基于条件生成对抗网络的人脸去妆算法研究
2021-07-02廖毅应三丛
廖毅,应三丛
(四川大学计算机学院,成都610065)
0 引言
随着生活水平不断提高,人们越来越多地关注自己的外表,使用化妆品或者使用手机进行上妆美颜是大家普遍且流行的选择。面部妆容虽然可以让一个人看起来更漂亮,但同时也会遮挡面部特征,甚至有些程度很深的妆容堪称“换头术”,这种厚重的妆容很容易造成人或者计算机人脸识别算法的错认、误认[1],影响到网络社交、人脸信息安全等领域。
和与之相反的上妆算法[2]不同,在卸妆算法中,面部信息被化妆品遮挡,通过有妆图像得到卸妆后图像相比之下更为困难,卸妆算法主要有一下挑战:①由于化妆品遮挡于皮肤上方,原本皮肤的颜色,纹理的信息较少。②化妆过程中会使用深色化妆品打阴影,由于2D图像没有深度信息,可能会影响算法对人脸结构的判断。
目前研究人员对于卸妆任务也开展了多方面研究。Wang S Y等人[3]提出了一种基于局部约束的框架(LC-CDL),先判断和化妆品的使用情况,再生成去妆人脸,从而根据不同的风格进行针对性地卸妆。Chen Y C等人[4]对于去除由美颜软件生成的人脸图像美颜效果,提出了一种分量回归网络(CRN),CRN在不知道美化操作细节的情况下,将编辑后的人像图像映射回原始图像,解决了在盲还原中使用欧几里得损失的局限性。Cao C等人[5]提出了深度双向可调控的去妆网络(BTD-Net),该网络联合学习化妆过程来辅助学习去妆过程。通过引入了一个反映化妆风格的潜变量,将其作为补充条件,最终把一对多的映射约束到特定的解。
已有的卸妆算法已经取得了不错的效果,但是依然存在一定局限性,算法得到的卸妆图片通常难以保留纹理信息,或是有伪影、边缘模糊的现象,使得生成的人脸不够真实。基于以上存在的问题,本文提出使用配对数据集训练,在条件生成对抗网络[6]的基础上,训练生成器将有妆图像生成无妆图像,并且引入L1损失函数保留身份信息,并且生成较为清晰的边缘。通过使用VGG16网络提取图片特征,引入感知损失确保较为真实的皮肤纹理质感。
1 相关技术
1.1 条件生成对抗网络
生成对抗网络由Goodfellow等人[7]在2014年提出,它被广泛的应用于风格迁移,高分辨率图像生成等计算机视觉领域。生成对抗网络将博弈论的思想引入深度学习,通过网络间的对抗不断提升生成图片的质量。生成对抗网络的基本结构由生成器G和判别器D两部分组成。生成器将输入的随机噪声z生成新的数据分布G(z),判别器D的任务则是区分真实样本x和由生成器生成的虚假样本G(z)。生成器和判别器之间相互对抗,交替训练,随着生成数据越来越接近真实数据,模型逐渐达到平衡,得到最优解,其目标函数可表示为:

条件生成对抗网络由Mirza等人对生成对抗网络改进得到,它是为了解决生成对抗网络生成难以控制目标图片生成的问题。条件生成对抗网络的结构如图所示。新加入条件c,并同时输入给生成器和判别器,指导网络生成更有针对性的数据。生成器生成与条件c相匹配的数据,判别器与常规生成对抗网络不同,除了判断数据是否真实,还需要判断数据是否与条件c匹配。目标函数可表示为:
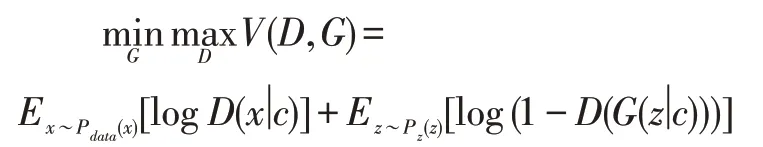
1.2 图像转换
图像转换是指将一幅图片转换为另一幅图片的一类问题,例如将照片中的黑夜转为白天,或者将人像照片转为素描,人脸去妆算法同样也属于一类图像转换任务。随着深度学习的发展,利用生成对抗网络解决图像转换问题的研究也越来越多。在图像转换的任务中,生成器G的输入通常是需要转换的图片,输出转换完成的图片。判别器D判断样本是真实样本还是由生成器生成的虚假样本。Isola等人[8]提出了Pix2Pix模型,通常用于图像转换任务。它基于条件生成对抗网络,学习输入图像和输出图像之间的一一对应关系,使用大量的配对数据进行训练,并且尽量保证每对训练数据无需转换的无关信息不改变。为了解决配对训练数据难以获取的问题,Zhu J Y等人[9]提出环形生成对抗网络模型CycleGAN,可以比较好地完成域间的图像转换。CycleGAN的结构包含两对生成器和判别器,形成了一个环形的结构。通过设置了循环一致的损失函数,让图片在不同域间转换而不丢失原本的信息。
2 方法设计
在人脸图像去妆容问题中,目标是由一张具有妆人脸图像得到一张该对象的去妆图像。本文方法使用条件生成对抗网络的框架,训练的最终目的是得到生成模型G,用于生成去妆图像。接下来将从网络结构、损失函数两个方面介绍本文方法。
2.1 网络结构
本文以条件生成对抗网络框架为基础,包含一个生成器和一个判别器,外接一个预训练过的VGG16网络用于训练过程,如图1所示。图中x为有妆图像,作为生成器的输入,经过生成器得到卸妆后图像G(x)。生成器采用包含9个残差块的全卷积结构网络,先将输入的图像进行卷积操作进行重复的下采样,中间经过9个残差块进行图像转换,再进行重复的上采样恢复到原本图像大小,最后输出生成的去妆图像。判别器同时输入卸妆后图像G(x)和有妆图像x的组合,或是输入真实无妆图像y有妆图像x的组合,判别器需要判断此样本是是包含G(x)的虚假负样本还是包含y的真实正样本。判别器使用PatchGAN的判别器结构,判别器输出一个判别矩阵,矩阵中每个数对应原图的一片区域。使用PatchGAN结构有助于生成分辨率更高,细节更清晰的图像。Gatys等人[10]发现VGG16网络卷积后的特征图可以表示图片的纹理信息,可以用此来约束网络生成与此人接近的皮肤特征。

