基于OpenPose的摔倒行为检测技术研究
2021-06-30尹志成徐熙平孙也尧
尹志成,徐熙平,孙也尧
(长春理工大学 光电工程学院,长春 130022)
随着中国人口老龄化加剧,高龄人群的出行安全面临巨大挑战,有研究表明,约有28%至35%的65岁以上老人每年至少摔倒一次[1]。高龄人群在摔倒后,极易引发身体损伤,而长时间得不到救治的话,更会导致健康情况进一步恶化等后果。再加上由于青壮年的学习工作压力增加导致的注意力不集中、走路看手机等原因而引发的安全事故,研究一套智能的、行之有效的摔倒行为检测系统迫在眉睫。它对于提高我国的行人出行安全系数、稳定社会公共安全具有重大意义。
目前,主流的摔倒检测方法主要分为两种,一种是基于外部传感器的摔倒检测方法,该方法通常是将传感器放置在室内墙壁、顶棚、地板等环境或手表、衣物等随身穿戴的物品中,以便采集到人体运动数据[2],继而通过机器学习等算法对采集到的数据进行训练、分析,以达到检测摔倒的目的。一种是基于计算机视觉的摔倒检测方法,该方法则是通过对视频或图像进行特征提取,机械学习、深度学习等算法训练分析的目标为提取到的特征。
两种方法中,传感器的方法需要佩戴外部设备,存在适用范围窄、硬件成本高等问题。而现行的计算机视觉方法存在检测精度低、误检率高等问题。针对上述问题,提出了一种基于OpenPose和CNN的运动目标摔倒检测算法。并自建数据集完成检测实验及数据对比。
1 姿态特征提取
姿态提取作为行为识别的第一个步骤,其所提取到的特征将直接决定行为识别的准确度。OpenPose是学者 Cao等人[3]于 2017年提出的开源项目库,该项目库运用了现今较为流行的深度学习算法,能较为快速地识别图像中单人及多人的二维姿态,通过学习检测图像中人物的关键点位置,从而能够不依赖于图像中的局部特征完成人物目标检测,即使在图像噪声较大的条件下也可准确提取人物的关键点,然后使用建模重构的方式对学习检测到的像中人物关键点位置进行姿态特征的提取,能更有效地保证精度及连续性。
1.1 姿态提取算法流程
OpenPose方法的总体流程如图1所示,可概括为以下几步:
