基于伪孪生网络的政务实体链接模型
2021-06-25姬美琳王德军孟博孙贝尔
姬美琳,王德军,孟博,孙贝尔
(中南民族大学 计算机科学学院,武汉 430074)
实体链接(Entity Linking, EL)[1]指将用户问句中的实体指称正确地链接到知识库中的实体上,完成问句实体与候选实体的关联匹配,解决同义词和多义词导致的歧义问题.实体链接是自动问答(Question Answering, QA)任务的核心环节,是识别用户问句意图的关键步骤.实体链接过程中存在大规模的实体匹配计算,实体链接的准确性和响应时间直接决定问答系统的性能.本文主要针对政务知识图谱问答性能需求,研究满足政务交互式问答应用场景的高准确度、低响应时延的实体链接模型.
传统的知识图谱问答系统基于字符相似和统计学方法解决实体链接任务,模型缺乏语义匹配能力,链接准确率低,不能充分满足政务问答需求[2].基于深度学习的实体链接模型近年来成为研究热点,利用神经网络强大的特征抽象能力,实体链接模型的语义表示能力和求解准确性得到较大提高,但模型计算复杂度高,模型的性能尚存在瓶颈[3],无法满足政务领域交互式场景的实时性要求.此外,政务实体的标准名称与公众口语表述之间存在较大的差异,给政务实体链接任务带来了挑战.
针对政务领域图谱问答需求,本文提出了一种基于伪孪生网络架构的政务实体链接模型,主要特点包括:(1)引入伪孪生网络架构,解耦问句和候选实体的特征提取过程,通过预先计算候选实体的向量表示,降低链接过程中的计算复杂度;(2)将政务知识图谱中实体的上下文子图信息引入到候选实体特征提取过程,利用神经网络模型提取文本所蕴含的深层语义信息,增强模型对相似政务实体的区分力,提高链接的准确率.
1 相关工作
知识图谱(Knowledge Graph,KG)[4]是一种结构化的语义知识库,具有强大的语义描述能力,在智能问答、个性化推荐等领域得到广泛应用.知识图谱包含开放域(open domain)和限定域(closed domain)两种类型,如Freebase[5]、DrugBank[6]等.开放域图谱注重知识的广度,通常采取自底向上方式从多源异构的数据源中抽取、融合知识,构建过程高度自动化,需要用户对图谱质量有一定的容忍.限定域图谱关注知识的深度,通常采取自顶向下方式从行业内积淀的结构化、半结构化数据集中抽取知识,并在领域专家指导下构建,同时具有人工审核机制,构建过程半自动化,因此限定域图谱的质量更高、语义信息更加丰富[7].政务知识图谱本身属于限定域,其涵盖多个部门1500项以上个人、法人业务事项,图谱规模较大,所支持的政务自动问答应用属于面向终端用户的交互式服务,应用场景对实体链接的准确性和响应时间具有综合性能要求.政务问答应用中,用户问句属于短文本,问句中实体指称数量少,指称上下文信息不足,无法通过联合推理解决政务实体链接任务.因此本文提出引入实体在政务知识图谱中的上下文信息,增强实体的背景知识,从而提高模型在相似实体上的区分度.
实体链接一般包含两个子任务:实体生成和实体消歧,相关研究一般通过这两个阶段提高链接任务的准确率.实体生成阶段目的是生成候选实体集合,一般通过加入部分匹配、模糊匹配以及构建别名词典等方式来提高候选实体的召回率[8-10];实体消歧阶段目的是从候选实体集合中选择符合问句语义的目标实体,该阶段主要有传统基于字符相似、基于机器学习和基于深度学习的实体消歧算法[2].基于字符相似的链接算法一般通过字符相似度排序候选实体,如编辑距离等,这种方法忽略了问句实体指称和候选实体的上下文信息,不适用于解决重名实体或者别名情况[11].基于机器学习的实体链接模型依赖人工提取的特征和高质量的数据集,模型的移植性差,在缺乏标记数据的领域中,模型无法达到最佳效果[2].基于深度学习的实体链接算法核心在于将不同类型的文本信息映射到同一特征空间内,学习问句和候选实体的语义向量表示,通过向量相似性求解实体链接任务.文献[10]为了增强候选实体语义特征,利用候选实体的类别、关系以及知识库邻近实体节点的特征信息作为候选实体的表示方法,并在WebQuestions-SP外文知识库问答数据集上验证了算法的有效性,准确率达到88%.
