基于孪生跟踪器的实时模板更新网络
2021-07-01张天宇
张天宇
(北京邮电大学人工智能学院,北京 100876)
1 引言
视觉目标跟踪(Visual Object Tracking, VOT)是指在一段视频序列的初始帧中给定目标的边界框信息,进而标定该目标在此视频序列所有后续帧中的精确位置,从而得到目标在视频中完整的运动轨迹。目标跟踪是计算机视觉的基本研究方向之一,应用范围十分广泛,包括视频监控、无人驾驶、人机交互和增强现实等。然而,由于视频亮度、目标变形、遮挡和快速运动而导致的频繁外观变化是目标跟踪任务一直面临的挑战。
现代跟踪器有两个分支:第一个分支基于相关滤波器,相关滤波利用循环相关的特征,通过傅里叶域来训练回归器,该回归器可以进行在线跟踪并有效地更新过滤器的权重,随着深度学习的发展,最近提出的基于相关滤波的方法也充分利用了深度特征来提高跟踪器的准确性;另一分支旨在通过利用深度学习来使模型获得强大的自主学习能力。具体来说,有两种基于深度学习的跟踪器:第一类是经过预训练的判别式分类器,通过区分前景(目标)和背景来对目标进行持续的跟踪,这种类型的跟踪器有效利用了图像中的背景信息,因此在多个公开测试集中表现出了具有竞争力的结果;第二类基于相似性匹配,此类型的跟踪器通过在模板框架和搜索框架中的候选区域之间执行互相关操作来获得得分图,得分最高的位置将被视为目标的当前位置。深度卷积神经网络通常利用Siamese结构来实现相似性学习,这种方法在为跟踪器提供出色计算效率的同时,又能使其保持具有竞争力的准确性。因此,在本文的实验工作中,将Siamese跟踪器视为ATUNet的基础跟踪器。
尽管Siamese结构已经很大程度地改善了跟踪器的性能,但仍然面临着以下问题。
1)在原始的Siamese跟踪器中,默认以视频序列第一帧中的目标外观作为跟踪任务的模板,该模板在整个跟踪任务中保持固定。然而,目标在一段视频序列中的外观特征通常会发生变化,无法实时对跟踪模板进行更新,极易导致目标丢失。
2)传统的模板更新策略主要是线性更新。采用线性更新的结果是,跟踪器对视频序列的每一帧所需的模板执行恒定的更新速率。显然,这与实际应用是不符的,因为目标外观的变化幅度在视频的每一帧中肯定是不同的。因此,线性更新机制很容易引起跟踪漂移的现象。
3)模板更新网络的结构不能太复杂,否则会影响Siamese跟踪器的实时性。因此,Siamese跟踪器需要在准确性和实时性之间达到一种最佳平衡。
为解决上述这些问题,本文提出了一种自适应模板更新网络(ATUNet),这项工作的主要贡献在于三方面。
1)自适应更新机制,突破跟踪器使用线性插值来更新每帧模板的限制,该网络分别将目标在第一帧的初始模板、在不同时刻的累积模板和预测模板作为帧间残差计算模块的输入,通过该模块计算相互之间的残差来得出当前帧实际所需的更新幅度,以此来自适应性地更新当前帧所需要的模板。
2)帧残差模块,旨在学习预测模板和初始模板之间的残差。初始模板可以为跟踪器提供高度可靠的原始目标特征,第5节的实验也表明,当帧间残差计算模块的跳连结构(Skip)与第一帧的初始模板连接时,模型的表现效果达到最佳。
3)N
步迭代训练,将网络的训练分为连续的N
个步骤,以迭代的方式完善ATUNet的性能,从而避免了烦琐且效率低下的训练过程。本文在实验部分(第 5节)中通过消融实验为步数N
选取了一个最优值。2 相关工作
本节简要介绍了Siamese跟踪框架以及现阶段的线性更新策略。
2.1 Siamese跟踪框架
