知识图谱研究综述
2021-06-24刘燕贾志杰闫利华邹妍
刘燕 贾志杰 闫利华 邹妍
摘 要:知识图谱将知识库以一种图谱的形式展现出来,使知识具有可解释性、可推理性,从而使机器具备认知能力,是人工智能的重要基石。本文对知识图谱构建的关键技术、工具以及应用进行了综述,并且对知识图谱未来的研究方向做出展望。
关键词:知识图谱;实体抽取;知识融合
中图分类号:TP391 文献标识码:A 文章编号:1673-260X(2021)04-0033-04
1 知识图谱概念及主要应用
知识图谱[1](Knowledge Graph)本质上是一种大规模语义网络,它包含了各种各样的实体、概念以及实体之间的语义关系,是大数据时代知识表示的重要方式之一。2012年google发布了基于知识图谱的搜索引擎产品,由于知识图谱将知识以一种直观、可视化的方式展现出来,并且可以建立碎片化的数据的关联,因此,知识图谱成为语义搜索、问答系统、推荐系统等领域的研究热点[2]。
语义搜索可以利用知识图谱准确地捕捉用户的搜索意图,进而用基于知识图谱中的知识解决传统搜索中遇到自然语言输入带来的表达多样性、歧义性问题,通过实体链接实现知识与文档的混合检索。Google、百度和搜狗等搜索引擎公司通过构建Knowledge Graph、知心和知立方改进搜索质量。
问答系统是信息服务的高级形式,基于知识图谱的问答系统能够让计算机以精准的自然语言自动回答用户提出的问题。北京大学构建了基于开放领域知识图谱的自然语言问答(QA)系统-gAnswer,用户通过自然语言输入,经过一系列的转化能直接得到最终答案。
个性化推荐系统是所有面向用户的互联网产品的核心技术,在大量商品中,猜测用户的兴趣,给用户推荐一个小规模的商品集合,知识图谱为推荐系统提供了额外的辅助信息来源,可以提高推荐系统的精度。易趣正在构建其产品知识图谱,从而给出产品的定位和吸引买家的因素[3]。
2 知识图谱的主要特征
知识图谱利用图的形式展现数据实体的关系,数据通常以三元组RDF
知识图谱是一个空间的概念,使知识具有可视化的展示,能够直观地看到实体之间的关系,通常具有以下几个特征。
2.1 知识图谱可以直观地表示实体之间的关系
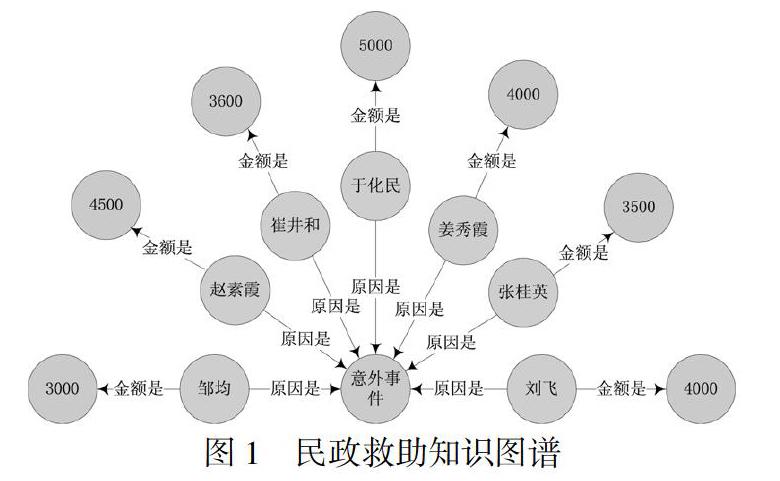
如图1所示,展示了民政救助知识图谱中“救助人”和“救助原因”“救助金额”实体之间的关系,将民政部门救助情况直观地展示出来。
2.2 知识图谱使知识具有可扩展性
随着时间变化,可以在知识图谱中增加新的知识节点(实体),新的知识结构和知识内容能够累积成一个完整的知识结构,在图1中还可以抽取救助人的家庭成员、收入等信息,使知识图谱更完备。
2.3 知识图谱使知识具有可推理性
知识图谱中大多数的关系是缺失的,基于已有的三元组关系,知识图谱还可以推导出新的关系,可以进一步实现知识发现。例如在知识图谱中存在<老虎,科,猫科>,<猫科,目,食肉目>这样的关系,可以推导出<老虎,目,食肉目>这样的关系。
2.4 知识图谱使知识具有可解释性
由于知识图谱具有可推理性,使得知识具有可解释性,尤其是在推荐系统的应用,能为用户推荐需要的商品,还能解释推荐的原因。
2.5 知识图谱的数据存储形式可以提高检索速度
知识图谱所采用的知识存储方式,在知识查询的过程中可以提高查询速度和效率,尤其是随着数据量的增多和关联深度的增加,更能展现知识图谱的数据查询和分析的优势。