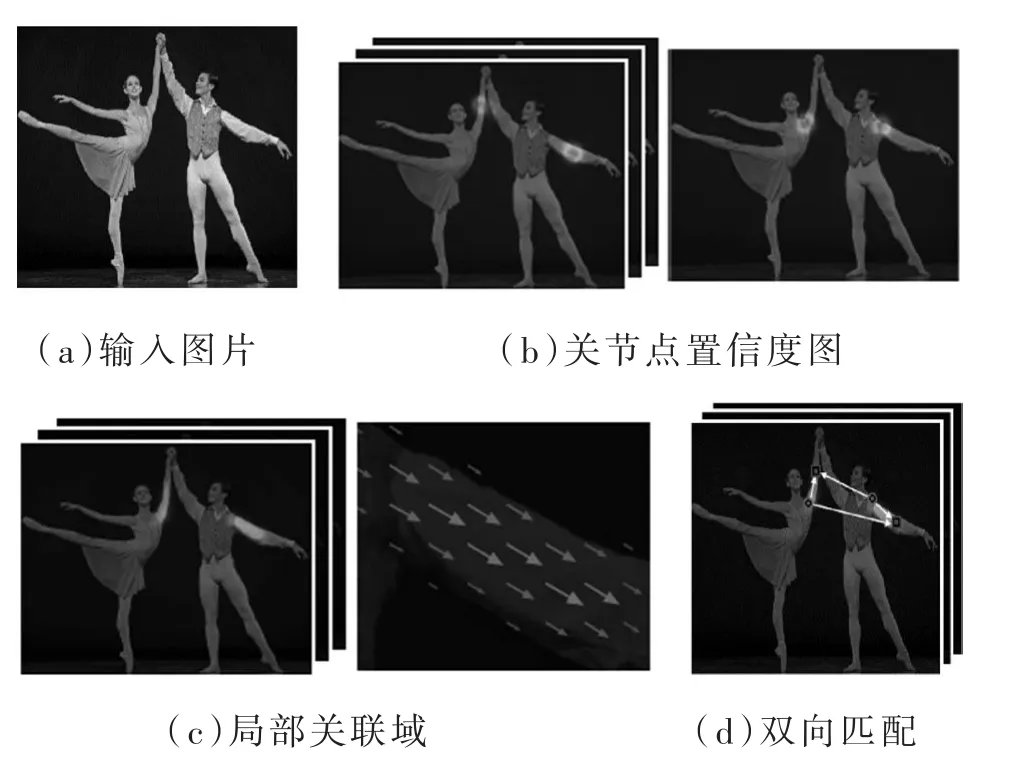
图1 OpenPose算法整体流程图
(a)输入一个w×h的彩色人物图像;
(b)前馈网络对检测目标的关键点位置进行预测,并得到其二维置信度映射S以及一组2D矢量向量场L;
(c)用S和L来编码检测目标各部间的关联向量场;
(d)通过置信度分析检测目标的亲和向量场,最终标示出所有检测目标的2D关键点。
其中:

表示需对每个关键点位置进行J次预测,有J个置信图。

表示每次预测对检测目标的每个肢体都会得到C个向量场。
1.2 OpenPose网络结构
OpenPose 的整体网络结构采用 VGG[4]网络作为骨架进行预训练处理。如图2所示,该网络分为两个部分,两部分能同时对提取到的关键点进行预测置信图、编码相邻关键点间的关联向量场并分别回归S和L。图中上半部分即第一分支用以预测置信图,下半部分即第二分支用以预测关联向量场。每回归一次S和L即为完成一轮迭代预测,通过连续的t∈( )1,…,T 轮迭代,就能形成整个预测网络体系结构。每一阶段统计一次反馈损失函数,并把S、L及F即原始输入连接起来,进而得到下一阶段预测训练的输入。在进行了n轮迭代之后,S能起到一定程度的区分预测网络体系左右结构的作用,迭代次数越多其区分程度越显著。
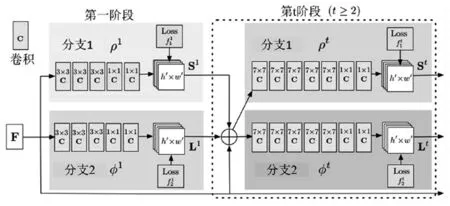
图2 OpenPose网络体系结构图
图中的F,即一、二分支初始阶段的输入,它是由CNN对原始图像进行分析所产生的一组映射;在网络的第一阶段预测训练时生成一组S1=ρ1(F)即置信度映射,和L1=φ1(F)即关联向量场。然后将S1、T1和F联接,以便使预测结果更加精细。进行到第t阶段时的预测结果可表示为:

式中,ρt、φt表示第t轮迭代的中间结果。
得到预测结果后,需要对每阶段的每个分支都计算一次损失函数,这是为了能够更有效地提高预测精度,引导OpenPose网络的体系结构。同时,考虑到实际问题中会存在某些检测目标的数据集未被完全标定等情况,因此还需要考虑损失函数的加权权重。式(5)、式(6)表示第t阶段时的损失函数:
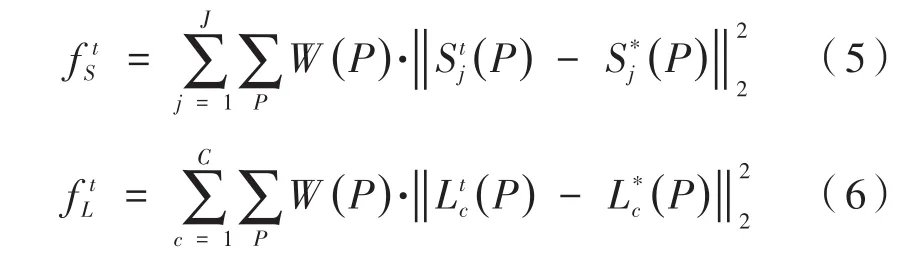
式中,表示真实的检测目标关键点置信度映射图;表示真实的关联域向量场;W表示一组用于避免惩罚训练时得到的真预测值的二进制掩码,即:当检测图像的p位置未被标定时,W(p)=0;当p位置被标定时,W(p) =1。
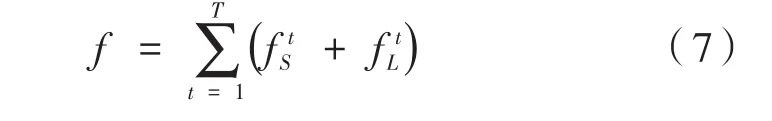
同时引入式(7)以规避神经网络中因梯度消失问题[5]而对预测结果造成的影响,在训练过程中的每个阶段周期性的补充梯度。
2 搭建姿态特征生成树
相对于以往的特征提取方法,提出了一种新的摔倒检测特征值,即完成对人体姿态特征的提取后,将目标人物的颈部位置,与脚部位置导出,计算二者之间的距离差值V;对视频每5帧提取一张图片,计算检测目标的高度,以提取图片的相邻两帧中检测目标的高度做差得参数D;此二者可用于判断静止姿态。根据提取图片中相邻两帧间检测目标的头部位置距离差值,计算检测目标的速度S,二轴加速度A用来判断运动姿态。
2.1 PAFs算法解析过程
借由非最大抑制算法,能够从网络的置信度映射图中得到一组候选的离散关键点位置。因为检测目标数目的不确定性,即可能有复数的检测目标,甚至是误检测关键点存在。因此,需要有多个候选区域来供每个关键点匹配,匹配得出很多的关键点对。如图3所示,图3(a)表示从检测目标中提取到的候选关键点,图3(b)表示各候选点匹配后得到的点对。
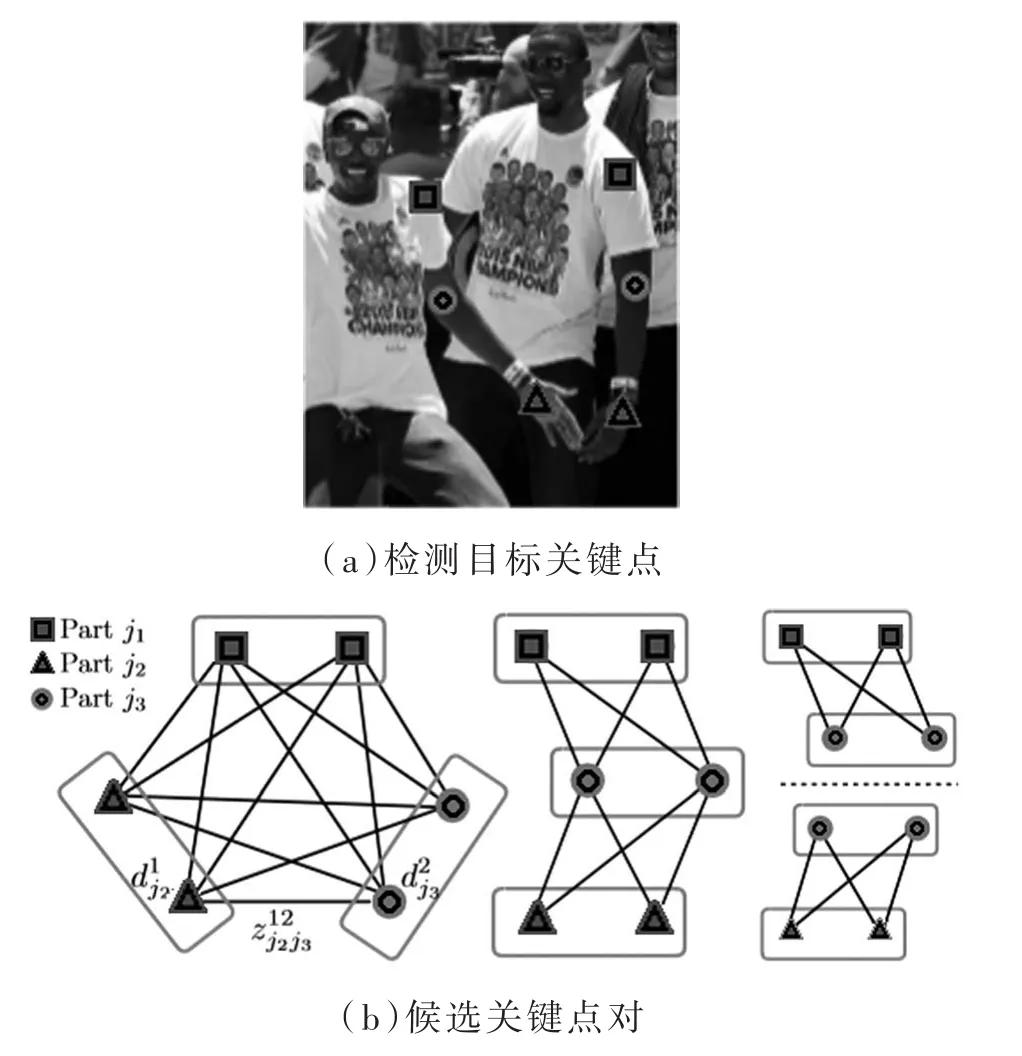
图3 候选关键点离散匹配图
然后,需要在所得匹配点对中找到最佳匹配结果,对每个匹配点对通过计算得到一个分数,可归结为一个NP-hard匹配问题[6]。下面将引出一种递归匹配算法解决此问题。
假定,通过网络置信度映射图中所得到的所有离散关键点构成的集合为DJ,如式(8)所示:
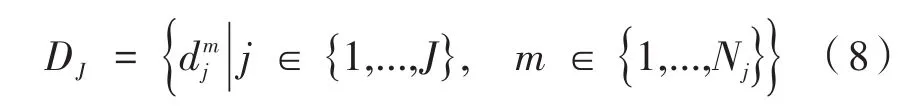
