基于模糊聚类分析的单词翻译缓存分区管理系统设计
2021-07-01许培红
许培红
基于模糊聚类分析的单词翻译缓存分区管理系统设计
许培红
(安徽职业技术学院 基础教学部,合肥 230001)
传统翻译缓存分区管理系统的翻译块miss率与异常指令定位时间均较高,导致缓存分区管理性能较差,因此设计一种基于模糊聚类分析的单词翻译缓存分区管理系统。在系统硬件设计中主要集成了内容寻址存储器,为数据存储提供空间以及翻译缓存包分区提供地址搜索上的便利;在软件设计中,使用模糊聚类算法完成数据挖掘算法的优化,并详细设计了模糊聚类算法的执行流程,建立单词翻译缓存分区管理模型,将缓存空间划分出子区域,实现二级管理,完成系统设计。系统性能测试结果表明,本文系统与传统系统相比,miss率与异常指令定位时间均能保持在较低水平,实际应用效果好。
模糊聚类分析;单词翻译;缓存;分区管理
在目前各类翻译器中,都离不开翻译缓存分析与管理系统。该系统的主要作用就是将指令集体系结构中的代码转换到另一种ISA上执行[1-2]。翻译器作为基础单元,以基本块的形式对单词进行翻译,形成对应的目标语言代码块。为了提高翻译器的工作效率,翻译缓存分区管理系统需要花费巨大代价得到的翻译块进行存储以便下次使用[3]。在系统对翻译块进行分区时,原有的系统中采用的是典型聚类算法,会定期清空翻译缓存,出现缓存碎片,再加上时间的复杂度比较高,导致缓存分区管理的性能较差,因此,本文设计一种基于模糊聚类分析的单词翻译缓存分区管理系统。
1 单词翻译缓存分区管理系统设计
1.1 硬件设计
在本文设计的分区管理系统中,存储技术是系统运行的根本保障。在硬件设计中首先集成内容寻址存储器,它是在传统存储技术的基础上,来实现联想记忆[4-5]。内容寻址存储器中具有数量较多的存储单元,可以给数据存储提供空间,数据被存储在某个特定的单元位置内,当前位置可以通过存储的数据内容被搜索到,得到数据的存储地址[6]。存储器内配备了一个硬件时钟周期,在这一个周期内,能够完成一次关键字精确匹配,如图1所示。
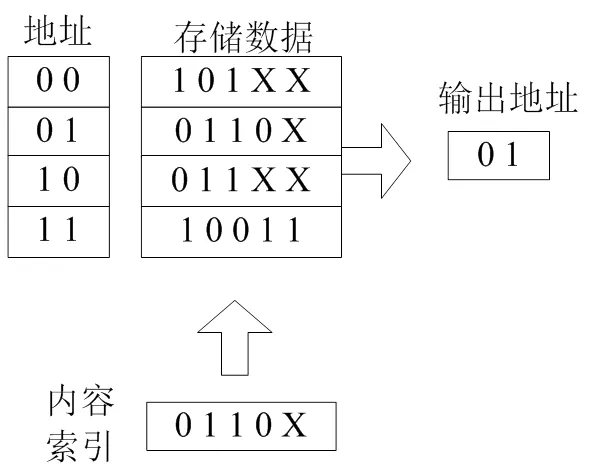
图1 内容寻址存储器工作示意图
在存储器中输入关键字内容,将输入的关键字与存储器中的所有的表项内容进行比较,最后在存储器相对应的地址中返回所有匹配的表项[7]。在所返回的地址中,会在一个相关联的表中完成寻址和分区,返回相对应的内容。在内容寻址存储器中,各个单元的比特位只有两种显示状态,即“0”和“1”,用来反映“匹配”和“不匹配”两种状态,因此,内容寻址存储器可以实现精准的匹配查找[8]。在单词翻译缓存包的分区等网络数据的通信应用场合中,需要将缓存地址和其他域进行比较以实现区分。翻译缓存地址一般会作为子网地址或前缀地址,前缀地址的长度也叫比特位长度。在分类应用子集中,主要是所匹配到的前缀是具有最大前缀长度的。如果存在多余的翻译缓存包,则需要对其进行分类处理。为满足最长前缀匹配规则,保证网络传输过程中每一种可能的地址前缀长度都能够配备单独的查找匹配芯片,在芯片中都需要保留统一长度的翻译缓存前缀的集合[9]。前缀长度有多少种,就需要配备多少块存储器芯片。至此完成系统硬件设计。
1.2 优化分区聚类算法

