结合Spatial CNN的端到端自动驾驶研究
2021-06-30单兆晨黄丹丹耿振野刘智
单兆晨,黄丹丹,耿振野,刘智
(长春理工大学 电子信息工程学院,长春 130022)
传统的自动驾驶是基于规则的系统[1]。一般方法是:融合多传感器获取的环境数据进行分析,基于此分割可行驶区域、识别障碍物、检测标示牌和路径规划等,系统理解了所处环境后做控制决策。其中每个子系统都涉及复杂的建模问题,并且还存在无法用规则描述的情况,规则构建是非常困难的工程。
随着人工智能时代的到来,深度学习成为计算机视觉领域最强大的机器学习方法。为了简化基于规则的过程,近年来应用端到端深度学习的方法受到学术和商业界的重视。该方法将感知、规划和控制囊括在一个深度神经网络中,将摄像头、雷达和陀螺仪等参数输入网络模型直接输出得到车辆速度、方向盘转向和刹车程度等驾驶控制指令,不深究特征提取、语义分析以及控制量的确定。这样便省去了人为制定控制规则的过程,极大地降低了系统的各项成本。
Pomerleau等人[2]最先在汽车上应用端到端算法,采用的是浅层的全连接BP神经网络,输出为45个方向预测节点和1个预测置信度的参数。该方法将方向预测作为分类任务用感知机模型训练,网络结构简单且没有关注图像特征与输出的相关性,可解释性较差。LeCun等人[3]在2005年的论文中使用卷积网络进行端到端的野外避障研究,系统命名为DAVE,可以从双目相机获取的原始图像直接得到转向角度。随后2016年 NVIDIA 在此基础上提出了 DAVE-2[4-5]无池化层的卷积网络模型,DAVE类方法利用卷积网络提取图像特征,但并未进一步分析感兴趣区域的特征表达方式。邹斌等人[6]对DAVE-2进行改进,将自编码器作为预训练模型并利用反卷积可视化感兴趣区域,解释了模型重点关注的是道路的部分边线特征。但该方法并未利用这一特征作进一步的改进,缺乏针对性。
虽然端到端的自动驾驶已取得较多成果,但仍存在问题:(1)数据集规模庞大,训练耗时较长;(2)卷积网络缺乏对道路信息的针对性提取。因此本文采用迁移学习[7-9]的方法,迁移预训练的 VGG16[10]网络结合 Spatial CNN(SCNN)[11-12]模型结构进行训练,并可视化特征图验证SCNN作用,最后比较不同网络结构的预测误差。