式中,Nj表示离散检测点j的候选位置数目;表示第j个离散点的第m个候选坐标。
将从属于同一个检测目标的离散检测点连成一体,即将其与同一检测目标的其他离散点相关联。为此,定义变量,用以判断两离散候选点是否从属于同一检测目标。即:当时,表示属于同一检测目标,可以相连,反之,则不能相连。进而得到式(9):
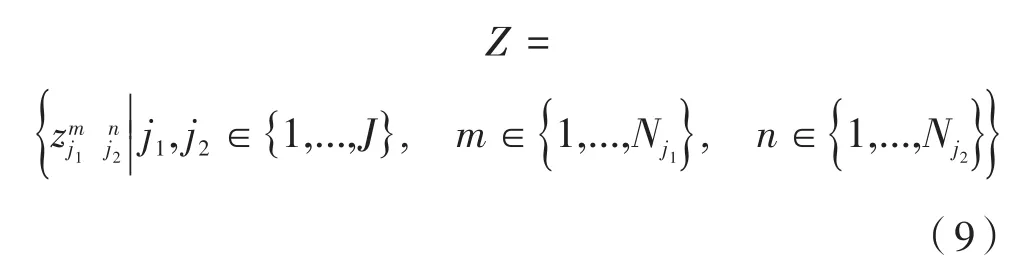
对于第c个检测目标单独区域(如躯干、左臂等部位),所需解决的问题就是找出一组权重最大的匹配点对。举例说明:对于第c个左臂,假定j1、j2为其上的检测点,则j1、j2对应的集合分别为,目标可以用式(10)代替:
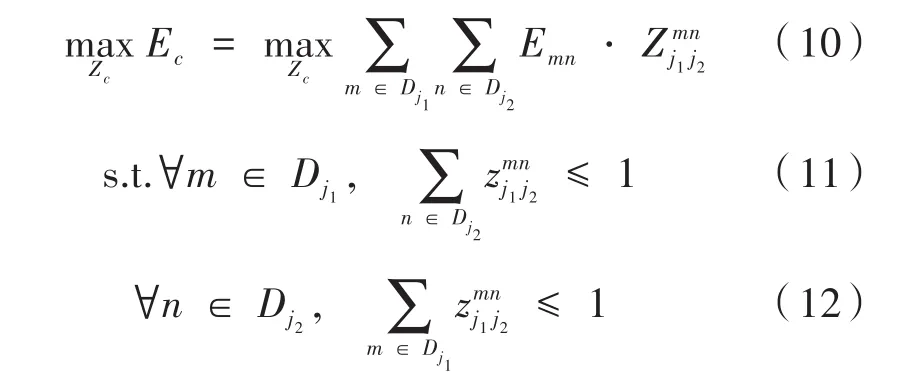
式中,Ec表示第c个左臂(躯干等单独区域)所对应的所有关键点匹配得权重总和;Zc表示左臂c对应于图片中含有的全部相同单独区域(左臂)Z的子集;Emn表示两个关键点间的关联向量场。
公式(11)和公式(12)强制要求任意两个相同类型的单独区域(如:两个左臂)不能共享一个关键点。即无法被连接到一个检测目标上。将其扩展到所有的C个单独区域Z上(左臂、躯干等),可得优化后的公式(13):
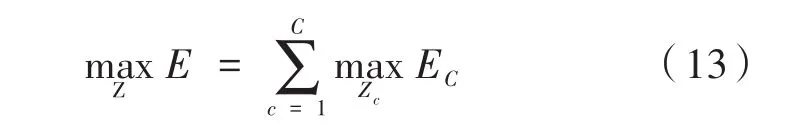
对每个单独区域重复公式(10)到(13)的步骤,可以获得检测目标包含的每种独立区域的所有关键点的最优匹配对,将从属于同一检测目标的关键点匹配对连接起来,就能组成一个完整的检测目标全身姿态。最终拼合成的全身姿态特征生成树如图4所示。
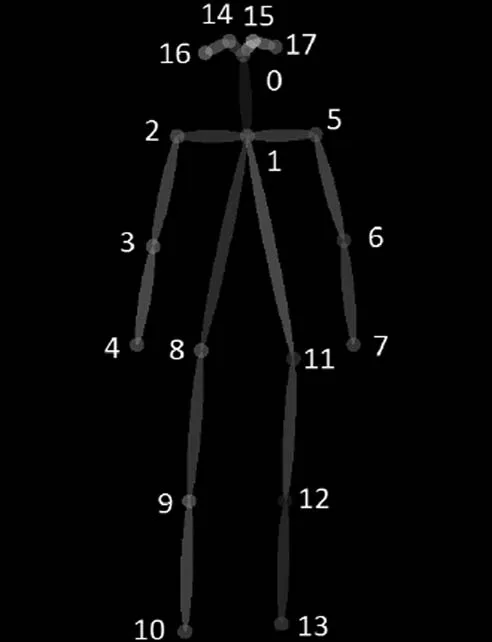
图4 全身姿态特征生成树
将图4所示的全身特征姿态生成树的关键位置检测点数据写入JSON格式文件,如图5所示。

图5 姿态关键点数据
图中,“pose_keypoints”即为当前帧中,检测目标的关键点数据,共计18个关键点。每个关键点信息由三个数据组成,形式为:( )x,y,score,其中,x、y即为关键点坐标,score则表示经过归一化处理后的预测评分,score∈( )0,1,其值越趋近于1,表示预测的准确性越高,同时关键点的预测置信度越高,生成树的组合度也就越好。