基于深度学习的实体链接模型虽然有效地提高了链接准确率,但是由于计算量大的缺点,模型响应时间较长,很难满足交互式场景下的应用需求,模型的整体性能有待提升.孪生网络(Siamese Network)[12]包含两支相同结构的网络模型,通过共享参数方式优化网络模型结构,两个子网计算过程相互独立,常应用于建模相似性比较任务,在人脸识别、语义搜索等任务中得到广泛应用.文献[13]基于孪生网络提出SBERT模型,解决了基于BERT的语义搜索任务计算量大的问题,并且证明了模型具有学习句子语义化向量表示的能力.
综上所述,为了提高政务领域链接任务的准确率,并满足交互式问答场景下的低时延需求,本文基于伪孪生网络(Pseudo-Siamese Network)[14]解耦问句和候选实体的向量提取过程,通过预先提取所有候选实体的特征向量,减少模型在链接过程中的计算量,使得候选实体的特征抽取不再依赖于用户输入的问句,因此显著地减少了模型的计算次数,降低了响应时间.同时,引入候选实体在知识图谱中的上下文信息,填充实体背景知识以增强其语义特征,使得链接模型在区分相似实体上具有更好的效果,从而提高链接的准确率.
2 政务实体链接模型
2.1 实体上下文信息抽取
影响政务实体链接任务准确性的关键因素是问句中实体指称上下文信息不足,如何有效地挖掘问句及知识图谱的深层语义信息,是提高政务实体链接任务准确性的重要因素.本文通过引入候选实体在知识图谱中的上下文子图信息,填充实体的背景知识,增强模型的语义匹配能力,从而提升实体链接效果.
候选实体在知识图谱中的上下文子图信息包含实体名称、实体类型、实体的结构化属性以及实体与其他实体间的语义关系.其中对实体链接任务具有价值的信息包括:候选实体的名称特征(以N表示),候选实体的结构化属性特征(以S表示)以及候选实体的描述性文本摘要特征(以A表示).特征N包含了实体的标准名称、常用名称、别名、缩写;特征S包含了实体的办理条件、办理材料、受理对象、办理流程四个结构化属性特征;特征A主要通过获取政务事项的法律依据、设定依据信息作为政务事项实体的文本摘要.
本文所使用的政务知识图谱数据来源于湖北省政务服务网,政务服务网按照事项主题、办事部门等类别梳理了多种政务领域数据信息,其提供的数据全面且权威,可以有效地增强实体的语义特征.以问句“公积金的身份证号码错了在哪里修改?”为例,问句正确的实体链接结果为“住房公积金个人账户信息变更服务”事项,如表 1所示为从政务知识图谱中抽取的两个政务事项实体上下文信息,所抽取的上下文信息将作为实体的背景知识,通过本文所提模型进行特征抽取,得到候选实体的语义向量表示.

表1 政务事项实体上下文信息示例Tab.1 Examples of government affairs entity context information
2.2 模型结构设计
政务实体链接模型需要支持编码多元信息,并具有较高的计算效率和较低的时间复杂度,因此本文基于伪孪生网络架构提出一种新的政务实体链接模型,结构如图 1所示.网络模型包含两个非对称的左右分支子网,每个分支由嵌入层、卷积层、池化层和全连接层组成.其中嵌入层将问句词序列和候选实体特征词序列映射成低维稠密向量,得到初始输入矩阵,本文使用BERT(Bidirectional Encoder Representations from Transformers)[15]作为嵌入层模型;卷积层进行局部特征提取工作,得到多个特征的向量表示;池化层用于降低向量维度;全连接层对池化后的向量进行线性映射,得到问句和候选实体的最终向量表示.两个子网在嵌入层共享参数,在其他层不共享参数.
