基于时间序列的体育产业数据精准挖掘模型构建
2021-06-24王杰
王杰


摘 要:为了提高体育产业数据精准挖掘和量化分析能力,本文提出基于时间序列的体育产业数据精准挖掘模型构建方法。采用全局稳态特征融合方法实现对体育产业数据分布式时间序列模型构建,采用统计量化融合分析方法实现体育产业数据特征量化空间转换,通过模糊解析控制方法,挖掘体育产业数据的关联分布熵。采用输出增益稳态分析方法,构建体育产业数据挖掘的线性解析参数分析模型,采用二乘规划和线性融合方法,实现对体育产业数据挖掘的内源融合和参数控制,结合模糊聚类实现对体育产业数据的统计特征线性聚类处理。结合稀疏性的特征匹配调度模型,构建体育产业数据挖掘的时间融合序列,通过时间序列重构,实现对体育产业数据的精准挖掘。仿真结果表明,采用该方法进行体育产业数据挖掘的精准度较高,特征匹配度较高,降低了体育产业数据挖掘的扰动误差。
关键词:时间序列;体育产业;数据;精准挖掘;数据聚类
中图分类号:TP391 文献标识码:A 文章编号:1673-260X(2021)04-0029-04
0 引言
随着体育产业融合式发展,在信息化环境下实现对体育产业的进一步结构化融合调度,构建体育产业的大数据融合和特征性挖掘模型,根据体育产业的信息分布,结合统计分析和融合调度方法,建立体育产业数据精准挖掘模型,提高体育产业的大数据共享和信息调度能力,从而提升体育产业的结构化融合发展能力,相关的体育产业数据精准挖掘模型研究在体育产业的优化升级和融合方面具有重要意义[1]。
对体育产业数据精准挖掘模型研究是建立在对体育产业大数据链特征分析基础上,通过大数据链分析和特征优化重组,建立体育产业数据的特征链结构分析模型,通过空间信息融合和量化特征解析控制,建立符合体育产业发展需求的绿色产业链[2],在大数据和云平台分析环境下,实现体育产业数据精准挖掘模型设计,提高体育产业数据精准挖掘能力。在传统方法中,对体育产业数据精准挖掘模型设计方法主要有向量回归分析方法、空间信息融合方法、统计分析方法和模糊度检测方法等,构建体育产业数据挖掘的统计分析模型,结合回归分析,实现对体育产业数据精准挖掘,但传统方法进行体育产业数据挖掘的精准度不高[3-5]。针对传统方法存在的弊端,本文提出基于时间序列的体育产业数据精准挖掘模型构建方法。首先采用全局稳态特征融合方法实现对体育产业数据分布式时间序列模型构建,采用统计量化融合分析方法实现体育产业数据特征量化空间转换,通过模糊解析控制方法,挖掘体育产业数据的关联分布熵。采用输出增益稳态分析方法,然后构建体育产业数据挖掘的线性解析参数分析模型,采用二乘规划和线性融合方法,实现对体育产业数据挖掘的内源融合和参数控制,结合模糊聚类实现对体育产业数据的统计特征线性聚类处理。结合稀疏性的特征匹配调度模型,构建体育产业数据挖掘的时间融合序列,通过时间序列重构,实现对体育产业数据的精准挖掘。最后进行仿真测试分析,展示了本文方法在提高体育产业数据精准挖掘能力方面的优越性能。
1 体育产业数据空间分布结构和统计量化融合分析