3 知识图谱构建的主要技术
知识图谱主要分为知识图谱构建和知识图谱应用两个部分,其中知识图谱的构建是关键,基本流程和主要技术为模型设计、知识抽取、知识融合、知识存储和管理。
3.1 模型设计
知识图谱的逻辑结构主要分为模式层和数据层,模式层在数据层之上,是知识图谱的核心,模式层存储的是经过提炼的知识,用本体表示,本体(ontology)的本质是概念模型,表达的是概念及概念之间的关系[5]。通常知识图谱的模式层采用本体库来管理,主要的本体库有WordNet、DBpedia、Cys等,可以借助本体库对公理、规则和约束条件的支持能力来规范实体的类型以及实体之间的关系类型。例如,高血压、糖尿病等实体在本体库中归类为病症,发烧、咳嗽归类为症状,在本体库中的规则约束病症和症状之间的联系。比较流行的本体编辑工具是Protégé,用户只需要在概念层次上进行本体的模型构建,比较灵活,但缺乏对中文的支持。
3.2 知识抽取
知识抽取是在海量、多源异构的数据中抽取出实体和关系,对结构化和半结构化的数据可以通过专门的工具进行抽取,对于非结构化的数据进行实体抽取通常有三种方法。
3.2.1 基于詞典和规则的方法
基于词典和规则的实体抽取方法需要通过人工定义命名词典、实体抽取规则模板,从文中抽取出三元组信息。例如,在医疗领域知识抽取过程中我们可以定义这样的规则:X+谓语+疾病(X作为实体可能是疾病、药品、症状),将这个规则保存在信息库,对于要抽取的文本经过处理后和信息库的规则进行匹配,基于以上规则,对于“高血压引起脑出血、脑梗等疾病”的描述,可以抽取出<高血压,引起,脑出血>这样的三元组信息。这种方法的缺点是需要依靠大量的人工标注和制定规则,对于不同的应用领域,需要专家重新标注词典和定义规则,效率低、可移植性差,但准确性较高。
3.2.2 基于统计的机器学习的方法
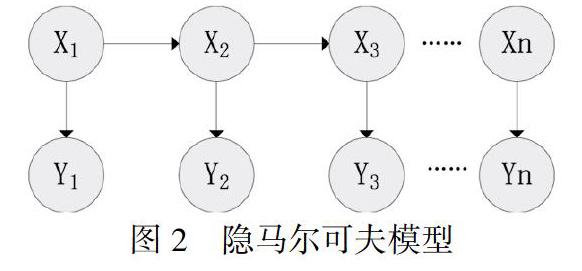
基于统计模型的方法通过对已经标注语料采用统计方法进行训练,并保存训练模型,从训练语料中挖掘出特征,对于要抽取的文本调用模板获取命名实体。主要模型有隐马尔可夫模型、条件马尔可夫模型、最大熵模型、条件随机场模型,这些模型都是将命名实体作为序列标注问题处理。例如,隐马尔可夫模型[6]就是在给定模型下,从一定的观察序列X选取一个最优的标记序列Y,使得P(Y|X)的概率最大,如图2所示。
3.2.3 基于深度学习的方法
深度学习方法将文本词向量作为输入,通过深度神经网络学习模型实现端到端的命名实体识别,不再依赖人工定义的特征,这种方法的迁移学习能力强,但由于网络模型繁多,对参数设置依赖大,模型可解释性较差。目前,采用深度学习的模型有BiLSTM、CNN、RNN、BiLSTM-CRF等。
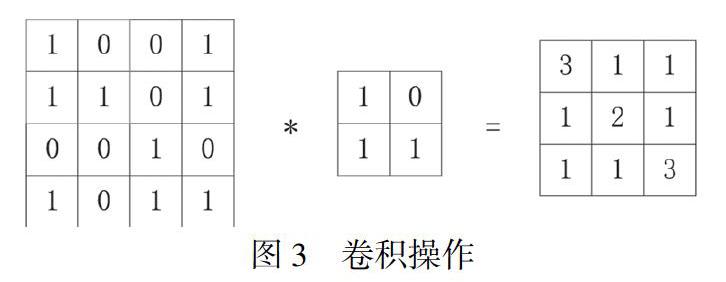
CNN(卷积神经网络模型)分为卷积层、池化层和全连接层,卷积层的输入是一个M×N的矩阵,N代表的是词向量的维度,M代表的是词的个数,例如,一句话中有5个词,每个词是10维的词向量,那么输入就是一个5×10的矩阵。卷积操作是指卷积核在输入张量上按步长进行左右上下滑动,每一步的滑动卷积核与张量重叠部分的元素按位相乘后求和[7]。通常一个卷积核用来抽取一个特征,一般用多个卷积核抽取多种特征,卷积层的输出结果为特征图,一个卷积核对应一个特征图,如图3所示。池化层主要是对卷积结果进行池化操作,降低卷积操作的数据量。全连接层对卷积层和池化层提取的特征进行分类。