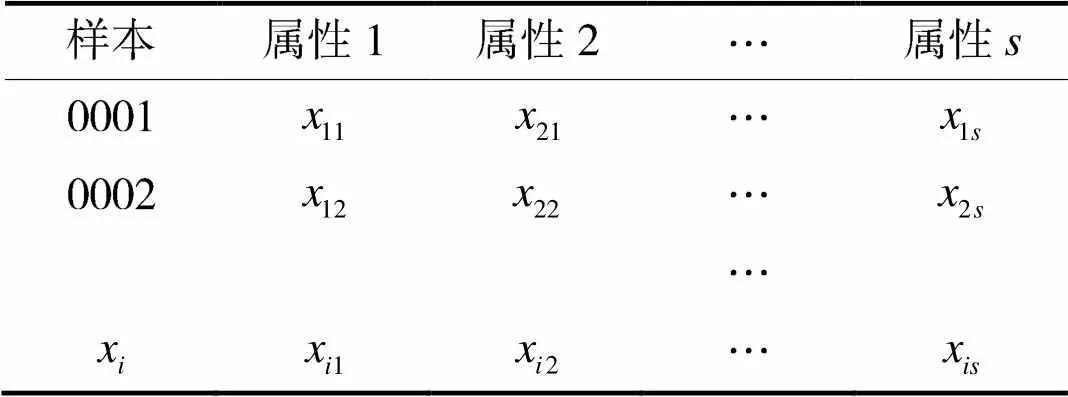
表1 待聚类的样本数据集

表2 待聚类样本的隶属度矩阵
以上述分析为基础,必须从诸多可能性的簇类中寻找出较为合理聚类划分结果,所以要建立隔离的模糊聚类目标准则和相关函数:


在上述条件下,使用拉格朗日乘数法进行求解,得到的最优模糊聚类分析矩阵为
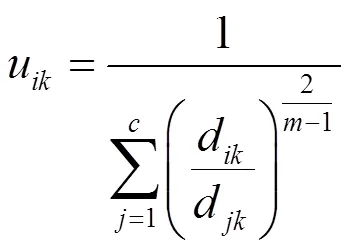
得到的聚类中心可以表示为
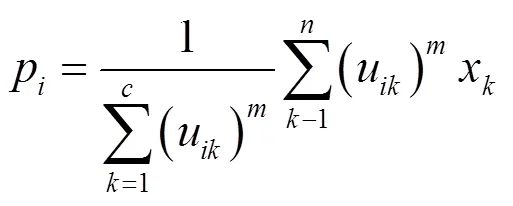

图2 模糊聚类算法流程
图2的流程中,从加载好的所有待聚类的数据集中设置相应的参数,计算中心距离和隶属度并分配给相应簇,完成模糊聚类的优化。
1.3 实现单词翻译缓存的分区管理
由于系统翻译缓存的容量有限,在翻译过程中生成的代码块会在一定时间内填满翻译缓存,在这种情况下,需要移除一定数量的翻译块,以此为翻译缓存腾出一定空间,最理想的移除目标就是以后不会再使用或未来最长时间不会再使用的翻译块。原有的系统就是将这样的翻译块进行移除,但是会持续产生缓存碎片。为解决该问题,本文主要将整个翻译缓存空间划分为若干相等的子区域,翻译缓存空间划分成8或16个子区域,从子区域释放出的TB可以实现2级管理,也就是子区域内部和外部的管理。分区管理模型如图3所示。
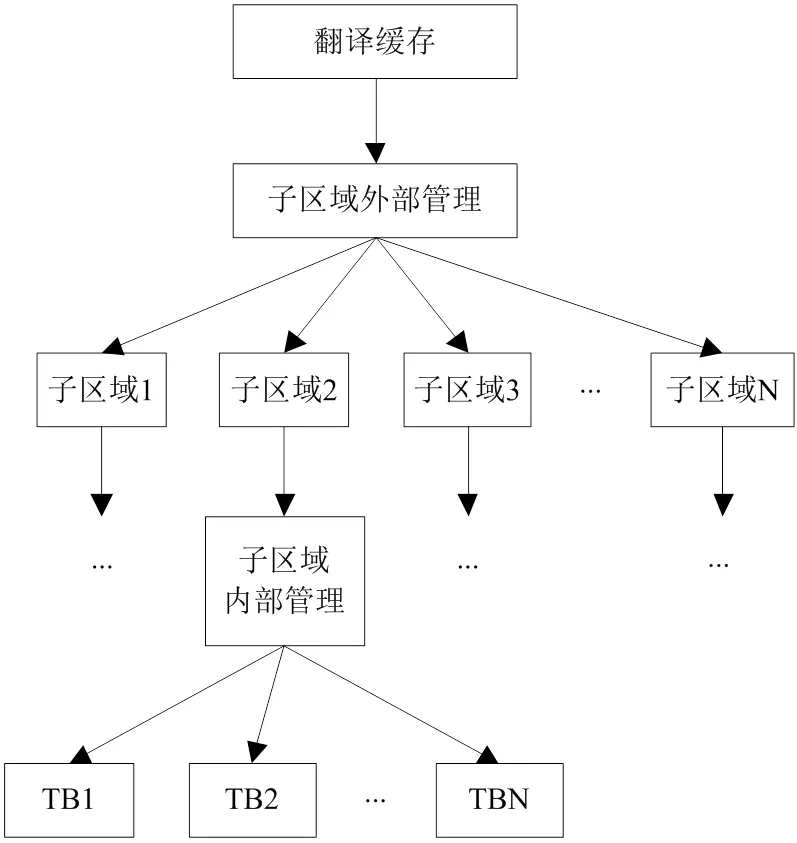
图3 分区管理模型
翻译缓存中的子区域位置都是固定的,且其大小也相等,外部的管理策略不会使其内部产生缓存碎片。再加上子区域的数量较少,能够提供动态二进制的翻译系统与翻译缓存的交互。
至此完成基于模糊聚类分析的单词翻译缓存分区管理系统设计。
2 系统性能测试
2.1 搭建系统测试平台
为了验证本文设计的基于模糊聚类分析的单词翻译缓存分区管理系统具有一定的有效性,本文使用通用验证方法学(UVM)作为验证环境开发库,将设计的系统搭载在该验证平台上。UVM验证平台的框架如图4所示。
对于翻译缓存的管理分区系统来说,其性能可以通过翻译块的miss率以及分区异常指令定位的效率这两方面进行评判。在上述的验证平台中实验了基于模糊聚类分析的缓存分区,根据目标代码块的生成频率,完成翻译集分区管理变迁的探测。图5是本次系统性能测试中用来探测翻译集分区管理变迁算法的状态图。