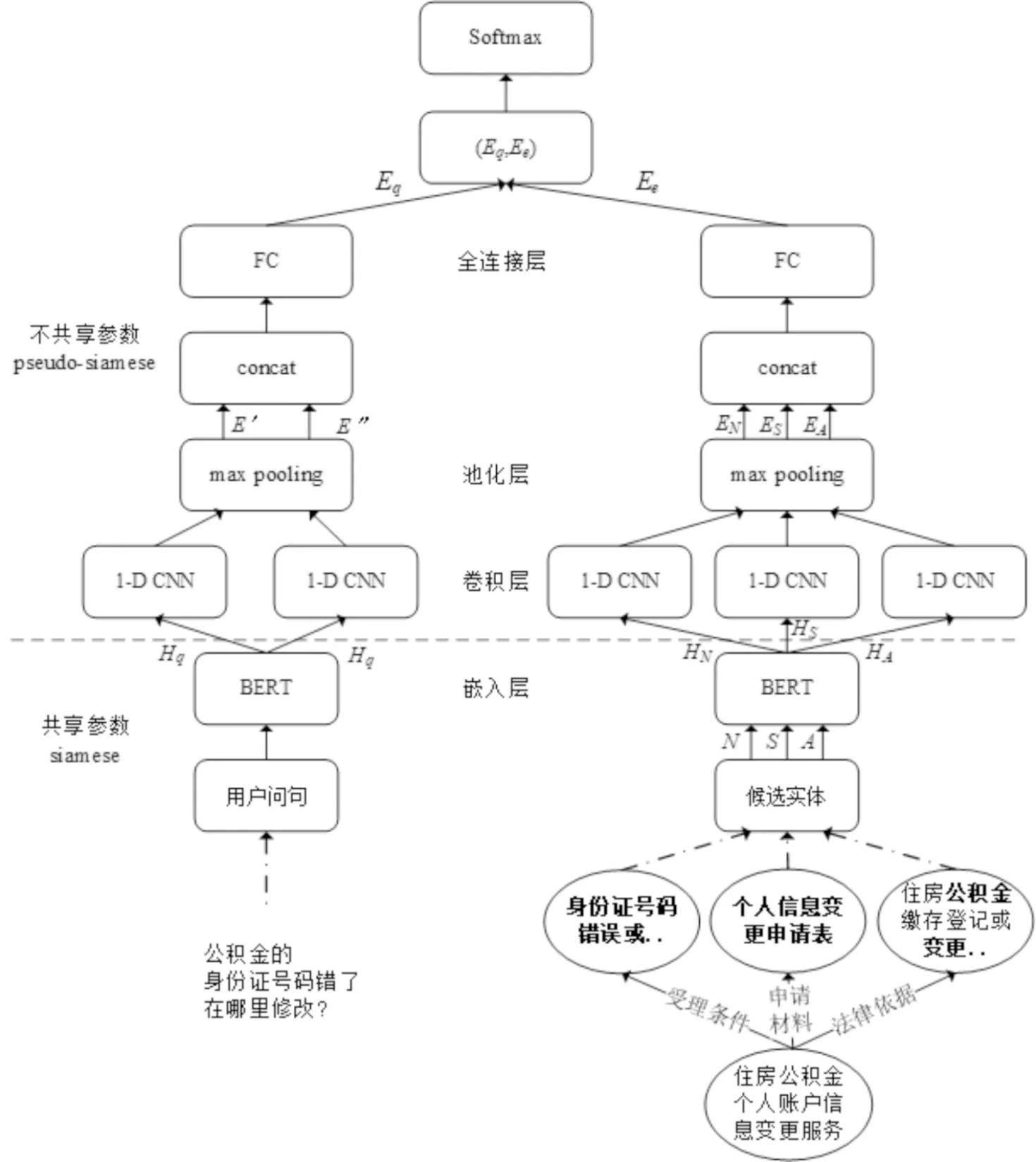
图1 政务实体链接模型结构Fig.1 Structure of government affairs entity linking model
左右分支子网分别负责编码问句和候选实体的上下文信息,左侧网络用于提取问句的文本特征,得到问句的向量表示,右侧网络用于提取候选实体上下文信息特征,得到候选实体的向量表示.本文通过计算向量余弦距离得到问句与候选实体的语义相关度,并对实体链接的结果进行筛选和排序,选择最高得分的候选实体作为目标实体返回.在链接过程中两个子网络相互独立,模型预先计算出所有候选实体的特征向量并保存,然后接收用户问句并提取问句特征,得到问句的特征向量,最后计算向量余弦距离,对候选实体进行打分排序.