1 端到端方法分析
端到端自动驾驶的核心为深度学习模型,基本思路是人工操控车辆在道路上正确行驶,同时车辆前方的摄像头记录下道路信息以及与之相对应的一系列控制数据,包括转向角、刹车、油门和车速等。将采集到的路况图像作为输入数据,与之对应控制数据作为模型的输出,模型训练后将具有一定的自动驾驶能力。根据前方道路的图像信息,做出控制预测,从而达到端到端自动驾驶的目的。
模型必须学习如何在车道线中央行驶,如何从偏移错误中恢复。为了提高模型的泛化能力,利用三个摄像头采集道路的正前方、左前方和右前方视频数据,扩充了额外的道路信息。这些信息显示了偏离道路中央的程度以及转向时车辆左右的信息差异。为了便于结果分析控制参数只采集转向参数。训练系统总框图如图1所示。
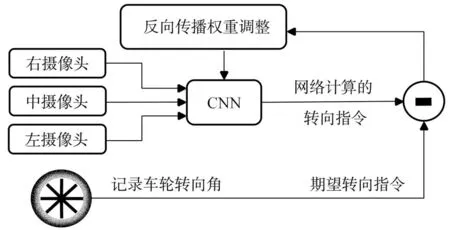
图1 训练系统总框
三个摄像头采集的图像传入一个卷积神经网络,然后计算一个被预测出的转向控制命令。这个转向命令会与该图像的期望命令相比较,卷积神经网络的权重就会被调整以使其实际输出更接近期望输出。
模型训练完成后,CNN就能从摄像头的视频图像生成转向控制命令,此时只需车辆正前方的摄像头采集的道路信息就可完成转向预测。转向预测框图如图2所示。

图2 转向预测框图
1.1 迁移学习模型架构
本文采用迁移预训练模型的方法构建端到端的自动驾驶模型。为了使迁移效果最大化,因此选择迁移预训练的VGG-16网络以及与本次任务具有强相关性的车道线检测模型Spatial CNN(SCNN)。传统的CNN模型通过堆叠卷积层实现深层特征提取,特征是在隐藏层间逐层传递的,是一种基于图像局部相关性的特征提取方法。SCNN是一种独特的空间特征提取结构,特征信息在层中传递,即卷积核在隐藏层中的三维特征图的行和列上做特征提取,将卷积神经网络推广到了空间层次,使得空间信息能够在同层的神经元上传播。SCNN能够关注在空间域上具有空间连续性的目标特征信息,如车道线、电线杆等线状目标。SCNN是基于已有的CNN主干架构上学习空间信息,一般来说SCNN可以应用在主干网络隐藏层的任何部分,通常隐层的后端包含丰富的语义信息,是应用SCNN理想的位置,SCNN结构如图3所示。
