基于Deep Lab V3+的手术器械语义分割算法
2021-07-02董沛君陶青川
董沛君,陶青川
(四川大学电子信息学院,成都610065)
0 引言
手术器械是医生在外科手术中为患者进行治疗的必备工具,不仅被要求性能良好,其准确性和完整性更是确保一台手术安全顺利进行的关键因素之一。一直以来,手术器械的管理都是医院医疗器械规范化管理中的一项重要工作,其中,手术器械的包装检查更是手术器械管理中的关键步骤,该步骤保证器械在经过灭菌处理程序后到正式被用到手术过程之前保持无菌性,且确保包装中的器械满足手术所需的准确性和完整性。手术器械的管理工作在医院一般都由专门部门负责,这项工作长期以来都是由人工完成的,手术器械种类繁多,部分器械相似度较高,所以该工作工作量大且重复性高,造成大量人力浪费,且极易造成漏检和错误分类的情况。
随着人工智能的发展与应用越来越广泛,更多的研究者开始关注手术器械的检测分类问题,希望由机器代替人类完成这项工作,降低人工成本的同时达到高效准确的效果。近年来,图像目标识别、检测和分类技术在科研活动和实际生产中也得到了越来越广泛的应用,大大节约了人力成本,提高了生产效率。陆续有很多学者将深度学习应用到医疗健康领域的研究应用中,如郑欣、田博等人将图像分割算法应用到宫颈细胞簇团检测中[1],张冠宏等人将图像分割算法应用到视网膜血管分割任务上[2],杨凯等人也将图像分割算法应用于细胞核分割的研究中[3],深度学习的加入,使诊断效率和准确率得到了大幅提升,加快了医疗健康领域的发展步伐。但是在医疗器械工具方面,目前人工智能的应用和发展还比较缓慢。在对手术器械进行装包的时候,常将其置于颜色极其相近的包装盒中,在研究手术器械智能化管理的过程中发现,这样会加大器械的分割识别难度,另外,现实环境中光照不均和阴影遮挡等因素的存在,也会对识别结果产生严重干扰,因此,手术器械包装管理自动化的实现难度较大。
为了解决上述问题,本文提出了一种基于Deep⁃Lab V3+网络模型[4]的深度学习卷积神经网络分割识别算法,对原DeepLab V3+网络进行优化改进,实时分割相机拍摄到的图片,进而实现对手术器械高效准确的自动分割识别,满足需求的同时降低医疗成本。
1 基于改进Deep Lab V3+的手术器械分割算法
1.1 算法流程
本文手术器械分割识别算法主要是在DeepLab V3+网络的基础上进行改进后实现的。首先使用平台上安装的工业相机采集不同背景下的手术器械图片,用labelme对图像中的器械进行标记,制作成满足训练条件的样本标签并建立数据集,然后修改网络参数,将数据集放到网络中进行训练,当训练到一定步数时,观察损失值的变化,当其收敛到一定程度时,结束训练。最后,用平台上的相机随机拍摄台面上的器械得到RGB图像,输入训练好的网络模型对其进行分割识别,看是否能达到预想的分割结果。
1.2 DeepLab V3+网络结构概述