综合VGG预训练网络与PAFs匹配算法最终实现的姿态特征提取效果如图6所示。效果图中可以明显看到姿态特征生成树的线条及包括头、颈、肩、肘、手、膝、足等十八个检测关键点。
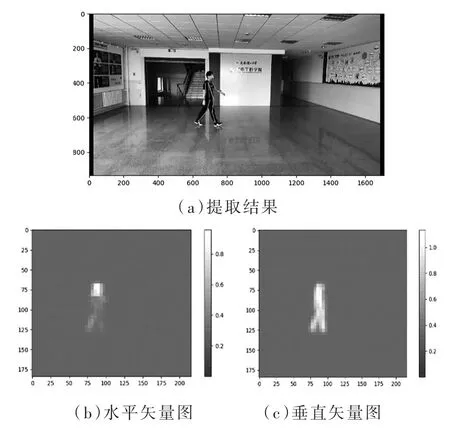
图6 姿态提取效果图
2.2 姿态特征计算方法
现行的基于视觉的摔倒检测算法中,更倾向于单独提取检测目标的静态特征或动态特征,这种提取单独特征的检测技术虽然能够较为快速的得到检测结果,但从动态角度判定时,由于快速下蹲和摔倒的质心率相近,所以难以区分两者的区别;从静态角度判断时,由于快速躺下和摔倒的姿态特征相近,同样难以区分二者。
同时提取静态特征与动态特征,提出一种综合了基于位置姿态特征的静态判别法和基于速度姿态信息的动态判别法的二次摔倒行为识别方法。
这种基于位置姿态特征的静态特征识别方法以颈部和脚部的高度差值以及间隔为10帧的前后两帧的颈部高度差作为判定参数,前者适用于识别正向的前摔、横摔;后者适用于侧向的前摔、横摔。同时引入基于速度姿态信息的运动姿态特征识别方法,该方法主要参考运动目标的颈部位置关键点坐标纵向帧间速度差值,大体方法流程如图8所示。

图8 速度姿态特征算法流程图
对应到图像中,整个摔倒过程如图9所示。

图9 姿态特征识别摔倒行为
图片从左到右依次为在第n-10帧、n-5帧、n帧时的被检测目标运动姿态,可以看出,在前后10帧内,当被检测目标摔倒时,颈部位置与脚部位置的平均高度差值具有较为明显的变化,且变化较快,而蹲、躺等近似行为的变化较慢,整个动作完成通常在前后30帧的范围内完成相同的高度差值变化。
3 实验与分析
测试使用的数据集从十八个自建视频序列中提取出来,该套视频序列包括三名志愿者在两种角度下的三种摔倒行为。分别为正向、侧向前摔;正向、侧向横摔;正向、侧向后摔。并结合包括蹲、躺、坐、行走、跳跃等五个非摔倒行为的三十个视频序列共同组成实验数据集,每三帧提取一次姿态特征。数据集参数详情如表1所示。