本文所提网络模型主要具有以下优点:(1)模型基于伪孪生网络架构解耦问句和候选实体的向量映射过程,使得候选实体的向量映射过程独立于用户实际输入的问句,模型在链接过程中只需要针对问句进行一次特征提取,显著地降低了模型的计算次数,提高了模型计算速度;(2)融合BERT和CNN,提升了实体链接模型的语义表示能力和特征抽象能力,使得模型在政务领域实体链接任务上具有更好的表现力和预测效果.
具体地,政务实体链接模型的计算过程包含问句特征向量映射、实体特征向量映射和语义相关度计算三个过程.
2.3 模型计算过程
2.3.1 问句向量映射
问句的向量映射过程如图 1左侧子网所示,主要包含嵌入层、卷积层、池化层和全连接层,其中卷积层包含两个一维卷积操作.问句query=(q1q2…qn),qn表示问句第n个词短语,问句向量映射的具体计算过程如下:
step1问句矩阵化表示:将问句转换成BERT标准输入序列“[CLS]q1q2…qn[SEP]”,通过获取BERT最后一层每个词短语的输出向量作为问句的初始输入矩阵Hq=(T1T2…Tn),其中Hq∈R|query|×d,|•|表示字符长度,d表示BERT模型输出向量的维度大小.
step2问句特征抽取:使用两个卷积核对Hq进行卷积操作,并通过最大池化层进行池化降维,得到问句两个特征向量E′和E″.E′的计算如式(1)和式(2)所示:
E′=max{c},
(1)
c=[c1,c2,…,cn-k+1],
(2)
其中E′∈R1×h,c∈Rh×(n-k+1),c为卷积操作的输出矩阵,h为卷积操作的输出通道大小,k为卷积核大小.对于单个卷积操作,计算如式(3)所示:
ci,j=f(wHj:j-k+1+b),
(3)
其中w∈Rd×k,b∈R,Hj:j-k+1表示问句从第j到第j-k+1个词短语所对应的BERT输出向量矩阵,f为非线性激活函数.对于特征向量E″,其计算过程与E′相同,但是卷积核k的大小以及参数w和b不同.
step3问句向量表示:将两个特征向量E′和E″按行拼接,并输入到全连接神经网络中进行线性映射,得到问句的向量表示Eq,计算公式如下:
Eq=W′([E′,E″])+b′,
(4)
其中Eq∈R1×d′,W′与b′为全连接层的权值和偏置参数,在训练中更新,且W′∈R2h×d′,b′∈R1×d′,d′表示链接模型输出层词向量的维度大小.