3.3 知识融合
知识融合是构建不同数据源获取的知识之间的关联,在构建知识图谱之前,首先需要消除来自多个不同数据源知识的歧义,以及进行知识的统一表达等,然后才能将实体链接到知识库中的实体上,对于知识库中没有的知识补全到知识库中。通常知识融合的方法有基于聚类的实体消歧和基于实体链接的命名实体消歧。
基于聚类的实体消歧不给定目标实体列表,以聚类的方式对实体指称项进行消歧。方法是对每个实体指称抽取其特征(上下文的词,实体,概念),组成特征向量,然后利用向量的余弦相似度进行比较,将指称项聚类到与之最相近的实体指称项集合中[8]。
基于实体链接的命名实体消歧给定目标实体列表,对于待消歧的实体根据上下文信息通过打分的方式获取分数最高的实体作为目标实体。例如,中关村的苹果不错,苹果是水果苹果还是苹果电脑?通过计算相关度(中关村,水果苹果)=0.1,相关度(中关村、电脑苹果)=0.7进行实体消歧。
3.4 知识存储和管理
3.4.1 基于邻接表的存储方式
知识图谱中的知识以三元组的形式表示,在抽取完实体、关系后,将三元组的知识存储在数据库中,基于邻接表的存储方式的典型是gStore[9],这种方式将每个实体点的邻接表转化成一个二进制位串,将二进制位串按照知识图谱中的实体之间的关系连接起来。查询的时候将查询的子图也按照这种方式转化成一个二进制位串的形式,那么,知识图谱的查询就变成了子图匹配的问题。gStore采用的查询语言为SPARQL查询语言。
3.4.2 基于图数据库的存储方式
图数据库是基于图模型,对图数据进行存储、操作和访问的一项技术,与关系型数据库相比,图数据库在处理关联数据时展现出高性能、灵活、敏捷的优势[10]。典型的图数据库是Neo4j[11],Neo4j底层以图的方式把用户定义的节点和关系存储起来,通过这种方式,实现从某个节点开始,利用节点与节点之间的关系,找出另外的节点之间的关系。Neo4j的查询语言为Cypher查询语言。
3.4.3 基于分布式的知识图谱存储
由于知识图谱的数据规模不断扩大,为了应对大规模知识图谱的存储和管理,将知识图谱采用分布式的存储方式,一种是利用现有的云存储平台和云平台上成熟的任务处理模式处理知识图谱的任务,称为基于云平台的分布式知识图谱存储方法;另一种根据知识图谱的查询要求,将知识图谱数据按照一定的方法进行划分,形成不同的分片,分别存储这些分片,称为基于数据划分的分布式知识图谱存储方法,采用这种方法面临的问题就是如何对数据进行划分,使得知识图谱查询速度最快。
4 知识图谱未来研究方向
4.1 大规模知识图谱的自动化构建
由于知识图谱在不同认知领域的广泛应用,要求能从大规模非结构化内容中自动构建知识图谱。目前,自动化构建知识图谱有四大技术重点:如何自动化地从结构化数据库映射为知识图谱并做知识融合;如何通过小样本学习和领域知识迁移的技术减少人工标注成本;如何从非结构化文本中做篇章级的事件抽取和多事件关联;基于深度学习的知识表示在各个构建的环节的应用。
4.2 时序性知识图谱的构建