表1 数据集参数
由于实验使用最新的OpenPose-Darknet对检测目标进行姿态提取,该框架采用最新的构架进行搭建,优化了整体网络结构,相较于原始Caffe,其实现速度提高了3倍。
以CNN分类算法对数据样本进行分类识别,训练样本时,将摔倒行为标记为正例,将非摔倒行为标记为反例。最终的分类结果如表2所示。

表2 预测结果
引入灵敏度(SE)和特异性(SP)作为分类结果的评价指标。
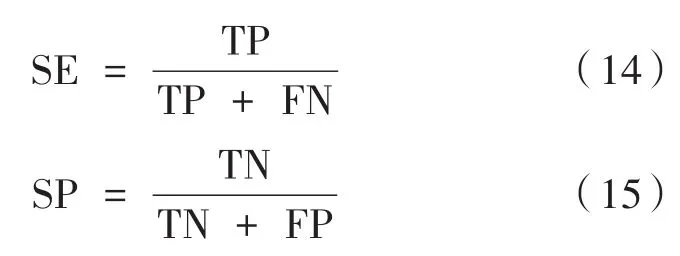
其中,SE表示在真实正例中被成功识别为真正例的概率,即在摔倒行为中被成功识别的概率;SP表示的是在真实反例中被成功识别为真反例的概率,即在非摔倒行为中被成功识别的非摔倒行为的概率。实验结果如表3所示。
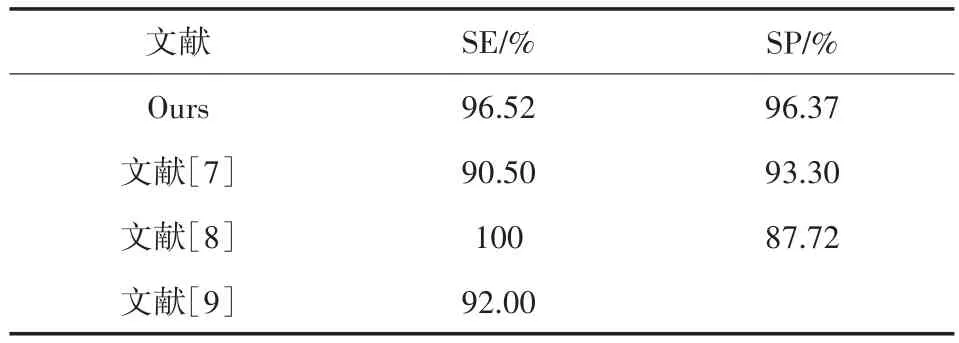
表3 实验结果
两项实验指标均高于96%,与文献[7]采用其自建数据集所得到的实验结果灵敏度90.5%特异性93.3%及文献[9]以双流神经网络对不同背景下的摔倒行为进行识别,并取得92%的平均识别率相比,实验所得的两项评价指标:
96.52%的灵敏度与96.37%的特异性,均有所提升。
文献[8]将阈值分类的算法应用到摔倒检测中,其进行分类实验所得到的灵敏度为100%、特异性为87.72%,较低的特异性代表着存在部分假反例会被识别为真反例的情况,在实际应用中,这种情况会带来频繁的误报、错报等。相比之下,96.37%的特异性更加稳定,能够有效地规避各种误检测。
4 结论
针对摔倒检测问题,提出了一种基于OpenPose与CNN的检测识别系统。通过OpenPose-Darknet对视频数据集进行姿态特征的提取,对检测目标的骨骼特征点进行检测,以卷积神经网络对提取的姿态特征进行分类识别。采用自建数据集进行数据实验,实验结果显示检测识别系统的灵敏度与准确性均在96%以上,既能较为准确的识别摔倒行为,同时兼顾了识别的稳定性,减少误判现象。