1.1 体育产业数据空间分布结构
为了实现基于时间序列的体育产业数据精准挖掘模型构建,采用全局稳态特征融合方法实现对体育产业数据分布式时间序列模型构建,结合两个体育产业数据存储中心节点引出的属性组,构建体育产业数据的底层数据模块,结合语义本体融合[6],构建体育产业数据空间分布结构模型,如图1所示。
在图1所示的体育产业数据空间分布结构模型中,采用空間分布结构特征匹配方法[7],得到体育产业数据空间分布的兼容性特征分布概念集为:
根据上述分析,得到体育产业数据空间分布结构模型,结合大数据融合,实现对体育产业数据空间分布结构重组和数据挖掘。
1.2 体育产业数据的统计量化融合分析
采用统计量化融合分析方法实现体育产业数据特征量化空间转换,通过模糊解析控制方法,挖掘体育产业数据的关联分布熵?啄,得到体育产业数据的关联评价的深度学习模型为:
2 体育产业数据精准挖掘模型优化
2.1 体育产业数据挖掘的线性解析
采用输出增益稳态分析方法,构建体育产业数据挖掘的线性解析参数分析模型,采用二乘规划和线性融合方法,得出概念图CR的中心参数,通过联合参数识别,实现对体育产业数据挖掘的内源融合和参数控制[10],得到体育产业数据挖掘的相似度计算公式可定义如下:
提取体育产业数据的语义本体特征量,构建体育产业数据挖掘的线性规划模型,得到体育产业数据挖掘的模糊阈值控制参数。根据两个概念与的语义相似度分布,得到节点i,从顶级概念类别中,利用最大扩充相容分布,根据内源融合控制,实现体育产业数据挖掘的线性解析[12]。
2.2 体育产业数据挖掘优化输出
结合模糊聚类实现对体育产业数据的统计特征线性聚类处理。结合稀疏性的特征匹配调度模型,构建体育产业数据挖掘的时间融合序列,建立体育产业数据回归分析模型,结合模糊信息融合特征提取的方法,得到体育产业数据挖掘的最短路径寻优控制模型为:
综上分析,结合稀疏性的特征匹配调度模型,构建体育产业数据挖掘的时间融合序列,通过时间序列重构,实现对体育产业数据的精准挖掘,实现流程如图2所示。
3 实验测试分析
为了验证本文方法在实现体育产业数据挖掘精准挖掘中的应用性能,采用SPSS和Visual C++ 进行仿真测试分析,设定递归分析的迭代次数为240,相似度分布系数为0.18,语义相似度为0.89,样本数为7,各组样本的体育产业数据测试集和训练集的匹配系数见表1。
根据上述参数设定,设定测试指标,实现体育产业数据的精准挖掘的性能分析,测试指标分为体育产业数据挖掘的可靠度百分差为:
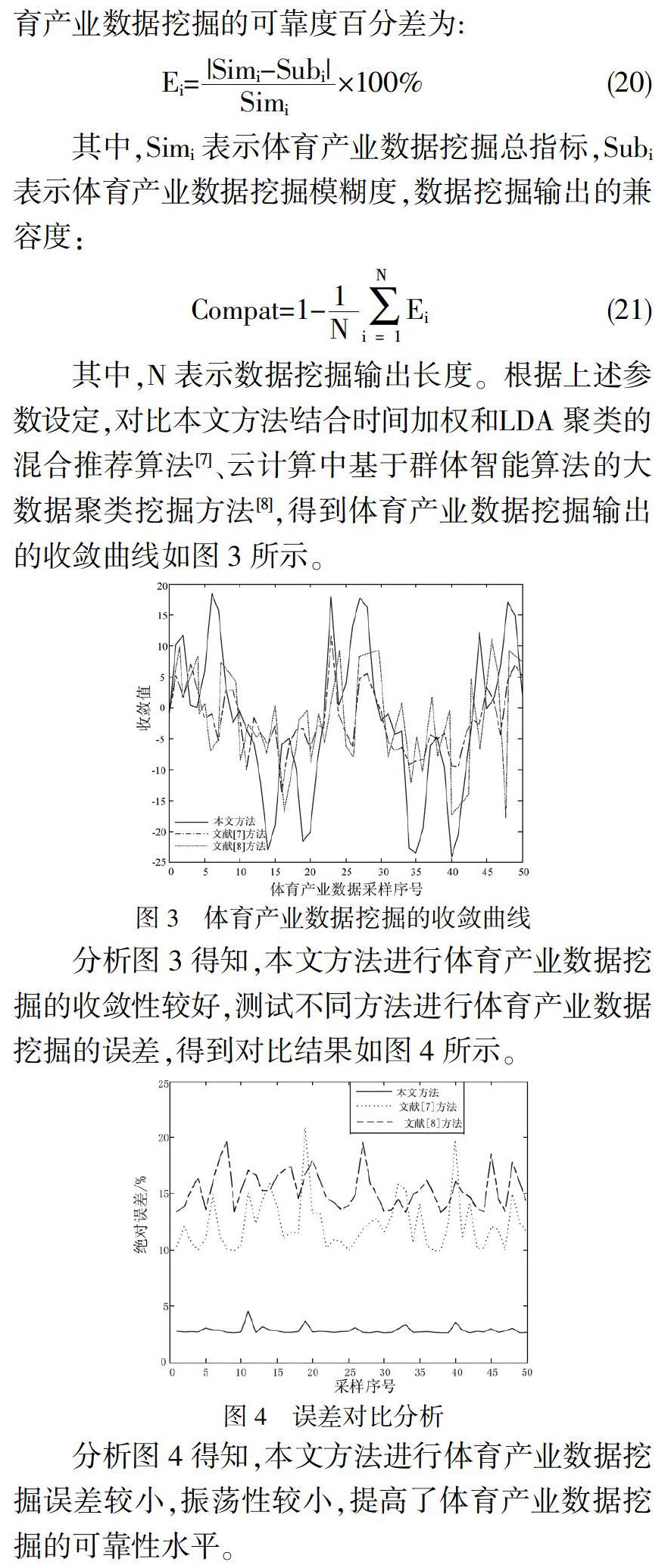
其中,N表示数据挖掘输出长度。根据上述参数设定,对比本文方法]结合时间加权和LDA聚类的混合推荐算法[7]、云计算中基于群体智能算法的大数据聚类挖掘方法[8],得到体育产业数据挖掘输出的收敛曲线如图3所示。
分析图3得知,本文方法进行体育产业数据挖掘的收敛性较好,测试不同方法进行体育产业数据挖掘的误差,得到对比结果如图4所示。
