零样本学习综述
2021-07-02欧光金
欧光金
(西南大学计算机与信息科学学院,重庆400715)
1 零样本学习概述
近年来监督学习取得了显著进步,监督学习的应用也随处可见。加之得益于深度学习的快速发展,监督学习的性能也得到很大提升。然而监督学习存在一些缺陷,需要足够样本,且学到的分类器只包含训练过程中出现过的类别,对从未见过的类别就无能为力。然而在实际应用中,许多类没有对应的标注样本参与训练,而人们需要确定这些测试样本是属于哪一类别。为了解决这一问题,零样本学习应运而生,其目的是对不可见类的样本进行识别和分类[1]。


定义1(零样本学习)给定属于可见类S的训练样本Dtr,零样本学习旨在学得一个分类器f(.):X→U,即可以预测测试样本Xte属于不可见类集合U的哪一类。
从定义1可以看出,零样本学习的思路是将可见类中学到的知识转移到不可见类中,以此实现分类任务,因此零样本学习是一种特殊的迁移学习[2]。迁移学习将源域的知识转移到目标域,而辅助信息是不可见类和可见类之间的桥梁。辅助信息通常具有辨别性,能保留每个类别的特性,且与样本相关联,保证辅助信息是有效的。受人类认识世界的模式启发,例如通过“斑马像马且有条纹”的描述,幼童可以识别出斑马,即使他们以前从来没见过。可见类和不可见类的语义信息组成语义空间,该空间为实数空间。在语义空间中,每个类都由一个特定的向量表示,该表示称为类别原型。根据零样本学习中使用数据的不同,可以将零样本学习分为直推式和归纳式两类。
定义2(直推式零样本学习)只利用带标记的可见类样本进行模型训练。
定义3(归纳式零样本学习)利用带标记的可见类样本以及不带标记的不可见类的样本进行模型训练。
2 语义空间
语义空间作为零样本学习的关键,有助于知识从可见类到不可见类的迁移。根据语义空间的构造方式,可以将已有工作中使用的语义空间分为人为语义空间和学习语义空间两种。
2.1 人为语义空间
人为语义空间中的每个维度都是人工定义的。接下来,对几种典型的人为语义空间进行介绍。
属性空间:属性空间由属性构成,在零样本学习任务中使用最多。在属性空间中,每个属性是与类的一个特性相对应的单词或短语。所有类的所有属性形成语义空间。类原型的每个维度用二进制值或实数值来表示该类是否含有对应的属性。例如我们有属性集{“四条腿”、“有尾巴”和“哺乳动物”},那么“青蛙”对应的属性为[1,0,0],而马对应的属性为[1,1,1]。
词空间:词空间由一组词组成,该空间利用类和数据集的标记来提供语义信息。数据库是结构化的词数据库(如WordNet),将其作为数据源或者利用其中的层次关系可以构建不同的语义空间。另外,词数据库中类之间的距离(如Jiang-Conrath距离、Lin距离)或相似度也可以用来构建语义空间。
文本-关键字空间:通过每个类的文本描述中的关键字组成。文本描述可以从预定义的网站(例如Wiki⁃pedia)获得,也可以从搜索引擎描述每个类的Web页面获得。
人为语义空间能够灵活地使用领域知识,但语义空间和类原型十分耗费人力。
2.2 学习语义空间
学习语义空间中的维度不是人工定义的,每个类别原型都是以机器学习的方式获取的。这些机器学习模型通常是从其他任务中预训练得到或从零样本学习中专门训练得到。下面介绍几种常见的学习语义空间。
标记嵌入空间:类别原型的语义空间是通过标记嵌入得到的。随着词嵌入技术在NLP领域的发展,引入标记嵌入空间。词向量在嵌入过程中被映射到实数空间中成为类别原型,该实数空间中包含着类别的语义信息。语义相近的词在迁入后距离相近,反之较远。
文本嵌入空间:类别原型的语义空间是从类别的文本嵌入得到的,即该空间语义信息从文本描述中获取。通过将类的文本描述输入到预训练模型,而模型输出即为类别的原型。
图片特征空间:类别原型的语义空间是从样本中提取的。通常将属于同一类别的图像输入到一个预训练的模型,将模型输出组合为一个向量表示作为该类的原型。
学习语义空间的原型的生成不需要人力参与且能够包含更多的信息,但通常需要借助一些机器学习模型得到。另外,获取到的类别原型的每个维度没有明显含义。
3 零样本学习方法
根据类别原型嵌入方式的区别,我们将已有的零样本学习方法分为四类。
3.1 贝叶斯模型