最早的Siamese结构是Luca Bertinetto等人提出的全卷积孪生网络(SiamFC)。全卷积网络的优势在于它可以提供更大的搜索图像作为卷积网络的输入并计算模板之间的相似度。在SiamFC之后,出现了许多基于Siamese结构的改进跟踪器。DSiam设计了一个快速更新模块,该模块可以有效地利用前几帧来动态获取目标的外观变化和背景情况,从而在目标变形和背景混乱的情况下提高跟踪器的鲁棒性。SiamRPN在Siamese网络之后引入了区域生成网络,因此该网络可以基于分类和回归任务进行联合跟踪。DaSiamRPN在SiamRPN的基础上进行了数据增强,它不仅扩展了训练集的数量,而且还引入了带有语义信息的否定样本对,以增强跟踪器的判别能力。SiamDW在主干网络内部设计了残差单元,以允许在Siamese结构中应用更深更宽的神经网络。但是,基于Siamese的各种方法对于干扰因素的鲁棒性普遍较差,这也是一直未能克服的缺陷。
2.2 线性更新策略
在近两年所提出的跟踪方法中,在给定新数据样本的情况下,使用简单的平均策略更新对象外观模型。详细而言,网络将会采用一个固定的更新幅度对每一帧所需要的累积模板iT
~进行更新,权重随时间呈指数衰减。T
~可表示为式中,i
是帧的索引值;T
是仅使用当前帧计算得出的预测模板;T
~是上一帧的累积模板。假设目标的外观在连续的帧中平稳且连续地变化,则将更新率γ
设置为一个固定的小值(例如γ
=0.01)。在DCF跟踪器中,T
对应的是相关滤波器,而在Siamese跟踪器中,T
代表由全卷积特征提取器从特定帧中提取的目标模板特征图。尽管原始的SiamFC跟踪器不执行任何模型更新,但较新的Siamese跟踪器已采用式(1)来更新其目标模板。3 自适应模板更新网络
本节提出了一种可直接应用于Siamese跟踪器的自适应模板更新网络,如图1所示。

图1 自适应模板更新网络结构图
自适应模板更新网络的三项输入分别为一段视频序列中第一帧的初始模板、前一帧的累积模板以及当前帧的预测模板。三项输入完成级联操作后,经过一个残差计算单元来更新当前帧所需要的累计模板。上述过程可表示为
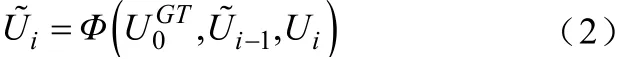
Φ
是残差计算函数。所学习的函数Φ
基于初始帧中提取的目标模板、上一帧的累积模板和当前帧的预测模板T
来计算更新后的累计模板。本质上,该函数通过集成当前帧U
给出的新信息来更新上一帧的累积模板。因此,Φ
可以基于当前模板和累积模板之间的差异来适应当前帧的特定更新需求。为提高Φ
对跟踪飘移的鲁棒性,还在每帧的更新过程中考虑了初始模板,可为模板更新提供高度可靠的原始目标特征。自适应模板更新网络的核心功能结构是帧间残差计算模块,其中包括两个组卷积层:一个通道混洗模块和一个跳连操作。组卷积层1用于提取输入信号的特征信息并完成降维,减少后续操作的参数量。通道混洗模块允许组卷积获得不同组的输入数据,从而使组卷积的输入和输出通道处于完全相关的状态。组卷积层2用于进一步提取图像的特征信息并完成升维,恢复图像信号的原始维度。
4 网络的训练
4.1 训练过程
从理论上讲,在训练过程中可以直接使用自适应模板更新网络输出的累加模板。但是,这将迫使训练重复进行,从而使该过程烦琐且效率低下。为避免这种情况,本文将训练过程分为连续的N
个步骤,以迭代地完善自适应模板更新网络。对于训练的第一步,在训练集上运行基于标准线性更新策略的跟踪器,以获取训练数据,包括要在下一步中使用的累积模板和预测模板。标准线性更新的计算方法为
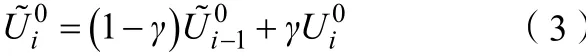
γ
是更新率。在实验中取γ
标准值(γ
= 0.01)。线性更新假定对象的外观特征在后续帧中平滑且固定地变化。对于第N
步训练,在前一步骤中获得的累积模板和预测模板均用于在当前步骤中训练自适应模板更新网络。可以将这种特定的实现形式表示为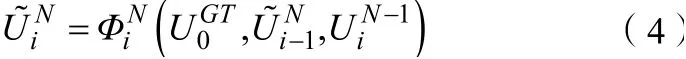
N
是训练的迭代次数。N
的最佳值需要通过实验确定,这将在后续的实验部分进行说明。4.2 训练集与实施细节
对于训练集的选择而言,由于LaSOT训练集数量众多,完全使用将消耗大量时间,并造成不必要的冗余。因此,本文从LaSOT的70个类别中随机选择30个类别,然后将每个类别中时间最长的视频序列添加到训练集中。实际上,自适应模板更新网络的训练集仅使用了包含30个随机选择类别的子序列。从大量实验中发现,附加数据只会给模板更新网络带来很小的性能提升,同时会增加网络模型的训练时间。