图1 本文提出的卸妆网络结构
2.2 损失函数
损失函数包括3个部分,对抗损失函数,平滑L1损失函数以及感知损失函数。对抗损失函数是生成对抗网络框架下的基本损失函数,控制生成器和判别器对抗训练。平滑L1损失函数用于控制生成出的图像尽量接近想要的目标图像。感知损失函数可以帮助生成器生成皮肤纹理更接近的目标图像。
(1)对抗损失函数
网络结构中包含一个生成器一个判别器,生成器G输入有妆图像x,得到卸妆后图像G(x)。判别器需要将有妆图片x和卸妆后图片G(x)组成的样本识别为正样本;将有妆图片x和无妆图片y组成的样本识别为负样本。训练时生成器和判别器交替训练,相互对抗。该损失函数可表示为:

(2)L1损失函数
L1损失函数式用来表示生成图像G(x)和目标图像y之间的差距。使用L1损失函数,让生成器在保持该目标的身份信息的前提下生成去妆图像,L1损失函数可表示为:
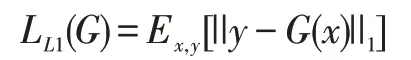
(3)感知损失函数
使用VGG16网络对生成图像G(x)和目标图像y进行特征提取,特征图记录着图像的纹理信息,生成图像G(x)和目标图像y经过第l层卷积得到特征图,分别记为F和P,再对F和P求Gram矩阵差的Froben⁃ius范数,最终生成风格纹理较为相近的图像。设置感知损失函数表示如下:

3 实验
为了验证本文方法的有效性,从定性和定量两个层面与其他图像转换方法进行对比。
本文使用了由Gu Q等人[11]制作的数据集中的一部分,包括134人,每人的25种妆容,一共4020张图片。为了更加贴近真实场景下的实际应用,在定性部分选用了从互联网收集的有妆人脸图片。定量部分使用了评价图片质量的两种指标峰值信噪比(PSNR)和结构相似性(SSIM)。
3.1 定性分析
首先实验从视觉角度,与Pix2Pix和CycleGAN进行对比进行定性分析。如图2所示,第一排是网络输入的有妆图像,是从网络中截取的真实场景下的有妆人脸图片,第二、三、四排分别是Pix2Pix和CycleGAN和本文方法得到的去妆图像。

图2 定性分析对比实验
通过对比观察,我们可以发现,Pix2Pix网络得到的去妆图像虽然有一定卸妆效果,但是眼周、嘴唇等部位较模糊,边缘不清晰,(e)、(f)、(g)等样本,皮肤也有斑纹,不真实。CycleGAN网络得到的图像虽然图像细节保持较好,但是卸妆效果不佳,对于(a)、(b)这类眼影较重的样本,妆容不能完全去除,即使对(i)这类妆容较轻的样本,卸妆效果依旧不理想。相比之下本文结果卸妆效果较好,对于口红、眼影、粉底、眉毛等都有较好的卸妆能力,并且生成了较为清晰的边缘和细节,皮肤纹理真实自然。
3.2 定量分析
本文使用了两种常用的图像质量评估指标:峰值信噪比(PSNR)和结构相似性(SSIM)。PSNR是最普遍,使用最广泛的评价图像质量的客观指标,常用作测量图像压缩等领域中信号重建质量,值越大图片质量越好,相似度越高。SSIM从亮度、对比度和结构三个角度评价两张图的相似度,取值范围是-1到1之间,越接近1代表两张图片相似度越高。实验通过求生成模型生成的去妆图像与无妆图像之间的PSNR与SSIM值,从定量角度评价本文方法与Pix2Pix、CycleGAN的去妆效果。根据表1,可以看出本文方法的PSNR与SSIM值分别为28.487和0.905,显著高于另两种图像转换方法。

表1 定量分析对比试验
4 结语
针对现有方法在图像去妆容过程中纹理不真实和细节模糊的问题,提出了一种基于条件生成对抗网络的卸妆算法。该方法通过使用L1损失函数和感知损失函数,约束训练得到一个去妆生成模型。通过实验从定性和定量两个角度验证了相比其他图像转移算法,生成了具有真实纹理,细节清晰的去妆人脸。后续工作计划考虑到妆容对人脸识别算法的影响,改进该生成模型,目标是提升现有人脸识别算法对有妆人脸的识别率。