2.3.2 实体向量映射
候选实体e的向量映射过程具体如下:
step1实体矩阵化表示:从知识图谱中抽取实体e的上下文信息,并按照BERT的标准输入格式构建输入序列,依次输入到BERT模型中,获取BERT最后一层的输出向量,得到政务实体e的3个特征矩阵:HN、HS、HA,其中HN∈R|N|×d,HS∈R|S|×d,HA∈R|A|×d,|•|表示字符长度,d为BERT模型输出向量的维度大小.
step2实体特征抽取:对实体e的3个特征矩阵HN、HS、HA分别进行卷积操作,并通过最大池化层进行降维,得到3个特征向量:EN,ES,EA,每个特征的参数互不共享.
step3实体向量表示:将3个特征向量EN、ES和EA按行拼接,并将得到的结果输入到全连接神经网络中进行线性投影,得到实体e的特征向量表示Ee,计算公式如下:
Ee=W″([EN,ES,EA])+b″,
(5)
其中Ee∈R1×d′,W″∈R3h×d′,b″∈R1×d′,d′表示链接模型输出层词向量的维度大小.
通过式(4)和式(5)计算得到问句的向量表示Eq和候选实体e的向量表示Ee,本文通过拼接Eq和Ee进行二分类任务,并使用softmax模型进行归一化,从而得到用户问句与候选实体e的语义相关度,计算公式如下:
o=softmax(W(Eq,Ee)),
(6)
其中o为链接模型最终输出的分类结果,代表问句与该候选实体的语义相关度,且W∈R2d′×2.
2.3.3 模型训练与预测
在训练过程中,实体链接模型共享BERT层参数,其他层参数不共享,使用交叉熵函数作为模型的损失函数.在预测过程中,模型主要存在两个阶段:初始化阶段和语义搜索阶段.初始化阶段指预先计算出知识库实体的特征向量表示,并加入到向量集合V中;语义搜索阶段指接收用户问句输出链接的目标实体.具体来说,模型预测过程中首先计算知识库中所有实体的特征向量并保存到集合V中,得到实体向量查询表;然后接收用户问句,使用jieba中文分词工具切分问句,得到实体指称短语集合,通过实体指称短语召回知识库中的相关实体,得到候选实体集合;最后通过实体链接模型左侧子网对问句进行向量映射,得到问句的向量表示Eq,并通过式(7)计算问句和候选实体的语义相关度,通过阈值λ对结果进行筛选排序,按照式(8)从知识库中选择最高得分的实体作为链接结果返回,公式如下:
(7)
(8)
3 实验
3.1 数据集
政务领域缺乏相关公开数据集,为了验证所提模型的有效性,本文利用网络爬虫技术获取湖北省政务服务网15个区县级政务事项的数据信息,得到2576条常见问题集,经过人工清洗、拓展后得到常见问题集1900多条,获得53个政务部门、400多个政务事项以及政务材料等信息,通过这些信息可以构建起政务知识图谱,作为政务实体上下文信息的知识来源.
对于政务实体链接任务数据集的构建策略如下:正抽样(即问句对应的标准政务实体)采取人工标注方法,标签为“1”;负抽样(反例数据集)来源于正抽样的相似子项,标签为“0”.每个政务服务事项都有所属的上级父类,例如“个人公积金账户信息变更服务”事项,其父类为“公积金”类.本文首先对正抽样的实体(以上述实体为例)进行中文分词[16]操作,得到核心词语“公积金”,使用“公积金”在知识库中进行模糊查询,从而得到反例数据.本文最终获得7100条实体链接数据集.
3.2 评价指标
给定一个政务问句,实体链接返回的结果为某个政务实体或者为空.以P表示模型预测的结果,O表示人工标注的结果,Pe和Oe表示链接到实体的指称,Pn和On表示链接到空的实体指称.当前针对实体链接模型的评测指标主要包含准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1值,各指标的定义如下:
(9)
(10)
(11)
(12)
3.3 参数设置
实验设备信息:CPU i5 8400,GPU Nvidia RTX 3070 8G.实体链接模型中参数设置如下:(1)本文使用BERT作为模型的嵌入层,得到用户问句和候选实体的向量表示,其中问句的最大序列长度为64,实体特征N、特征S和特征A的最大序列长度分别为128、512和512;(2)问句卷积核大小分别设置为2和3;特征N的卷积核大小为2,特征S的卷积核大小为3,特征A的卷积核大小为2,步长均为1.模型的初始学习率为5×10-5,迭代20轮,嵌入层输出的向量维度大小d为768,卷积层输出的向量维度大小h为256,模型最终输出的向量维度大小d′为128,问句与候选实体的语义相关度阈值λ取值为0.8.