通过该推理框架,给定一个测试图片特征,可以通过上面的乘法得到每个样本属于某不可见类的概率。在这项开创性的工作之后,很多工作在DAP的基础上做了改进。一些方法侧重于提高属性分类器的分类能力,而另一些则侧重于修改推理框架。
3.2 语义嵌入
语义嵌入是寻找视觉空间到语义空间的映射。例如,属性标签嵌入(ALE)[4]提出了一种双线性得分函数去连接视觉特征和语义特征,如式(2)所示。

其中θ(x)和φ(y)分别是图片特征和类别语义特征,W是所学的参数矩阵。通过最小化标签和图像嵌入之间的损失函数,将零样本学习问题转化为标签嵌入问题。给定输入图片,兼容性得分函数可以预测与图片得分最高的类作为预测标记。Kodirov等人提出了基于语义自编码器的方法(SAE)[5],通过在视觉特征表示上添加重构约束,可以有效解决投影漂移问题。
3.3 公共空间嵌入
与上述语义嵌入方法不同,公共空间嵌入寻找一个公共的空间来学习视觉特征和语义空间之间的关系。结构化联合映射(SJE)[6]学习了一个包含多种语义(文本、属性和层次关系等)的公共空间,其损失函数受到结构化SVM的启发,将全部权重赋予排名靠前的列表,如式(3)所示。Romera和Li等人也提出了基于公共空间嵌入的方法。
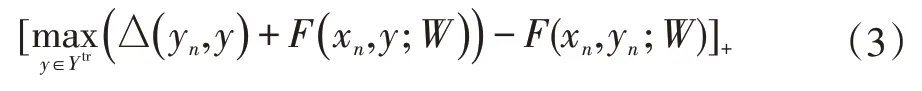
3.4 深度嵌入
可以通过深度方式学习非线性嵌入解决零样本学习问题。Frome等人提出的DeViSE方法,首次通过预先训练深层语言和视觉模型来解决零样本问题,其损失函数受到无正则化的排序SVM影响,如式(4)所示。
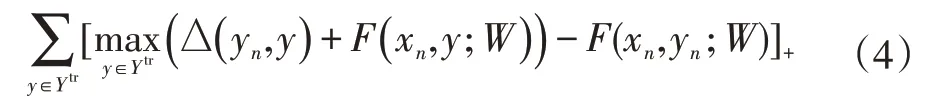
随后越来越多的深度学习方法(Norouzi、Wu等人)被提出用于解决零样本学习任务。
4 零样本学习应用
随着零样本学习方法的性能的提高,其在实际场景中的应用逐渐增多。
(1)计算机视觉。零样本学习最大的应用在于图像和视频的研究。零样本学习不仅可以完成分类任务,解决鸟类、花类等细粒度分类问题,还可以用于图像分割、图像检索和领域适应等问题。零样本学习也被用于研究视频相关的问题,它可以被用来识别未知动作和未知情感标签的视频。另外,零样本学习还用于动作定位、事件叙述和生成描述(文本)等任务。
(2)自然语言处理。近年来零样本学习在自然语言处理领域中也有一席之地。在罕见稀有语言的学习中,零样本学习有助于构建双语词典;在机器翻译问题中,零样本学习用于没有平行语料库的语言对中进行零样本翻译。此外零样本学习还被用于口语理解、语义话语分类。除以上之外,零样本学习还可以被用于网页实体抽取、细粒度命名实体类型、跨语言文档检索和关系抽取等自然语言处理相关问题。
(3)其他。除上述领域外,借助传感器,零样本学习可用来识别人类的活动;在计算生物学领域,零样本学习可以分析分子化合物的组成;在安全和隐私领域,零样本学习可以帮助发射机识别。
5 未来研究方向
目前零样本学习已应用在多个领域,我们对未来的研究方向进行了考虑:
(1)输入特征。现有的关于零样本学习的工作是适用于各个场景下的通用方法,并没有针对数据在不同应用中的特性进行建模。例如在图像识别中,除了考虑图像全局特征之外,一些局部的具有辨别性的特征可能会有助分类;再例如动作检测中的输入数据是多模态的,可以利用多模态方法进行建模。因此在未来的研究中,根据不同应用场景的输入数据的特征进行研究是大有益处的。
(2)训练数据的主动选择。现有的零样本学习方法大多处于可见类和不可见类相关联这一假设下,例如训练数据和测试数据都是关于动物的图像。而现实生活中数据的来源可能多种多样,存在一些噪声数据,应该考虑数据清洗的方法以处理实际情况中的复杂环境,主动学习可能是一个好的选择。
(3)开放设定。与传统零样本学习相比,在广义的零样本学习中,测试实例可以来自于可见类和不可见类。尽管这个设置更为实际,但仍不能满足实际生活中的复杂情况,例如训练过程中不断增加新的类别,以及少量可见类别和大量不可见类别的场景。我们需要在更为开放的设定下讨论零样本学习方法。