分析图4得知,本文方法进行体育产业数据挖掘误差较小,振荡性较小,提高了体育产业数据挖掘的可靠性水平。
4 结语
建立体育产业数据精准挖掘模型,提高体育产业的大数据共享和信息调度能力,从而提升体育产业的结构化融合发展能力。本文提出基于时间序列的体育产业数据精准挖掘模型构建方法。构建体育产业数据的底层数据模块,结合语义本体融合,实现对体育产业数据空间分布结构重组和数据挖掘。采用二乘規划和线性融合方法,根据内源融合控制,实现体育产业数据挖掘的线性解析。通过时间序列重构,实现对体育产业数据的精准挖掘。研究得知,本文方法对体育产业数据挖掘的误差较低,性能较好。
参考文献:
〔1〕胡甜甜,但雅波,胡杰,等.基于注意力机制的Bi-LSTM结合CRF的新闻命名实体识别及其情感分类[J].计算机应用,2020,40(07):1879-1883.
〔2〕刘璟.中文命名实体识别方法研究[J].电脑知识与技术,2019,15(09):179-180.
〔3〕冯贵兰,李正楠,周文刚.大数据分析技术在网络领域中的研究综述[J].计算机科学,2019,46(06):1-20.
〔4〕田保军,刘爽,房建东.融合主题信息和卷积神经网络的混合推荐算法[J].计算机应用,2020,40(07):1901-1907.
〔5〕SHU J, SHEN X, LIU H,et al. A content-based recommendation algorithm for learning resources[J]. Multimedia Systems,2018, 24(02):163-173.
〔6〕KARABADJI N E I,BELDJOUDI S,SERIDI H,et al. Improving memory-based user collaborative filtering with evolutionary multi-objective optimization[J]. Expert Systems with Applications,2018, 98:153-165.
〔7〕程磊,高茂庭.结合时间加权和LDA聚类的混合推荐算法[J].计算机工程与应用,2019,55(11):160-166.
〔8〕唐新宇,张新政,赵月爱.云计算中基于群体智能算法的大数据聚类挖掘[J].重庆理工大学学报(自然科学),2019,33(04):128-133+167.
〔9〕刘久彪.空间数据库反向最近邻聚类方法[J].吉林大学学报(理学版),2019,57(02):387-392.
〔10〕王亮,冶继民.整合DBSCAN和改进SMOTE的过采样算法[J].计算机工程与应用,2020,56(18):111-118.
〔11〕于超,王璐,程道文.基于本体的教育资源语义检索系统研究[J].吉林大学学报(信息科学版),2018,36(02):207-212.
〔12〕杨志明,王来奇,王泳.深度学习算法在问句意图分类中的应用研究[J].计算机工程与应用,2019,55(10):154-160.
