sector machine,SVM)和K最近邻(k-nearest neighbor,KNN)两种经典的分类方法进行比较。同时也与三种其他基于跨领域学习方法进行实验对比,其中第一种方法是基于统计生成模型的协同-对偶PLSA模型[10],以下简称CDPLSA,该方法力求同时找到不同领域内的区别与共性,并将两者融合以实现知识的迁移;第二种方法是在PLSA模型的基础上运用非负矩阵三因子分解的方法建立源领域和目标领域之间迁移学习的桥梁[11],以下简称TLPLSA;第三种方法是基于深度自编码的迁移学习,利用深度自动编码器来同时表示不同领域的特征[12],以下简称DEEP-AC。对于SVM和KNN方法,分类器使用源领域中标记文本进行训练,之后将该分类器用于目标领域中预测类标签的未标记文本。
实验数据集(如表1所示)有两个:一个是常用的文本分类测试数据集20 newsgroups,另一个是关于专利分类的数据集。20 newsgroups数据集包含了近20 000个新闻组,并被均匀分割成20个不同的主题。利用文献[13]中生成的跨域文本数据集,利用数据集的二元结构层次结构,如comp.graphics,其中comp为大类,代表的是该文本属于计算机领域,而comp.graphics为小类,代表该文本是属于计算机领域下的图像领域,通过对源领域数据集的分析,判断目标领域文本所属的大类。专利分类数据集来自上海知识产权公共服务平台的中国专利数据库,选取水处理技术领域的 500 篇专利文献作为语料库,以该数据库中各个专利对应的人工标引IPC分类号作为依据,将技术内容注明为:部-大类-小类-大组-小组。专利文本语料库中源领域的数据是由两个大类下的小类的文本组成,通过本方法判定目标领域中相关文本所属的IPC分类号中的大类信息,从而实现专利的自动分类。