由Google团队开发的DeepLab系列网络框架,是目前语义分割任务中应用最为广泛的网络模型,该系列网络大大提升了模型在语义分割任务上的性能,使语义分割在科研和生产中得到更加广泛的应用,提升了检测识别的精度和效率。其中DeepLab V3+是一种用于语义分割的典型网络框架,该网络在DeepLab V1、V2及V3系列[5-7]之后提出,结合了前DeepLab系列及SegNet和PSPNet等网络的特点,并采取了新的改进措施,在语义分割任务中取得了较好的表现。
DeepLab V3中引入了图像级别的带膨胀卷积的空间金字塔池化层,通过在不同膨胀率上进行池化操作来获取更加详细的上下文信息。但是这样的操作并不能充分恢复下采样的过程中损失的细节信息,会使分割结果边缘模糊,不够精确。所以,DeepLab V3+则在DeepLab V3的基础上添加了解码模块[8],构建了一个带有空洞卷积的空间金字塔池化编码-解码结构,其网络模型结构如图1所示。DeepLab V3+的编解码结构可以恢复图片的原始分辨率,从而有效解决了DeepLab V3仅通过采样恢复特征图时导致细节信息丢失的问题,使得边缘细节信息能够较好地被保留,分割结果更加精确。同时基础网络也由DeepLab V3的ResNet101换成了Xception网络,加快了网络的计算速度,实现了准确率和运算时间的综合性能最优化[9]。
DeepLab V3+网络的整体编解码模型如图1所示,该网络的编码器部分由Xception和ASPP模块两部分组成,提取底层特征,其中Xception为提取特征骨干网,是由输入流、中间流和输出流组成的DCNN网络。ASPP则为含不同空洞卷积扩张率的多尺度金字塔特征提取模块,利用骨干网得到的高级语义特征图进行并行多尺度语义信息提取,生成多尺度特征图,在编码器尾部将多尺度的高级语义特征图在通道维度上进行组合,通过1×1的卷积进行通道降维[10]。DeepLab V3+的解码器部分采用的是级联解码器,而非一步到位。先用1×1的卷积核对编码过程中提取到的低层次的特征信息进行通道降维,以便其和编码器输出的特征图四倍上采样之后的通道数保持一致进行融合,然后将融合后的结果通过一个常规的3×3卷积来提取特征,最后经过一个四倍双线性插值上采样之后输出语义分割图。
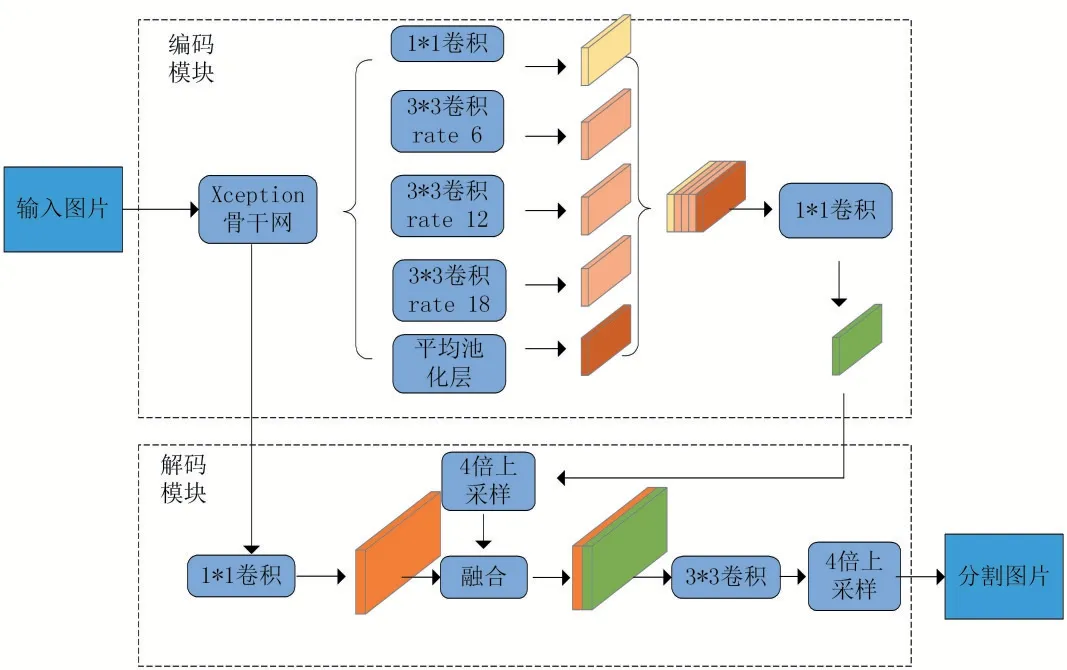
图1 DeepLab V3+编码-解码模型结构
1.3 改进的DeepLab V3+网络框架
然而,将手术器械数据集放在DeepLab V3+原网络中进行语义分割训练时,虽然能分割出手术器械的基本轮廓,但是在可视化结果图中可以看到,存在边缘不够平滑、细节不够清晰等问题,分割结果与器械的实图有较大出入,无法分辨形状相似的器械,对后面的模板匹配结果的精确度影响较大。分析实验过程可以知道,出现这种情况是因为在编码时,卷积下采样过程中存在图像的有用信息丢失的情况,如一些边缘的点、线、角度等细节信息,导致了内部数据结构丢失和空间层级化信息丢失,且这种操作导致的信息丢失是不可逆的。经过卷积次数越多,得到的特征图就越抽象,在解码的上采样过程中,双线性插值上采样方法只能将图像平滑放大,并不能增加图像信息,并不能恢复下采样过程中的损失。