自适应模板更新网络由两个组卷积层、ReLU和通道混洗模块组成,其中第一个卷积层的尺寸为1×1×3C
×96×8,第二个卷积层的尺寸为1×1×96×C
×8。对于不同的Siamese跟踪器,C
的取值有所不同。当与SiamFC和SiamRPN连接时,H
=W
= 6并且C
= 256,而与SiamDW连接时,H
与W
的数值不变,C
=512。由于采用的训练方式为分布迭代训练,在第一步中,权重开始初始化,并且学习率在每个epoch从10到10呈对数递减。在下一步中,权重从上一步的最佳结果开始初始化,并且学习率在每个epoch从10到10呈对数递减。整个训练阶段使用大小为64的mini-batch训练50个epoch,并使用动量为0.9,权重衰减为0.000 5的随机梯度下降(SGD)。所有实验均在NVIDIA GTX 2080ti GPU上使用Pytorch 进行。5 实验结果与分析
为了获得更好的测试结果,本文选用了视觉目标跟踪(VOT)测试集中几个常用的版本:VOT2016,VOT2017和VOT2018。VOT系列测试集通过一种重置方法来评估跟踪器,只要跟踪器的结果与Ground Truth没有重叠,跟踪器将在五帧后重新初始化。VOT测试集的主要评估指标包括准确性(A)、鲁棒性(R)和预期平均重叠(EAO)。更好的跟踪器具有较高的A和EAO得分,但具有较低的R得分。
将本文所提出的自适应模板更新网络分别应用于SiamFC、SiamRPN和SiamDW跟踪器,在VOT2016和VOT2017上与主流的跟踪器进行了比较,结果见表1。
表1 自适应模板更新网络在VOT数据集上与其他跟踪器的比较
?
实验结果表明,本文所提出的自适应模板更新网络可以为多种Siamese跟踪器带来超过3%的性能提升,并有效提高了Siamese跟踪器对于复杂环境的鲁棒性。此外,还将自适应更新模板更新网络与应用线性更新策略的DSiam和MemTrack进行了对比,实验结果表明本文的更新策略比之前的线性更新策略更有效。
使用VOT2018数据集,并将SiamFC作为基础跟踪器来进行消融实验,结果见表2。将N
值固定,帧残差模块中的跳连(Skip)结构与相连时,自适应模板更新网络的性能最优。将Skip结构固定,当自适应模板更新网络迭代训练到第3步时,模型的效果最好。该实验同时表明,随着N
值的增加,网络的性能并不会越好。根据消融实验1所得到的结论,自适应模板更新网络在帧残差模块中的跳连(Skip)结构与相连,并且迭代训练到第3步时,取得的性能最好。相比于传统SiameseFC而言,ATUNet使其拥有了对环境杂乱、目标旋转及快速运动等干扰因素的鲁棒性。自适应模板更新网络测试效果图如图2所示。
表2 消融实验
?

图2 自适应模板更新网络测试效果图
6 结束语
现阶段基于Siamese结构的跟踪器大多数是以初始帧中的目标特征作为固定的相似度匹配模板,并且在整个跟踪过程中不会根据实时情况对模板进行在线更新。当目标在后续的视频帧中被部分遮挡、发生形变、快速运动以及所处背景变得杂乱时,Siamese跟踪器很难再对该目标进行精确的定位,极易出现跟踪漂移的情况。为解决上述问题,本文首先介绍了Siamese跟踪器中曾用到的线性模板更新策略以及组卷积的原理,然后提出了一种可直接应用于Siamese跟踪器的自适应模板更新网络,该网络将目标的初始模板、在不同时刻的累积模板和预测模板作为帧间残差计算模块的输入,通过计算相互之间的残差来适应当前帧所需的更新幅度,以此来更新当前帧所需要的模板。此外,为避免烦琐且效率低下的训练过程,在网络的训练阶段引入了一种N
步迭代训练方式。实验表明,在本文提出的自适应模板更新网络使Siamese跟踪器在VOT2016和VOT2017数据集上的表现都超过了自身原本的性能,这也证明所提出的自适应模板更新网络有效地预测了目标在每一帧中的变化。