值得一提的是,专利分类实验采用 jieba中文分词的.NET 版本并通过精确分词模式来实现,在特征选择阶段,文本特征利用 TFC 加权法[14]计算出每一个特征词的权重,并且选取了前1 000个 TF*IDF 值对应的特征词作为数据的索引词。
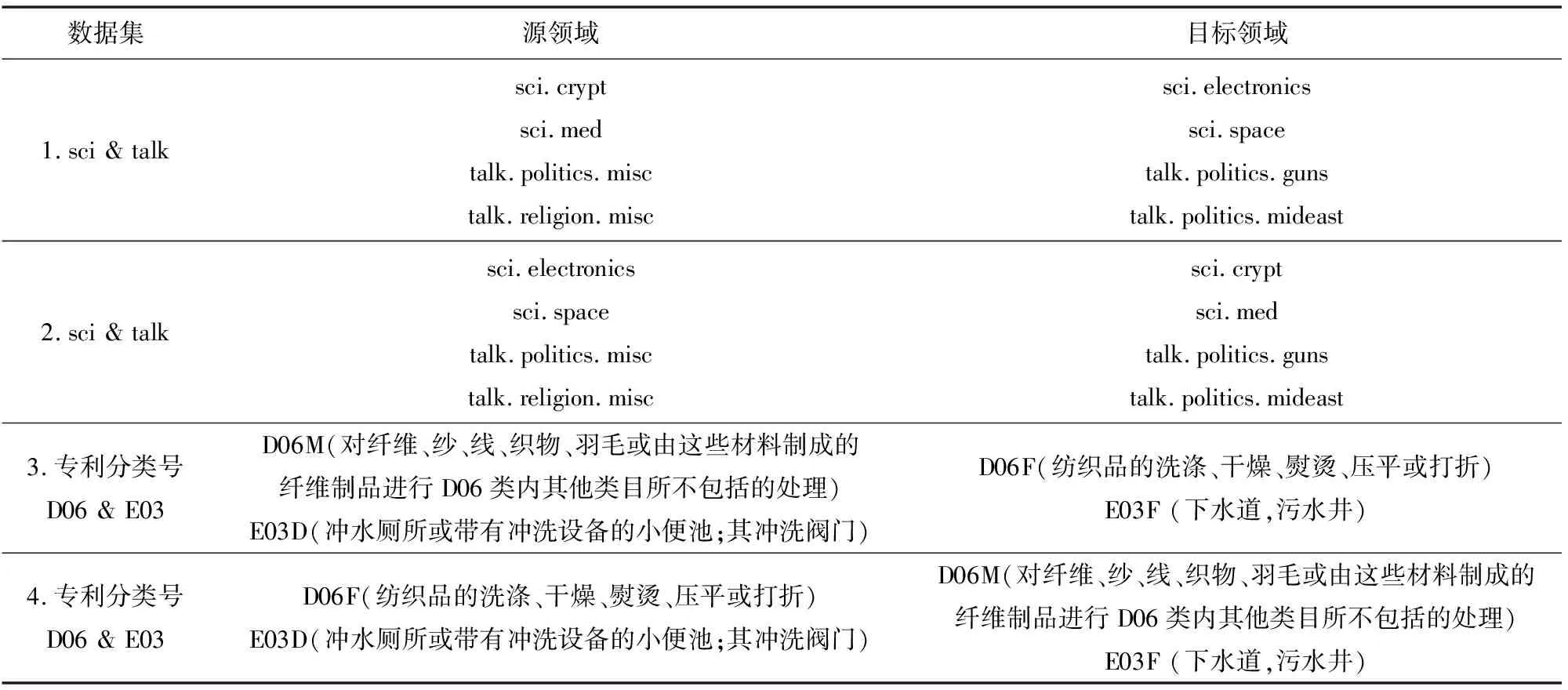
表1 实验数据介绍
本研究将共同主题数、源领域文本数据特定主题个数和目标领域文本数据的特定主题个数设置为相同的值,通过分析不同共同主题数在分类准确率上的变化情况,选取最优的主题数目。图1表示sci & talk和D06 & E03的数据集中分类准确率的变化情况,可见sci & talk数据集的共同主题数为6时,分类准确率最高,而D06 & E03数据集的共同主题数设置为7。

图1 不同数据集中分类准确率随着主题个数的变化情况
以数据集20 newsgroups中的sci & talk数据为例,说明本文第一部分的运算流程。数据集1的源领域数据包括sci.crypt、sci.med、talk.politics.misc和talk.religion.misc,而目标领域包括sci.electronics、sci.space、talk.politics.guns和talk.politics.mideast,将共同主题的个数设为K=6,并将源领域文本数据特定主题个数、目标领域文本数据的特定主题个数都设置为6,得出该实验中共同主题对应的主题词、源领域文本数据特定主题对应的主题词、目标领域中特定主题所对应的主题词见表2~4。

表2 源领域和目标领域共同主题所对应的主题词
根据1.2节中的介绍,用于表示源领域和目标领域文本数据特定主题之间的映射矩阵为:

表4 目标领域中特定主题所对应的主题词
由表3~4可知,源领域文本中的主题6与目标领域中的主题4的主题词有很多相似之处,都包含edu、writes、com和article等词语,由此推断这两个主题之间的相似度应该会较高,从源领域和目标领域文本数据特定主题之间的映射矩阵U可以看出相关度为0.824,符合实际主题分布的情况。
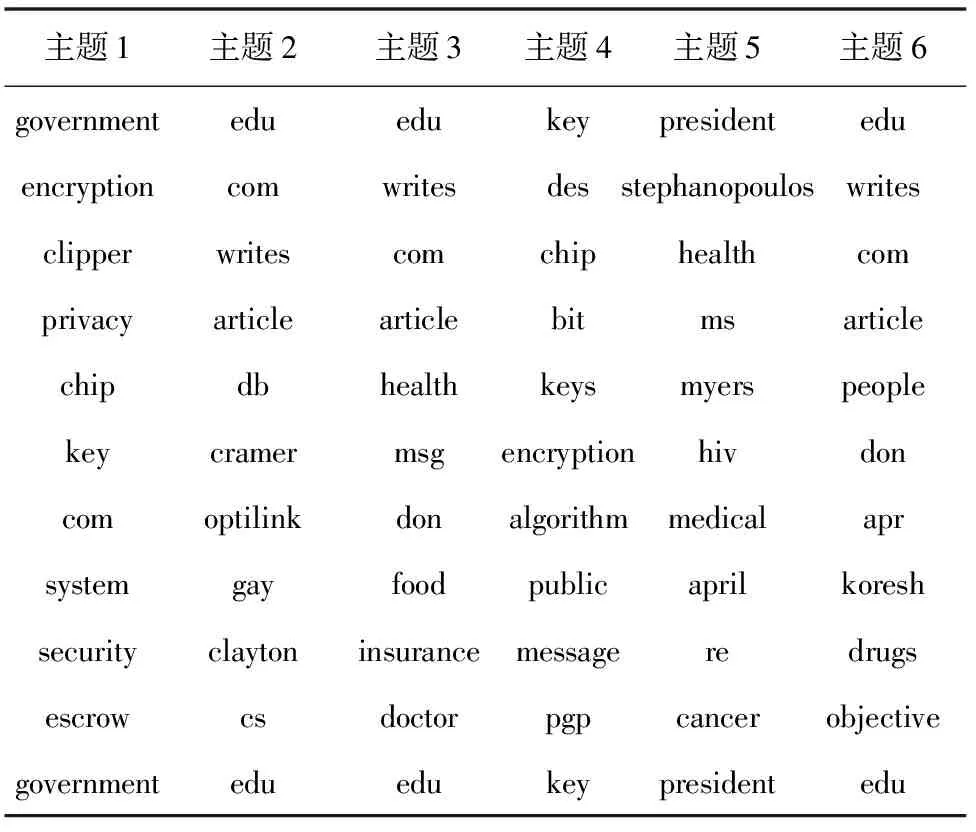
表3 源领域中特定主题所对应的主题词
由于本方法有随机初始化过程,因此在实验设计中设置程序运行次数为10次,并对10次运行的平均结果进行分析,采用P、R、综合准确率和召回率的F值作为评价指标,具体实验数据如表5。
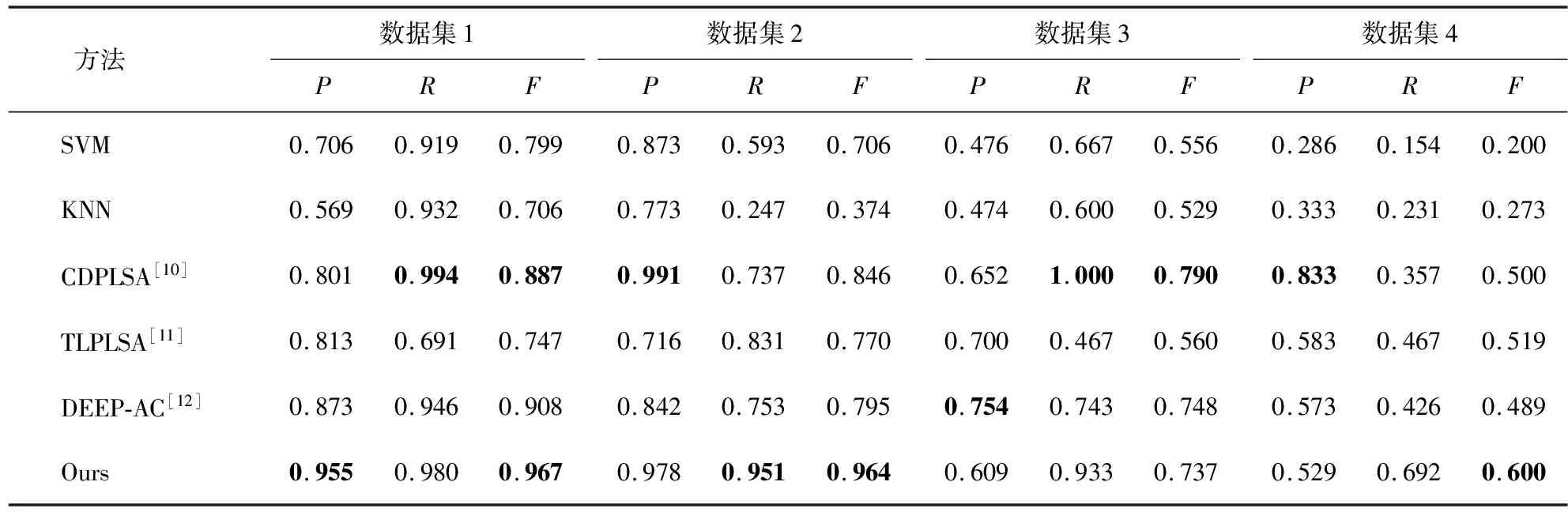
表5 各种分类方法在不同数据集上的分类结果
表5比较了6种方法在4个数据集上的分类指标,实验结果表明,本研究方法在数据集1、2、4中F值都是最高的。具体的,在数据集1上,除了R值略低于CDPLSA方法,其他的指标都是最优的;在数据集2和数据集4上,除了P值略低于CDPLSA方法,其他的指标也都是最优的;CDPLSA的方法在数据集3上取得最优的R值和F值,而DEEP-AC方法则有最优的P值,但是本文F指标与以上两种方法的结果都比较接近。综上所述,本方法比SVM和KNN方法的分类效果要好很多;尽管在有些数据集上的某些指标上略逊于CDPLSA、TLPLSA、DEEP-AC几种迁移学习的衍生方法,但本方法对应的分类指标没有出现P、R两个指标非常小的极端现象,说明本方法具有良好的适用性。