3.4 实验结果
为了验证所提模型的准确性,在相同实验环境下,本文选择魏成志[17]提出的基于TF-IDF的政务实体链接模型进行对比,实验结果如表 2所示.

表2 不同算法实验结果对比Tab.2 Comparison of experimental results of different algorithms
从结果中可以看出,基于TF-IDF的政务实体链接模型准确率明显低于本文所提模型准确率.通过分析发现:基于TF-IDF的实体链接模型依据词频衡量候选实体的重要性,模型缺乏语义匹配能力,而本文提出的实体链接模型通过引入实体在知识图谱中的上下文信息,丰富了实体的背景知识,使得模型在区分相似实体上具有更好的表现,因此提高了链接准确率.如问句“买房子怎么提取公积金?”,本文所提模型由于融合了“购房公积金提取”的结构化属性知识,其“受理条件”的第一条:“在本市行政区域内非按揭购买拥有所有权的自住住房”表明该政务事项适用于“购买”情况下提取公积金,因此使得最终链接的结果为“购房公积金提取”,而非“租房公积金提取”.
本文进一步通过组合实体不同类型的上下文信息来探讨其对链接准确率的影响,实验结果如表 3所示.从结果中可以发现政务实体不同维度的上下文信息对模型的准确率有着不同的重要性,其中候选实体的名称特征N和实体结构化属性特征S影响力相当.
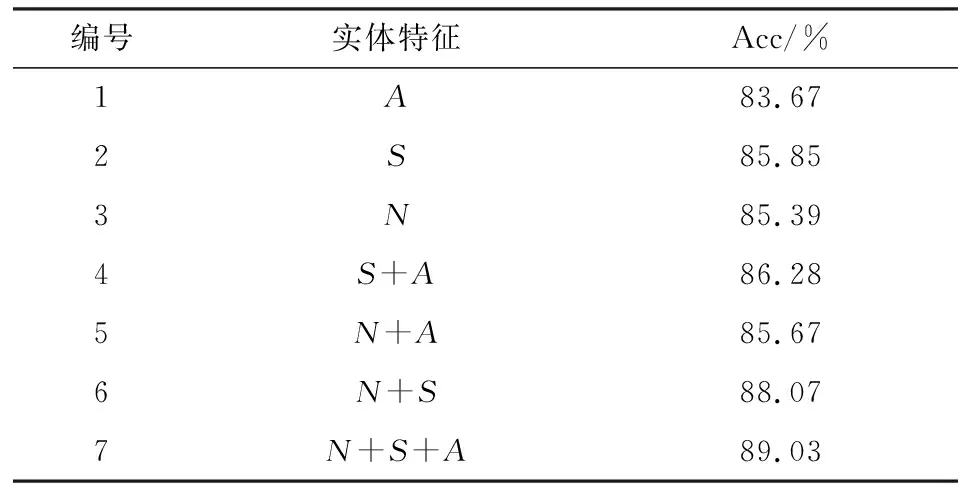
表3 不同上下文信息实验结果Tab.3 Experimental results of different context information
本文基于BERT作为问句和候选实体的向量嵌入层,为了验证BERT的引入是否有利于提升政务实体链接模型的性能,本文进行了相关消融实验.在相同的实验环境下,使用传统的静态词向量替换BERT,取得的结果如表 4所示.从结果中可以看出,通过迁移BERT模型可以提升政务实体链接模型的性能,从而验证了BERT具有更强的语义表示能力.