在整个手术器械识别过程中,语义分割后的结果要用于与平台拍摄的RGB图像进行比对裁剪,然后进行模板匹配识别。该过程对实时性要求较高,语义分割的速度要能实时跟上图片的拍摄速度,但是Deep⁃Lab V3+网络的实时性达不到系统要求,导致模板匹配速率慢,工作效率低下。
故为了提高网络在手术器械数据集上的语义分割性能,实现分割精确度与分割速率的双重提高,本文对DeepLab V3+网络框架做了以下改进。
1.3.1 将ASPP模块中的3×3空洞卷积进行2D分解
在编码端,ASPP模块利用骨干网得到的高级语义特征图以不同扩张率的空洞卷积进行并行多尺度采样,生成多尺度特征图。在这个过程中,ASPP模块的3×3卷积会学到一些冗余信息,且参数数量较多,在训练中造成资源浪费,增加计算成本。本文将3×3的卷积分解成3×1和1×3的卷积,如图2所示,保持其空洞率不变,改进后的卷积参数量比原本的3×3卷积减少了33.33%,从而大大减少了计算量,在保证提取有效语义信息的同时提高了运算速率。

图2 改进后的ASPP模块
1.3.2 使用深度可分离卷积替换普通卷积
本文在解码器部分,采用3层深度可分离卷积替换原本的普通3×3卷积,对深度信息和空间信息去耦,以逐步获取精细的分割结果[11]。
深度可分离卷积将原始卷积拆分为逐通道卷积和逐点卷积两部分[12]。逐通道卷积的一个卷积核只负责一个通道,一个通道也只被一个卷积核卷积,逐通道卷积完全是在二维平面内进行的,卷积核的数量与上一层的通道数相同。逐点卷积的运算则与常规卷积运算类似,其卷积核尺寸为1×1×M(M为上一层的通道数),逐点卷积是将上一步得到的多个特征图在深度方向上进行加权组合,生成新的特征图。
与传统卷积相比,深度可分离卷积将深度信息和空间信息进行拆分处理[13],并且融合了不同尺度的底层特征信息,实现了对空间信息和深度信息的去耦,相较于普通卷积,深度可分离卷积对每个通道使用不同的卷积核,对每一个通道的特征都进行了学习,得到的特征信息更全面,保留了更多重要边缘特征信息,有效减少了上采样过程中的信息丢失,提高了分割预测结果精确度。此外,深度可分离卷积与普通卷积相比,参数数量也大量减少,进一步减少冗余计算,提高运算速率。
2 实验与分析
2.1 制作数据集
在本次实验中,由于网上没有公开的符合实验要求的手术器械图像数据集,因此需要实验人员自己拍摄制作数据集。我们使用搭建的平台上安装的工业相机从成90°角度的两个方向拍摄手术包装盒里的手术器械,然后用Photoshop对图像中的器械进行标记提取得到二值图,再编写程序对图像中手术器械部分的灰度值进行修改制作成满足训练条件的样本标签并建立数据集。未来增强算法的泛化能力,使分割结果更加精确,实验中图片的拍摄是在不同背景和光照条件下进行的,而且为了防止因为样本单一导致过拟合问题,本实验采取了旋转、翻转等方法对数据集进行了扩充。本文中的数据集总共包括1500张图片,其中随机抽取1300张作为训练集,200张作为验证集。
2.2 分割性能评价指标