通过表6可以看出,本方法的AUC值较SVM、KNN等有较大优势。尽管在某些数据集上的AUC值不如CDPLSA、TLPLSA和DEEP-AC方法,但在20 newsgroups-sci和20 newsgroups-talk数据集上本方法的AUC值明显高于其他方法;在专利数据集D06和E03上,虽然本方法的AUC值分别低于CDPLSA和TLPLSA,但与最优值之间的差距较小。
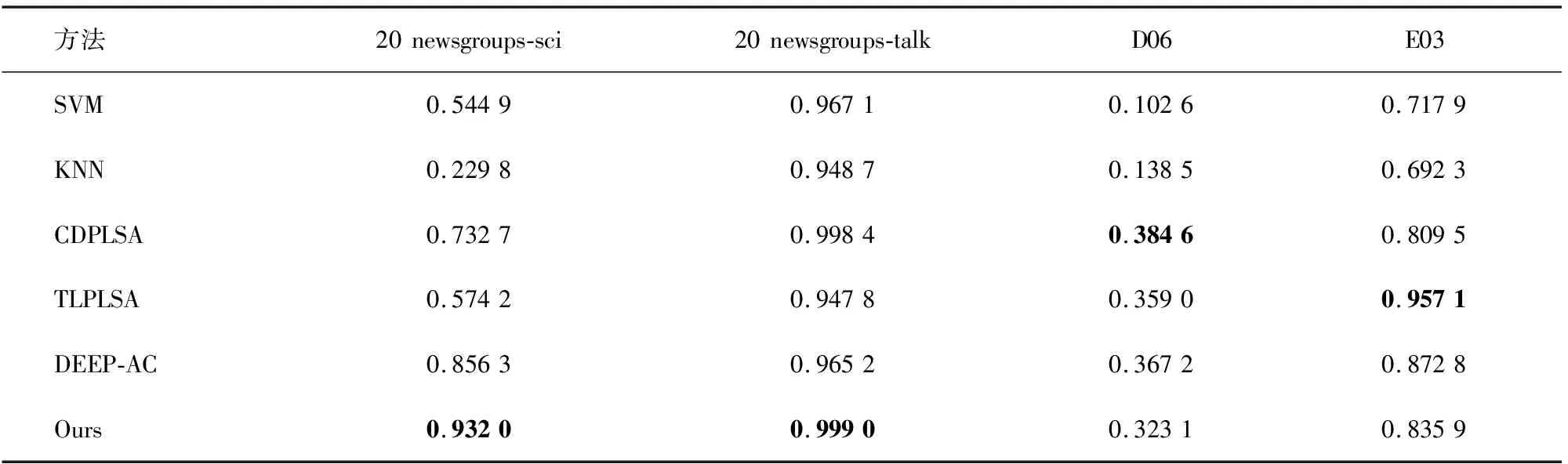
表6 各种分类方法在不同数据集上分类AUC值比较
综上所述,本方法在20 newsgroups数据以及自建的中国专利数据集上都具有较好的分类效果,说明适用性较好。其次,本研究的主题个数的设置通过准确率分析即可确定,只需设置EM算法的迭代次数,并对公式(1)进行初始参数的确定,总体来说参数设置比较简单。最后,本方法不需要进行预处理,只需要对公式(1)进行初始参数的确定,而初始参数在EM算法多次迭代之后对分类结果的影响很小,时间复杂度也较小。
3 总结与展望
本研究基于主题模型与迁移学习的文本分类方法,借助跨领域迁移学习的方法对跨域的文本进行分类,通过挖掘文本的共同主题和特定主题及相关性推断出不同领域之间主题的映射关系,融合共同主题以及映射后的特定主题形成一个新的特征空间,并在此特征空间中完成文本的分类。实验表明,该方法能较为准确地预测跨领域的文本分类,为实现更多文本的自动分类提供参考。总体而言,从国内外的语料库的实验可以发现,本方法相较于其他对比方法鲁棒性较好,没有出现非常极端的情况。但是,本研究提供的方法仍有一些缺陷,例如,主题模型中共同主题和特定主题数目的确定是通过枚举方法确定,缺乏严谨的理论支撑;本实验的专利语料库由水处理领域的两个不同IPC号的相关文献构建而成,该专利语料库可能存在两类对比主题过于接近、中文语料库预处理结果不是非常理想等问题,导致专利语料库上的分类效果与其他对比方法没有过多的优势。