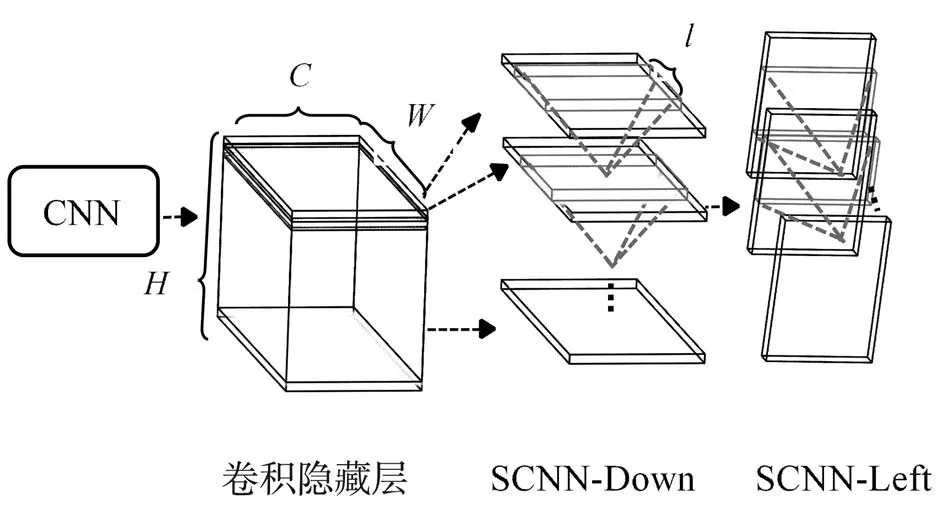
图3 SCNN网络结构
SCNN应用在卷积网络隐层的三维特征图上,假设隐藏层大小为C×W×H,依次对应通道数、长和宽,对三维矩阵切片可以拆分出H×W,H×C,C×W三种二维张量,对应六种信息传递方向,其中H×C和C×W张量切片可以实现空间信息传递,有向下(SCNN-Down),向上(SCNN-Up),向右(SCNN-Right),向左(SCNN-Left)四个方向,具体可用公式(1)表示:
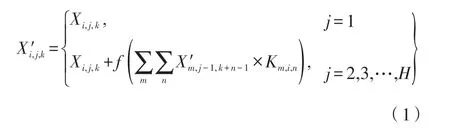
式中,Xi,j,k记为张量X的元素,其中i、j、k分别指代通道、行、列,f是非线性激活函数,X′表示更新后的值,所有的切片共享一组卷积核。
本文选用预训练的VGG-16作为主干网络模型,具体架构如图4所示。
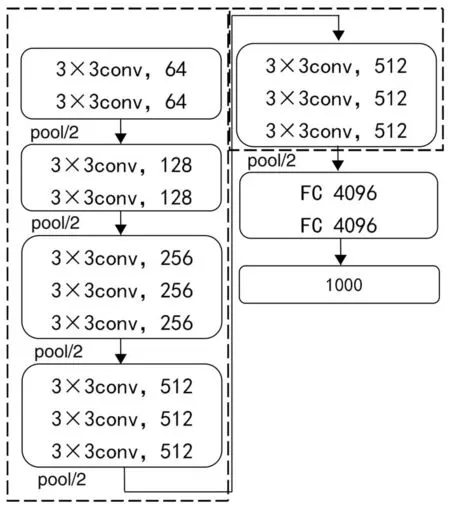
图4 VGG-16网络模型架构
VGG-16网络采用 224×224×3的 RGB 三通道彩色输入图像,结构中包含五轮卷积、池化处理层和三个全连接层。这里选择将第五轮池化之前虚线框部分作为冻结层,将冻结层作为预训练好的特征提取器深度迁移到自动驾驶模型,在其后端加入SCNN结构增强对空间特征信息的提取。预训练的VGG-16网络源任务是做1 000个类别的分类,而本文的目标任务是回归转向角,需要重构全连接层将输出节点改为1,重新训练全连接层与SCNN网络,迁移学习模型总体架构如图5所示。
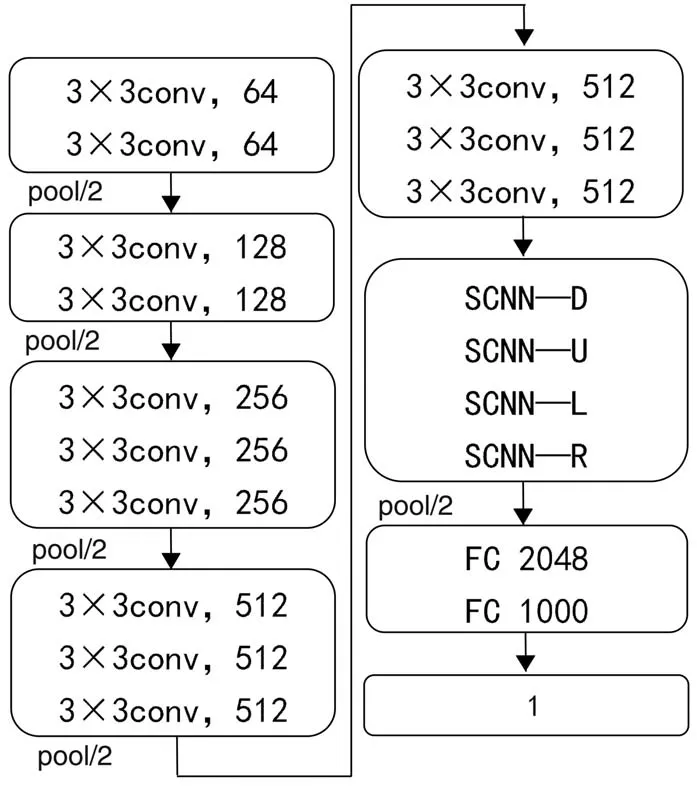
图5 迁移学习模型总体架构
1.2 损失函数设计
端到端自动驾驶的本质是一个回归任务。常用于回归模型的损失函数有均方误差(Mean Squared Error,MSE)以及平均绝对误差(Mean Absolute Error,MAE)。DAVE-2模型与自编码器网络都采用均方误差作为训练损失函数,用公式(2)表示为:
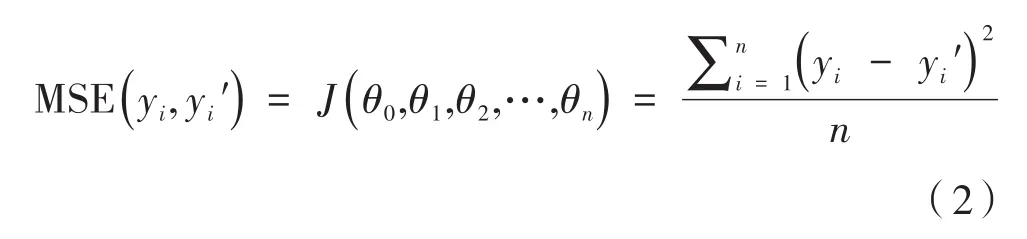
式中,n为一个批次中的n个样本;yi为输出;yi′为期望输出;θi为需要更新的权重。
由于驾驶数据集存在直行数据多于转弯数据的不均衡问题[13-14],而MSE特点是对误差取平方,这会使其对离群点非常敏感,模型训练结束会使预测值偏向离群点。如果采用MAE作为损失函数,又存在梯度恒定的问题,使得小误差仍具有大梯度,不利于学习。针对这种问题,设计了一种带参数的条件损失函数,用公式(3)表示如下:
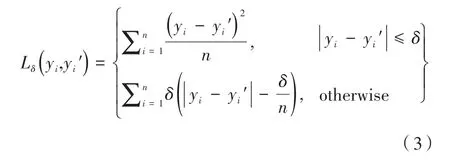
δ作为超参数可以自定义,其作为阈值条件将损失函数分段,当绝对误差小于设定阈值,损失函数形式为MSE,否则损失函数形式为MAE。其结合了MSE和MAE的优点,并且增强了MSE对离群点的鲁棒性,分段函数处处可导求解效率高。
训练中采用自适应学习率的优化器Adam(adaptive moment estimation,Adam)优化损失函数。
2 实验结果与分析
本文所用的道路图像信息数据与对应的控制参数采集自udacity机构所提供的无人车模拟器beta_simulator,实验软件环境为python3.6,GPU为Nvidia RTX2080,深度学习框架采用的是TensorFlow2.0,模拟器驾驶界面如图6所示。

图6 模拟器驾驶界面
2.1 数据采集
模拟器人为操控汽车采集数据时,需要不断控制汽车回到道路中心位置。操控汽车在多弯道的山路地图行驶五圈采集5 000份数据,部分道路数据集如图7所示。

图7 部分道路数据集展示
模拟驾驶数据采集完成,所有的数据会保存在一个CSV文件中,其中包含七项数据′center′,′left′,′right′,′steering′,′throttle′,′reverse′,′speed′。其中′center′,′left′,′right′作为训练数据,′steering′为标签数据。
2.2 数据预处理
为了使图像数据集符合预训练模型输入大小,需将原始图像批量缩放。数据集剪裁完成后,进行图像像素值和转向角[-25°,25°]的归一化处理。其目的是为了将数据范围映射到激活函数最好的工作范围内[-1,1]。其中转向角归一化后的数据分布如图8所示。