我们在对语义分割结果进行评价的时候,有一些常用的评价指标,主要包括均交并比(Mean Intersec⁃tion over Union,MIoU)、像素精度(Pixcal Accuracy,PA)、召回率(Recall)和运行时间,通过这些数值我们可以更直观地对语义分割性能进行评估。
IoU(Intersection over Union)是模型所预测的目标区域与标注数据集中所标注的真实区域的交并比,MIoU则是计算不同类别的IoU然后加权求平均得到,计算方法如下所示。
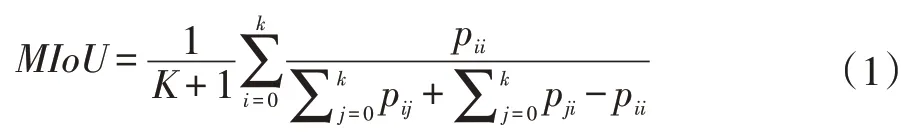
式中:pii表示真实值为i,被预测为i的数量;pij表示真实值为i,被预测为j的数量;p ji表示真实值为j,被预测为i的数量;K表示除背景外的样本种类数量。
PA为分类预测正确的像素点数占像素点总数的比例,计算方法如下所示。

Recall是所有被正确预测为正样本的样本数量与真实的正样本的总数量的比值,计算方法如下所示。

理想情况下,像素精度和召回率都是越高,说明分割效果越好,但是像素精度和召回率是成负相关的,二者相互制约。所以为了找到二者的最佳组合,我们引入F值对像素精度和召回率进行调和平均,计算方法如下所示。

算法的运行时间也是我们衡量其分割性能的一项重要指标,本文中指的是计算机处理一批(batchsize=8)图片所需要的时间。
2.3 实验结果与分析
2.3.1 实验参数设置
本文的分割数据集是自己制作的手术器械图片数据集,硬件配置采用GPU显卡为NVIDIA GTX 1080TI,内存8GB,Intel Core i5-6500处理器;实验在Tensor⁃Flow 1.11.0,Python 3.6,Win10环境下进行。学习率设置为0.001,batchsize设置为8,训练步长为5万步。
2.3.2 分割性能对比
分别用改进后的DeepLab V3+网络和原本的Dee⁃pLab V3+网络训练自己制作的数据集,随机拍摄4张图片在两个模型上进行测试,可视化对比结果如图3所示。从图3可以看出,改进后的网络保留了更多的边缘信息,细节清晰,分割效果更好。

图3 算法效果图对比
此外,本文还从通过MIoU、PA、Recall、F值和运行时间等数值定量对改进后的DeepLab V3+网络和原网络进行了对比,对比结果如表1所示。从表中可以看出,本文的语义分割算法要明显优于原本的DeepLab V3+网络,可以在高准确率的前提下达到实时分割识别的目的,更加符合系统的实用要求。

表1 算法性能对比
3 结语
本文提出了一种基于改进DeepLab V3+网络的手术器械分割识别算法。将ASPP模块中的3×3空洞卷积进行2D分解,减少了参数数量,并且在解码端使用深度可分离卷积替换普通卷积,提升分割精确度的同时也提高了处理速度。将训练结果应用到手术器械识别系统中,通过实验可以看到,识别准确率很高,实用性较强,满足系统的设计要求。
本文的语义分割模型兼顾了分割准确率和分割速率,但是本文算法对图片中手术器械的完整性要求较高,当目标有遮挡,或多个目标重叠时,无法完成正确的分割识别,因此,通过局部特征实现对手术器械的分割识别,是以后研究的重要方向。