图4 典型的UVM验证平台构造

图5 探测翻译集变迁的算法示意图
根据目标翻译块的生成频率特征,在性能测试的过程中设阈值l为60%,设阈值2为40%。在统计生成频率时采用profile,目标代码块加入了一条用于统计生成频率的语句。程序刚开始运行处于S1,一旦生成频率大于阈值1,此时则会立即进入S2,则说明工作集正在构建。此时如果探测到生成频率小于阈值2,那么进入S3,表示工作集已构建完成。在S3一旦探测到生成频率大于阈值1,表示开始了新的工作集的构建,就立即全清空翻译缓存,将之前的工作集从翻译缓存中清空。
系统性能测试过程中主要对比传统的分区管理系统与本文设计的分析管理系统的miss率与分区异常指令定位的效率,观测两种系统翻译缓存分区管理策略在保存翻译成果方面的能力,并对测试结果进行分析。
2.2 测试结果与分析
将UVM验证平台中翻译缓存分别使用两种系统分别进行管理,并在此基础上对翻译块的miss率进行统计,实验结果如表3所示。

表3 miss率对比
从表3可以看出,使用传统系统对单词翻译缓存分区管理时,会使miss率产生周期性波动,且波动的幅度较大,主要是由于每次缓存满时,传统系统都会清除所有的翻译块,清空操作发生后,系统内执行路径上的所有单词都需要被重新翻译,这个阶段便是miss率的高峰期;随着系统工作不断进行,缓存中翻译块数量的增加,miss率有逐渐降低,直至缓存再次被填满,再次被清空,因此出现了miss率的周期性较大波动。在本文系统开始工作后,在运行基本块数量在6000以下时,miss率的变化情况与传统系统相同,随着运行基本块数量的增加,本文系统仍然可以将miss率维持在一个恒定的较低水平;主要是因为本文设计的分区管理系统中,缓存空间的最大释放粒度是子区域,其他所有子区域的翻译块可继续使用,因此miss率不会突然间大幅上升,这种持续低的miss率,为系统获得持续较高的执行效率提供重要保证。
分区异常指令定位效率测试中,通过计时器测定定位时间,得到的测试结果如表4所示。
表4中的结果显示,传统系统的时间损耗远远超出本文系统。在异常发生的比较频繁时,传统系统会将整个单词块重新翻译,大大降低系统性能。综上所述,本文设计的基于模糊聚类分析的单词翻译缓存分区管理系统相对于传统系统来说,实用性更好。
在上述实验的基础上,比较当运行翻译块个数为16000情况下不同系统的单词翻译缓存分区管理耗时,结果如图6所示。
分析图6可知,传统系统的单词翻译缓存分区管理耗时在0~5.5s之间,本文系统的单词翻译缓存分区管理耗时始终低于0.9s,说明与传统系统相比,本文系统的管理耗时更短,管理效率更高。