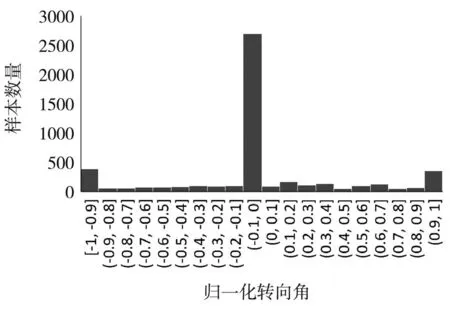
图8 转向角归一化后数据分布
可以看出,转向角数据分布极度不均衡,如果直接进行训练会导致模型输出过拟合到直行数据,从而在转弯处的表现较差。为解决样本不均衡的问题,训练前需将训练样本中非直行图像数据进行镜像翻转来增多转弯训练样本,同时翻转对应的转向角。
将归一化的数据集(5 000)随机拆分成训练集和测试集,同时为了避免过拟合,将采用交叉验证的方法,其中训练集占80%(4 000),验证集占20%(1 000)。
2.3 模型训练与评估
Adam优化器本质上是利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。推荐参数配置:learning_rate=0.001,beta1=0.9,beta2=0.999,epsilon=1e-08,在能保证损失函数收敛的情况下,学习率设置为0.001时衰减最快。迭代次数设为5 000,每次迭代随机选取250张图像进行训练,并且每次迭代完成后用验证集进行一次交叉验证。迁移学习模型和DAVE-2模型训练过程的条件误差损失随迭代次数的变化情况如图9和图10所示。
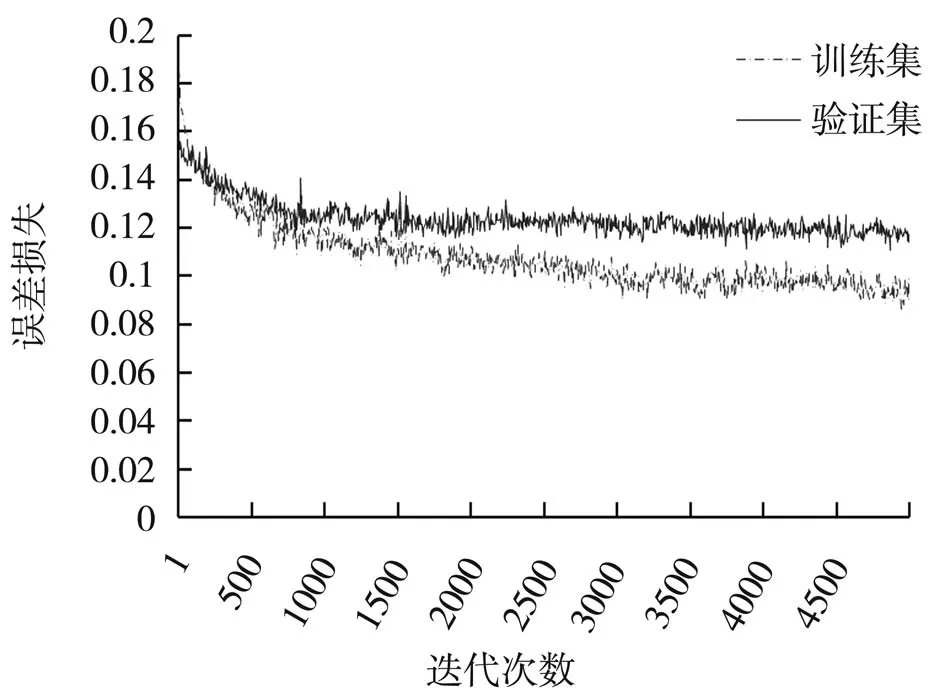
图9 迁移学习模型训练误差损失
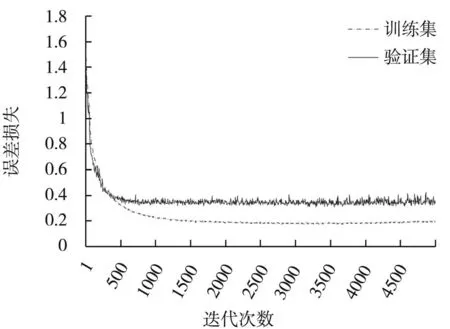
图10 DAVE-2模型训练误差损失
由于预训练模型已具有一定的图片识别能力,从中迁移的冻结层可以捕获图像普遍性的特征。由图9和图10可以很明显的看出,迁移学习的转向预测模型其损失函数具有较低的初始误差,仅用4 000个训练样本经过5 000次迭代就能将损失从0.19降到0.09左右。而对于从零开始训练的DAVE-2网络来说,在训练初始阶段不存在学习能力。在同等条件下,其具有较高的初始误差,经过2 000次的迭代后损失从1.58降低到0.2左右就已停止下降趋于稳定。说明从零开始训练的DAVE-2网络利用4 000个样本训练将误差损失衰减到0.2就已达到学习上限,仍需要大量的训练数据进行更多次数的迭代学习,才能达到迁移学习模型的效果。