目前,知识图谱中展现的实体或者是概念的关系都是静态的,事实不随时间的变化而变化,对知识图谱的时序动态研究比较少,然而,在大数据背景下,能够实现数据的实时采集,事实通常具有时效性,静态的知识图谱难以适应对数据准确性要求较高的业务。例如,在知识图谱中实体的數量、实体之间的关系或者是实体的属性值会实时变化,如果简单的通过对图数据库进行delete和insert操作实现,会大大影响知识图谱的性能,那么如何构建具有时序性的知识图谱成为研究方向之一。
5 结束语
知识图谱提供了一种新的知识表示、存储、管理方式,使机器能够理解知识,进行知识推理,在很多领域得到了广泛应用,未来,知识图的研究也会越来越受到重视。本文介绍了知识图谱的应用、构建以及未来研究方向,目前知识图谱的应用领域相对较小,下一步我们要在大规模知识图谱的自动化构技术和时序性知识图谱的构建做深入研究,提高知识图谱在其他领域的应用水平。
参考文献:
〔1〕漆桂林,高桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(01):4-25.
〔2〕黃恒琪,于娟,廖晓.知识图谱研究综述[J].计算机系统应用,2019,28(6):1-12.
〔3〕G.Gini.Industry-scale knowledge graphs: lessons and challenges[J].Communication of the ACM,2019,62(08):36-43.
〔4〕Yan Liu, Yan Zou,Lihua Yan,Zhijie Jia,Visualization Research of People's Livelihood Service Data based on Knowledge Graph[C].2020 IEEE International Conference on Information Technology,Big Data and Artificial Intelligence(ICIBA).IEEE,2020.
〔5〕邓志鸿,唐世渭,张铭,等.Ontology研究综述[J].北京大学学报,2002,38(05):731-737.
〔6〕赵琳瑛.基于隐马尔可夫模型的中文实体识别研究[D].西安:西安电子科技大学,2008.
〔7〕霍振朗.基于深度学习的命名实体识别研究[D].广州:华南理工大学,2018.
〔8〕范鹏程,沈英汉,许洪波,程学旗.融合实体知识描述的实体联合消歧方法[J].中文信息学报,2020, 35(07):42-49.
〔9〕王鑫,邹磊,王朝坤.知识图谱数据管理研究综述[J].软件学报,2019,30(07):2139-2174.
〔10〕Kurt Cagle.Graph Databases Go Mainstream[J/OL].https://www.forbes.com/sites/cognitiveworl d/2019/07/18/graph-databases-go-mainstream/#32d93bd0179d,2019-07-18.
〔11〕Zou Y, Liu Y. The Implementation Knowledge Graph of Air Crash Data based on Neo4j*[C]// 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). IEEE, 2020.