表4 两系统分区异常指令定位时间

图6 两系统单词翻译缓存分区管理耗时
3 结束语
本文针对传统系统在工作过程中所存在的缺陷,设计了一种基于模糊聚类分析的单词翻译缓存分区管理系统,并从硬件和软件两方面进行详细的设计优化,最后通过实验结果表明,设计的系统在工作性能上更优。由于本文主要将模糊聚类分析技术应用在单词翻译缓存分区管理中,可以实现较大数据量下的系统性能保持,也是未来各类翻译器中必不可少的一项关键技术。
[1] 尹志强. 基于模糊聚类的图书馆电子资源的安全共享平台设计[J]. 科技通报,2018, 34(12): 181-185.
[2] 汪天宇,曹成茂,谢承健,等. 基于模糊聚类算法的山核桃壳仁分选系统设计[J]. 食品与机械,2018(6): 110-114, 157.
[3] 沈振辉,杨拴强. 基于模糊聚类及相关性分析的温度测点布置优化方法研究[J]. 现代制造工程,2018, 458(11): 118-124.
[4] 李慧琴,孙英,王俊洁. 基于模糊分区聚类的关联挖掘改进算法[J]. 微电子学与计算机,2018, 35(03): 130-134.
[5] 陈钟荣,洪滔. 基于Java和聚类分析移动端天气雷达管理系统设计[J]. 现代电子技术,2019, 42(02): 62-66.
[6] 范延芳,韦涌泉,王向晖. 基于多级队列缓存淘汰算法的处理器全数字仿真优化[J]. 计算机测量与控制,2018, 26(06): 188-191.
[7] 李男,庞建民,单征. 一种基于频度统计的动态二进制翻译优化方法[J]. 计算机工程与科学,2018, 280(04): 36-42.
[8] 吴灿强,芮晔,潘东梅. 基于YAFFS2文件系统的分区管理对载荷数据存储效率的研究[J]. 电子设计工程,2018, 26(23): 42-47.
[9] 张许诺,赵英,郭亮. 基于数据融合技术的松花江流域水生态功能分区[J]. 哈尔滨工业大学学报,2019, 51(8): 80-87.
[10] 马小博,王芳,程俊强. 基于安全分区操作系统的容错计算机软件架构[J]. 计算机测量与控制,2019, 27(12): 142-145.
[11]李晨来. 联想硬盘保护系统在公共机房管理中的应用[J]. 信息与电脑,2018(11): 105-107.
[12]蔺红,徐邦恩. 基于分段分区聚合近似和模糊聚类的风电出力特性分析[J]. 水力发电,2018, 44(12): 95-99.
[13]高金兰,康迪,雷星宇,等. 基于改进模糊聚类分析的电力系统不良数据辨识[J]. 电气自动化,2018, 40(05): 34-37, 54.
[14]陈希,范波,吴奇石. 基于模糊聚类分析的汽车配件库存分类研究[J]. 制造业自动化,2020, 42(03): 110-116.
[15]陈世超,杜太生,王素芬. 基于模糊c均值聚类法的玉米农田管理分区研究[J]. 农业机械学报,2019, 50(11): 293-300.
Design of word translation cache partition management system based on fuzzy clustering analysis
XU Pei-hong
(Basic Teaching Department, Anhui Vocational and Technical College, Hefei 230001, China)
Traditional translation cache partition management system has high translation block miss rate and abnormal instruction location time, which results in poor performance of cache partition management. Therefore, a word translation cache partition management system based on fuzzy clustering analysis is designed. In the hardware design of the system, the content addressing memory is mainly integrated to provide space for data storage and the convenience of address search in the partition of translation cache package. In the software design, the fuzzy clustering algorithm is used to optimize the data mining algorithm, and the implementation process of the fuzzy clustering algorithm is designed in detail, and the word translation cache partition management model is established to partition the cache space. The sub area is divided out to realize the secondary management and complete the system design. The system performance test results show that, compared with the traditional system, the miss rate and abnormal instruction location time can be kept at a lower level, and the actual application effect is good.
fuzzy clustering analysis;word translation;cache;partition management
2020-12-14
安徽省教育厅质量工程项目“教学资源库项目旅游英语专业教学资源库”(2019ZYK36);安徽省教育厅质量工程项目“大规模在线开放课程(MOOC)公共英语”(2018MOOC006)
许培红(1974-),女,安徽肥东人,讲师,硕士,主要从事大学英语教学与研究,xgyuhenanxc@163.com。
TP311.54
A
1007-984X(2021)05-0026-05