从两种模型的训练过程对比来看,迁移一个具有图像识别能力的预训练模型进行端到端自动驾驶的转向预测,不需要大量数据训练,短时间内就可以得到一个误差较低的转向预测模型。
将SCNN最后一层特征图进行上采样可视化,与测试图片进行对比分析。可以看出嵌入了SCNN结构的特征提取器更加关注道路的线状信息,消除了其他特征干扰,使得模型更具有针对性。对比如图11所示。

图11 特征图上采样与原图对比
模型训练完成后,为了更直观的观测模型的预测效果,在模拟器上进行模型的准确性测试,模拟器提供两种类型的地图,一种是平坦公路还有一种是多弯道山路,将迁移学习模型载入程序用Socket与模拟器通信,分别在两种道路上进行自动驾驶测试,得到与人工操控驾驶的转向角真实值折线图对比,如图12和图13所示。
如图12、图13对比表明:迁移学习模型预测输出的角度和人工操控的角度变化趋势一致,而且在实际行驶过程中车辆能够很好的保持在道路中央行驶。
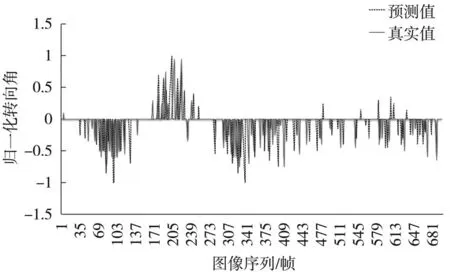
图12 平坦公路转向角预测对比
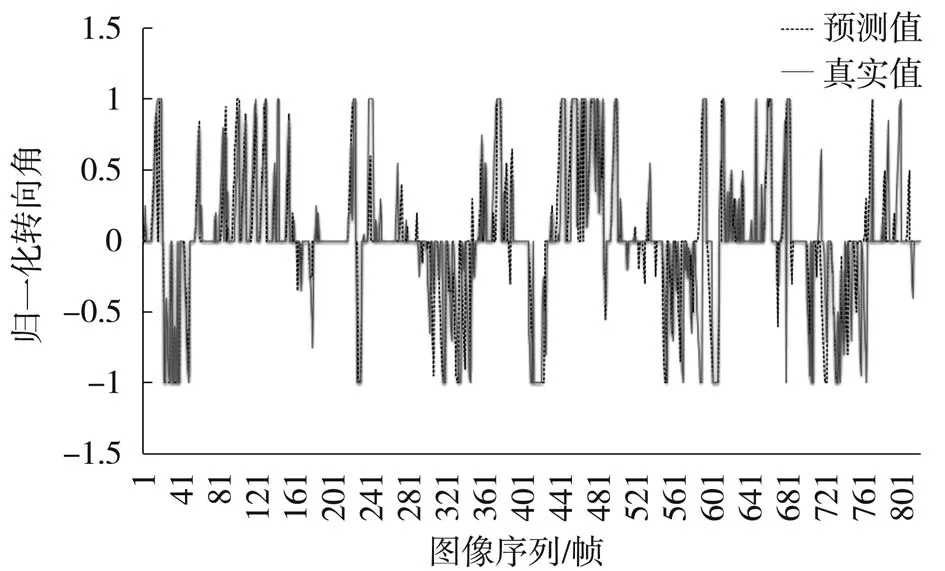
图13 多弯道山路转向角预测对比
实验共训练了6种网络结构,其中迁移VGG-16+SCNN模型损失优化以及预测统计误差最小,模型采用MAE进行拟合度评估,对比如表1所示。
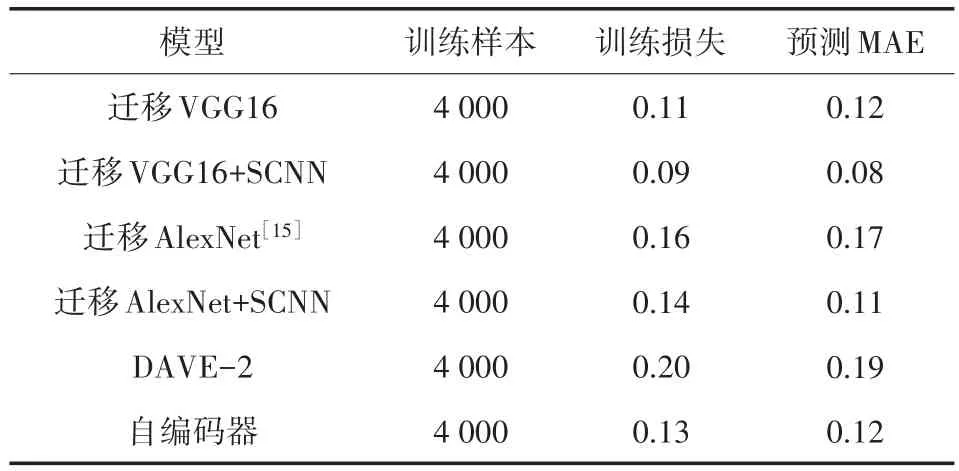
表1 不同网络结构结果对比
3 结论
本研究结合迁移VGG16和SCNN结构建立了端到端的自动驾驶模型,用少量的样本训练模型的转向预测能力,在模拟器上得到了较好的测试效果。与直接从零开始训练的DAVE-2网络相比,转向角的误差损失与预测误差在相同的学习率和迭代次数下更低。实验中特征图经过可视化后,结果表明了结合能够提取空间连续线状目标特征的SCNN网络,让模型能够重点关注车道线的变化,使得本文的迁移模型与任务更具任务相关性。测试中发现,在没有车道线的路况上,模型仍然能够提取出可行驶区域,没有出现失控偏离车道的状态。