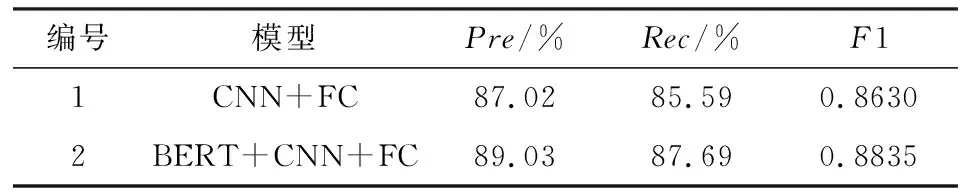
表4 消融实验结果Tab.4 Results of ablation experiments
为了证明所提模型在响应时间上的优越性,本文选择曾宇涛等[18]提出的实体链接模型进行对比实验.曾宇涛等基于深度学习技术,提出一种面向知识库问答的实体链接模型,模型接收“问句-实体”对形式的输入样本,在链接过程中,依赖用户问句提取候选实体不同类型的语义特征.而本文所提模型解耦了问句和候选实体的特征提取过程,通过预先计算所有实体的语义向量表示,使得模型在预测过程中只需对问句进行向量映射,因此降低了模型的计算复杂度.具体来说,模型响应时间包含候选实体集合生成和实体消歧两个阶段的时间,在相同的实验环境下,当候选实体集合大小为30时,两个模型的响应时间随着知识库规模的变化曲线如图 2所示,可以看出:随着知识库规模的增加,两个模型的响应时间也在增加,而本文所提模型的响应时间明显低于曾宇涛等提出的模型,由此证明了本文所提模型在响应时间上的有效性.
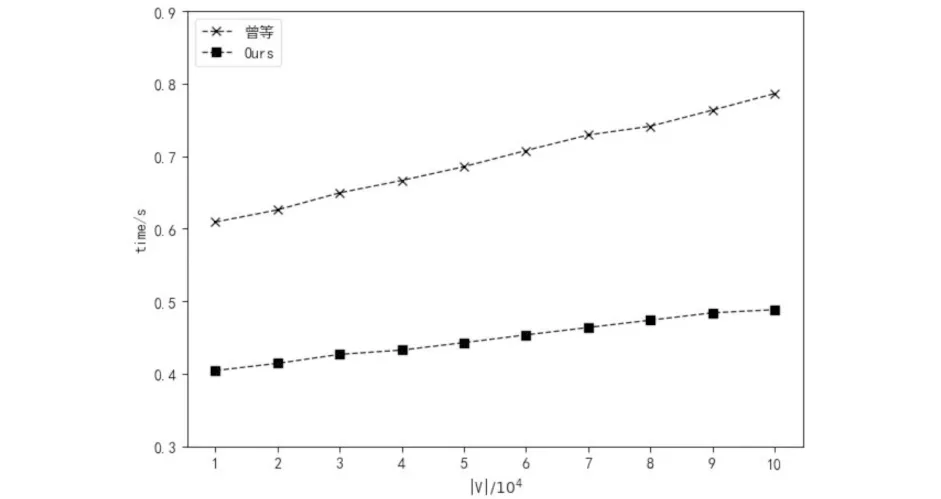
图2 模型响应时间Fig.2 Response time of model
4 结语
为了提升政务领域实体链接任务的准确率和计算效率,本文基于伪孪生网络,提出一种具有深度语义匹配能力的实体链接模型.实验结果发现:模型通过融合政务实体知识图谱中的上下文信息,增强了模型的语义匹配能力,相比于现有基于统计学的政务实体链接模型,本文所提模型显著地提高了链接任务的准确率;迁移BERT有助于提高政务领域实体链接模型的性能;模型基于伪孪生网络解耦用户问句和候选实体的特征提取过程,有效地减少了模型在链接过程中的计算量,提高了响应速度,在10万候选实体数据量下,链接时间在0.5 s左右,满足政务问答交互式场景的使用需求.
